




概括下最近看的博客和論文,整理下基於深度學習的目標檢測方面的知識點:
一. RCNN (Regions with CNN) RBG (2014年)
1. 候選區域選擇(region proposal), 用到了SelectiveSearch
2. 對於每個區域利用CNN抽取一個固定長度的特徵向量(Alexnet, 基於Caffe進行的代碼開發)
3. 再對每個區域利用SVM進行目標分類。同時做邊界迴歸。
技巧:採用在ImageNet上已經訓練好的模型,然後在PASCAL VOC數據集上進行fine-tune。做遷移學習
Selective search產生的候選區域大小不一,爲了與Alexnet兼容,R-CNN採用了非常暴力的手段,無視候選區域的大小和形狀,統一變換到227*227的尺寸。變換時可以先對這些區域進行膨脹處理,box周圍附加p個像素,這裏p=16
存在的問題:
1. 多個候選區域對應的圖像需要預先提取,佔用較大的磁盤空間
2. crop/warp(歸一化)產生的物體截斷或拉伸,會導致輸入CNN的信息丟失
3. 每一個ProposalRegion都需要進行CNN網絡計算,多數是互相重疊,重疊部分會被多次重複提取feature
二. Fast RCNN
1. 和SPPnet做比較,Fast-RCNN訓練速度達3倍。測試速度達10倍。
2. 網絡首先做的就是用一些卷積神經網絡以及最大值池化層等圖片進行特徵提取
3. 利用感興趣區域池化層從特徵圖中提取一個特徵向量,在全連接層末尾產生兩個分支
一個產生softmax來估計K個類別及背景的概率(K+1類別的softmax概率),另外一個層輸出四個實數數據,確定邊界框
4. ROI MAX Pooling可以將任意的proposal轉化成固定的HxW的區域。
5. 預訓練網絡的初始化
6. Fast-RCNN,整個網絡權重參數進行反向傳播訓練是Fast-RCNN網絡獨有的能力,SPPnet網絡不能更新金子塔前面的卷積網絡的參數。
7.使用多任務損失L來對分類和邊界框進行聯合優化
8. 不用限定網絡的輸入結構,不管特徵圖的大小如何,進入到空間金子塔池化層後,變成固定大小的值
三. SPP-Net

SPP的結構如上圖所示,將最後一個卷積層後緊跟SPP層,作爲全連接層的輸入。至此,網絡不僅可對任意長寬比的圖像進行處理,而且可對任意尺度的圖像進行處理。圖像就不需要reshape了。(如果固定網絡輸入的話,要麼選擇crop策略,要麼選擇warp策略,crop就是從一個大圖扣出網絡輸入大小的patch(比如227×227),而warp則是把一個bounding box的內容resize成227×227。這兩種方法都存在着丟失或者扭曲原始圖像信息的缺陷。這樣CNN獲取的特徵也就受到了限制,從而導致後續分類/預測的泛化能力不夠。)
SPP已有一定的速度提升,它在ConvNet的最後一個卷積層才提取proposal,但是依然有不足之處。和R-CNN一樣,它的訓練要經過多個階段,特徵也要存在磁盤中,另外,SPP中的微調只更新spp層後面的全連接層,對很深的網絡這樣肯定是不行的。
四. Faster-RCNN(https://zhuanlan.zhihu.com/p/31426458)
雖然Fast-Rcnn基於R-CNN有了很大的改進,但是Fast-Rcnn仍然是基於Selective Search方法進行提取region proposal,而Selective Search方法提取region proposal的計算是無法用GPU進行的,無法藉助GPU的高度並行運算能力,所以效率極低。而且選取2000個候選區域,也加重了後面深度學習的處理壓力。那Faster-RCNN在吸取了Fast-RCNN的特點的前提下,採用共享的卷積網組成RPN網絡(Region Proposal Network),用RPN直接預測出候選區域建議框,數據限定在300個,RPN的預測絕大部分在GPU中完成,而且卷積網和Fast-RCNN部分共享,因此大幅度提升了目標檢測的速度。
可以看成:Faster-RCNN = RPN(區域生成網絡)+ Fast-RCNN,用RPN網絡代替Fast-RCNN中的Selective Search是Faster-RCNN的核心思想。
RPN網絡首先經過3x3卷積,再分別生成positive anchors和對應bounding box regression偏移量,然後計算出proposals;而Roi Pooling層則利用proposals從feature maps中提取proposal feature送入後續全連接和softmax網絡作classification(即分類proposal到底是什麼object)


