




本文轉自:http://news.mydrivers.com/1/197/197710_all.htm
導讀:AMD統一渲染架構全回顧

數月之前,筆者曾寫過《風雨二十五載!驀然回首看ATI顯卡發展之路》一文,文章就AMD(ATI)的顯卡發展之路進行了詳細回顧,對歷代比較有代表性的顯卡以及重大事件着墨較多。撰文之時,Radeon HD 5000風華正茂,Radeon HD 6000還在孕育當中。時光飛梭,如今Radeon HD 6000已部署完畢,具有顛覆意義的APU也橫空出世,傳統GPU與CPU的概念將逐步走向融合。藉此之機,筆者希望通過此文對AMD以往統一渲染GPU架構的發展歷程進行回顧,以此窺探AMD未來GPU架構將會朝着何種方向發展。
爲什麼要有GPU?說實話,這個問題有些難回答,不過我們依然從過往的一些回憶中引出GPU的概念。雖然民用顯卡可以追溯到上世紀的80年代,但當時的並沒有GPU的概念,而所謂的顯卡更多的被成爲顯示適配器(Display Adapter),僅能用於簡單的文字和圖形輸出,在處理3D圖像和特效是主要還是依賴CPU。
史上首款GPU—GeForce 256

真正的GPU,也就是Graphic Processing Unit(圖形處理器)的概念,最早是由NVIDIA在1999年發佈GeForce 256圖形處理芯片時首先提出的,核心技術有硬體T&L、立方環境材質貼圖和頂點混合、紋理壓縮和凹凸映射貼圖、雙重紋理四像素256位渲染引擎等等。GPU的出現使得顯卡減少了對CPU的依賴,尤其是在3D圖形處理時取代了部分原本CPU的工作,而這一切都要歸功於GPU引入的硬件T&L( Transform & lighting,座標轉換和光源)功能。
本質上來說,3D圖形的渲染是由複雜的座標轉換和光源運算組成的,當顯卡還沒有T&L功能時,座標處理和光源運算都是由CPU來處理的,也就是所謂的軟件T&L。不過由於CPU的任務繁多,除了T&L之外,還要做內存管理、輸入響應等非3D圖形處理工作,因此在實際運算的時候性能會大打折扣,常常出現顯卡等待CPU數據的情況,其運算速度遠跟不上覆雜3D遊戲的要求。
硬件T&L

而GPU從硬件上支持T&L以後, CPU就得以從繁重的運算中解脫出來。首先,3D模型可以用更多的多邊形來描繪,這樣就擁有了更加細膩的效果。其次,CPU不必再計算大量的光照數據,直接通過顯卡就能獲得更好的效能。雖然後來的GPU取消了T&L,採用全新的Shader Model來完成3D建模和光影效果,但就當時來說,硬體T&L技術是GPU的標誌。限於篇幅,關於T&L更多的細節這裏就不再一一贅述。
下面要說一下GPU的工作原理,雖然這和今天的主題看起來離得有些遠,不過考慮到能夠對下面章節更好的闡述,我認爲還是很有必要的。簡單的說,GPU的主要功能就是完成對3D圖形的處理即生成渲染。一般來說,GPU的圖形處理流水線可分爲以下五個階段:
傳統GPU渲染流程

1、 頂點處理:這個階段GPU讀取描述3D圖形外觀的頂點數據並根據頂點數據確定3D圖形的形狀及位置關係,建立起3D圖形的骨架。在支持DX8以後的GPU中,這些工作由硬件實現的Vertex Shader(頂定點着色器)完成。
2、 光柵化計算:顯示器實際顯示的圖像是由像素組成的,我們需要將上面生成的圖形上的點和線通過一定的算法轉換到相應的像素點。把一個矢量圖形轉換爲一系列像素點的過程就稱爲光柵化。例如,一條數學表示的斜線段,最終被轉化成階梯狀的連續像素點。
3、 紋理帖圖:頂點單元生成的多邊形只構成了3D物體的輪廓,而紋理映射(texture mapping)工作完成對多邊形表面的帖圖,通俗的說,就是將多邊形的表面貼上相應的圖片,從而生成“真實”的圖形。TMU(Texture mapping unit)即是用來完成此項工作。
4、 像素處理:這階段(在對每個像素進行光柵化處理期間)GPU完成對像素的計算和處理,從而確定每個像素的最終屬性。在支持DX8以後的GPU中,這些工作由硬件實現的Pixel Shader(像素着色器)完成。
5、 最終輸出:由ROP(光柵化引擎)最終完成像素的輸出,1幀渲染完畢後,被送到顯存幀緩衝區。
所以通俗一點來講,GPU的工作就是完成3D圖形的生成,將圖像映射到相應的像素點上,並且對每個像素進行計算確定最終顏色,最後完成輸出。
上文我們提到了GPU的由來以及渲染過程,以及象徵着初期GPU標識的T&L。GPU通過硬件T&L,實現大量的座標和光影轉換。隨着更加複雜多變的圖形效果的出現,頂點和像素運算的需求量大幅提升,此時的GPU架構也遇到了一些麻煩的問題。遊戲畫面的提高對GPU有了更高的要求,圖形處理生成多邊形的過程中需要加上許多附加運算,比如頂點上的紋理信息、散光和映射光源下的顏色表現等等,有了這些就可以實現更多的圖形效果。
當然,與此同時帶來的就是對GPU頂點和像素的計算能力極具考驗。通過對GPU圖形流水線的分析,工程師們發現與傳統的硬件T&L相比,另一種方案具有更高的效率和靈活性,這就是Shader(渲染器/着色器)的出現。2001年微軟發佈的DirectX 8帶出了Shader Model(渲染單元模式),Shader也由此誕生。
DX8顯卡體系結構及渲染流水線

