




bert
guide attention
Monotonic Attention
Location-awar attention
DCA
Fast Speech
文章目錄
- Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis 2018
- Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron 2018
- HIERARCHICAL GENERATIVE MODELING FOR CONTROLLABLE SPEECH SYNTHESIS 2018
- Multi-reference Tacotron by Intercross Training for Style Disentangling,Transfer and Control in Speech Synthesis 20190404
- MULTI-REFERENCE NEURAL TTS STYLIZATION WITH ADVERSARIAL CYCLE CONSISTENCY 20191125
- MELLOTRON: MULTISPEAKER EXPRESSIVE VOICE SYNTHESIS BY CONDITIONING ON RHYTHM, PITCH AND GLOBAL STYLE TOKENS 20191126
- PROSODY TRANSFER IN NEURAL TEXT TO SPEECH USING GLOBAL PITCH AND LOUDNESS FEATURES 20191221
- USING VAES AND NORMALIZING FLOWS FOR ONE-SHOT TEXT-TO-SPEECH SYNTHESIS OF EXPRESSIVE SPEECH 20200217
- UNSUPERVISED STYLE AND CONTENT SEPARATION BY MINIMIZING MUTUAL INFORMATION FOR SPEECH SYNTHESIS 20200309
- Disentangling Correlated Speaker and Noise for Speech Synthesis via Data Augmentation and Adversarial Factorization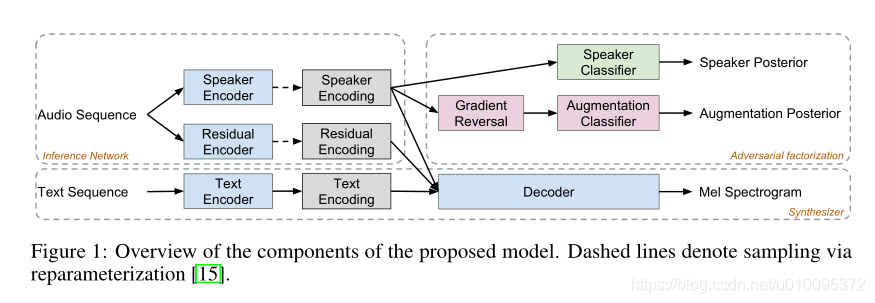
Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis 2018

就把情緒信息和說話人的信息,添加在embedding裏,詞嵌入,之後的decoder該怎麼訓還怎麼訓
Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron 2018

增加了訓練的輸入,韻律的輸入+說話人的輸入+文字的輸入
HIERARCHICAL GENERATIVE MODELING FOR CONTROLLABLE SPEECH SYNTHESIS 2018
引入變分自動編碼器 VAE ,從嘈雜的數據中提出潛在的特性。對於VAE網上講的特別多,我最淺顯的理解就是,我拿到了一些X,然後我要生成和X相似的數據,我假設有個公式 F(Z) = X,我現在的目的就是基於觀測到的X,去反推隱藏的Z以及F(Z)的式子,要是可以的話,那我就可以生成無限個和X相似的X了。替換到語音的話,就是拿到語音,找到其背後的推手,然後再用這個推手去生成,這樣就不愁可以控制了,我可以控制其隱藏的Z從而達到控制X的目的,但這個是不可以預估的,有驚喜。
Multi-reference Tacotron by Intercross Training for Style Disentangling,Transfer and Control in Speech Synthesis 20190404
百度的一篇,GST,之前的input只有文字,現在加入了一些聲音信息,用了多頭注意力,更加厲害。

風格由三個音素控制:說話人、情緒、韻律。有三百個不同的說話人;有喜怒哀樂等情緒;有新聞故事廣播等不同韻律。
MULTI-REFERENCE NEURAL TTS STYLIZATION WITH ADVERSARIAL CYCLE CONSISTENCY 20191125

同時嵌入音頻1和音頻2,交叉起來更厲害
MELLOTRON: MULTISPEAKER EXPRESSIVE VOICE SYNTHESIS BY CONDITIONING ON RHYTHM, PITCH AND GLOBAL STYLE TOKENS 20191126
在標準的數據里弄,合成唱歌,一種顯式變量:文本、說話者id、音高輪廓;一種是隱藏變量:節奏、GTS。

音高輪廓 用 Alain De Cheveigné and Hideki Kawahara, “Yin, a fun-damental frequency estimator for speech and music,” The Journal of the Acoustical Society of America, vol. 111, no. 4, pp. 1917–1930, 2002. 或者 Justin Salamon and Emilia Gómez, “Melody extraction from polyphonic music signals using pitch contour char- acteristics,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 6, pp. 1759–1770, 2012. 獲取。
PROSODY TRANSFER IN NEURAL TEXT TO SPEECH USING GLOBAL PITCH AND LOUDNESS FEATURES 20191221
參考音頻得韻律轉移到合成音頻,音高輪廓和RMS能量曲線 基本頻率(F0)和能量(RMS)

USING VAES AND NORMALIZING FLOWS FOR ONE-SHOT TEXT-TO-SPEECH SYNTHESIS OF EXPRESSIVE SPEECH 20200217
可變自動編碼器和Householder Flow

UNSUPERVISED STYLE AND CONTENT SEPARATION BY MINIMIZING MUTUAL INFORMATION FOR SPEECH SYNTHESIS 20200309

文本和風格的分離更加厲害
Disentangling Correlated Speaker and Noise for Speech Synthesis via Data Augmentation and Adversarial Factorization![在這裏插入圖片描述]()

本文提出了三個組成部分來解決此問題,方法是:(1)制定一個具有因子分解潛變量的條件生成模型;(2)使用數據增強來添加與說話者身份不相關並且在訓練過程中已知其標籤的噪聲;以及( 3)使用對抗分解來改善解纏結。