




機器學習是一門多學科交叉專業,涵蓋概率論知識、統計學知識、近似理論知識和複雜算法知識。機器學習算法是一類從數據中自動分析獲得規律,並利用規律對未知數據進行預測的算法。通過計算機對數據的處理和對算法的運用,實現對業務場景的深度分析,幫助人們更好的做決策。永洪深度分析模塊是將機器學習算法封裝成節點,用戶通過拖拽的方式從而便捷的應用機器學習算法。
如何使用深度分析模塊?首先需要安裝永洪Desktop,裏面會帶有深度分析功能,目前可以免費試用3個月。其次根據需要安裝R服務環境或Python服務環境,也可以兩個都安裝。如果不會安裝可以查看在線幫助或到官網社區中的產品問答中看相關說明。再次,安裝好後,打開Desktop,選擇【管理系統】-【系統設置】-【R計算配置/Python計算配置】,如下圖1所示。填寫服務器地址和端口號,點擊測試連接,如果連接正確,右上角會彈出測試成功。最後點擊保存連接,至此,深度分析功能就可以使用了。

圖1
想要對業務進行深度分析,就需要對機器學習的流程有一定的瞭解,通常的流程共有8步,如下圖2。在永洪的產品中提供了幾個常用的深度分析的場景,大家可以打開看看,也可以複用使用。
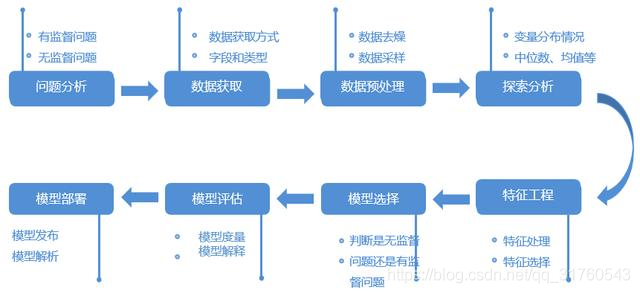
圖2
第一步,問題分析,就是要確定對哪個問題進行分析。例如,對於銀行業企業,通常會進行信用卡反欺詐分析、營銷策略分析等。對於零售行業,通常會進行銷售預測、用戶畫像分析等。對於政府,可以進行交通預測、人流量預測等。確定問題後就要判斷問題是有監督問題還是無監督問題,以此來確定採用哪種技術方案。有監督學習是指輸入數據中有標籤,以概率函數、代數函數或人工神經網絡爲基函數模型,採用迭代計算方法,學習結果爲函數。無監督學習是指輸入數據中無標籤,採用聚類方法,學習結果爲類別。典型的無監督學習算法有降維、聚類等。如何判斷有監督還是無監督,簡單說就是主要看數據是否有打標籤,如果有就是有監督,如果沒有就是無監督。
第二步,數據獲取,就是要把數據導入到產品中。在永洪產品中需要選擇添加數據源模塊,目前支持30多種數據源,如Excel、Mysql、Oracle等。設置好數據源後選擇創建數據集,常用的爲SQL數據集和Excel數據集,選擇完數據後點擊刷新數據,在右側面板中可以看到獲取的數據。
第三步,數據預處理,就是把導入到數據集的數據進行處理。如去重、拆分列、去空格、採樣、分區等。這項工作用戶可以在創建數據集模塊進行設置,如下圖3。
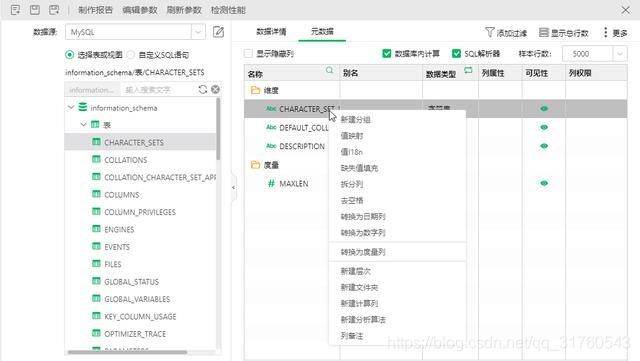
圖3
此外,在深度分析模塊也提供了一些數據處理的節點供用戶使用,從這一步開始到第七步,我們就真正的進入到深度分析的領域了。下面,讓我們來看看永洪的深度分析功能是如何使用的?基本流程如下圖4。

