




B樹的定義爲“在計算機科學中,B樹(B-tree)是一種樹狀數據結構,它能夠存儲數據、對其進行排序並允許以O(log n)的時間複雜度運行進行查找、順序讀取、插入和刪除的數據結構。B樹,概括來說是一個節點可以擁有多於2個子節點的二叉查找樹。與自平衡二叉查找樹不同,B-樹爲系統最優化大塊數據的讀和寫操作。B-tree算法減少定位記錄時所經歷的中間過程,從而加快存取速度。普遍運用在數據庫和文件系統。”
定義
B 樹可以看作是對2-3查找樹的一種擴展,即他允許每個節點有M-1個子節點。
- 根節點至少有兩個子節點
- 每個節點有M-1個key,並且以升序排列
- 位於M-1和M key的子節點的值位於M-1 和M key對應的Value之間
- 其它節點至少有M/2個子節點
下圖是一個M=4 階的B樹:
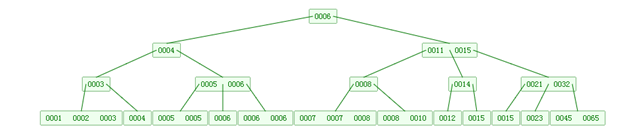
可以看到B樹是2-3樹的一種擴展,他允許一個節點有多於2個的元素。
B樹的插入及平衡化操作和2-3樹很相似,這裏就不介紹了。下面是往B樹中依次插入
6 10 4 14 5 11 15 3 2 12 1 7 8 8 6 3 6 21 5 15 15 6 32 23 45 65 7 8 6 5 4
的演示動畫:

B+樹是對B樹的一種變形樹,它與B樹的差異在於:
- 有k個子結點的結點必然有k個關鍵碼;
- 非葉結點僅具有索引作用,跟記錄有關的信息均存放在葉結點中。
- 樹的所有葉結點構成一個有序鏈表,可以按照關鍵碼排序的次序遍歷全部記錄。
如下圖,是一個B+樹:

下圖是B+樹的插入動畫:

B和B+樹的區別在於,B+樹的非葉子結點只包含導航信息,不包含實際的值,所有的葉子結點和相連的節點使用鏈表相連,便於區間查找和遍歷。
B+ 樹的優點在於:
- 由於B+樹在內部節點上不包含數據信息,因此在內存頁中能夠存放更多的key。 數據存放的更加緊密,具有更好的空間局部性。因此訪問葉子節點上關聯的數據也具有更好的緩存命中率。
- B+樹的葉子結點都是相鏈的,因此對整棵樹的便利只需要一次線性遍歷葉子結點即可。而且由於數據順序排列並且相連,所以便於區間查找和搜索。而B樹則需要進行每一層的遞歸遍歷。相鄰的元素可能在內存中不相鄰,所以緩存命中性沒有B+樹好。
但是B樹也有優點,其優點在於,由於B樹的每一個節點都包含key和value,因此經常訪問的元素可能離根節點更近,因此訪問也更迅速。下面是B 樹和B+樹的區別圖:

分析
對B樹和B+樹的分析和對前面講解的2-3樹的分析類似,
對於一顆節點爲N度爲M的子樹,查找和插入需要logM-1N ~ logM/2N次比較。這個很好證明,對於度爲M的B樹,每一個節點的子節點個數爲M/2 到 M-1之間,所以樹的高度在logM-1N至logM/2N之間。
這種效率是很高的,對於N=62*1000000000個節點,如果度爲1024,則logM/2N <=4,即在620億個元素中,如果這棵樹的度爲1024,則只需要小於4次即可定位到該節點,然後再採用二分查找即可找到要找的值。
應用
B樹和B+廣泛應用於文件存儲系統以及數據庫系統中,在講解應用之前,我們看一下常見的存儲結構:

我們計算機的主存基本都是隨機訪問存儲器(Random-Access Memory,RAM),他分爲兩類:靜態隨機訪問存儲器(SRAM)和動態隨機訪問存儲器(DRAM)。SRAM比DRAM快,但是也貴的多,一般作爲CPU的高速緩存,DRAM通常作爲內存。這類存儲器他們的結構和存儲原理比較複雜,基本是使用電信號來保存信息的,不存在機器操作,所以訪問速度非常快,具體的訪問原理可以查看CSAPP,另外,他們是易失的,即如果斷電,保存DRAM和SRAM保存的信息就會丟失。
我們使用的更多的是使用磁盤,磁盤能夠保存大量的數據,從GB一直到TB級,但是 他的讀取速度比較慢,因爲涉及到機器操作,讀取速度爲毫秒級,從DRAM讀速度比從磁盤度快10萬倍,從SRAM讀速度比從磁盤讀快100萬倍。下面來看下磁盤的結構:

如上圖,磁盤由盤片構成,每個盤片有兩面,又稱爲盤面(Surface),這些盤面覆蓋有磁性材料。盤片中央有一個可以旋轉的主軸(spindle),他使得盤片以固定的旋轉速率旋轉,通常是5400轉每分鐘(Revolution Per Minute,RPM)或者是7200RPM。磁盤包含一個多多個這樣的盤片並封裝在一個密封的容器內。上圖左,展示了一個典型的磁盤表面結構。每個表面是由一組成爲磁道(track)的同心圓組成的,每個磁道被劃分爲了一組扇區(sector).每個扇區包含相等數量的數據位,通常是(512)子節。扇區之間由一些間隔(gap)隔開,不存儲數據。
以上是磁盤的物理結構,現在來看下磁盤的讀寫操作:

如上圖,磁盤用讀/寫頭來讀寫存儲在磁性表面的位,而讀寫頭連接到一個傳動臂的一端。通過沿着半徑軸前後移動傳動臂,驅動器可以將讀寫頭定位到任何磁道上,這稱之爲尋道操作。一旦定位到磁道後,盤片轉動,磁道上的每個位經過磁頭時,讀寫磁頭就可以感知到位的值,也可以修改值。對磁盤的訪問時間分爲 尋道時間,旋轉時間,以及傳送時間。
由於存儲介質的特性,磁盤本身存取就比主存慢很多,再加上機械運動耗費,因此爲了提高效率,要儘量減少磁盤I/O,減少讀寫操作。爲了達到這個目的,磁盤往往不是嚴格按需讀取,而是每次都會預讀,即使只需要一個字節,磁盤也會從這個位置開始,順序向後讀取一定長度的數據放入內存。這樣做的理論依據是計算機科學中著名的局部性原理:
當一個數據被用到時,其附近的數據也通常會馬上被使用。
程序運行期間所需要的數據通常比較集中。
由於磁盤順序讀取的效率很高(不需要尋道時間,只需很少的旋轉時間),因此對於具有局部性的程序來說,預讀可以提高I/O效率。
預讀的長度一般爲頁(page)的整倍數。頁是計算機管理存儲器的邏輯塊,硬件及操作系統往往將主存和磁盤存儲區分割爲連續的大小相等的塊,每個存儲塊稱爲一頁(在許多操作系統中,頁得大小通常爲4k),主存和磁盤以頁爲單位交換數據。當程序要讀取的數據不在主存中時,會觸發一個缺頁異常,此時系統會向磁盤發出讀盤信號,磁盤會找到數據的起始位置並向後連續讀取一頁或幾頁載入內存中,然後異常返回,程序繼續運行。
文件系統及數據庫系統的設計者利用了磁盤預讀原理,將一個節點的大小設爲等於一個頁,這樣每個節點只需要一次I/O就可以完全載入。爲了達到這個目的,在實際實現B-Tree還需要使用如下技巧:
每次新建一個節點的同時,直接申請一個頁的空間( 512或者1024),這樣就保證一個節點物理上也存儲在一個頁裏,加之計算機存儲分配都是按頁對齊的,就實現了一個node只需一次I/O。如,將B樹的度M設置爲1024,這樣在前面的例子中,600億個元素中只需要小於4次查找即可定位到某一存儲位置。
同時在B+樹中,內節點只存儲導航用到的key,並不存儲具體值,這樣內節點個數較少,能夠全部讀取到主存中,外接點存儲key及值,並且順序排列,具有良好的空間局部性。所以B及B+樹比較適合與文件系統的數據結構。下面是一顆B樹,用來進行內容存儲。