假設在conv5 feature map中每個點上有k個anchor(默認k=9),而每個anhcor要分positive和negative,所以每個點由256d feature轉化爲cls=2k scores;而每個anchor都有(x, y, w, h)對應4個偏移量,所以reg=4k coordinates
補充一點,全部anchors拿去訓練太多了,訓練程序會在合適的anchors中隨機選取128個postive anchors+128個negative anchors進行訓練(什麼是合適的anchors下文5.1有解釋)
其實RPN最終就是在原圖尺度上,設置了密密麻麻的候選Anchor。然後用cnn去判斷哪些Anchor是裏面有目標的positive anchor,哪些是沒目標的negative anchor。所以,僅僅是個二分類而已!
該1x1卷積的caffe prototxt定義如下:
layer {
name: "rpn_cls_score"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_cls_score"
convolution_param {
num_output: 18 # 2(positive/negative) * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
}
}
可以看到其num_output=18,也就是經過該卷積的輸出圖像爲WxHx18大小(注意第二章開頭提到的卷積計算方式)。這也就剛好對應了feature maps每一個點都有9個anchors,同時每個anchors又有可能是positive和negative,所有這些信息都保存WxHx(9*2)大小的矩陣。爲何這樣做?後面接softmax分類獲得positive anchors,也就相當於初步提取了檢測目標候選區域box(一般認爲目標在positive anchors中)。

Faster R-CNN的訓練,是在已經訓練好的model(如VGG_CNN_M_1024,VGG,ZF)的基礎上繼續進行訓練。實際中訓練過程分爲6個步驟:
- 在已經訓練好的model上,訓練RPN網絡,對應stage1_rpn_train.pt
- 利用步驟1中訓練好的RPN網絡,收集proposals,對應rpn_test.pt
- 第一次訓練Fast RCNN網絡,對應stage1_fast_rcnn_train.pt
- 第二訓練RPN網絡,對應stage2_rpn_train.pt
- 再次利用步驟4中訓練好的RPN網絡,收集proposals,對應rpn_test.pt
- 第二次訓練Fast RCNN網絡,對應stage2_fast_rcnn_train.pt
可以看到訓練過程類似於一種“迭代”的過程,不過只循環了2次。至於只循環了2次的原因是應爲作者提到:"A similar alternating training can be run for more iterations, but we have observed negligible improvements",即循環更多次沒有提升了。接下來本章以上述6個步驟講解訓練過程。
五. OverFeat《 OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks 》
本篇博文主要講解來自2014年ICLR的經典圖片分類、定位物體檢測overfeat算法:《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks》,至今爲止這篇paper,已然被引用了幾百次,把圖片分類、定位、檢測一起搞,可見算法牛逼之處非同一般啊。
OverFeat就是一種特徵提取算子,就相當於SIFT,HOG等這些算子一樣。這篇文獻充分利用了卷積神經網絡的特徵提取功能,它把分類過程中,提取到的特徵,同時又用於定位檢測等各種任務,只需要改變網絡的最後幾層,就可以實現不同的任務,而不需要從頭開始訓練整個網絡的參數。
本文的核心操作(FCN + offset max-pooling)
網絡最後的輸出是一張2*2大小的圖片。這個時候,我們就可以發現採用FCN網絡,可以輸入任意大小的圖片。同時需要注意的是網絡最後輸出的圖片大小不在是一個1*1大小的圖片,而是一個與輸入圖片大小息息相關的一張圖片了。

以往的CNN中,一般我們只用了△=0,得到池化結果後,就送入了下一層。於是文獻的方法是,把上面的△=0、△=1、△=2的三種組合方式的池化結果,分別送入網絡的下一層。這樣的話,我們網絡在最後輸出的時候,就會出現3種預測結果了。
如果是2維圖片的話,那麼(△x,△y)就會有9種取值情況(3*3);如果我們在做圖片分類的時候,在網絡的某一個池化層加入了這種offset 池化方法,然後把這9種池化結果,分別送入後面的網絡層,最後我們的圖片分類輸出結果就可以得到9個預測結果(每個類別都可以得到9種概率值,然後我們對每個類別的9種概率,取其最大值,做爲此類別的預測概率值)。優中選優,避免因爲池化而漏掉某些信息,尤其是邊緣的信息。
Alexnet在測試階段的時候,採用了對輸入圖片的四個角落和中心位置進行裁剪,得到10個大小爲網路喲輸入大小的圖片,分別進行預測,分別得到結果,選出最好結果(平均或最大池化),這最後的結果就是類似對應於上面2*2的預測圖選一個最優值。這個2*2的每個像素點,就類似於對應於一個角落裁剪下來的圖片預測分類結果。只不過Alexnet把這4個像素點,相加在一起,求取平均值,作爲該類別的概率值。