圖4
打開深度分析功能,可以看到,產品提供了一些案例可以幫助用戶快速的學習和了解深度分析。選擇新增實驗模型,打開一個空白的實驗創建面板,如下圖5。
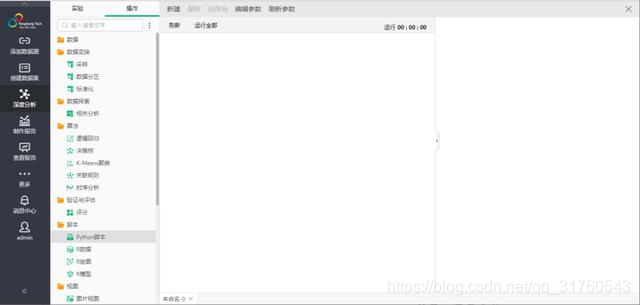
圖5
左側爲操作節點,中間爲畫布,右側爲節點配置、實驗探索等。操作中各個文件夾代表不同的功能節點。其中,數據裏是用戶上傳後數據集保存的位置。數據變換裏是可以對數據進行操作處理的節點。數據探索裏是查看數據是否有缺失值、數據類型等。算法裏目前支持(邏輯迴歸、決策樹、K-Means、關聯規則、時序分析)算法。驗證與評估是評估模型預測結果(R)。腳本可以支持R、Python編程自定義開發。視圖可以將實驗結果進行可視化展示。導出中包括導出模型結果到數據庫或數據集、保存訓練模型或Excel等。訓練模型顯示的是用戶保存的訓練好的模型。
瞭解這些基本的操作後,我們來試試做一個簡單的例子來運用深度分析。比如想要通過用戶行爲的歷史數據進行預測分析,找出可能流失的客戶,以採取對應策略挽留住老客戶,如下圖6。
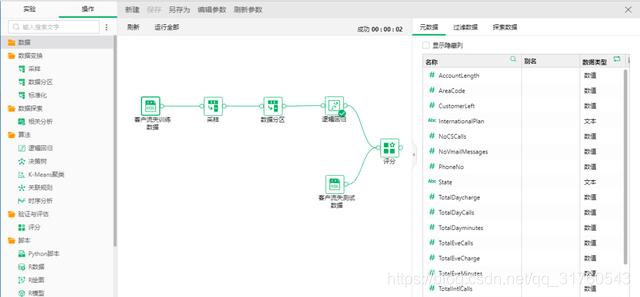
圖6
首先拖入已經創建的客戶流失訓練數據,在右側可以看到元數據列名稱和數據類型,要想了解客戶流失,需要的數據有客戶每天訪問的總時間、客戶每天總的費用、客戶每天訪問的平均時間、客戶平均費用、客戶流失與否等所有影響客戶和與客戶有關的數據,可以在探索數據中看到詳細的數據值。當有數據後,還需要對數據進行處理,將採樣節點拖入到畫布中,對數據進行採樣,一般我們使用隨機採樣的方式,採樣比例視數據量大小而定,如果數據量很大的話可以使用稍小的採樣比例,比如設置爲10%,採樣的結果可以在探索數據中查看。
在採樣後我們需要對數據進行分區訓練,以驗證評估訓練模型的好壞,一般訓練集比例選擇70%。分區後就需要選擇合適的算法,由於數據屬於有監督數據,且是預測分析,因此我們選擇迴歸算法。將邏輯迴歸拖到畫布上,與數據分區連接,在右側配置項目中設置,如下圖7,產品共支持兩種迴歸算法,選擇GLM(廣義線性模型),迴歸方法選擇逐步,因變量選擇CustomerLeft列,然後點擊選擇,添加其餘數值列爲自變量。
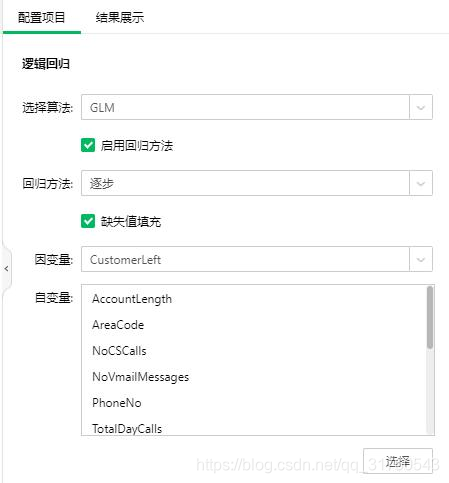
圖7
這步配置好後,可以在節點上單擊右鍵選擇運行,查看預測的數據結果。運行成功後,會彈出結果展示,顯示運行的結果,如下圖8。從結果中我們可以看出,通過模型係數可以得到邏輯迴歸方程的係數,包括截距項、各自變量的係數以及它們的P值、標準誤差。還可以看到模型訓練集合驗證集的準確率和均方誤差。
可以看出,訓練集的準確率高於驗證集且P值都較小(P值越小結果越好)。通過ROC曲線可以看出數據訓練後效果更好,訓練集AUC值0.797大於驗證集AUC值0.748(AUC值越大模型分類效果越好)。
訓練好後可以保存爲訓練模型,將保存爲訓練模型節點拖到畫布中與邏輯迴歸相連接,然後在右側配置中選擇保存的路徑,運行實驗後模型顯示在訓練模型文件夾中。保存的訓練模型可以應用在製作報告模塊或作爲節點拖拽到畫布上再次使用。
不會機器學習也能搞定深度分析,實操演練一看即會
圖8
在對數據進行了預測分析後,我們還需要對訓練數據進行評估,來驗證數據的準確性。拖入“客戶流失測試數據”節點和評分節點,評分節點連接邏輯迴歸和客戶流失測試數據兩個節點。點擊頂部菜單欄中的運行全部,運行成功後選擇評分節點,在數據探索裏可以查看已經使用邏輯迴歸算法訓練的模型應用於“客戶流失測試數據“的結果,如下圖9。
切換不同列,可以看到每列的數據,通過統計數據和可視化圖表可以觀察預測的準確性。數據中包括平均數、數據類型、唯一值、缺失值等,當缺失值爲0時說明數據沒有異常值。

