




說明: 該文檔主要考察平安文本糾錯項目和愛奇藝文本糾錯項目整理而來。
1. 常見的中文錯誤類型
-
發音錯誤, 特點:音近,發音不標準, 原因:地方發音,語言轉化。 - 灰機
-
拼寫錯誤:特點: 正確詞語錯誤使用, 原因: 輸入法導致-拼音、五筆、手寫 - 眼睛蛇
-
語法,知識錯誤: 特點:邏輯錯誤,多字、少字,亂序 - 女性患病前列腺炎
2. 研究現狀
2.1 通用糾錯項目
https://github.com/shibing624/pycorrector
-
錯誤檢測
- 常用字典匹配: 切詞後不再常用字典中認爲有錯
- 統計語言模型:某個字的似然概率低於句子的平均值
- 混淆字典匹配:example - 國藉 -> 國籍
-
候選召回
- 近音字替換(拼音): 藉\ji -> 籍, 集, 寄。。。
- 近形字替換(五筆): 藉 -> 籍,藕,箱
-
候選排序
-
語言模型計算句子概率,取概率超過原句子切最大的
P(患者1天前體檢發現脾動脈瘤)
P(患者1天前體檢發現皮動脈瘤)
P(患者1天前體檢發現劈動脈瘤)
-
2.2 學術界進展
-
基於序列標註的糾錯
《 Alibaba at IJCNLP-2017 Task 1: Embedding Grammatical Features
into LSTMs for Chinese Grammatical Error Diagnosis Task 》利用序列標註模型 + 人工提取特徵進行錯誤位置的標註
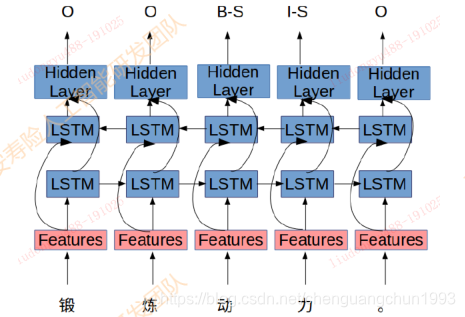
2017年IJCNLP舉辦的CGED比賽中阿里團隊提出的Top1方案
成績: P:0.36, R: 0.21, F1:0.27
-
基於NMT的糾錯
《 Youdao’s Winning Solution to the NLPCC-2018 Task 2 Challenge: A Neural
Machine Translation Approach to Chinese Grammatical Error Correction 》利用模型將錯誤語句翻譯成正確語句,利用transformer模型完成端到端的糾錯過程

成績: P: 0.34, R:0.18, F0.5: 0.29
2.3 評價指標
-
過糾率 / 誤報率
-
召回率
-
糾錯目標
被改正的句子數 >> 被改錯的句子數
目標在於儘可能的提高召回率R。
2.4 存在的問題
公司目前糾錯現狀,還存在一下問題。
- 缺乏標註語料,難以展開基於深度學習的監督學習
- 糾錯強調實時性,對內存和實效性要求很高,線上糾錯不得超過10ms/句,導致大規模字典和複雜模型無法線上使用
- 糾錯要求高準確性,寧願犧牲召回也必須保證高準確度,防止過糾(把正確的詞改錯),過糾率不得高於0.2%
- 結合電子病歷,絕大部分錯誤都是替換錯誤,同音字,同行字等。
3. 平安文本糾錯方案
平安人壽問答糾錯模塊結構如下圖所示。其基本流程包括錯誤檢測、候選召回、候選排序、候選篩選。

3.1 錯誤檢測
-
基於規則的錯誤檢測
- 拼音匹配: 適合實體錯誤檢測,比如疾病,藥品等實體,需要維護拼音-實體隱射字典

-
拼音編輯距離:1. 檢測所有編輯距離小於閾值的路徑 2. 最優路徑選取(最小拼音編輯距離, 最長字符匹配)3. 語言模型 + 規則聯合篩選
-
單雙向2gram檢測
當前詞與上下文組成的2gram詞頻很低,認爲有錯
基於假設: 正確表述發生的頻次要遠遠大於錯誤表述發生的次數

-
基於神經網絡語言模型的錯誤檢測
核心思想:
- 通過完形填空的方式預測候選字的概率分佈
- 如果原字的概率不在topK或者top1比值操作閾值則認爲有錯
改進措施:
-
傳統的語言模型從左到右,單向,只利用上文,改爲雙向模型,利用上下文信息。
-
傳統的語言模型把預測字MASK,沒有預測字的信息,可以改爲引入當前字的混淆字信息(如:相似的字音和字形字)。
-
傳統語言模型會直接預測字表,比如字表大小是3800,預測結果會直接得到3800個字的概率分佈,其中大多是無用信息,且容易引發維度災問題。可以通過將預測字約束在近音、近形和混淆字表裏,提高效率和正確字與錯誤中字的區分度。


