




基於深度學習的知識圖譜綜述
摘要:隨着現如今計算機設備的更新,計算能力的不斷提高促使深度學習再一度推上熱門技術,深度學習已經廣泛應用於圖像處理、文本挖掘、自然語言處理等方面,在醫學、交通、教育、旅遊等行業發揮極大地作用。知識圖譜也在深度學習的技術下得到了很大的發展。
Ps:與知識圖譜相關的:深度神經網絡,基於深度學習的命名實體識別和關係抽取
本博文的結構如下:
- 知識圖譜的定義
- 知識圖譜的構建流程
- 相關構建技術
- 總結
一、知識圖譜的定義
知識圖譜(Knowledge Graph)最先由谷歌公司提出,其開發了基於知識圖譜的項目,其將知識圖譜應用在語義搜索方面,通過構建起來的知識圖譜可以精準的搜索出需要的信息。谷歌給予的定義爲:知識圖譜是谷歌用於增強其搜索引擎功能的輔助知識庫,總的來講,知識圖譜就是以結構化的信息通過圖結構進行關聯起來的一個知識庫,而基於深度學習的知識圖譜的構建是將某一領域的數據信息通過深度學習算法構建“實體——關係——實體”的三元組模型,並將其存儲在圖結構數據庫中。
二、知識圖譜的構建流程
知識圖譜的結構是指實現構建知識圖譜的技術體系,主要分爲兩大數據採集與處理兩部分。數據採集(Data Acquisition )是指選擇構建知識圖譜的“原材料”,基於深度學習的知識圖譜需要大量的訓練數據進行模型訓練,因此數據採集是知識圖譜的重要的架構之一。數據處理是指針對採集的數據進行相關算法操作,完成相應的任務。如圖1,知識圖譜架構主要分爲如下幾個流程:

-
數據採集(Data Acquisition ) :採集數據集一般可以通過網絡爬蟲、數據庫獲取、人工製作數據或者在相應官網上下載處理過的數據,採集的數據一般由三種形態:
- 結構化數據(Structed Data):對於網絡數據庫現有的信息,可以直接進行數據庫讀寫,這一類數據屬於事先被篩選或整理成二維形式內容,因爲其屬於人工篩選,其置信度往往很高,因此這一類數據是作爲知識圖譜構建前期最主要的方式。但是由於結構化數據需要進行大量的人工操作,所以基於大量數據的情況下,以人工製作結構化數據需要的成本太高;
- 半結構化數據(Semi-Structed Data):半結構化數據是指以web形式顯示的內容,例如百度百科、維基百科等,這一類數據往往是以XML、JSON等形式存在,介於結構化與非結構化之間。這一類數據需要進行一系列的數據預處理工作,將其轉換爲結構化數據;
- 非結構化數據(Unstructed Data):非結構化數據往往是沒有任何結構的數據,例如圖片、音頻、文本等信息,這一類數據往往整體存儲或讀寫。知識圖譜的構建絕大多數需要對這些非結構化數據進行挖掘,因此知識圖譜的構建主要數據來源爲非結構化數據,同時相關的研究也主要以非結構化數據爲“原材料”。
-
知識抽取(Information Extraction):
數據採集後需要進行相應的數據操作,在知識圖譜中的數據操作的關鍵部分是知識抽取,知識抽取主要包括三個步驟:命名實體識別(NER)、實體關係抽取(RC)和屬性抽取。
- 命名實體識別(NER):命名實體識別是對半結構化數據和非機構化數據進行信息抽取的第一步,往往實體是信息的主要載體。實體可以是人、地名等事物,也可以是某個概念。在早期通過字符串匹配或人工操作等方式將需要的實體提取出,隨後人們通過自然語言處理和機器學習方式進行實體提取,而基於深度學習的知識圖譜架構中,命名實體識別通過序列標註方法進行識別
- 實體關係抽取(RC):實體關係抽取又稱關係分類,爲了確定“實體——關係——實體”三元組,需要對實體之間的關係進行分類,這一過程也成爲語義信息的提取。早起的關係抽取採用人工方式,根據語言的語法規則進行模式匹配,這一方式雖然精度很高,但是需要各個領域的專業人士進行操作,同時需要大量的勞動力成本。基於深度學習的知識圖譜架構中,通過特徵工程對含有具有關係的兩個實體的句子進行關係標註,實現監督學習。現如今也有基於自監督學習方式進行關係抽取。另外,Zheng等人提出的聯合NER和RC的學習,將兩個步驟融合一起形成聯合學習方式,在一定程度上提高了模型的精準度,因此
- 屬性抽取:構建起三元組後,需要對實體和關係進行屬性的抽取,屬性抽取往往可以直接通過網絡獲取,同時也可以將屬性視爲實體或關係,通過NER或者RC方式進行處理。
命名實體識別、實體關係抽取以及屬性抽取是知識圖譜的構建的主要部分,也是爲下一步操作做準備。
- 知識融合(Knowledge Fusion):
通過知識抽取工作獲得的三元組往往有一定程度的錯誤信息。在通過NER、RC的模型優化角度考慮,模型的精度往往不是100%,因此會有被錯誤識別的實體或被錯誤分類的關係,因此爲了提高知識圖譜的置信度,需要對其進行處理,主要方式有:
- 實體消歧:同一個實體可能有不同種名稱,同一個名稱可能表示不同類型實體。例如“華東師大”和“華東師範大學”都是同一個事物,而在知識抽取過程中,並沒有將其合併,因此實體消歧的主要目的是消除同名實體產生的歧義問題。參考文獻[1]提供的四種方法:空間向量模型、語義模型、社會網絡模型和百科知識模型可以實現實體消歧。
- 共指消解:在一個句子中,往往有多種指稱項指向同一個實體,這一類問題可以通過句法分析方式進行處理,也可以通過基於機器學習算法方式轉化爲分類或聚類問題。
- 知識合併:往往自主建立的知識體系相對孤立,信息量有限。爲了使自主構建的知識體系可以與網絡現有的知識庫相呼應,需要對知識進行合併,可以將以構建的知識體系以圖結構存儲在圖形數據庫中,通過實體消歧進行合併,也可以將知識體系以關係型存儲在關係數據庫中,並通過數據庫技術進行合併。知識合併是擴大自主學習構建知識庫的重要步驟。
在自主構建知識圖譜過程中,知識融合往往會被忽略,但也格外重要。
- 知識加工(Know Processing):
通過信息抽取,可以從原始語料中提取出實體、關係與屬性等知識要素.再經過知識融合,可以消除實體指稱項與實體對象之間的歧義,得到一系列基本的事實表達.然而,事實本身並不等於知識,要想最終獲得結構化、網絡化的知識體系,還需要經歷知識加工的過程.知識加工主要包括3方面內容:本體構建、知識推理和質量評估。
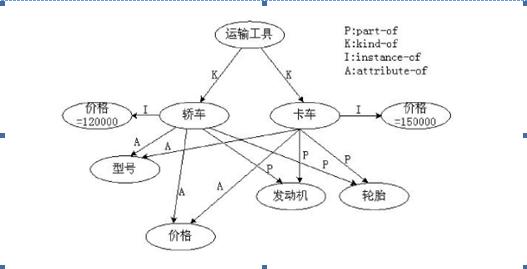
- 本體構建:本體是用於描述一個領域的術語集合(如下圖),本體的目標是獲取、描述和表示相關領域的知識,提供對該領域知識的共同理解,確定領域內共同認可的詞彙,並從不同層次的形式化模式上給出了這些詞彙(術語)和詞彙間相互關係的明確定義。本體的構建可參考:領域本體的構建方法研究
[外鏈圖片轉存失敗(img-NieECZtk-1563620051182)(https://p-blog.csdn.net/images/p_blog_csdn_net/mawenhu/EntryImages/20090101/1.jpg)] - 知識推理:顧名思義,是對知識之間的關係推理,知識推理包括邏輯關係推理和圖關係推理。邏輯關係推理屬於語義分析部分。例如命題“985高校一定是211,而211高校不一定是985”,由此可以推理出華東師範大學是985也是211。圖關係推理根據圖模型進行關係拓展,例如建立的三元組有“華東師範大學在普陀區”,“普陀區在上海市”,可以推理出“華東師範大學在上海市”。
- 知識更新:知識是不斷的更新迭代的,構建好的知識圖譜需要不斷的進行更新。更新方式一般有兩種:全面更新和增量更新。
{kind=link}
三、知識圖譜構建技術
基於深度學習的知識圖譜構建,主要應用深度學習框架,技術主要包括:
(1)數據採集:基於Python網絡爬蟲的數據採集;
(2)詞向量訓練:word-embedding訓練,包括CBOW、Skip-gram模型以及哈夫曼樹和負採樣加速方法;
(3)命名實體識別:RNN,BiRNN,LSTM,BiLSTM,CRF;
(4)實體關係抽取:基於CNN的關係分類,基於依存關係模型的關係抽取;
(5)聯合實體與關係抽取:複合神經網絡模型Bi-LSTM+CRF+CNN,端到端(End-to-end)模型,注意力(Attention)機制等;
(6)深度學習框架:Tensorflow;
(7)數據標註:特徵工程;
(8)圖數據庫:較爲流行的圖數據庫有 Neo4j,Titan,OrientDB和 ArangoDB,本人常用的是Neo4j;
(9)涉及到數學知識:微積分、矩陣論(線性代數)、概率論與數理統計、最優化方法、泛函分析、數值優化等。
Ps:現如今知識圖譜的構建在科研領域是一個龐大的課程研究體系,涉及諸多技術,本人在學習過程中將不斷更新和增加相關技術以適應知識圖譜的發展。
四、總結
知識圖譜已經廣泛應用於各個領域中,常用的應用包括智能問答系統,精準搜索等,知識圖譜作爲當今非常火的人工智能研究方向,在未來將有很大的上升空間。
參考文獻:
[1]: 段宏等. 知識圖譜構建技術綜述[J]. 計算機研究與發展(03).
[2]: 袁凱琦等.醫學知識圖譜構建技術與研究進展[j].計算機應用研究.
[3]: https://blog.csdn.net/github_37002236/article/details/81907721
博客記錄着學習的腳步,分享着最新的技術,非常感謝您的閱讀,本博客將不斷進行更新,希望能夠給您在技術上帶來幫助。