




線性和多項式迴歸
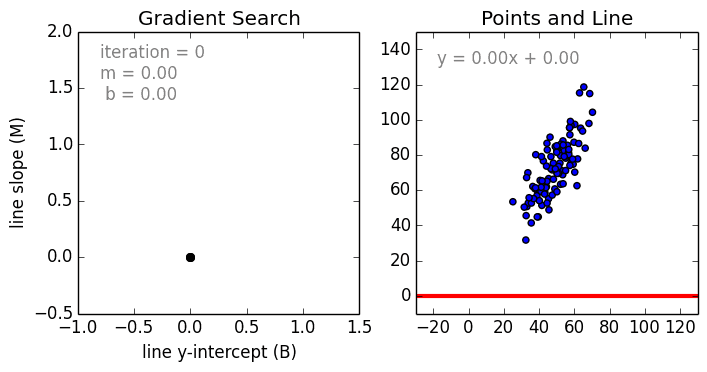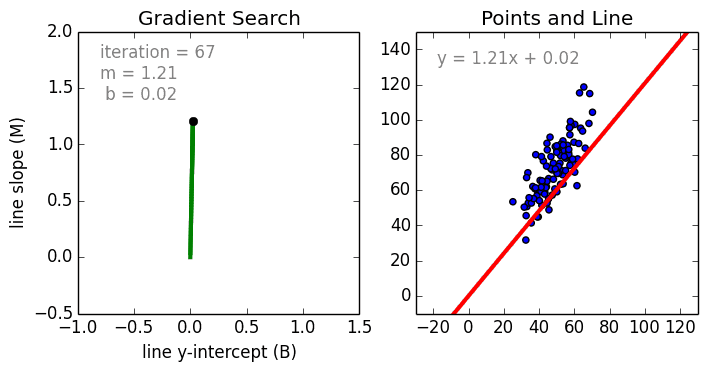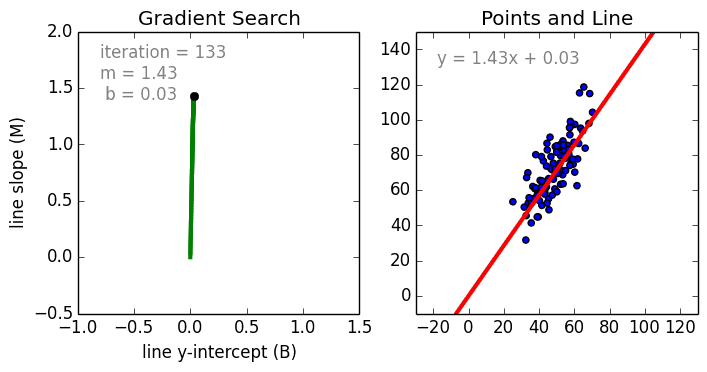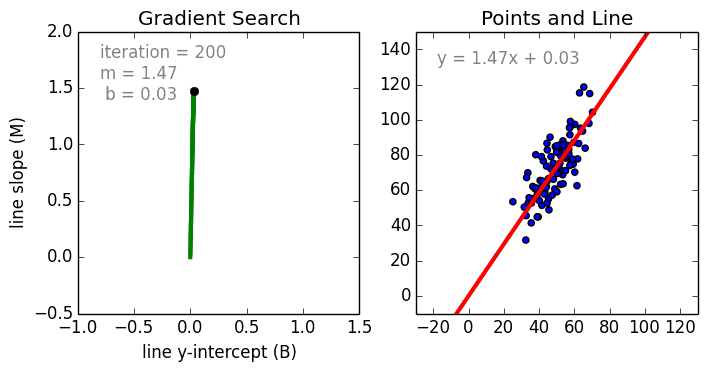
在這一簡單的模型中,單變量線性迴歸的任務是建立起單個輸入的獨立變量與因變量之間的線性關係;而多變量回歸則意味着要建立多個獨立輸入變量與輸出變量之間的關係。除此之外,非線性的多項式迴歸則將輸入變量進行一系列非線性組合以建立與輸出之間的關係,但這需要擁有輸入輸出之間關係的一定知識。訓練迴歸算法模型一般使用隨機梯度下降法(SGD)。
優點:
建模迅速,對於小數據量、簡單的關係很有效;
線性迴歸模型十分容易理解,有利於決策分析。
缺點:
對於非線性數據或者數據特徵間具有相關性多項式迴歸難以建模;
難以很好地表達高度複雜的數據。
迴歸樹和迴歸森林
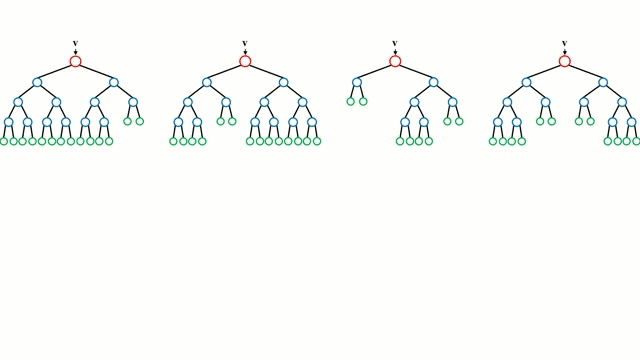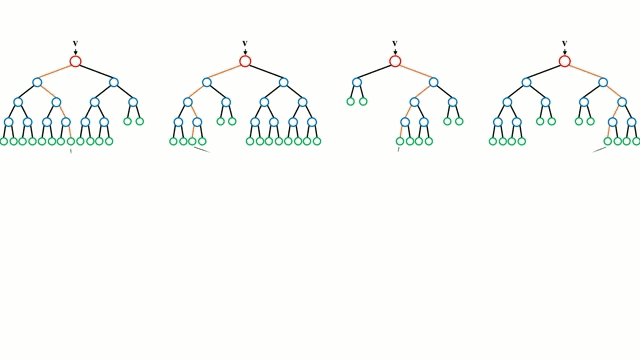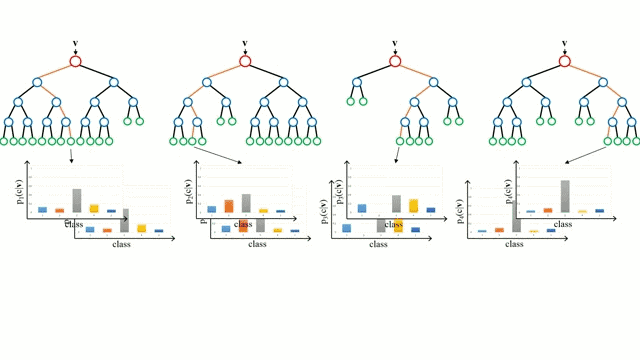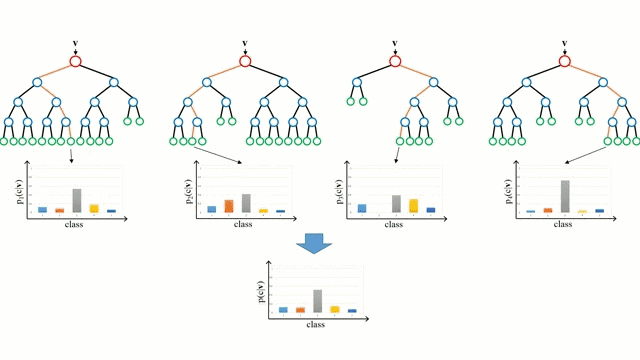
讓我們從最基本的概念出發,決策樹是通過遍歷樹的分支並根據節點的決策選擇下一個分支的模型。樹型感知利用訓練數據作爲數據,根據最適合的特徵進行拆分,並不斷進行循環指導訓練數據被分到一類中去。建立樹的過程中需要將分離建立在最純粹的子節點上,從而在分離特徵的情況下保持分離數目儘可能的小。純粹性是來源於信息增益的概念,它表示對於一個未曾謀面的樣本需要多大的信息量才能將它正確的分類。實際上通過比較熵或者分類所需信息的數量來定義。而隨機森林則是決策樹的簡單集合,輸入矢量通過多個決策樹的處理,最終的對於迴歸需要對輸出數據取平均、對於分類則引入投票機制來決定分類結果。
優點:
具有很高的複雜度和高度的非線性關係,比多項式擬合擁有更好的效果;
模型容易理解和闡述,訓練過程中的決策邊界容易實踐和理解。
缺點:
由於決策樹有過擬合的傾向,完整的決策樹模型包含很多過於複雜和非必須的結構。但可以通過擴大隨機森林或者剪枝的方法來緩解這一問題;
較大的隨機數表現很好,但是卻帶來了運行速度慢和內存消耗高的問題。
神經網絡
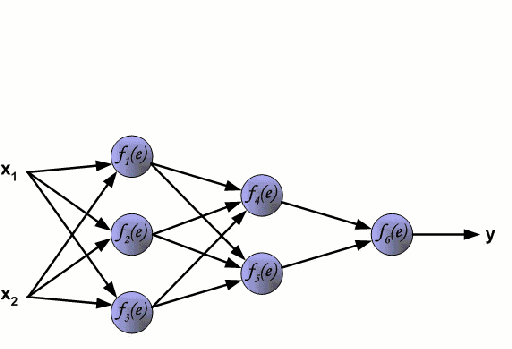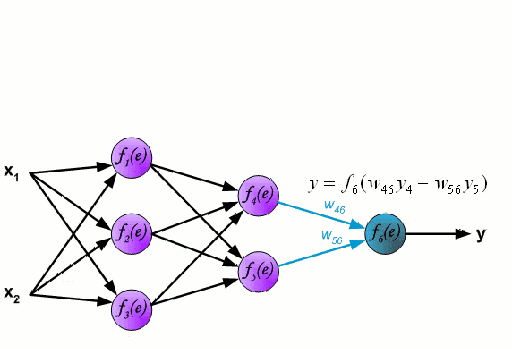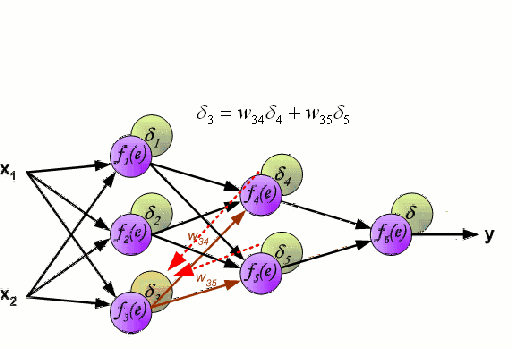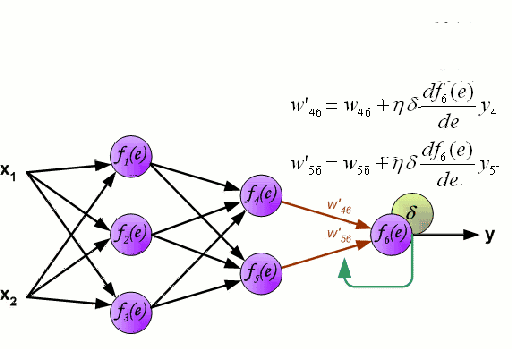
神經網絡由一系列稱爲神經元的節點通過內部網絡連接而成,數據的特徵通過輸入層被逐級傳遞到網絡中,形成多個特徵的線性組合,每個特徵會與網絡中的權重相互作用。隨後神經元對線性組合進行非線性變化,這使得神經網絡模型具有對多特徵複雜的非線性表徵能力。神經網絡可以具有多層結構,以增強對於輸入數據特徵的表徵。人們一般利用隨機梯度下降法和反向傳播法來對神經網絡進行訓練,請參照上述圖解。
優點:
多層的非線性結構可以表達十分複雜的非線性關係;
模型的靈活性使得我們不需要關心數據的結構;
數據越多網絡表現越好。
缺點:
模型過於複雜,難以解釋;
訓練過程需要強大算力、並且需要微調超參數;
對數據量依賴大,但常規機器學習問題則使用較小量數據。
BP神經網絡
預測波士頓房價

import numpy as np
import tensorflow as tf
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 數據集預處理
data_X = []
data_Y = []
with open('boston_house_prices.csv') as f:
for line in f.readlines():
line = line.split(',')
data_X.append(line[:-1])
data_Y.append(line[-1:])
# 轉換爲nparray
data_X = np.array(data_X, dtype='float32')
data_Y = np.array(data_Y, dtype='float32')
# 檢查大小
print('data shape', data_X.shape, data_Y.shape)
print('data_x shape[0]', data_X.shape[1])
# 歸一化
for i in range(data_X.shape[1]):
_min = np.min(data_X[:, i]) #每一列的最小值
_max = np.max(data_X[:, i]) #每一列的最大值
data_X[:, i] = (data_X[:, i] - _min) / (_max - _min) #歸一化到0-1之間
# # 分割訓練集、測試集
X_train, X_test, y_train, y_test = train_test_split(data_X, # 被劃分的樣本特徵集
data_Y, # 被劃分的樣本標籤
test_size=0.5, # 測試集佔比
random_state=0) # 隨機數種子,在需要重複試驗的時候,保證得到一組一樣的隨機數
# 查看測試集,訓練集形狀
print(X_train.shape)
print(X_test.shape)
# 定義每個批次大小
batch_size = 1
# 計算總批次的次數,以便迭代
n_batch = X_train.shape[0] // batch_size
# 訓練次數
# max_step =10000
max_step =10000
# 文件路徑
# DIR = "D:/PycharmProjects/BostonHousePrices/projector"
# 參數概要
def variable_summaries(var):
with tf.name_scope("summaries"):
mean = tf.reduce_mean(var)
tf.summary.scalar("mean", mean) # 均值
with tf.name_scope("stddev"):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var-mean)))