overfeat這篇文獻的圖片分類算法,在訓練階段採用與Alexnet相同的訓練方式,然而在測試階段可是差別很大,overfeat就是把採用FCN的思想把全連接層看成了卷積層,讓我們在網絡測試階段可以輸入任意大小的圖片。這就是文獻最大的創新點(overfeat的方法不是裁剪出10張224*224的圖片進行結果預測平均,具體方法請看下面繼續詳細講解)。
overfeat把網絡的第一層到第五層看做是特徵提取層,然後不同的任務共享這個特徵提取層。基本用了同一個網絡架構模型(特徵提取層相同,分類迴歸層根據不同任務稍作修改、訓練)、同時共享基礎特徵。論文的網絡分爲兩個版本,一個快速版,一個精確版。下圖是精確版的網絡結構圖:
訓練完上面所說的網絡之後,在測試階段,文章不再是用一張221*221大小的圖片了作爲網絡的輸入,而是用了6張大小都不相同的圖片,也就是所謂的多尺度輸入預測,如下表格所示:

測試階段網絡輸入圖片大小分別是245*245,281*317……461*569。
然後當網絡前向傳導到layer 5的時候,就使出了FCN和offset pooling一記組合拳。以輸入一張圖片爲例(6張圖片的計算方法都相同),講解layer 5後面的過程:
(1)layer-5 pre-pool【輸入是17*17,輸出是(5*5)*(3*3)】:
通過大小爲(3,3)的池化進行池化,然後△x=0、1、2,△y=0、1、2,這樣我們可以得到對於每一張特徵圖,我們都可以得到9幅池化結果圖。以上面表格中的sacle1爲例,layer-5 pre-pool大小是17*17,經過池化後,大小就是5*5,然後有3*3張結果圖(不同offset得到的結果)。
(2)
layer-5 post-pool【輸入是(5*5)*(3*3),輸出是(1*1)*(3*3)*C】:
在訓練的時候,全連接層輸入的大小是4096*(5*5),然後經過FC層,得到4096*(1*1)。但是現在輸入的是各種不同大小的圖片,因此從第5層後採用FCN的招式(用卷積層代替FC層),讓網絡繼續前向傳導。我們從layer-5 post-pool到第六層的時候,如果把全連接看成是卷積,那麼其實這個時候卷積核的大小爲5*5,因爲訓練的時候,layer-5 post-pool得到的結果是5*5。因此在預測分類的時候,假設layer-5 post-pool 得到的是7*9(上面表格中的scale 3),經過5*5的卷積核進行卷積後,那麼它將得到(7-5+1)*(9-5+1)=3*5的輸出。然後我們就只需要在後面把它們拉成一維向量擺放就ok了,這樣在一個尺度上,我們可以得到一個C*N個預測值向量,每一列就表示圖片屬於某一類別的概率值,共C列,然後我們求取每一列(類別)的N個待選概率中的最大值作爲本尺度的這個類別的概率值。
從上面過程,我們可以看到整個網絡分成兩部分:layer 1~5這五層我們把它稱之爲特徵提取層;layer 6~output我們把它們稱之爲分類層。具體流程示意圖如下:
以一維爲例,offset池化就是移動一定的位置再池化,(b)中Δ=0,1,2 就可以表示可以做三種池化,得到三個結果,因爲圖像是二維的,所以最後會得到3*3也就是9種池化結果,最後對於每個類別就有9個結果,可以對這些結果集成預測(下圖的例子中只考慮一維的所以圖中最後會得到三個結果,紅藍綠三種顏色表示三種池化後得到的結果)圖中(c)表示進行3*3池化後得到6*6的圖(6個格子)。(d)表示經過5*5的全卷積得到2*2的圖(2個格子)。e表示把位置信息(長度爲2)和offset方式(3種)交錯後得到的最後的輸出圖。
在實際的二維圖像處理中,上述這個操作會對重複6*2也就是12次,其中6代表6個scale,如下圖所示的6個不同的scale,而2表示水平翻轉後會得到兩個圖。在這12次裏面的每一次,對位置信息取最大,以Scale2爲例,最後大小爲6x9xC,就在這6x9個值中取最大。那麼就會得到12個長度爲C的向量,12個向量加起來取平均,得到一個長度爲C的向量,然後求Top1或Top5,得到最後的結果。
用於定位任務的時候,就把分類層(上面的layer 6~output)給重新設計,把分類改成迴歸問題,然後在各種不同尺度上訓練預測物體的bounding box。把用分類學習的特徵提取層的參數固定下來,然後繼續訓練後面的迴歸層的參數,網絡包含了4個輸出,對應於bounding box的上左上角點和右下角點,然後損失函數採用歐式距離L2損失函數。
六. MobileNet V1
這篇論文是谷歌在2017年提出了,專注於移動端或者嵌入式設備中的輕量級CNN網絡。該論文最大的創新點是,提出了深度可分離卷積(depthwise separable convolution)。
首先,我們分析一下傳統卷積的運算過程,請參考第一個動圖或者這篇博客。可以看出,傳統卷積分成兩步,每個卷積核與每張特徵圖進行按位相成然後進行相加,此時,計算量爲DF∗DF∗DK∗DK∗M∗NDF∗DF∗DK∗DK∗M∗N,其中DFDF爲特徵圖尺寸,DKDK爲卷積核尺寸,M爲輸入通道數,N爲輸出通道數。
然後,重點介紹一下深度可分離卷積。深度可分離卷積將傳統卷積的兩步進行分離開來,分別是depthwise和pointwise。從下面的圖可以看出,首先按照通道進行計算按位相乘的計算,此時通道數不改變;然後依然得到將第一步的結果,使用1*1的卷積核進行傳統的卷積運算,此時通道數可以進行改變。使用了深度可分離卷積,其計算量爲DK∗DK∗M∗DF∗DF+1∗1∗M∗N∗DF∗DFDK∗DK∗M∗DF∗DF+1∗1∗M∗N∗DF∗DF。

