




聚簇索引(Clustered Index)和非聚簇索引 (Non- Clustered Index)
最通俗的解釋是:聚簇索引的順序就是數據的物理存儲順序,而對非聚簇索引的索引順序與數據物理排列順序無關。在一張表上最多隻能創建一個聚集索引,因爲真實數據的物理順序只能有一種。舉例來說,你翻到新華字典的漢字“爬”那一頁就是P開頭的部分,這就是物理存儲順序(聚簇索引);而不用你到目錄,找到漢字“爬”所在的頁碼,然後根據頁碼找到這個字(非聚簇索引)。
下表給出了何時使用聚簇索引與非聚簇索引:
|
動作 |
使用聚簇索引 |
使用非聚簇索引 |
|
列經常被分組排序 |
應 |
應 |
|
返回某範圍內的數據 |
應 |
不應 |
|
一個或極少不同值 |
不應 |
不應 |
|
小數目的不同值 |
應 |
不應 |
|
大數目的不同值 |
不應 |
應 |
|
頻繁更新的列 |
不應 |
應 |
|
外鍵列 |
應 |
應 |
|
主鍵列 |
應 |
應 |
|
頻繁修改索引列 |
不應 |
應 |
聚簇索引的唯一性
正式聚簇索引的順序就是數據的物理存儲順序,所以一個表最多隻能有一個聚簇索引,因爲物理存儲只能有一個順序。正因爲一個表最多隻能有一個聚簇索引,所以它顯得更爲珍貴,一個表設置什麼爲聚簇索引對性能很關鍵。
初學者最大的誤區:把主鍵自動設爲聚簇索引
因爲這是SQLServer的默認主鍵行爲,你設置了主鍵,它就把主鍵設爲聚簇索引,而一個表最多隻能有一個聚簇索引,所以很多人就把其他索引設置爲非聚簇索引。這個是最大的誤區。甚至有的主鍵又是無意義的自動增量字段,那樣的話Clustered index對效率的幫助,完全被浪費了。
剛纔說到了,聚簇索引性能最好而且具有唯一性,所以非常珍貴,必須慎重設置。一般要根據這個表最常用的SQL查詢方式來進行選擇,某個字段作爲聚簇索引,或組合聚簇索引,這個要看實際情況。
事實上,建表的時候,先需要設置主鍵,然後添加我們想要的聚簇索引,最後設置主鍵,SQLServer就會自動把主鍵設置爲非聚簇索引(會自動根據情況選擇)。如果你已經設置了主鍵爲聚簇索引,必須先刪除主鍵,然後添加我們想要的聚簇索引,最後恢復設置主鍵即可。
記住我們的最終目的就是在相同結果集情況下,儘可能減少邏輯IO。
我們先從一個實際使用的簡單例子開始。
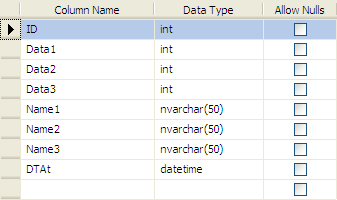
一個簡單的表:
- CREATE TABLE [dbo].[Table1](
- [ID] [int] IDENTITY(1,1) NOT NULL,
- [Data1] [int] NOT NULL DEFAULT ((0)),
- [Data2] [int] NOT NULL DEFAULT ((0)),
- [Data3] [int] NOT NULL DEFAULT ((0)),
- [Name1] [nvarchar](50) NOT NULL DEFAULT (''),
- [Name2] [nvarchar](50) NOT NULL DEFAULT (''),
- [Name3] [nvarchar](50) DEFAULT (''),
- [DTAt] [datetime] NOT NULL DEFAULT (getdate())
來點測試數據(10w條):
- declare @i int
- set @i = 1
- while @i < 100000
- begin
- insert into Table1 ([Data1] ,[Data2] ,[Data3] ,[Name1],[Name2] ,[Name3])
- values(@i, 2* @i,3*@i, CAST(@i AS NVARCHAR(50)), CAST(2*@i AS NVARCHAR(50)), CAST(3*@i AS NVARCHAR(50)))
- set @i = @i + 1
- end
- update table1 set dtat= DateAdd (s, data1, dtat)
- SET STATISTICS IO ON;
- SET STATISTICS TIME ON;
我們最常用的SQL查詢是這樣的:
- SELECT * FROM Table1 WHERE Data1 = 2 ORDER BY DTAt DESC;
然後執行該語句,結果是:
- Table 'Table1'. Scan count 1, logical reads 911, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 16 ms, elapsed time = 7 ms.