tf.summary.scalar("stddev", stddev) # 標準差
tf.summary.scalar("max", tf.reduce_max(var)) # 最大值
tf.summary.scalar("min", tf.reduce_min(var)) # 最小值
tf.summary.histogram("histogram", var) # 直方圖
# 定義一個命名空間
with tf.name_scope("input"):
# 定義兩個佔位變量
x = tf.placeholder(tf.float32, [None, 13], name="x-input")
y = tf.placeholder(tf.float32, [None, 1], name="y-input")
# 設置參數設置DROPOUT參數
arg_dropout = tf.placeholder(tf.float32)
# 定義神經網絡
with tf.name_scope("layer"):
# 第一層網絡
with tf.name_scope('weight_1'):
weight_1 = tf.Variable(tf.truncated_normal([13, 50], stddev=0.1), name='weight_1')
variable_summaries(weight_1)
with tf.name_scope('bias_1'):
bias_1 = tf.Variable(tf.zeros([50])+0.1, name='bias_1')
variable_summaries(bias_1)
with tf.name_scope('L_1_dropout'):
L_1 = tf.nn.tanh(tf.matmul(x, weight_1)+bias_1)
L_1_dropout = tf.nn.dropout(L_1, arg_dropout)
#第二層網絡
with tf.name_scope('weight_2'):
weight_2 = tf.Variable(tf.truncated_normal([50, 300], stddev=0.1), name='weight_2')
variable_summaries(weight_2)
with tf.name_scope('bias_2'):
bias_2 = tf.Variable(tf.zeros([300]) + 0.1, name='bias_2')
variable_summaries(bias_2)
with tf.name_scope('L_2_dropout'):
L_2 = tf.nn.tanh(tf.matmul(L_1_dropout, weight_2) + bias_2)
L_2_dropout = tf.nn.dropout(L_2, arg_dropout)
#第三層網絡
with tf.name_scope('weight_3'):
weight_3 = tf.Variable(tf.truncated_normal([300, 50], stddev=0.1), name='weight_3')
variable_summaries(weight_3)