通過深度可分離卷積,計算量將會下降1N+1D2K1N+1DK2,當DK=3DK=3時,深度可分離卷積比傳統卷積少8到9倍的計算量。
這種深度可分離卷積雖然很好的減少計算量,但同時也會損失一定的準確率。從下圖可以看到,使用傳統卷積的準確率比深度可分離卷積的準確率高約1%,但計算量卻增大了9倍。

最後給出v1的整個模型結構,該網絡有28層。可以看出,該網絡基本去除了pool層,使用stride來進行降採樣(難道是因爲pool層的速度慢?)。
- depthwise後接BN層和RELU6,pointwise後也接BN層和RELU6,如下圖所示(圖中應該是RELU6)。左圖是傳統卷積,右圖是深度可分離卷積。更多的ReLU6,增加了模型的非線性變化,增強了模型的泛化能力。

- v1中使用了RELU6作爲激活函數,這個激活函數在float16/int8的嵌入式設備中效果很好,能較好地保持網絡的魯棒性。

- v1還給出了2個超參,寬度乘子αα和分辨率乘子ββ,通過這兩個超參,可以進一步縮減模型,文章中也給出了具體的試驗結果。此時,我們反過來看,擴大寬度和分辨率,都能提高網絡的準確率,但如果單一提升一個的話,準確率很快就會達到飽和,這就是2019年穀歌提出efficientnet的原因之一,動態提高深度、寬度、分辨率來提高網絡的準確率。
mobilenet v2發表與2018年,時隔一年,谷歌的又一力作。V2在V1的基礎上,引入了Inverted Residuals和Linear Bottlenecks。
爲什麼要引入這兩個模塊呢?參考這篇文章,有人發現,在使用V1的時候,發現depthwise部分的卷積核容易費掉,即卷積核大部分爲零。作者認爲這是ReLU引起的。文章的一個章節來介紹這個理論,但小弟水平有限,還理解不了。
簡單來說,就是當低維信息映射到高維,經過ReLU後再映射回低維時,若映射到的維度相對較高,則信息變換回去的損失較小;若映射到的維度相對較低,則信息變換回去後損失很大,如下圖所示。因此,認爲對低維度做ReLU運算,很容易造成信息的丟失。而在高維度進行ReLU運算的話,信息的丟失則會很少。另外一種解釋是,高維信息變換回低維信息時,相當於做了一次特徵壓縮,會損失一部分信息,而再進過relu後,損失的部分就更加大了。作者爲了這個問題,就將ReLU替換成線性激活函數。

Inverted Residuals
這個可以翻譯成“倒殘差模塊”。什麼意思呢?我們來對比一下殘差模塊和倒殘差模塊的區別。
- 殘差模塊:輸入首先經過1*1的卷積進行壓縮,然後使用3*3的卷積進行特徵提取,最後在用1*1的卷積把通道數變換回去。整個過程是“壓縮-卷積-擴張”。這樣做的目的是減少3*3模塊的計算量,提高殘差模塊的計算效率。
- 倒殘差模塊:輸入首先經過1*1的卷積進行通道擴張,然後使用3*3的depthwise卷積,最後使用1*1的pointwise卷積將通道數壓縮回去。整個過程是“擴張-卷積-壓縮”。爲什麼這麼做呢?因爲depthwise卷積不能改變通道數,因此特徵提取受限於輸入的通道數,所以將通道數先提升上去。文中的擴展因子爲6。

