




1.switch支持的參數類型?
java5之前支持char、short、int、byte,java5又支持了enum類型,java7及以後再支持String類型,long類型都不支持
|
|
int |
short |
byte |
char |
enum |
String |
Long |
|
Java5以前 |
√ |
√ |
√ |
√ |
|
|
|
|
Java5-java7 |
√ |
√ |
√ |
√ |
√ |
|
|
|
Java7及以後 |
√ |
√ |
√ |
√ |
√ |
√ |
|
2. 八種基本數據及封裝類
|
基本數據類型 |
int(32) |
short(16) |
byte(8) |
char(16) |
boolean(2) |
float(32) |
long(64) |
double(64) |
|
封裝類 |
Integer |
Short |
Byte |
Character |
Boolean |
Float |
Long |
Double |
區別:
-
包裝類型可以爲 null,而基本類型不可以(數據庫的查詢結果可能是 null,如果使用基本類型的話,因爲要自動拆箱(將包裝類型轉爲基本類型,比如說把 Integer 對象轉換成 int 值),就會拋出
NullPointerException的異常。)
2. 包裝類型可用於泛型,而基本類型不可以(因爲泛型在編譯時只保留原始類型,而原始類型只能是 Object 類及其子類——基本類型不是Object及子類,因此會報錯。)
3. 基本類型比包裝類型更高效(基本類型在棧中直接存儲的具體數值,而包裝類型則存儲的是堆中的引用,需佔較多的內存,而且對於多次用到的數值,使用包裝類型就顯得麻煩)
4. 兩個包裝類型的值相同時,卻並不相等(兩個包裝類型指向了不同的地址)
補充:自動拆箱與包裝
把基本類型轉換成包裝類型的過程叫做裝箱(boxing)。反之,把包裝類型轉換成基本類型的過程叫做拆箱(unboxing)
//輸出的是true int a = 100; Integer b = 100; System.out.println(a == b);*/ //輸出的true Integer c = 100; Integer d = 100; System.out.println(c == d); //輸出的是false c = 200; d = 200; System.out.println(c == d);第一題直接裝箱,肯定是相等;
第二題和第三題的結果可能有點疑問,這裏做個解釋:java將int轉爲Integer是用的Integer.valueOf(),而根據源碼可知,它對於-128到127的整數轉成包裝類型時不是去新建一個Integer對象,而是直接去IntegerCache中取出一個Integer對象,這樣兩個對象相等,所以返回是true,而對於超過這個範圍的整數,就是常見的新建Integer對象了,由於對象地址不同,所以返回是true
再補充:new Integer()與Integer.valueOf()的區別
new Integer()是新建一個對象,而Integer.valueOf()會使用緩存池中的對象,多次調用會取得同一個對象的引用,valueOf的實現就是先判斷值是否在緩衝池中(java8默認是-128到127),在的話就返回緩衝池裏的內容。
public static void main(String []args){ Integer x = new Integer(64); Integer y = new Integer(64); System.out.println(x==y);//false x = Integer.valueOf(64); y = Integer.valueOf(64); System.out.println(x==y);//true }編譯器會在自動裝箱過程調用 valueOf() 方法,因此多個值相同且值在緩存池範圍內的 Integer 實例使用自動裝箱來創建,那麼就會引用相同的對象。
Integer x =127; Integer y = 127; System.out.println(x==y);
3.equals與==的區別
- ==常用於判斷基本數據類型是否相等,而equals常用於判斷對象相等
- 當==與equals都用來判斷對象時,如果對象引用地址相同,==返回true,否則會返回false,因此==是來判斷對象的內存地址是否相同。而equals返回true或者false主要取決於重寫實現,如果沒有重寫,則單單判斷內存地址是否相同,與==一樣,當判斷String對象,Integer對象時,默認會進行重寫,這時只要值相同就會返回true.
補充:
String a="abc"; String b="abc"; System.out.println(a==b);//返回true System.out.println(a.equals(b));//返回true String str2 = new String("abc"); System.out.println(a == str2);//返回false System.out.println(a.equals(str2));//返回trueJava的虛擬機在內存中開闢出一塊單獨的區域,用來存儲字符串對象,這塊內存區域被稱爲字符串常量池。當使用
String a = "abc"這樣的語句進行定義一個引用的時候,首先會在字符串常量池中查找是否已經相同的對象,如果存在,那麼就直接將這個對象的引用返回給a,如果不存在,則需要新建一個值爲"abc"的對象,再將新的引用返回a。String a = new String("abc");這樣的語句明確告訴JVM想要產生一個新的String對象,並且值爲"abc",於是就在堆內存中的某一個小角落開闢了一個新的String對象。