with tf.name_scope('bias_3'):
bias_3 = tf.Variable(tf.zeros([50]) + 0.1, name='bias_3')
variable_summaries(bias_3)
with tf.name_scope('L_3_dropout'):
L_3 = tf.nn.tanh(tf.matmul(L_2_dropout, weight_3) + bias_3)
L_3_dropout = tf.nn.dropout(L_3, arg_dropout)
with tf.name_scope("output"):
# 創建最後一層神經網絡
with tf.name_scope('weight'):
weight = tf.Variable(tf.truncated_normal([50, 1], stddev=0.1), name='weight')
variable_summaries(weight)
with tf.name_scope('bias'):
bias = tf.Variable(tf.zeros([1])+0.1, name='bias')
variable_summaries(bias)
with tf.name_scope('prediction'):
prediction = tf.matmul(L_3_dropout, weight) + bias
with tf.name_scope("loss"):
# 方法一:二次代價函數
loss = tf.reduce_mean(tf.square(prediction - y))
# 方法二:交叉墒
# loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
tf.summary.scalar("loss", loss)
# adam梯度下降方式最小化代價函數
train = tf.train.AdamOptimizer(1e-4).minimize(loss)
# 合併所有的summary標量
merged = tf.summary.merge_all()
# 訓練
def get_Batch(image, label, batch_size, now_batch, total_batch):
if now_batch < total_batch:
x_batch = image[now_batch*batch_size:(now_batch+1)*batch_size]
y_batch = label[now_batch*batch_size:(now_batch+1)*batch_size]
else:
x_batch = image[now_batch*batch_size:]
y_batch = label[now_batch*batch_size:]
return x_batch, y_batch
with tf.Session() as sess:
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
write = tf.summary.FileWriter("logs/", sess.graph)