本質上來說,Shader是一段能夠針對3D圖像進行操作並被GPU所執行的圖形渲染指令集。通過這些指令集,開發人員就能獲得大部分想要的3D圖形效果。在一個3D場景中,一般包含多個Shader,這些Shader中有的負責對3D對象頂點進行處理,有的負責對3D對象的像素進行處理。所以最早版本的Shader Model 1.0中,根據操作對象的不同分別Vertex Shader(頂點着色器/頂點單元,VS)和Pixel Shader(像素着色器/像素單元,PS)。
相比T&L實現的固定的座標和光影轉換,VS和PS擁有更大的靈活性,使得GPU在硬件上實現了頂點和像素的可編程(雖然當時的可編程特性與現在相比很是孱弱),反映在圖形特效上就是出現了動態的光影效果,遊戲玩家們第一次見到了更加逼真波光粼粼的水面;而對於開發者來說,遊戲的開發難度也大大降低了。從歷史意義上來講,Shader Model的出現對GPU來說是一場空前的革命,日後也成爲DirectX API的一個重要部分。每逢DirectX版本升級,Shader Model的技術特性都會隨之增強和擴充。
具體來說,VS的主要作用就是構建3D圖形的骨架,也就是頂點。本質上,任何3D圖形在計算機中只有兩種存在形式,構建骨架的頂點以及連接頂點之間的直線。比如,我們劃一個圓,計算機會把它當做多邊形來處理;如果精度較低,可能是5邊形和或6邊形;如果精度較高,則會是500邊形或600邊形,也就是幾百個頂點和幾百個直線。
而PS的作用就更好理解了,主要負責VS之後的處理,比如圖形表面的紋理以及像素值、顏色等等,使其達到預期的的效果。不過PS中根據各工種的不同細化分爲像素渲染單元(Pixel Shader Unit,PSU)、紋理貼圖單元(Texture Map Unit,TMU)以及光柵化單元(Raster Operations Pipe,ROP;A卡中叫做Render Back End,RBE)。PSU主要負責像素的處理工作,比如我們在遊戲中見到的場景、光影效果等;TMU主要負責紋理處理工作,比如樹木、石頭的紋理以及水面反射等等;而ROP/RBE負責像素的最終輸出工作,執行像素的讀/寫操作、Z-Buffer檢查、色彩混合及抗鋸齒等。
以上諸多單元協同工作,就形成了渲染管線(Shader Pipeline)的概念。渲染管線也習慣上被成爲渲染流水線,從某種程度上來講,我們可以把它看做工廠裏面常見的生產流水線,工廠裏的生產流水線是爲了提高產品的生產能力和效率,而渲染管線則是提高顯卡的工作能力和效率。當然,同樣按照工種,還可分爲頂點渲染管線(Vertex Shader Pipeline,主要就是指頂點單元)和像素渲染管線(Pixel Shder Pipeline,包括PSU、TMU和ROP/RBE),而我們常說的渲染管線就是指像素渲染管線。
在傳統GPU實時渲染的時候,一條管線顯然是遠遠不夠的,於是多條管線並行處理的結構誕生了。一般在同等芯片的對比情況下,管線數量越多性能越高;同樣管線數量的情況下,新核心的性能要高於於老核心的產品。不過另外一個問題又出現了,傳統意義上的像素流水線各個部分單元比例相當,但隨着3D圖形技術的發展,管線各部分負載的壓力開始不均衡起來。
最簡單的例子就是,VS很快完成頂點處理的任務,然後發現PS部分還忙得不可開交。由於運算量太大,PS既不能接收VS的新數據,又不能給後面的ROP/RBE輸出信號,就造成數據的延遲出現。所以PS成爲了管線中的瓶頸;這種情況下,使用更多的PS單元來加強像素和紋理處理工作就成爲顯卡着重改進的地方。而PS的數量也成了衡量顯卡性能的標準之一(針對早期GPU來說)。
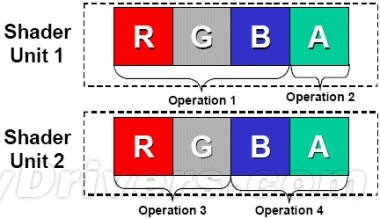
VS和PS都是四元組結構