4. Object有哪些公用方法?
- clone方法:實現對象的淺複製,只有當對象實現了Cloneable接口才可以調用該方法,否則拋出CloneNotSupportedException異常。主要是JAVA裏除了8種基本類型傳參數是值傳遞,其他的類對象傳參數都是引用傳遞,我們有時候不希望在方法裏把參數改變,這就需要在類中複寫clone方法,如下:
public class Hello implements Cloneable{ int x =15; @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } public static void main(String []args) throws CloneNotSupportedException { Hello hello = new Hello(); Hello hello2 = (Hello)hello.clone(); hello2.x = 20; System.out.println(hello.x);//返回15 System.out.println(hello2.x);//返回20 } } - getClass方法:final修飾,不能被重寫,獲得運行時類型。
package com.example.demo; public class Hello{ public static void main(String []args) throws CloneNotSupportedException { Hello hello = new Hello(); System.out.println(hello.getClass());//返回com.example.demo.Hello } } - toString方法:該方法用得比較多,一般子類要進行重寫,否則返回“類型@HashCode“,如com.example.demo.Hello@23ab930d
- finalize方法:該方法用於釋放資源。因爲無法確定該方法什麼時候被調用,很少使用。
- equals方法:常用於對象相等比較,子類一般都要重寫這個方法,否則和==一樣.
- hashCode方法:該方法常用於哈希查找,可以減少在查找中使用equals的次數,重寫了equals方法一般都要重寫hashCode方法。這個方法在一些具有哈希功能的Collection中用到。一般必須滿足obj1.equals(obj2)==true,可以推出obj1.hashCode()==obj2.hashCode(),但是hashCode相同不一定就滿足equals(有可能equals被重寫了)。不過爲了提高效率,應該儘量使上面兩個條件接近等價。如果不重寫hashCode(),在HashSet中添加兩個equals的對象,會將兩個對象都加入進去。
- wait方法:不可被重寫,就是使當前線程等待該對象的鎖,當前線程必須是該對象的擁有者,也就是具有該對象的鎖。wait()方法一直等待,直到獲得鎖或者被中斷。wait(long timeout)設定一個超時間隔,如果在規定時間內沒有獲得鎖就返回。調用該方法後當前線程進入睡眠狀態,直到以下事件發生:
(1)其他線程調用了該對象的notify方法。
(2)其他線程調用了該對象的notifyAll方法。
(3)其他線程調用了interrupt中斷該線程。
(4)時間間隔到了。
此時該線程就可以被調度了,如果是被中斷的話就拋出一個InterruptedException異常。
8.notify方法:不可被重寫,該方法喚醒在該對象上等待的某個線程。
9.notifyAll方法該方法喚醒在該對象上等待的所有線程。
補充:
作者: MoonGeek
出處:https://www.cnblogs.com/moongeek/p/7631447.html
java多線程學習之wait、notify/notifyAll 詳解
1、wait()、notify/notifyAll() 方法是Object的本地final方法,無法被重寫。
2、wait()使當前線程阻塞,前提是 必須先獲得鎖,一般配合synchronized 關鍵字使用,即,一般在synchronized 同步代碼塊裏使用 wait()、notify/notifyAll() 方法。
3、 由於 wait()、notify/notifyAll() 在synchronized 代碼塊執行,說明當前線程一定是獲取了鎖的。當線程執行wait()方法時候,會釋放當前的鎖,然後讓出CPU,進入等待狀態。只有當 notify/notifyAll() 被執行時候,纔會喚醒一個或多個正處於等待狀態的線程,然後繼續往下執行,直到執行完synchronized 代碼塊的代碼或是中途遇到wait() ,再次釋放鎖。也就是說,notify/notifyAll() 的執行只是喚醒沉睡的線程,而不會立即釋放鎖,鎖的釋放要看代碼塊的具體執行情況。所以在編程中,儘量在使用了notify/notifyAll() 後立即退出臨界區,以喚醒其他線程讓其獲得鎖
4、wait() 需要被try catch包圍,以便發生異常中斷也可以使wait等待的線程喚醒。
5、notify 和wait 的順序不能錯,如果A線程先執行notify方法,B線程在執行wait方法,那麼B線程是無法被喚醒的。
6、notify 和 notifyAll的區別
notify方法只喚醒一個等待(對象的)線程並使該線程開始執行。所以如果有多個線程等待一個對象,這個方法只會喚醒其中一個線程,選擇哪個線程取決於操作系統對多線程管理的實現。notifyAll 會喚醒所有等待(對象的)線程,儘管哪一個線程將會第一個處理取決於操作系統的實現。如果當前情況下有多個線程需要被喚醒,推薦使用notifyAll 方法。比如在生產者-消費者裏面的使用,每次都需要喚醒所有的消費者或是生產者,以判斷程序是否可以繼續往下執行。
7、在多線程中要測試某個條件的變化,使用if 還是while?