for epoch in range(max_step):
train_loss_list = []
for batch in range(n_batch):
batch_xs, batch_ys = get_Batch(X_train, y_train, 1, batch, n_batch)
summary, _ , train_loss = sess.run([merged, train, loss], feed_dict={x: batch_xs, y: batch_ys, arg_dropout: 0.5})
train_loss_list.append(train_loss)
write.add_summary(summary, epoch)
if epoch % 100 == 0:
print('epoch ' + str(epoch) + ' train_loss ' + str(np.mean(train_loss_list)))
test_loss_list = []
pre = []
true = []
for batch1 in range(n_batch):
batch_xss, batch_yss = get_Batch(X_test, y_test, 1, batch1, n_batch)
test_pre, test_loss = sess.run([prediction, loss], feed_dict={x: batch_xss, y: batch_yss, arg_dropout: 1.0})
test_loss_list.append(test_loss)
true.append(batch_yss[0][0])
pre.append(test_pre[0][0])
print('test_loss ' + str(np.mean(test_loss_list)))
plt.plot(range(n_batch), true, 'b-')
plt.plot(range(n_batch), pre, 'r:')
plt.savefig('./test2.jpg')
plt.show()
saver.save(sess, "./projector/a_model_ckpt", global_step=max_step)
write.close()
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-YV7YnDZs-1592112928720)(D:\CSDN\pic\迴歸\1592112180038.png)]](https://pic1.xuehuaimg.com/proxy/csdn/https://img-blog.csdnimg.cn/2020061413354522.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70)
其中歸一化是肯定要做的.文章屬於複習,非完全原創,參考於:
reference:https://www.cnblogs.com/jwg-fendi/p/10066545.html
https://blog.csdn.net/qq_44479403/article/details/103183635