大数据面试之Sqoop
说明,感谢亮哥长期对我的帮助,此处多篇文章均为亮哥带我整理。以及参考诸多博主的文章。如果侵权,请及时指出,我会立马停止该行为;如有不足之处,还请大佬不吝指教,以期共同进步。
1.Sqoop
1.1 Sqoop架构?如何启动访问?
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle 等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到关系型数据库中。

1.2 导入数据
1.2.1 MySQL=> Hive
MySQL=> Hive (MySQL数据导入进Hive)
1.将指定的mysql表迁移到Hive中
sqoop import --hive-import --connect jdbc:mysql://192.168.1.1/dbname --table ${tablename} --username ${username} --password ${password} --hive-database${dbname} -m 1 --as-parquetfile
例如:
sqoop import --hive-import --connect jdbc:mysql://172.16.16.15/test --table person --username mdba --password dsf0723 --hive-database test -m 1 --as-parquetfile
2.将mysql指定库中的所有表迁移到Hive中
sqoop import-all-tables --hive-import --connect jdbc:mysql://192.168.1.1/dbname --username ${username} --password ${password} --hive-database ${dbname} -m 1 --hive-database anhui --as-parquetfile
1.2.2 Oracle=> Hive
-Oracle => Hbase 将上述命令中的jdbc:mysql:改为jdbc:oracle:thin
例如:
sqoop import --hive-import --connect jdbc:oracle:thin:@172.16.16.16:1523:orcl --table test --username cq2017 --password cq2017 --hive-database chongqing_2017 --hive-table test_20170505 -m 1 --as-parquetfile
1.2.3 Sqoop import原理
从传统数据库获取元数据信息(schema、table、field、field type),把导入功能转换为只有Map的Mapreduce作业,在mapreduce中有很多map,每个map读一片数据,进而并行的完成数据的拷贝
Sqoop 在 import 时,需要制定 split-by 参数。
Sqoop 根据不同的 split-by参数值 来进行切分, 然后将切分出来的区域分配到不同 map 中。每个map中再处理数据库中获取的一行一行的值,写入到 HDFS 中。同时split-by 根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的 num-mappers来确定划分几个区域。
1.3 导出数据
1.3.1 Hive(HDFS)=>MySQL
从Hive(HDFS)=>MySQL (从Hive导入进MySQL)
sqoop export --connect jdbc:mysql://192.168.1.1:3306/dbname --username root
--password 123 --export-dir ‘hive表hdfs文件文件存放路径’ --table mysqltablename -m 1 --fields-termianted-by '\t'
--MysqlTableName 必须是提前创建好的,且数据字段和字段类型,分隔符的设定与Hive中一致
--Hive中没有特殊的分隔符要求的话,默认分隔符是/u0001 不用加命令项 --fields-termianted-by ‘\t’
-- hive表hdfs文件文件存放路径 /user/hive/warehouse/库名/表名
1.3.2 Sqoop export 原理
获取导出表的schema、meta信息,和Hadoop中的字段match;多个map only作业同时运行,完成hdfs中数据导出到关系型数据库中介绍Hadoop业务的开发流程以及Sqoop在业务当中的实际地位
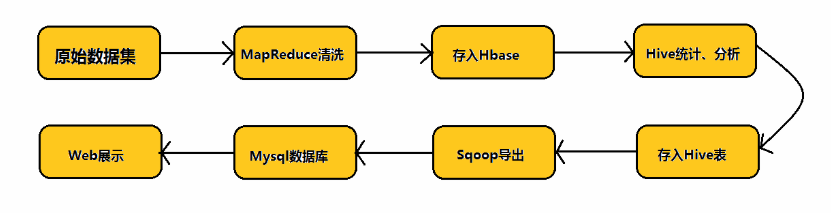
在实际的业务当中,我们首先对原始数据集通过MapReduce进行数据清洗,然后将清洗后的数据存入到Hbase数据库中,而后通过数据仓库Hive对Hbase中的数据进行统计与分析,分析之后将分析结果存入到Hive表中,然后通过Sqoop这个工具将我们的数据挖掘结果导入到MySql数据库中,最后通过Web将结果展示给客户。