Linear Bottleneck
這個模塊是爲了解決一開始提出的那個低維-高維-低維的問題,即將最後一層的ReLU替換成線性激活函數,而其他層的激活函數依然是ReLU6。
發表於2019年,該v3版本結合了v1的深度可分離卷積、v2的Inverted Residuals和Linear Bottleneck、SE模塊,利用NAS(神經結構搜索)來搜索網絡的配置和參數。這種方式已經遠遠超過了人工調參了,太恐怖了。
v3在v2的版本上有以下的改進:
- 作者發現,計算資源耗費最多的層是網絡的輸入和輸出層,因此作者對這兩部分進行了改進。如下圖所示,上面是v2的最後輸出幾層,下面是v3的最後輸出的幾層。可以看出,v3版本將平均池化層提前了。在使用1×11×1卷積進行擴張後,就緊接池化層-激活函數,最後使用1×11×1的卷積進行輸出。通過這一改變,能減少10ms的延遲,提高了15%的運算速度,且幾乎沒有任何精度損失。其次,對於v2的輸入層,通過3×33×3卷積將輸入擴張成32維。作者發現使用ReLU或者switch激活函數,能將通道數縮減到16維,且準確率保持不變。這又能節省3ms的延時。
七. vgg16(https://www.cnblogs.com/lfri/p/10493408.html)
VGG中根據卷積核大小和卷積層數目的不同,可分爲A,A-LRN,B,C,D,E共6個配置(ConvNet Configuration),其中以D,E兩種配置較爲常用,分別稱爲VGG16和VGG19。
下圖給出了VGG的六種結構配置:
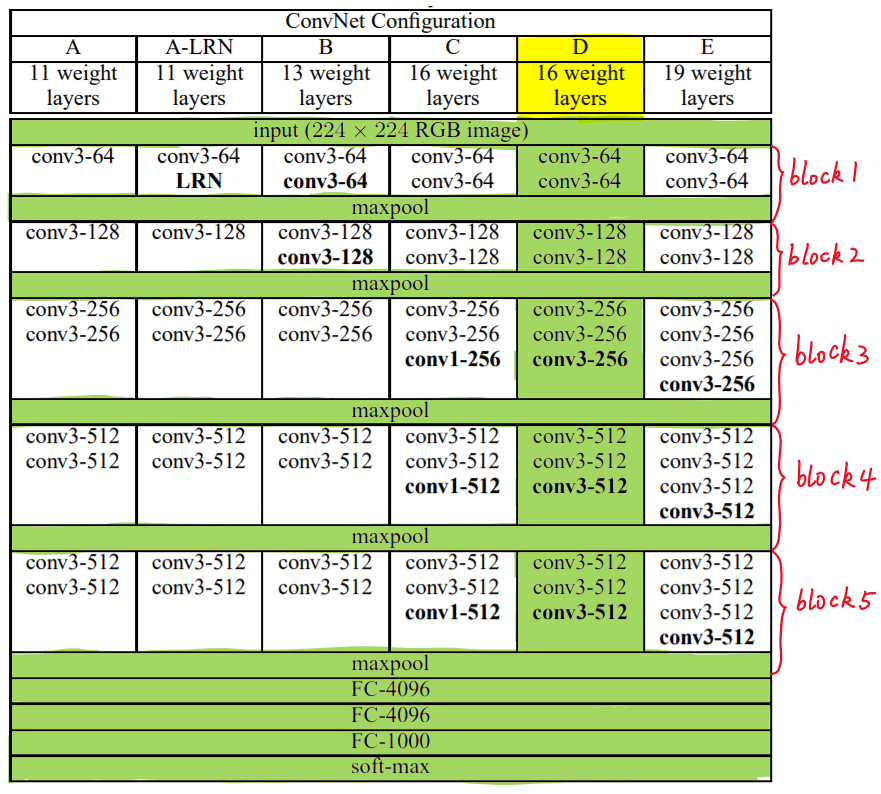
上圖中,每一列對應一種結構配置。例如,圖中綠色部分即指明瞭VGG16所採用的結構。
我們針對VGG16進行具體分析發現,VGG16共包含:
- 13個卷積層(Convolutional Layer),分別用conv3-XXX表示
- 3個全連接層(Fully connected Layer),分別用FC-XXXX表示
- 5個池化層(Pool layer),分別用maxpool表示
其中,卷積層和全連接層具有權重係數,因此也被稱爲權重層,總數目爲13+3=16,這即是
VGG16中16的來源。(池化層不涉及權重,因此不屬於權重層,不被計數)。