經過上面的介紹,我們知道VS和PS是傳統GPU中的兩項重要指標,那麼VS和PS在架構又有何異同呢?在計算機圖形處理中,最常見的像素數據都是由R、G、B(紅、綠、藍)三種顏色構成的,加上它們共有的信息說明(Alpha),用來表示顏色的透明度,加起來總共是四個通道;而頂點數據一般是由X、Y、Z、W四個座標構成,這樣也是四個通道。所以從架構上來看,VS和PS既有相同又有不同之處。相同之處在於,二者處理的都是四元組數據,不同之處在於VS需要比較高的計算精度,而PS計算精度較低。
事實上,在3D圖形進行渲染的過程中,VS和PS的主要工作就是進行X、Y、Z、W四個座標運算和計算除R、G、B、A得出像素顏色。爲了一次性處理1個完整的幾何轉換或像素渲染,GPU的VS和PS從最初就被設計成爲同時具備4次運算能力的算數邏輯運算器(ALU)。 而數據的基本單元是Scalar(標量),就是指一個單獨的變量,所以GPU的ALU進行一次這種變量操作,被稱做1D標量。
SIMD架構示意

與標量對應的是Vector(矢量),一個矢量由N個標量標量組成。所以傳統GPU的ALU在一個時鐘週期可以同時執行4次標量的並行運算被稱做4D Vector(矢量)操作。雖然GPU的ALU指令發射端只有一個,但卻可以同時運算4個通道的數據,這就是單指令多數據流(Single Instruction Multiple Data,SIMD)架構。
承接上文,由於先天性設計的優勢,SIMD能夠有效提高GPU的矢量處理性能,尤其是在頂點和像素都是4D矢量的時候,只需要一個指令端口就能在單週期內完成預運算,可以做到100%效率運行不浪費運算單元。雖然早期SIMD執行效率很高,因爲很多情況都是4D矢量的運算操作。但隨着3D技術的不斷髮展,圖形API和Shader指令中的標量運算也開始不斷增多,1D/2D/3D混合指令頻率出現,這時SIMD架構的弊端就顯現出來了。當執行1D標量指令運算的時候,SIMD的效率就會下降到原來的1/4,也就是說在一個運算週期內3/4的運算單元都被浪費了。
混合型SIMD架構的出現
遇到問題的時候,當時的ATI和NVIDIA都在尋求改進。進入DX9時代之後,混合型SIMD設計得到採用,不再使用單純的4D矢量架構,允許矢量和標量指令可以並行運算(也就是Co-issue技術)。比如當時的ATI的R300就採用了3D矢量+1D標量架構,而NVDIA的NV40之後也採用了2D矢量+2D標量和3D矢量+1D標量兩種運算模式。雖然Co-isuue技術一定程度上解決了SIMD架構標量指令執行率低的問題,但遇到需要分支預測運算的情況,依然無法發揮ALU的最大運算能力。
除了SIMD架構的弊端之外,VS和PS構成的所謂“分離式”渲染架構也遭遇了麻煩。在全新一代圖形API DirectX 10的到來之前,頂點渲染和像素渲染各自獨立進行,而且一旦當架構確定下來,VS和PS的比例就會固定。微軟認爲這種分離渲染架構不夠靈活,不同的GPU,其VS和PS的比例不一樣,大大限制了開發人員自由發揮的空間。另外,不同的應用程序和遊戲對像素渲染和頂點渲染的需求不一樣,導致GPU的運算資源得不到充分利用。
分離式渲染架構:VS和PS負載不均
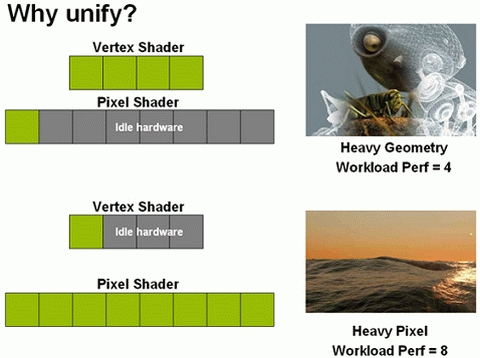
統一渲染架構:VS和PS負載均衡