要注意,notify喚醒沉睡的線程後,線程會接着上次的執行繼續往下執行。所以在進行條件判斷時候,可以先把 wait 語句忽略不計來進行考慮;顯然,要確保程序一定要執行,並且要保證程序直到滿足一定的條件再執行,要使用while進行等待,直到滿足條件才繼續往下執行。如下代碼:
public class K { //狀態鎖 private Object lock; //條件變量 private int now,need; public void produce(int num){ //同步 synchronized (lock){ //當前有的不滿足需要,進行等待,直到滿足條件 while(now < need){ try { //等待阻塞 lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("我被喚醒了!"); } // 做其他的事情 } } }
顯然,只有當前值滿足需要值的時候,線程纔可以往下執行,所以,必須使用while 循環阻塞。注意,wait() 當被喚醒時候,只是讓while循環繼續往下走.如果此處用if的話,意味着if繼續往下走,會跳出if語句塊。
8、實現生產者和消費者問題
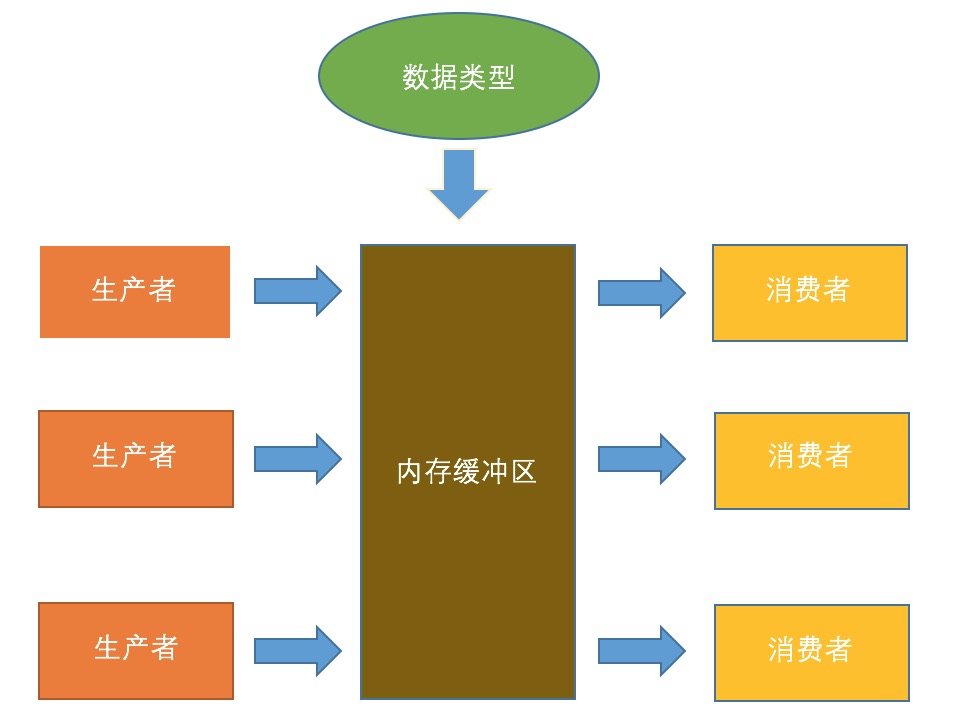
什麼是生產者-消費者問題呢?