然後我們在Data1和DTat字段分別建立非聚簇索引:
- CREATE NONCLUSTERED INDEX [N_Data1] ON [dbo].[Table1]
- (
- [Data1] ASC
- )WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF) ON [PRIMARY]
- CREATE NONCLUSTERED INDEX [N_DTat] ON [dbo].[Table1]
- (
- [DTAt] ASC
- )WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF) ON [PRIMARY]
- Table 'Table1'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 0 ms, elapsed time = 39 ms.
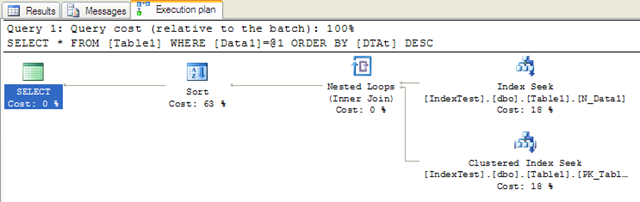
可以看到設立了索引反而沒有任何性能的提升而且消耗的時間更多了,繼續調整。
然後我們刪除所有非聚簇索引,並刪除主鍵,這樣所有索引都刪除了。建立組合索引Data1和DTAt,最後加上主鍵:
- CREATE CLUSTERED INDEX [C_Data1_DTat] ON [dbo].[Table1]
- (
- [Data1] ASC,
- [DTAt] ASC
- )WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF) ON [PRIMARY]
- Table 'Table1'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 0 ms, elapsed time = 1 ms.
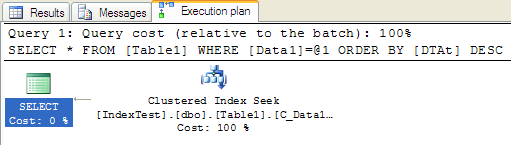
可以看到只有聚簇索引seek了,消除了index scan和nested loop,而且執行時間也只有1ms,達到了最初優化的目的。
組合索引小結
小結以上的調優實踐,要注意聚簇索引的選擇。首先我們要找到我們最多用到的SQL查詢,像本例就是那句類似的組合條件查詢的情況,這種情況最好使用組合聚簇索引,而且最多用到的字段要放在組合聚簇索引的前面,否則的話就索引就不會有好的效果,看下例:
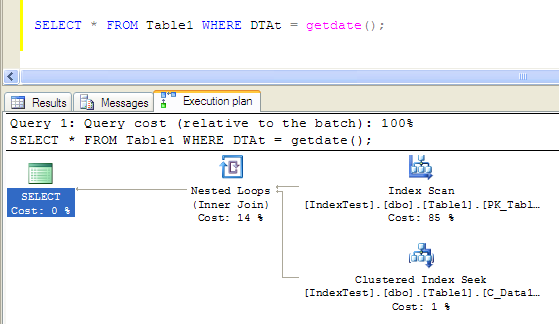
查詢條件落在組合索引的第二個字段上,引起了index scan,效果很不好,執行時間是:
- Table 'Table1'. Scan count 1, logical reads 238, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 16 ms, elapsed time = 22 ms.
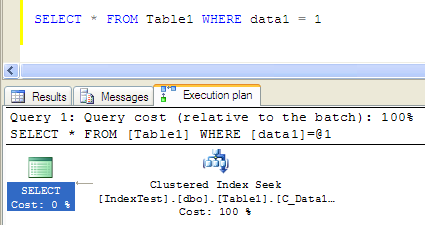
- Table 'Table1'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 0 ms, elapsed time = 1 ms.
Index seek 爲什麼比 Index scan好?