舉例來說,許多大型3D遊戲中的獨立渲染場景中,遇到高負載幾何工作的時候,VS處理壓力增大大,而PS單元工作較少很多時候都被閒置;反之,遇到高負載像素工作的時候,PS處理壓力增大,而VS又處於閒置狀態。加上傳統的PS和VS以前都是各自爲戰,彼此不相干涉,PS也幫不上VS任何忙,也就造成了GPU執行效率的降低。傳統的管線架構已經跟不上時代了,而這也就促使了DirectX 10中統一渲染架構(Unified Shader Architecture)的出現。
分離式架構和統一架構的差異
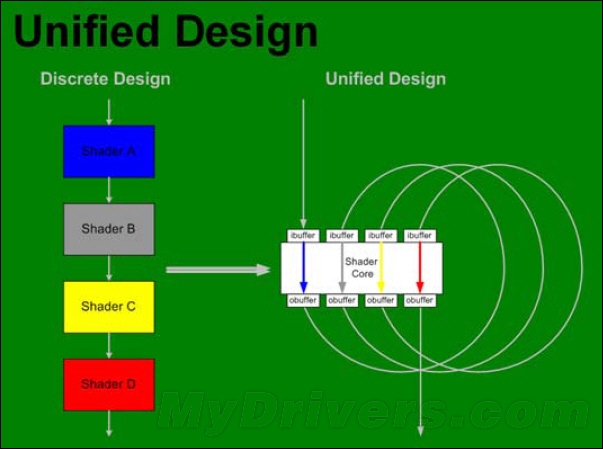
所謂統一渲染架構,就是將傳統的VS、PS以及DirectX 10新引入的GS進行統一分裝。與傳統GPU架構不同,此時的GPU不再分配單獨的渲染管線,所有的運算單元都可以處理任何一種Shader運算(不論頂點操作、像素操作還是幾何操作),而這種運算單元就是經常提到的統一渲染單元(Unified Shader,US)。它的出現避免了傳統GPU架構中PS和VS資源分配不合理的現象,也使得GPU的利用率更高。US的概念一直沿用至今,一般來說US的數量越多,GPU的3D渲染執行能力就越強,所以US的數量也就成了判斷顯卡性能的一個主要標準。
不過對於很多GPU愛好者來說,第一次接觸統一渲染架構的概念並非來自桌面顯卡,而是當時還沒被收購的ATI於2005年與微軟合作發佈的XBOX 360遊戲主機採用的Xenos圖形處理器。Xenos採用了統一渲染架構,頂點、像素等操作都在US上執行,架構上區別於ATI以往任何一款GPU,是ATI第一代統一渲染架構,對日後的R600等也有較大影響。關於的詳細架構,這裏限於篇幅就不再過多介紹,感興趣的讀者可以自行查閱。
Xenos的邏輯架構示意圖

那麼第一款統一渲染架構的桌面GPU呢?雖然理論上這款GPU非ATI莫屬,畢竟已經有了Xenos的設計經驗。不過由於2006年7月份被AMD收購,ATI主要忙收購之後的事宜,研發精力大打折扣,反倒被沒有統一渲染架構設計經驗的NVIDIA在同年7月份搶先發布G80核心的GeForce 8800 GTX顯卡,掀開了桌面統一渲染GPU架構的序幕。G80是NVDIA顯卡歷史上一款極具劃時代意義的GPU,革命性的架構影響了日後的數代顯卡。(雖然G80與AMD毫不相干,但通過G80的和下文R600的對比,我們能夠發現A/N兩家在面對統一架構時做出的不同選擇。)
G80的流處理器結構

G80架構上的改變可謂相當激進,在實現統一渲染單元(Unified Shader,US)的過程中,將傳統GPU架構中VS和PS中的4D矢量 ALU重新設計爲功能更全的1D標量ALU,每一個ALU都有自己的專屬指令發射器,所有運算全部轉化爲1D標量運算,可在一個週期內完成乘加操作。這種1D標量的ALU被NVIDIA稱爲流處理器(Stream Processors,SP)。
G80核心架構圖

G80採用的1D標量式的流處理器架構稱爲多指令多數據流架構(MIMD),完全區別於傳統GPU的SIMD架構。MIMD走的是徹底的標量化路線,這種實現的最大好處是靈活、效率更高,不論是1D、2D、3D、4D指令,G80都通過編譯器將其拆成1D指令交給不同的SP來處理。
每個TPC的詳細結構

這樣也帶來了一些問題,傳統GPU中一個週期完成的4D矢量操作,在這種標量SP中需4個週期才能完成,或者說1個4D操作需要4個SP並行處理完成,那麼執行效率是否會受到很大影響呢?不過NVIDIA異步架構將核心頻率和流處理器頻率分離,流處理頻率進行了大幅提升,達到兩倍於核心頻率的水平,同時大幅增加流處理器數量的方法很好的解決了這一問題。
除了流處理器,G80的紋理單元也被重新設計,將傳統紋理單元(TMU)的功能拆分爲兩種單元:紋理尋址單元(Texture Address Unit)和紋理過濾單元(TexTure Filtering Unit),它們以跟核心頻率相同的頻率運作,以1:2的比例組成了新的紋理渲染陣列(Tex Array)。
所以規格方面,G80核心擁有128個流處理器、64個紋理單元和24個光柵單元,由8個TPC(Thread Processing Cluster,線程處理器集羣)組成,每個TPC中擁有兩組SM(Streaming Multiprocesser,流式多處理器),每組SM擁有16個流處理器和8個紋理單元。每一個TPC都擁有獨立的8個紋理過濾單元(Texture Filtering Unit,TFU)、4個紋理尋址單元(Texture Address Unit,TAU)以及L1緩存。
雖然MIMD架構看起來無懈可擊額,不過和任何事物一樣,GPU架構也不可做到完美。雖然1D標量ALU的設計執行效率很高,但也有相應的代價。理論上4個1D標量ALU和1個4D矢量ALU的運算能力是相當的,但是前者需要4個指令發射端和4個控制單元,而後者只需要1個,如此以來MIMD架構設計的複雜度和所佔用的晶體管數都要遠高於SIMD架構。
直到G80架構出現半年之後的2007年5月15日,AMD(此時已不叫ATI)才正式發佈了基於統一渲染架構R600的Radeon HD 2900 XT(以及其它低端型號的HD 2000系列)。發佈的數月之前AMD就表示R600將會比Xenos快不止一個檔次。但是面對對手G80呢?
相比G80激進地架構變革,R600顯得相對保守一些,因爲它的身上還能看到傳統GPU採用SIMD架構的影子,不過其中的改變還是相對傳統的GPU架構已經算是脫胎換骨了。不同於G80的全標量設計,R600是將原有的4D矢量ALU擴展設計爲5D ALU,準確一點應該叫作5個1D ALU,因爲每個ALU可以執行任意的1D+1D+1D+1D+1D或1D+4D或2D+3D指令運算,(而以往的GPU往往只能是1D+3D或2D+2D),Co-isuue(矢量和標量並行執行)技術在這裏更加靈活多變,所以這種架構也叫做5D Superscalar超標量架構。
R600採用的5D Superscalar超標量架構