另外B/B+樹也經常用做數據庫的索引,這方面推薦您直接看張洋的MySQL索引背後的數據結構及算法原理 這篇文章,這篇文章對MySQL中的如何使用B+樹進行索引有比較詳細的介紹,推薦閱讀。
總結
在前面兩篇文章介紹了平衡查找樹中的2-3樹,紅黑樹之後,本文介紹了文件系統和數據庫系統中常用的B/B+ 樹,他通過對每個節點存儲個數的擴展,使得對連續的數據能夠進行較快的定位和訪問,能夠有效減少查找時間,提高存儲的空間局部性從而減少IO操作。他廣泛用於文件系統及數據庫中,如:
- Windows:HPFS文件系統
- Mac:HFS,HFS+文件系統
- Linux:ResiserFS,XFS,Ext3FS,JFS文件系統
- 數據庫:ORACLE,MYSQL,SQLSERVER等
代碼實現:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
#define DEGREE 3
typedef int KEY_VALUE;
typedef struct _btree_node {
KEY_VALUE *keys;
struct _btree_node **childrens;
int num;
int leaf;
} btree_node;
typedef struct _btree {
btree_node *root;
int t;
} btree;
btree_node *btree_create_node(int t, int leaf) {
btree_node *node = (btree_node*)calloc(1, sizeof(btree_node));
if (node == NULL) assert(0);
node->leaf = leaf;
node->keys = (KEY_VALUE*)calloc(1, (2*t-1)*sizeof(KEY_VALUE));
node->childrens = (btree_node**)calloc(1, (2*t) * sizeof(btree_node));
node->num = 0;
return node;
}
void btree_destroy_node(btree_node *node) {
assert(node);
free(node->childrens);
free(node->keys);
free(node);
}
void btree_create(btree *T, int t) {
T->t = t;
btree_node *x = btree_create_node(t, 1);
T->root = x;
}
void btree_split_child(btree *T, btree_node *x, int i) {
int t = T->t;
btree_node *y = x->childrens[i];
btree_node *z = btree_create_node(t, y->leaf);
z->num = t - 1;
int j = 0;
for (j = 0;j < t-1;j ++) {
z->keys[j] = y->keys[j+t];
}
if (y->leaf == 0) {
for (j = 0;j < t;j ++) {
z->childrens[j] = y->childrens[j+t];
}
}
y->num = t - 1;
for (j = x->num;j >= i+1;j --) {
x->childrens[j+1] = x->childrens[j];
}
x->childrens[i+1] = z;
for (j = x->num-1;j >= i;j --) {
x->keys[j+1] = x->keys[j];
}
x->keys[i] = y->keys[t-1];
x->num += 1;
}
void btree_insert_nonfull(btree *T, btree_node *x, KEY_VALUE k) {
int i = x->num - 1;
if (x->leaf == 1) {
while (i >= 0 && x->keys[i] > k) {
x->keys[i+1] = x->keys[i];
i --;
}
x->keys[i+1] = k;
x->num += 1;
} else {
while (i >= 0 && x->keys[i] > k) i --;
if (x->childrens[i+1]->num == (2*(T->t))-1) {
btree_split_child(T, x, i+1);
if (k > x->keys[i+1]) i++;
}
btree_insert_nonfull(T, x->childrens[i+1], k);
}
}
void btree_insert(btree *T, KEY_VALUE key) {
//int t = T->t;
btree_node *r = T->root;
if (r->num == 2 * T->t - 1) {
btree_node *node = btree_create_node(T->t, 0);
T->root = node;
node->childrens[0] = r;
btree_split_child(T, node, 0);
int i = 0;
if (node->keys[0] < key) i++;
btree_insert_nonfull(T, node->childrens[i], key);
} else {
btree_insert_nonfull(T, r, key);
}
}
void btree_traverse(btree_node *x) {
int i = 0;
for (i = 0;i < x->num;i ++) {
if (x->leaf == 0)
btree_traverse(x->childrens[i]);
printf("%C ", x->keys[i]);
}
if (x->leaf == 0) btree_traverse(x->childrens[i]);
}
void btree_print(btree *T, btree_node *node, int layer)
{
btree_node* p = node;
int i;
if(p){
printf("\nlayer = %d keynum = %d is_leaf = %d\n", layer, p->num, p->leaf);
for(i = 0; i < node->num; i++)
printf("%c ", p->keys[i]);
printf("\n");
#if 0
printf("%p\n", p);
for(i = 0; i <= 2 * T->t; i++)
printf("%p ", p->childrens[i]);
printf("\n");
#endif
layer++;
for(i = 0; i <= p->num; i++)
if(p->childrens[i])
btree_print(T, p->childrens[i], layer);
}
else printf("the tree is empty\n");
}
int btree_bin_search(btree_node *node, int low, int high, KEY_VALUE key) {
int mid;
if (low > high || low < 0 || high < 0) {
return -1;
}
while (low <= high) {
mid = (low + high) / 2;
if (key > node->keys[mid]) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return low;
}
//{child[idx], key[idx], child[idx+1]}
void btree_merge(btree *T, btree_node *node, int idx) {
btree_node *left = node->childrens[idx];