我們注意圖1右側,VGG16的卷積層和池化層可以劃分爲不同的塊(Block),從前到後依次編號爲Block1~block5。每一個塊內包含若干卷積層和一個池化層。例如:Block4包含:
- 3個卷積層,conv3-512
- 1個池化層,maxpool
並且同一塊內,卷積層的通道(channel)數是相同的,例如:
block2中包含2個卷積層,每個卷積層用conv3-128表示,即卷積核爲:3x3x3,通道數都是128block3中包含3個卷積層,每個卷積層用conv3-256表示,即卷積核爲:3x3x3,通道數都是256
下面給出按照塊劃分的VGG16的結構圖,可以結合圖2進行理解:
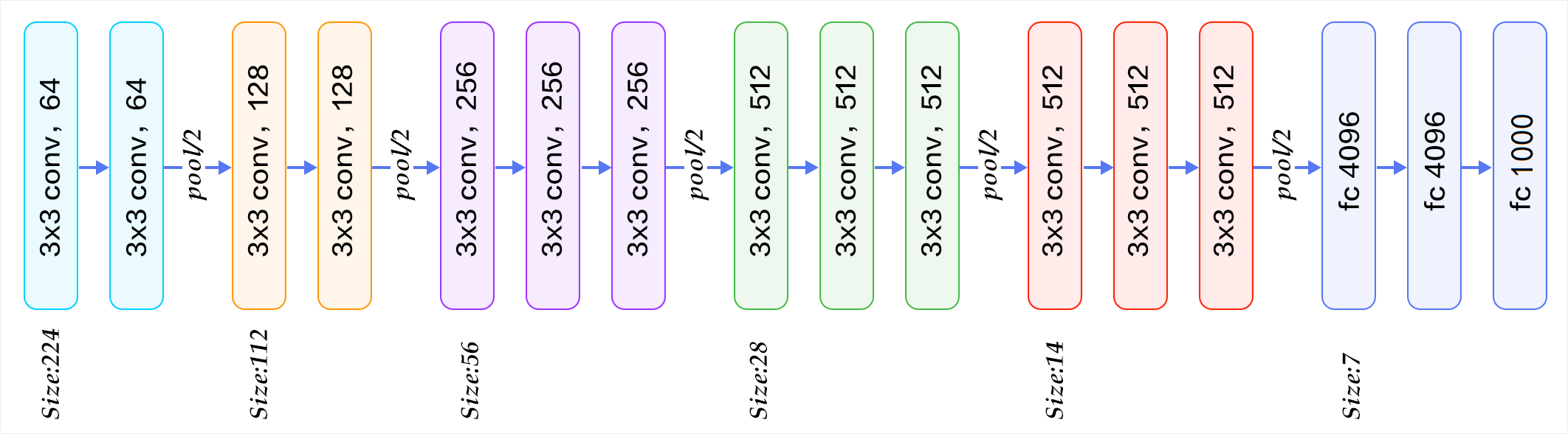
VGG的輸入圖像是 224x224x3 的圖像張量(tensor),隨着層數的增加,後一個塊內的張量相比於前一個塊內的張量:
- 通道數翻倍,由64依次增加到128,再到256,直至512保持不變,不再翻倍
- 高和寬變減半,由 224→112→56→28→14→7
八. LeNet
LeNet是最早的卷積神經網絡之一[1]。1998年,Yan LeCun第一次將LeNet卷積神經網絡應用到圖像分類上,在手寫數字識別任務中取得了巨大成功。LeNet通過連續使用卷積和池化層的組合提取圖像特徵,其架構如 圖1所示,這裏展示的是作者論文中的LeNet-5模型:
圖1:LeNet模型網絡結構示意圖
第一輪卷積和池化:卷積提取圖像中包含的特徵模式(激活函數使用sigmoid),圖像尺寸從32減小到28。經過池化層可以降低輸出特徵圖對空間位置的敏感性,圖像尺寸減到14。第二輪卷積和池化:卷積操作使圖像尺寸減小到10,經過池化後變成5。第三輪卷積:將經過第3次卷積提取到的特徵圖輸入到全連接層。第一個全連接層的輸出神經元的個數是64,第二個全連接層的輸出神經元個數是分類標籤的類別數,對於手寫數字識別其大小是10。然後使用Softmax激活函數即可計算出每個類別的預測概率。


九. Alexnet
AlexNet與LeNet相比,具有更深的網絡結構,包含5層卷積和3層全連接,同時使用瞭如下三種方法改進模型的訓練過程:
數據增多:深度學習中常用的一種處理方式,通過對訓練隨機加一些變化,比如平移、縮放、裁剪、旋轉、翻轉或者增減亮度等,產生一系列跟原始圖片相似但又不完全相同的樣本,從而擴大訓練數據集。通過這種方式,可以隨機改變訓練樣本,避免模型過度依賴於某些屬性,能從一定程度上抑制過擬合。使用Dropout抑制過擬合使用ReLU激活函數少梯度消失現象