AMD稱這些5D ALU爲統一流處理器單元(Stream Processing Units,SPU,區別於SP),每一個SPU中都有5個ALU(也就解釋了爲何A卡和N卡中的流處理器數目差距如此大),其中4個ALU可以進行MADD(Multiply-Add,乘加)操作,而另外一個(也可叫做SFU,特殊函數運算單元)可以執行函數運算、浮點運算以及運算Multiply運算(不能進行ADD運算)。由於每個流處理器單元每個週期只能執行一條指令(這也是傳統SIMD架構的弊端),但是每個每個流處理器中卻擁有5個ALU,如果遇到類似1D標量類似的短指令,執行效率只有1/5,其餘4個ALU都將閒置。
R600核心架構圖

爲了儘可能的提高效率,AMD引入了VLIW5體系(Very Long Instruction Word,超長指令集)的設計,可以將多個短指令合併爲一組長的指令交給流處理器單元去執行,比如5條1D指令或者1條3D指令和兩條1D指令可以合併爲一組5D VLIW指令。這部分的操作由流處理器單元中的Branch Execution Unit(分歧執行單元)來執行。分之執行單元就是指令發射和控制器,它獲得指令包後將會安排至它管轄下5個ALU,進行流控制和條件運算。General Purpose Registers(通用寄存器)存儲輸入數據、臨時數值和輸出數據,並不存放具體的指令。
整體規格方面,R600設計了320個流處理器(64個流處理器單元X5),分爲四個SIMD陣列,每個SIMD陣列分爲兩組,每組包含40個流處理器(16個流處理器單元X5)。紋理單元爲4組,每組包括4個紋理過濾單元和8個紋理尋址單元以及20個紋理採樣單元,共計16個紋理過濾單元和32個紋理尋址單元以及80個紋理採樣單元。
R600中引入的Tessellation是現在曲面細分的雛形

在R600架構中還有兩項技術值得一提,第一個則是Hardware Tessellation,也就是目前DX11中火熱的硬件曲面細分技術,AMD在HD 2000顯卡中引入了這一技術,不過當時的硬件環境遠不成熟,Hardware Tessellation不具有實用性,只在HD 2000顯卡上曇花一現,到了HD 3000系列就去掉了。
R600中的環形總線技術

另外一個則是1024-bit環形總線技術,R600本身就擁有512bit顯存位寬,已經是當時位寬最大的,G80最大位寬也不過384-bit。AMD在此基礎上又引入了Ring bus環形總線,可以等效1024-bit位寬,如果使用高速的GDDR4顯存,那麼顯存帶寬可以輕易突破130GB/s,普通的GDDR3顯存帶寬也有100GB/s以上的帶寬。可惜的是當時的生產工藝還是80nm,512-bit的顯存位寬要佔據相當大的晶體管規模,AMD的環形總線技術也沒有普及開來,到HD 3000系列上甚至精簡爲256-bit,但是搭配高速GDDR3顯存來彌補。
總得來說,得益於SIMD架構,R600可以用少於G80的晶體管堆積出遠遠大於後者的ALU規模,但是在指令執行效率方面,R600相比G80並沒有什麼優勢。因爲非常依賴於將短指令重新打包組合成長指令的算法,對編譯器要求比較高,而G80則不存在這樣的問題。雖然ALU規模、顯存帶寬等一系列數據都要領先,但執行效能的劣勢還是讓R600輸給了G80,這一點也深刻地反映到當時的實際測試中。
作爲AMD第一款桌面統一渲染架構GPU的R600雖然在新特性上亮點不少,但絕對性能面對G80沒有任何優勢,再加上發佈時間上的落後,相關產品在市場上的反映很是慘淡,也宣告了AMD統一渲染架構在桌面GPU的第一次試水以落寞而告終。
R600的試水失敗之後,AMD很快便推出了改進版的RV670架構。AMD在RV670上並沒有增加新晶體管,反而是在減負,晶體管數量由R600的7.2億個降至6.6億,核心面積則從原來的408平方毫米減少至192平方毫米。RV670能夠減負一方面是架構的精簡,比如去掉了1024-bit環線總線改用25bit,另外一方面則得益於生產工藝的進步,由原來的80nm、65nm一步跨入55nm製程工藝,核心面積因此大幅減少。
RV670採用了全新的55nm,核心規模減小,功耗更低