索引掃描也就是遍歷B樹,而seek是B樹查找直接定位。
Index scan多半是出現在索引列在表達式中。數據庫引擎無法直接確定你要的列的值,所以只能掃描整個整個索引進行計算。index seek就要好很多.數據庫引擎只需要掃描幾個分支節點就可以定位到你要的記錄。回過來,如果聚集索引的葉子節點就是記錄,那麼Clustered Index Scan就基本等同於full table scan。
一些優化原則
1、缺省情況下建立的索引是非聚簇索引,但有時它並不是最佳的。在非羣集索引下,數據在物理上隨機存放在數據頁上。合理的索引設計要建立在對各種查詢的分析和預測上。一般來說:
a.有大量重複值、且經常有範圍查詢( > ,< ,> =,< =)和order by、group by發生的列,可考
慮建立羣集索引;
b.經常同時存取多列,且每列都含有重複值可考慮建立組合索引;
c.組合索引要儘量使關鍵查詢形成索引覆蓋,其前導列一定是使用最頻繁的列。索引雖有助於提高性能但不是索引越多越好,恰好相反過多的索引會導致系統低效。用戶在表中每加進一個索引,維護索引集合就要做相應的更新工作。
2、ORDER BY和GROPU BY使用ORDER BY和GROUP BY短語,任何一種索引都有助於SELECT的性能提高。
3、多表操作在被實際執行前,查詢優化器會根據連接條件,列出幾組可能的連接方案並從中找出系統開銷最小的最佳方案。連接條件要充份考慮帶有索引的表、行數多的表;內外表的選擇可由公式:外層表中的匹配行數*內層表中每一次查找的次數確定,乘積最小爲最佳方案。
4、任何對列的操作都將導致表掃描,它包括數據庫函數、計算表達式等等,查詢時要儘可能將操作移至等號右邊。
5、IN、OR子句常會使用工作表,使索引失效。如果不產生大量重複值,可以考慮把子句拆開。拆開的子句中應該包含索引。
Sql的優化原則2:
1、只要能滿足你的需求,應儘可能使用更小的數據類型:例如使用MEDIUMINT代替INT
2、儘量把所有的列設置爲NOT NULL,如果你要保存NULL,手動去設置它,而不是把它設爲默認值。
3、儘量少用VARCHAR、TEXT、BLOB類型
4、如果你的數據只有你所知的少量的幾個。最好使用ENUM類型
使用SQLServer Profiler找出數據庫中性能最差的SQL
首先打開SQLServer Profiler:

然後點擊工具欄“New Trace”,使用默認的模板,點擊RUN。
也許會有報錯:"only TrueType fonts are supported. There id not a TrueType font"。不用怕,點擊Tools菜單->Options,重新選擇一個字體例如Vendana 即可。(這個是微軟的一個bug)
運行起來以後,SQLServer Profiler會監控數據庫的活動,所以最好在你需要監控的數據庫上多做些操作。等覺得差不多了,點擊停止。然後保存trace結果到文件或者table。
這裏保存到Table:在菜單“File”-“Save as ”-“Trace table”,例如輸入一個master數據庫的新的table名:profileTrace,保存即可。
找到最耗時的SQL:
- use master
- select * from profiletrace order by duration desc;
對使用SQLServer Profiler的更多信息可以參考:
http://www.codeproject.com/KB/database/DiagnoseProblemsSQLServer.aspx
使用SQLServer Database Engine Tuning Advisor數據庫引擎優化顧問
使用上述的SQLServer Profiler得到了trace還有一個好處就是可以用到這個優化顧問。用它可以偷點懶,得到SQLServer給您的優化顧問,例如這個表需要加個索引什麼的…
首先打開數據庫引擎優化顧問:
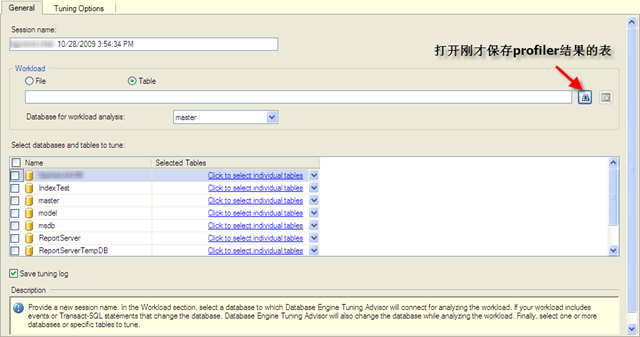
然後打開剛纔profiler的結果(我們存到了master數據庫的profileTrace表):
點擊“start analysis”,運行完成後查看優化建議(圖中最後是建議建立的索引,性能提升72%)

這個方法可以偷點懶,得到SQLServer給您的優化顧問。
索引在數據結構上可以分爲三種B樹索引、位圖索引和散列索引
B樹索引
結構:

特點:
1.索引不存儲null值。
更準確的說,單列索引不存儲null值,複合索引不存儲全爲null的值
索引不能存儲Null,所以對這列採用is null條件時,因爲索引上根本沒Null值,不能利用到索引,只
能全表掃描。
爲什麼索引列不能存Null值呢?將索引列值進行建樹,其中必然涉及到諸多的比較操作。Null值
的特殊性就在於參與的運算大多取值爲null。這樣的話,null值實際上是不能參與進建索引的
過程。也就是說,null值不會像其他取值一樣出現在索引樹的葉子節點上。
B樹索引測試1:NULL是否存在索引上。