-
基於word2vec-cbow改造的音字混合受限字表示語言模型檢測算法
基於CSLM的中文拼寫檢測:《Chinese Spelling Errors Detection Based on CSLM,2015》
主要特徵:
- 帶入預測字及上下文拼音、五筆特徵
- 去掉前後鼻音和翹舌音,並利用混淆音集映射的方式來提高模型對諧音錯誤的識別性能。
- 預測字表受限於近音字、近形字和混淆字表中。

3.2 候選召回
-
近音字候選召回
選擇近音字作爲候選字,構造一個近音字字典。大規模的基礎字典,使得在存儲和讀取速度方面收到了極大的調整。
字典存儲構架如下:

關鍵技術:
-
減低存儲空間:
- 利用Trie樹降低信息冗餘
- 利用經典結合CSR壓縮稀疏矩陣
- 使用詞典間的關聯信息回覆2gram同音字典
-
提高讀取速度:Trie樹、CSR技術的高效索引。
-
字、音編輯距離召回
使用編輯距離作爲是否召回的依據。
-
混淆詞集
-
疾病口語詞
3.3 候選排序
針對候選詞的排序主要由二級排序來實現。
-
一級排序
模型:邏輯迴歸LR
作用:二級排序比較耗時,通過一級排序初篩出TopK進入下一級
要求:正類召回率高,運行速度快
特徵:
- 頻次比值:候選頻次越高分數越高
- 編輯距離:編輯距離越小分數越高
- 拼音jaccard距離:拼音相近分數越高
- 4gram-LM概率差值:候選替換後橘子越通順分數越高
一級排序大致流程如下:

例如:甲狀腺姐姐該怎麼治療? ->結節 0.99
-
頻次: 55 -> 94
-
編輯距離:2
-
拼音jaccard距離:0
-
語言模型概率:-21.9 -> -8.6
-
二級排序
模型:xgboost
作用:分數超過設定閾值且是Top1作爲最終候選
要求:正類準確率高
特徵:
- 局部特徵
- 切詞變化:短語個數、含錯別字片段長度等
- PMI變化:最小值、最值
- 頻次變化:頻次變化、2gram頻次變化
- 4gram語言模型變化
- 形音變化:拼音韻母變化、jccard距離、五筆變化
- 其他:停用詞\錯別字位置、候選來源等等
- 全局特徵
- Cbow-LM
- LSTM-Attention-LM
- BERT-LM
- 局部特徵

例子:紅癍狼倉常見症狀有哪些? 紅斑狼瘡
- 頻次 :20 -> 1688
- 切詞:紅\癍\狼瘡 (1\1\2) -> 紅斑狼瘡 (4)
- nn語言模型:癍 (<0.001) -> 斑 (0.979)
- 4gram語言模型:-19.2 -> -10.6
- PMI:紅癍(0.33) ->紅斑(9.7)
3.4 整體架構