在功能上,RV670增加了DX10.1和PCI-E 2.0支持,增加了RV 670缺失的UVD解碼引擎,可完整支持主流高清編碼的硬解,新一代RV670顯卡還支持三路/四路交火以提高遊戲性能,並在功耗上有過人表現。
RV670相比R600核心架構沒有改變

核心架構設計上,RV670與R600並沒有明顯區別,依然是320個流處理器,分爲4組SIMD陣列,每個陣列對應一組紋理單元。每5個ALU和一個分支預測單元組成一個流處理器單元,繼續着5D的超標量結構。
總體來說,RV670相比R600主要有以下幾點改進:製造工藝由80nm升級至55nm;PCI-E控制器升級支持2.0版本,帶寬倍增;高清解碼引擎由原來的Shader解碼升級爲UVD引擎,支持H.264和VC-1的完全硬解碼;顯存控制器由512bit降至256bit,這是控制成本的需要,而且以R600和RV670的運算能力其實不需要太高的顯存位寬;支持PowerPlay節能技術,待機功耗很低;API升級至DX10.1;
所以說,RV670架構本質上沒有改變,更像是R600架構的工藝改進版。雖然此時NVIDIA的G92相比G80同樣改進不多,但RV670依然沒有討到什麼便宜。R600承擔了太多不成熟的技術和工藝導致性能和架構都沒什麼優勢,但AMD從RV670身上AMD發現了另外一條路:如果頂級性能上不能超越對手,那麼就要在同價位上比對手做的好。要實現這一點,需要AMD在製程工藝、設計思路以及市場策略上作出相應的改變,這也就出現了後來AMD“田忌賽馬”的策略。
雖然改進版的RV670依然沒能給AMD帶來任何生機,但接下來的RV770卻是AMD的揚眉之作。2008年6月份,AMD發佈了基於RV770架構的第二代DX10.1顯卡,顯卡的流處理器單元從上代的320個暴增到800個,AMD的5D超標量架構容易增加流處理器單元的優勢漸漸顯現出來。
RV770的SIMD陣列由RV670的4組增加到10組,紋理單元也相應地增加到10組,整體規格是上一代架構的2.5倍,流處理器單元達到了800個,紋理單元則提高到了40個,光柵單元(ROP)爲16個,SP單元的急劇增加也大幅提升了RV770的性能,至少可以抗衡G92沒有問題,面對“怪獸”GT200也多了一分底氣。
RV770核心架構圖

對比前面的RV670,RV770在架構上主要有以下幾點不同:SIMD陣列排列方向橫置,紋理單元緊靠流處理器單元。因爲RV670架構在紋理性能上不盡如人意,AMD在RV770上改進了紋理單元的設計,雖然每個紋理單元的規格沒有變化,但是效率更高,一個簡單的例子就是開發者去掉用以保證紋理單元獨立性的TMU Pool設計。
RV770的紋理單元改進設計

在紋理單元與顯存控制器之間設有一級緩存,RV770核心相比RV670,L1 TC容量翻倍,再加上數量同比增加2.5倍,因此RV770的總L1容量達到了RV670/R600的五倍之多。另外,RV770還放棄了使用多年的環形總線,估計是因爲高頻率下數據存取命中率的問題,迴歸了交叉總線設計,有效提高了顯存利用率,並節約了顯存帶寬。
RV770的ROP單元

此外,RV770的光柵單元數量保持在RV670的16個,但抗鋸齒性能有了大幅提升,ROP單元Depth stencil ops(景深模板的每秒操作數)雙倍於後者,在執行2MSAA/4MSAA運算時每週期可填充16像素,8AA時每週期可填充8像素,都達到了RV670的兩倍。 此外AMD之前引入過名爲CFAA(Custom Filter Anti-Aliasing)的新算法,在使用CFAA的時候AMD的顯卡還可以利用流處理器進行抗鋸齒運算,800個流處理器最高可以達到24x CFAA。
RV770最爲成功的並非它的架構設計而是AMD的市場策略。通過對55nm製程工藝的熟練掌握,RV770在規格翻了一倍多的同時並沒有大幅增加核心面積(RV670爲192平方毫米,RV770在256平方毫米),晶體管數量從6.6億增加到9.56億的同時功耗控制也非常出色(TDP功耗爲110W,支持自動降頻),所以RV770的成本很低,顯卡上市直接切入消費者的心理價位,AMD的小核心策略贏得了市場成功。
在RV770成功翻身之後,AMD終於有了充足的精力和條件着手開發下一代GPU了。2009年9月23日AMD搶先發布了收款DX11圖形GPU——Cypress(此時AMD已經不再用輸在命名GPU架構),轟動一時。同樣是受益於5D超標量架構出色的可擴展性和40nm新工藝,Cypress在規模方面又有了驚人的提升,其中流處理器數量達到了瘋狂的1600個。
Cypress核心架構圖