btree_node *right = node->childrens[idx+1];
int i = 0;
/////data merge
left->keys[T->t-1] = node->keys[idx];
for (i = 0;i < T->t-1;i ++) {
left->keys[T->t+i] = right->keys[i];
}
if (!left->leaf) {
for (i = 0;i < T->t;i ++) {
left->childrens[T->t+i] = right->childrens[i];
}
}
left->num += T->t;
//destroy right
btree_destroy_node(right);
//node
for (i = idx+1;i < node->num;i ++) {
node->keys[i-1] = node->keys[i];
node->childrens[i] = node->childrens[i+1];
}
node->childrens[i+1] = NULL;
node->num -= 1;
if (node->num == 0) {
T->root = left;
btree_destroy_node(node);
}
}
void btree_delete_key(btree *T, btree_node *node, KEY_VALUE key) {
if (node == NULL) return ;
int idx = 0, i;
while (idx < node->num && key > node->keys[idx]) {
idx ++;
}
if (idx < node->num && key == node->keys[idx]) {
if (node->leaf) {
for (i = idx;i < node->num-1;i ++) {
node->keys[i] = node->keys[i+1];
}
node->keys[node->num - 1] = 0;
node->num--;
if (node->num == 0) { //root
free(node);
T->root = NULL;
}
return ;
} else if (node->childrens[idx]->num >= T->t) {
btree_node *left = node->childrens[idx];
node->keys[idx] = left->keys[left->num - 1];
btree_delete_key(T, left, left->keys[left->num - 1]);
} else if (node->childrens[idx+1]->num >= T->t) {
btree_node *right = node->childrens[idx+1];
node->keys[idx] = right->keys[0];
btree_delete_key(T, right, right->keys[0]);
} else {
btree_merge(T, node, idx);
btree_delete_key(T, node->childrens[idx], key);
}
} else {
btree_node *child = node->childrens[idx];
if (child == NULL) {
printf("Cannot del key = %d\n", key);
return ;
}
if (child->num == T->t - 1) {
btree_node *left = NULL;
btree_node *right = NULL;
if (idx - 1 >= 0)
left = node->childrens[idx-1];
if (idx + 1 <= node->num)
right = node->childrens[idx+1];
if ((left && left->num >= T->t) ||
(right && right->num >= T->t)) {
int richR = 0;
if (right) richR = 1;
if (left && right) richR = (right->num > left->num) ? 1 : 0;
if (right && right->num >= T->t && richR) { //borrow from next
child->keys[child->num] = node->keys[idx];
child->childrens[child->num+1] = right->childrens[0];
child->num ++;
node->keys[idx] = right->keys[0];
for (i = 0;i < right->num - 1;i ++) {
right->keys[i] = right->keys[i+1];
right->childrens[i] = right->childrens[i+1];
}
right->keys[right->num-1] = 0;
right->childrens[right->num-1] = right->childrens[right->num];
right->childrens[right->num] = NULL;
right->num --;
} else { //borrow from prev
for (i = child->num;i > 0;i --) {
child->keys[i] = child->keys[i-1];
child->childrens[i+1] = child->childrens[i];
}
child->childrens[1] = child->childrens[0];
child->childrens[0] = left->childrens[left->num];
child->keys[0] = node->keys[idx-1];
child->num ++;
left->keys[left->num-1] = 0;
left->childrens[left->num] = NULL;
left->num --;
}
} else if ((!left || (left->num == T->t - 1))
&& (!right || (right->num == T->t - 1))) {
if (left && left->num == T->t - 1) {
btree_merge(T, node, idx-1);
child = left;
} else if (right && right->num == T->t - 1) {
btree_merge(T, node, idx);
}
}
}
btree_delete_key(T, child, key);
}
}
int btree_delete(btree *T, KEY_VALUE key) {
if (!T->root) return -1;
btree_delete_key(T, T->root, key);
return 0;
}
int main() {
btree T = {0};
btree_create(&T, 3);
srand(48);
int i = 0;
char key[26] = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (i = 0;i < 26;i ++) {
//key[i] = rand() % 1000;
printf("%c ", key[i]);
btree_insert(&T, key[i]);
}
btree_print(&T, T.root, 0);
for (i = 0;i < 26;i ++) {
printf("\n---------------------------------\n");
btree_delete(&T, key[25-i]);
//btree_traverse(T.root);
btree_print(&T, T.root, 0);
}
}