特性:
-
pipline串聯,熱插拔
-
子模塊均遵循檢測-召回-排序流程
-
規則+模型混用
-
離線+在線
在線方案:
- 低延遲、低複雜度
- 高速1ms-3ms/句
- 用於線上實時預測
離線方案:
- 大規模、複雜模型
- 低速200ms-500ms/句
- 用於構造在線模型,訓練數據
3.5 總結與改進
- 優點:
- 無監督,方便將該方法遷移到其他垂直領域,只需要重新無監督挖掘數據
- 系統架構方便插拔特殊編寫糾錯子模塊
- 缺點:
- 很難遷移到通用領域
- Pipline導致錯誤逐級傳遞
- Pipline鏈越長,耗時越長
- 改進思路
- 強化上下文/全局的語義理解
- 訓練預料去噪處理
- 端到端算法,如NMT(神經機器翻譯)
- 語法錯誤(多字少字亂序)
4. 愛奇藝文本糾錯方案
《FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm》
4.1 背景
大部分的中文拼寫檢查模型都使用用一個範式,即講每個漢字的固定相似字符集(混淆集或困惑集)作爲候選項,然後使用過濾器選擇最佳候選項作爲錯字的替換字符。這種設計面臨着兩個主要瓶頸:
-
稀疏的中文拼寫檢查數據上的過擬合問題。
由於中文拼寫檢查數據需要乏味繁冗的專業人力工作,因爲一直資源不足。爲了防止模型的過擬合, Wang等人(2018)提出了一種自動方法來生成僞拼寫檢查數據。 但是,當生成的數據達到40k句子時,其拼寫檢查模型的精度不再提高。 Zhao等人(2017)使用了大量的語言學規則來過濾候選項,但結果卻比我們的表現差,儘管我們的模型沒有利用任何語言學知識。
-
困惑集的使用帶來的漢字字符相似度利用上的不靈活性和不充分性問題。
困惑集因爲是固定的,因此並非在任何語境、場景下都能包含正確候選項(一個比較極端的例子是,如果困惑集按照繁體中文制定,那麼繁體中文的 “體”和“休”肯定不在困惑集的同一組相似字符中,但是在簡體中文中對應的“體”和“休”缺是相似字符,如果錯誤文本中是把“休”寫成了“體”,那麼繁體中文困惑集下就無法檢出,必須專門再製定一個簡體困惑集纔可以),這會極大降低檢測的召回率(不靈活性問題);另外,困惑集中的字符的相似性的信息有損失,沒有得到充分利用,因爲一個字符在困惑集中相似字符是無差別對待的,然而事實上每兩個字符間的相似度明顯是有差別的,因此會影響檢測的精確率(不充分性)。
4.2 設計
FASPell提出通過設計中文拼寫檢查範式來避免傳統模型的兩個瓶頸。FASPell利用seq2seq的思想,包括去噪自編碼器(DAE)和解碼器。
-
編碼器DAE
DAE通過利用無監督預訓練方法(BERT),減少了監督學習中所需的中文拼寫檢查數據量(<10000個句子)。DAE可以將錯誤文本修改爲正確文本的可能候選矩陣,解碼器只需要在這個矩陣中尋求最佳候選項作爲輸出。DAE因爲可以在大規模正常預料數據上無監督訓練,而僅在中文拼寫檢測數據上做fine-tune,避免了過擬合問題。此外,只要DAE足夠強大,所有語境上可能的候選字符都可以出現,且候選字符是根據上下文即時生成的,避免了困惑集帶來的不靈活性。
-
解碼器CSD
CSD巧妙的將預訓練模型的置信度和字相似度結合起來,作爲候選集的評價標準,消除困惑集的使用。CSD根據量化的字符相似度和DAE給出的符合語境的置信度來過濾出正確的替換字符,如此,字符相似性上的細微差別信息都可以得到充分利用。
模型架構如圖1所示:

可以看到,在FASPell中,DAE由BERT中的掩碼語言模型(MLM)來充當,而解碼器使用了置信度-相似度解碼器(CSD)。
4.3 CSD解碼器
CSD主要結合DAE的置信度和字符相似度,置信度直接由DAE給出,暫且不談,這裏詳細說明字符相似度。
-
字符相似度
-
字音
採用中日韓統一表意文字(CJK)語言中的漢語發音,儘管目前只是對中文文本檢錯糾錯,但是實驗證明考慮諸如粵語、日語音讀、韓語、越南語的漢字發音對提高拼寫檢查的性能是有幫助的,而過去的方法均只考慮了普通話拼音。
-
字形
採用Unicode標準的IDS表徵,它可以準確的掃描漢字中各個筆畫和他們的佈局方式,這使得即使相同筆畫和筆畫順序的漢字之間也擁有不爲1的相似度。
以午和牛,田和由爲例:
![在這裏插入圖片描述]()
-
-
訓練CSD
CSD的訓練階段,利用訓練集文本通過MLM輸出的矩陣,逐行繪製置信度-字符相似度散點圖,確定能將FP和 TP分開的最佳分界曲線。


如上圖所示,紅點代表正確檢測並正確糾正的樣本,藍色圓圈代表正確檢測但糾正錯誤的樣本,叉叉代表錯誤檢測的樣本。圖一併沒有過濾候選集;圖二傾向於錯誤檢測性能,大部分正確檢測的候選集保留了下來;圖三更加傾向於錯誤糾正,FASPell採用此種曲線;圖四採用加權確定閾值的方式來確定曲線。
在訓練階段,我們的目標在於確定一條合適的曲線,供於推理階段使用。
3. 推理
在推理階段,逐行根據分界線過濾掉FP得到TP結果,然後將每行的結果取並集得到最終替換結果。以上面架構圖爲例片,句子首先通過fine-tune訓練好的MLM模型,得到的候選字符矩陣通過CSD進行解碼過濾,第一行候選項中只有“主”字沒有被CSD過濾掉,第二行只有“著”字未被過濾掉,其它行候選項均被分界線過濾清除,得到最終輸出結果,即“苦”字被替換爲爲“著”,“豐”被替換爲“主”。