第一層:卷積層1,輸入爲 224×224×3 224 \times 224 \times 3224×224×3的圖像,卷積核的數量爲96,論文中兩片GPU分別計算48個核; 卷積核的大小爲 11×11×3 11 \times 11 \times 311×11×3; stride = 4, stride表示的是步長, pad = 0, 表示不擴充邊緣;
卷積後的圖形大小是怎樣的呢?
wide = (224 + 2 * padding - kernel_size) / stride + 1 = 54
height = (224 + 2 * padding - kernel_size) / stride + 1 = 54
dimention = 96
然後進行 (Local Response Normalized), 後面跟着池化pool_size = (3, 3), stride = 2, pad = 0 最終獲得第一層卷積的feature map
最終第一層卷積的輸出爲
第二層:卷積層2, 輸入爲上一層卷積的feature map, 卷積的個數爲256個,論文中的兩個GPU分別有128個卷積核。卷積核的大小爲:5×5×48 5 \times 5 \times 485×5×48; pad = 2, stride = 1; 然後做 LRN, 最後 max_pooling, pool_size = (3, 3), stride = 2;
第三層:卷積3, 輸入爲第二層的輸出,卷積核個數爲384, kernel_size = (3×3×256 3 \times 3 \times 2563×3×256), padding = 1, 第三層沒有做LRN和Pool
第四層:卷積4, 輸入爲第三層的輸出,卷積核個數爲384, kernel_size = (3×3 3 \times 33×3), padding = 1, 和第三層一樣,沒有LRN和Pool
第五層:卷積5, 輸入爲第四層的輸出,卷積核個數爲256, kernel_size = (3×3 3 \times 33×3), padding = 1。然後直接進行max_pooling, pool_size = (3, 3), stride = 2;
第6,7,8層是全連接層,每一層的神經元的個數爲4096,最終輸出softmax爲1000,因爲上面介紹過,ImageNet這個比賽的分類個數爲1000。全連接層中使用了RELU和Dropout。
十. GoogLeNet
GoogLeNet是谷歌(Google)研究出來的深度網絡結構,爲什麼不叫“GoogleNet”,而叫“GoogLeNet”,據說是爲了向“LeNet”致敬,因此取名爲“GoogLeNet”
一般來說,提升網絡性能最直接的辦法就是增加網絡深度和寬度,深度指網絡層次數量、寬度指神經元數量。但這種方式存在以下問題:
(1)參數太多,如果訓練數據集有限,很容易產生過擬合;
(2)網絡越大、參數越多,計算複雜度越大,難以應用;
(3)網絡越深,容易出現梯度彌散問題(梯度越往後穿越容易消失),難以優化模型。
所以,有人調侃“深度學習”其實是“深度調參”。
解決這些問題的方法當然就是在增加網絡深度和寬度的同時減少參數,爲了減少參數,自然就想到將全連接變成稀疏連接。但是在實現上,全連接變成稀疏連接後實際計算量並不會有質的提升,因爲大部分硬件是針對密集矩陣計算優化的,稀疏矩陣雖然數據量少,但是計算所消耗的時間卻很難減少。
那麼,有沒有一種方法既能保持網絡結構的稀疏性,又能利用密集矩陣的高計算性能。大量的文獻表明可以將稀疏矩陣聚類爲較爲密集的子矩陣來提高計算性能,就如人類的大腦是可以看做是神經元的重複堆積,因此,GoogLeNet團隊提出了Inception網絡結構,就是構造一種“基礎神經元”結構,來搭建一個稀疏性、高計算性能的網絡結構。

該結構將CNN中常用的卷積(1x1,3x3,5x5)、池化操作(3x3)堆疊在一起(卷積、池化後的尺寸相同,將通道相加),一方面增加了網絡的寬度,另一方面也增加了網絡對尺度的適應性。
網絡卷積層中的網絡能夠提取輸入的每一個細節信息,同時5x5的濾波器也能夠覆蓋大部分接受層的的輸入。還可以進行一個池化操作,以減少空間大小,降低過度擬合。在這些層之上,在每一個卷積層後都要做一個ReLU操作,以增加網絡的非線性特徵。
然而這個Inception原始版本,所有的卷積核都在上一層的所有輸出上來做,而那個5x5的卷積核所需的計算量就太大了,造成了特徵圖的厚度很大,爲了避免這種情況,在3x3前、5x5前、max pooling後分別加上了1x1的卷積核,以起到了降低特徵圖厚度的作用,這也就形成了Inception v1的網絡結構,如下圖所示:

1x1的卷積核有什麼用呢?
1x1卷積的主要目的是爲了減少維度,還用於修正線性激活(ReLU)。比如,上一層的輸出爲100x100x128,經過具有256個通道的5x5卷積層之後(stride=1,pad=2),輸出數據爲100x100x256,其中,卷積層的參數爲128x5x5x256= 819200。而假如上一層輸出先經過具有32個通道的1x1卷積層,再經過具有256個輸出的5x5卷積層,那麼輸出數據仍爲爲100x100x256,但卷積參數量已經減少爲128x1x1x32 + 32x5x5x256= 204800,大約減少了4倍。