create table btree_test(id number,code varchar2(10));
create index idx_btree_test_id on btree_test(id,code);
select object_id from user_objects where object_name='IDX_BTREE_TEST_ID';
alter session set events 'immediate trace name treedump level 59097';
insert into btree_test values(null,null);
alter session set events 'immediate trace name treedump level 59097';
insert into btree_test values(null,'1');
alter session set events 'immediate trace name treedump level 59097';
insert into btree_test values(1,null);
alter session set events 'immediate trace name treedump level 59097';
然後查看轉儲文件,admin\數據庫名\udump
發現這樣的信息:
*** 2013-07-19 14:56:41.827
----- begin tree dump
leaf: 0x140142c 20976684 (0: nrow: 0 rrow: 0)
----- end tree dump
*** 2013-07-19 14:56:54.480
----- begin tree dump
leaf: 0x140142c 20976684 (0: nrow: 1 rrow: 1)
----- end tree dump
*** 2013-07-19 14:57:08.139
----- begin tree dump
leaf: 0x140142c 20976684 (0: nrow: 2 rrow: 2)
----- end tree dump
nrow當前節點所含索引條目的數量(包括delete的條目)
rrow有效的索引條目的數量
可以發現:
插入null,null時,有效的索引條目爲0
插入null,1時, 有效的索引條目爲1
插入1,null時, 有效的索引條目爲2
所以,複合索引只有當要插入的值全爲Null時纔不能放入存入索引中。
也可以這樣看:
SELECT num_rows FROM user_indexes t WHERE t.index_name ='btree_test';
2.不適合鍵值較少的列(重複數據較多的列)。
假如索引列TYPE有5個鍵值,如果有1萬條數據,那麼 WHERE TYPE = 1將訪問表中的2000個數據塊。
再加上訪問索引塊,一共要訪問大於200個的數據塊。
如果全表掃描,假設10條數據一個數據塊,那麼只需訪問1000個數據塊,既然全表掃描訪問的數據塊
少一些,肯定就不會利用索引了。
3.前導模糊查詢不能利用索引(like '%XX'或者like '%XX%')
假如有這樣一列code的值爲'AAA','AAB','BAA','BAB' ,如果where code like '%AB'條件,由於前面是
模糊的,所以不能利用索引的順序,必須一個個去找,看是否滿足條件。這樣會導致全索引掃描或者全表掃
描。如果是這樣的條件where code like 'A % ',就可以查找CODE中A開頭的CODE的位置,當碰到B開頭的
數據時,就可以停止查找了,因爲後面的數據一定不滿足要求。這樣就可以利用索引了。
位圖索引
就是用位圖表示的索引,對列的每個鍵值建立一個位圖。
如test表中有state這樣一列,數據如下:
10 20 30 20 10 30 10 30 20 30
那麼會建立三個位圖,如下:
BLOCK1 KEY=10 1 0 0 0 1 0 1 0 0 0
BLOCK2 KEY=20 1 0 0 0 1 0 1 0 0 0
BLOCK3 KEY=30 1 0 0 0 1 0 1 0 0 0
位圖索引特點:
1.相對於B*Tree索引,佔用的空間非常小,創建和使用非常快。
位圖索引由於只存儲鍵值的起止Rowid和位圖,佔用的空間非常少。
2.不適合鍵值較多的列。
3.不適合update、insert、delete頻繁的列。
4.可以存儲null值。
B*Tree索引由於不記錄空值,當基於is null的查詢時,會使用全表掃描,而對位圖索引列進
行is null查詢時,則可以使用索引。
5.當select count(XX) 時,可以直接訪問索引中一個位圖就快速得出統計數據。
6.當根據鍵值做and,or或 in(x,y,..)查詢時,直接用索引的位圖進行或運算,快速得出結果行數
據。
散列索引
散列索引是根據HASH算法來構建的索引,所以檢索速度很快,但不能範圍查詢。
散列索引的特點
1.只適合等值查詢(包括= <> 和in),不適合模糊或範圍查詢