從架構來看設計方面來看,Cypress就像是兩顆RV770封裝在一起,流處理器部分可以看做是“雙核心”設計,各項規格也都是RV770的兩倍,比如1600個流處理器、80個紋理單元和32和ROP光柵單元等等。那麼爲什麼要採用這種雙核心設計呢?AMD給出的解釋是,當流處理器擴充至1600個這樣的恐怖規模時,不僅芯片設計製造的難度非常高,而且相應的緩存和控制模塊難以管理協調如此衆多的流處理器,一分爲二的做法效率將會更高。當然,Cypress也並非簡單的雙核版RV770。
Cypress架構前端

這種非常像是CPU中的雙核設計,兩顆核心各自相對獨立,獨享L1、共享L2和內存控制器等其他總線模塊,核心之間則通過專用的數據共享及請求總線通信。爲了配合這兩顆核心中衆多流處理器的工作,裝配引擎內部設計有雙倍的Rasterizer(光柵器)和Hierarchial-Z(多級Z緩衝模塊),這也是與RV770最大的不同。
在流處理器部分,RV870相對於RV770改進有限,只是加入了DX11新增的位操作類指令,並優化了Sum of Absolute Differences(SAD,誤差絕對值求和)算法,指令執行速度提升12倍,此項指令可以在OpenCL底層執行。SAD算法應用最多的就是H.264/AVC編碼的移動向量估算部分(約佔整個AVC編碼總時間的80%),如此一來使用RV870做視頻編碼類通用計算時,性能會大幅提升。
Cypress流處理器單元

另外,流處理器部分還加入了雙精度浮點運算支持,每個流處理器單元(包括5個流處理器)可以執行4條32-bit FP MAD運算,2條64-bit FP MUL or ADD運算,1條64-bit FP MAD運算,4條24-bit Int MUL or ADD運算,特殊功能區每週期可以執行一條32-bit FP MAD運算,均比RV770有了大幅提高。
Cypress的SIMD陣列的紋理單元也有多項改進,支持讀取壓縮後的AA顏色緩衝數據以減少帶寬佔用,此外紋理的差值運算轉移到流處理器中而不再由紋理單元負責。Cypress的雙線過濾紋理運算能力達到了每秒680億次,實際性能中一大明顯改變就是可實現各向無角度紋理過濾。
爲了迎合DX11,Cypress還重拾了R600中的曲面細分單元,並加以優化和改進,使之可以更高效率的細分出更多的多邊形和曲面。還增加了Eyefinity Display Contorllers,可以實現六屏輸出,這也是Cypress的一個亮點。不過總得來說,Cypress相對RV770在架構方面改進有限,主要是新增了DX11新特性,另外利用40nm和新一代GDDR5顯存在功耗控制方面做的非常完美,加上搶先發布性能均衡,受到了很好的市場反響,
即便從本質上來說Cypress架構不算太多改進不多,但搶先發布、衆多新特性的出現、更方面均衡的表現還是受到了很多消費者的青睞,對手的Fermi架構的改變雖然徹底,但遲到許久發佈而且功耗溫度控制很不完善。一路領先的AMD在進入DX11時代節奏就明顯快半拍,更多的研發時間也讓人不禁對下一代“北方羣島”充滿了期待。
但讓人遺憾的是,雖然所謂的代號的Barts核心架構在發佈之前就有各種各樣的傳聞,但是受到各方面限制,特別是臺積電代工工藝的落後,Radeon HD 6800系列所屬的“北方羣島”家族並沒有在覈心架構方面進行大規模的重新設計,而是基本沿用了R600以來的VLIW5式SIMD流處理器結構,並在諸多細節上做了優化和增強,AMD稱之爲“第二代DX11設計”。
Barts核心架構圖

對比前面的Cypress核心架構,Barts 的改變可謂“微乎其微”,最明顯的就是Ultra-Threaded Dispatch Processor(超線程派遣分配單元)不再是Cypress當中的一組,而是爲每個核心模塊均配備了一組。也就是說,原本在Cypress當中的一個超線程派遣分配單元負責的1600個流處理器改爲了現在的兩個超線程派遣分配單元分別負責560個(每核心560個流處理器,兩個核心共1120個)流處理器,從而保證流處理器單元能夠儘可能的達到最高的利用率。
雖然相關產品型更高,但Barts相比Cypress規格卻進行了削減,Barts擁有14個SIMD引擎,每個引擎還是80個流處理器,總共1120個,紋理單元56個,ROP光柵單元32個。從由於各項規格性能上來講要弱於Cypress。當然這跟架構毫無關係,而是AMD的市場策略所致。
按照AMD的說法,Radeon HD 6000系列架構重點有五大方面的進步:1、更強的單位面積性能,比上代提升最多35%;2、第二代DX11設計,更快的曲面細分和幾何吞吐;3、新的和改進的畫質功能,包括抗鋸齒和各向異性過濾;4、增強的多媒體加速,包括、UVD3硬件解碼引擎、AMD APP並行異構計算技術、藍光3D立體技術;5、下一代顯示技術,包括Eyefinity+多屏輸出、HDMI 1.4a規範、DisplayPort 1.2規範。
雖然架構方面的調整微乎其微,但Barts還是對內核設計做了重新配置,單精度浮點性能最高能夠突破2TFlops(每秒2萬億次計算)大關,每秒鐘能夠處理的像素也能超過240億,同時曲面細分單元進行了特別增強(第七代),光柵器(Rasterizer)也配備了兩個,Hub部分有PCI-E 2.1總線控制器、UVD3硬件解碼引擎、CrossFireX管理引擎、Eyefinity顯示控制器等,顯存控制器則依然是四個64-bit,總位寬256-bit,繼續搭配高速GDDR5顯存顆粒。總的來說,Barts算是AMD顯卡發展道路上的穩中過渡。
Barts的出現算是AMD產品路線的一個策略,我們不能說AMD保守,但從長遠發展方面來看,如此做法未必是長久之計。到了Radeon HD 6000的高端型號:Radeon HD 6900系列,我們看到了Cayman革新的VLIW4架構。
Cayman核心架構