GoogLeNet網絡結構明細表解析如下:
0、輸入
原始輸入圖像爲224x224x3,且都進行了零均值化的預處理操作(圖像每個像素減去均值)。
1、第一層(卷積層)
使用7x7的卷積核(滑動步長2,padding爲3),64通道,輸出爲112x112x64,卷積後進行ReLU操作
經過3x3的max pooling(步長爲2),輸出爲((112 - 3+1)/2)+1=56,即56x56x64,再進行ReLU操作
2、第二層(卷積層)
使用3x3的卷積核(滑動步長爲1,padding爲1),192通道,輸出爲56x56x192,卷積後進行ReLU操作
經過3x3的max pooling(步長爲2),輸出爲((56 - 3+1)/2)+1=28,即28x28x192,再進行ReLU操作
3a、第三層(Inception 3a層)
分爲四個分支,採用不同尺度的卷積核來進行處理
(1)64個1x1的卷積核,然後RuLU,輸出28x28x64
(2)96個1x1的卷積核,作爲3x3卷積核之前的降維,變成28x28x96,然後進行ReLU計算,再進行128個3x3的卷積(padding爲1),輸出28x28x128
(3)16個1x1的卷積核,作爲5x5卷積核之前的降維,變成28x28x16,進行ReLU計算後,再進行32個5x5的卷積(padding爲2),輸出28x28x32
(4)pool層,使用3x3的核(padding爲1),輸出28x28x192,然後進行32個1x1的卷積,輸出28x28x32。
將四個結果進行連接,對這四部分輸出結果的第三維並聯,即64+128+32+32=256,最終輸出28x28x256
3b、第三層(Inception 3b層)
(1)128個1x1的卷積核,然後RuLU,輸出28x28x128
(2)128個1x1的卷積核,作爲3x3卷積核之前的降維,變成28x28x128,進行ReLU,再進行192個3x3的卷積(padding爲1),輸出28x28x192
(3)32個1x1的卷積核,作爲5x5卷積核之前的降維,變成28x28x32,進行ReLU計算後,再進行96個5x5的卷積(padding爲2),輸出28x28x96
(4)pool層,使用3x3的核(padding爲1),輸出28x28x256,然後進行64個1x1的卷積,輸出28x28x64。
將四個結果進行連接,對這四部分輸出結果的第三維並聯,即128+192+96+64=480,最終輸出輸出爲28x28x480
第四層(4a,4b,4c,4d,4e)、第五層(5a,5b)……,與3a、3b類似,在此就不再重複。
GoogLeNet憑藉其優秀的表現,得到了很多研究人員的學習和使用,因此GoogLeNet團隊又對其進行了進一步地發掘改進,產生了升級版本的GoogLeNet。
GoogLeNet設計的初衷就是要又準又快,而如果只是單純的堆疊網絡雖然可以提高準確率,但是會導致計算效率有明顯的下降,所以如何在不增加過多計算量的同時提高網絡的表達能力就成爲了一個問題。
Inception V2版本的解決方案就是修改Inception的內部計算邏輯,提出了比較特殊的“卷積”計算結構。

降低特徵圖大小
一般情況下,如果想讓圖像縮小,可以有如下兩種方式:
先池化再作Inception卷積,或者先作Inception卷積再作池化。但是方法一(左圖)先作pooling(池化)會導致特徵表示遇到瓶頸(特徵缺失),方法二(右圖)是正常的縮小,但計算量很大。爲了同時保持特徵表示且降低計算量,將網絡結構改爲下圖,使用兩個並行化的模塊來降低計算量(卷積、池化並行執行,再進行合併)

Inception V3一個最重要的改進是分解(Factorization),將7x7分解成兩個一維的卷積(1x7,7x1),3x3也是一樣(1x3,3x1),這樣的好處,既可以加速計算,又可以將1個卷積拆成2個卷積,使得網絡深度進一步增加,增加了網絡的非線性(每增加一層都要進行ReLU)。
另外,網絡輸入從224x224變爲了299x299。
Inception V4研究了Inception模塊與殘差連接的結合。ResNet結構大大地加深了網絡深度,還極大地提升了訓練速度,同時性能也有提升(ResNet的技術原理介紹見本博客之前的文章:大話深度殘差網絡ResNet)。
Inception V4主要利用殘差連接(Residual Connection)來改進V3結構,得到Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4網絡。
ResNet的殘差結構如下:
將該結構與Inception相結合,變成下圖:
通過20個類似的模塊組合,Inception-ResNet構建如下:

原文鏈接:https://blog.csdn.net/Gentleman_Qin/article/details/84836122
以上參考博客https://blog.csdn.net/Gentleman_Qin/article/details/84836122