圖9
實驗創建成功後我們就可以進行最後一步發佈和部署了,將保存爲PMML文件節點拖入畫布中,與邏輯迴歸連接,運行成功後,選擇此節點,在右側配置項目中可以選擇下載到本地,你可以將這個PMML文件部署到其他平臺,如下圖10。產品還支持導出到數據庫和保存爲數據集。

圖10
對於成功的實驗,我們可以在可視化頁面查看預測的數據,打開製作報告頁面,拖入餅圖組件,選擇客戶流失訓練數據,然後在更多中選擇已指定訓練模型,選擇剛剛保存的訓練模型,可以看到維度和度量分別新增了類和概率,可以看到流失和不流失的佔比。再拖入一個表格組件,拖入訓練的數據,可以觀察預測的概率(1是流失,0是非流失),如下圖11。
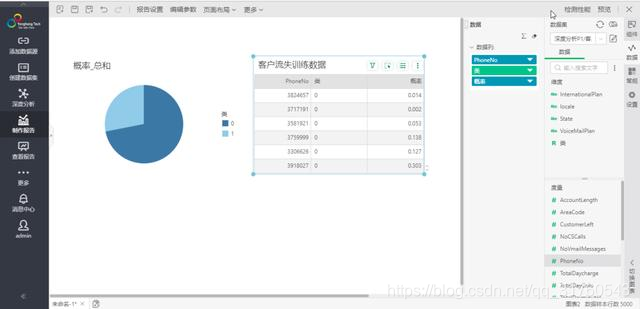
圖11
通過以上這些,你對深度分析是不是有了一些瞭解呢?在國內,擁有深度分析功能的BI產品很少,永洪的深度分析模塊便於沒有機器學習基礎的小白上手,對於機器學習模型部署方便、快捷、不需要定開,且支持R、Python 兩種編程語言,用戶可以通過腳本自定義數據處理和模型,並通過可視化展示模型運行結果。如果你也想要成爲預測大師,就快來和我一起玩轉起來吧!