與其說是革新,不如說是稍作調整,因爲整個Cayman最根本的流處理器單元依然是基於VILW體系,只不過由5D調整爲4D。每個流處理器單元由4個ALU、一個分支單元、一個通用目的寄存器組成,其中四個流處理器的整數、浮點執行功能完全相同(不再有T-Unit,特殊執行單元),可以執行四路並行發射,但是特殊功能佔據四個發射位中的三個。
VLIW4流處理器單元中的ALU單元減爲4個,數量雖然少了但是這種設計減少了指令調度和寄存器管理,反而提升了利用率。雖然VLIW4架構有着更好的利用率,能將性能與核心面積比提高10%,簡化調度與寄存器管理,邏輯核心也可以很好地重複使用。不過,5D到4D的轉換,相比1D的純標量架構執行效率依然相差甚遠。
除了前端,渲染器後端也進行了升級,支持寫入操作合併,16位整數操作提速兩倍,32位浮點操作也快了兩到四倍。GPU並行計算方面(以往AMD所有圖形架構的弱點),Cayman最大的亮點就是增加了一個全局異步寄存器,從而支持異步分配,可以同時執行多個計算內核,每個內核都有自己的命令隊列與受保護虛擬尋址域。此外還有兩個雙向DMA引擎(更快的系統內存讀寫速度)、着色器讀取操作合併、LDS(本地數據存儲)直接預取、流控制改進、更快雙精度操作(單精度的1/5提高到1/4)。
除此之外,Cayman還增強了曲面細分性能、增強畫質抗鋸齒(EQAA)、增強各向異性過濾與紋理過濾、加入全新功耗管理等等。限於篇幅,這裏就不在過多介紹了。總的來說,Cayman核心算是AMD自統一渲染架構出現以來底層架構最大的一次改變,雖然這種改變並不算徹底,但是不難看出全新架構已經初露苗頭了。
經過前面的介紹不難看出,從R600開始VLIW 5D式SIMD流處理器結構就一直是AMD所有統一渲染GPU架構的基礎,後代產品都是在前代產品的基礎上進行規模擴充、特性革新以及架構微調而來,屬於“裏三年、外三年、裏裏外外又三年”的做法,RV670、RV770以及近兩代的Cypress、Barts、Cayman,本質上無一例外的都是如此。在對手NVIDIA經歷了革新的費米架構之後,AMD是不是也該做點什麼呢?
不可否認,雖然在架構轉變方面沒有NVIDIA那般激進,但過去的數年之中AMD卻硬是靠着長久以來的傳統架構打出了一片天地。這也就說明AMD一直不願放棄的VLIW式SIMD架構自由其獨到之處:設計簡單、不浪費晶體管、規模易於擴充、溫度功耗控制理想、架構換代快、容易加入新特性等等,雖然也存在着執行效率不高、並行計算能力差等等缺點,但總體來說在過去的幾年中AMD做的不錯,至少在3D圖形方面。
但是,無論願不願意承認,隨着技術不斷的發展,AMD依賴數年的的VLIW式SIMD架構是時候壽終正寢了。尤其是進入DX11時代之後,全新API和新特性帶來了以往DirectX 版本看不到的東西,尤其是大量的圖形特效可以靠GPU的計算能力進行加速,這一切在要求傳統圖形渲染能力的同時,對GPU的計算能力也要求十分苛刻。而VLIW架構天生的缺點就在於此,雖然3D圖形渲染沒有問題甚至是相當不錯,但是面向未來,AMD是時候改變了。
AMD Graphics Core Next全新圖形架構設計圖

可喜的是,在前不久的AMD Fusion開發者峯會上,真正的全新圖形架構(Graphics Core Next)已經初露端倪。新架構將會摒棄沿用數年的VLIW,改用全新的non-VLIW體系,除了繼續鞏固3D圖形性能,徹底爲計算優化將使新架構革新的重點。毫無疑問,全新新架構將顛覆AMD以往所有的傳統設計。雖然目前還無法確定新架構什麼時候出現,但至少我們看到AMD對未來GPU架構變革的的信心。