如上圖,假設有一個公共的容量有限的池子,有兩種人,一種是生產者,另一種是消費者。需要滿足如下條件:
1、生產者產生資源往池子裏添加,前提是池子沒有滿,如果池子滿了,則生產者暫停生產,直到自己的生成能放下池子。
2、消費者消耗池子裏的資源,前提是池子的資源不爲空,否則消費者暫停消耗,進入等待直到池子裏有資源數滿足自己的需求。
實現:
1.先定義一個倉庫接口,包含消費和生產方法
1 public interface AbstractStorage { 2 void consume(int num); 3 void produce(int num); 4 }2. 倉庫接口實現類
1 import java.util.LinkedList; 2 3 /** 4 * 生產者和消費者的問題 5 * wait、notify/notifyAll() 實現 6 */ 7 public class Storage1 implements AbstractStorage { 8 //倉庫最大容量 9 private final int MAX_SIZE = 100; 10 //倉庫存儲的載體 11 private LinkedList list = new LinkedList(); 12 13 //生產產品 14 public void produce(int num){ 15 //同步 16 synchronized (list){ 17 //倉庫剩餘的容量不足以存放即將要生產的數量,暫停生產 18 while(list.size()+num > MAX_SIZE){ 19 System.out.println("【要生產的產品數量】:" + num + "\t【庫存量】:" 20 + list.size() + "\t暫時不能執行生產任務!"); 21 22 try { 23 //條件不滿足,生產阻塞 24 list.wait(); 25 } catch (InterruptedException e) { 26 e.printStackTrace(); 27 } 28 } 29 30 for(int i=0;i<num;i++){ 31 list.add(new Object()); 32 } 33 34 System.out.println("【已經生產產品數】:" + num + "\t【現倉儲量爲】:" + list.size()); 35 36 list.notifyAll(); 37 } 38 } 39 40 //消費產品 41 public void consume(int num){ 42 synchronized (list){ 43 44 //不滿足消費條件 45 while(num > list.size()){ 46 System.out.println("【要消費的產品數量】:" + num + "\t【庫存量】:" 47 + list.size() + "\t暫時不能執行生產任務!"); 48 49 try { 50 list.wait(); 51 } catch (InterruptedException e) { 52 e.printStackTrace(); 53 } 54 } 55 56 //消費條件滿足,開始消費 57 for(int i=0;i<num;i++){ 58 list.remove(); 59 } 60 61 System.out.println("【已經消費產品數】:" + num + "\t【現倉儲量爲】:" + list.size()); 62 63 list.notifyAll(); 64 } 65 } 66 }3.實現生產者類
1 public class Producer extends Thread{ 2 //每次生產的數量 3 private int num ; 4 5 //所屬的倉庫 6 public AbstractStorage abstractStorage; 7 8 public Producer(AbstractStorage abstractStorage){ 9 this.abstractStorage = abstractStorage; 10 } 11 12 public void setNum(int num){ 13 this.num = num; 14 } 15 16 // 線程run函數 17 @Override 18 public void run() 19 { 20 produce(num); 21 } 22 23 // 調用倉庫Storage的生產函數 24 public void produce(int num) 25 { 26 abstractStorage.produce(num); 27 } 28 }4.實現消費者類
1 public class Consumer extends Thread{ 2 // 每次消費的產品數量 3 private int num; 4 5 // 所在放置的倉庫 6 private AbstractStorage abstractStorage1; 7 8 // 構造函數,設置倉庫 9 public Consumer(AbstractStorage abstractStorage1) 10 { 11 this.abstractStorage1 = abstractStorage1; 12 } 13 14 // 線程run函數 15 public void run() 16 { 17 consume(num); 18 } 19 20 // 調用倉庫Storage的生產函數 21 public void consume(int num) 22 { 23 abstractStorage1.consume(num); 24 } 25 26 public void setNum(int num){ 27 this.num = num; 28 } 29 }測試
1 public class Test{ 2 public static void main(String[] args) { 3 // 倉庫對象 4 AbstractStorage abstractStorage = new Storage1(); 5 6 // 生產者對象 7 Producer p1 = new Producer(abstractStorage); 8 Producer p2 = new Producer(abstractStorage); 9 Producer p3 = new Producer(abstractStorage); 10 Producer p4 = new Producer(abstractStorage); 11 Producer p5 = new Producer(abstractStorage); 12 Producer p6 = new Producer(abstractStorage); 13 Producer p7 = new Producer(abstractStorage); 14 15 // 消費者對象 16 Consumer c1 = new Consumer(abstractStorage); 17 Consumer c2 = new Consumer(abstractStorage); 18 Consumer c3 = new Consumer(abstractStorage); 19 20 // 設置生產者產品生產數量 21 p1.setNum(10); 22 p2.setNum(10); 23 p3.setNum(10); 24 p4.setNum(10); 25 p5.setNum(10); 26 p6.setNum(10); 27 p7.setNum(80); 28 29 // 設置消費者產品消費數量 30 c1.setNum(50); 31 c2.setNum(20); 32 c3.setNum(30); 33 34 // 線程開始執行 35 c1.start(); 36 c2.start(); 37 c3.start(); 38 39 p1.start(); 40 p2.start(); 41 p3.start(); 42 p4.start(); 43 p5.start(); 44 p6.start(); 45 p7.start(); 46 } 47 }輸出
【要消費的產品數量】:50 【庫存量】:0 暫時不能執行生產任務! 【要消費的產品數量】:20 【庫存量】:0 暫時不能執行生產任務! 【要消費的產品數量】:30 【庫存量】:0 暫時不能執行生產任務! 【已經生產產品數】:10 【現倉儲量爲】:10 【要消費的產品數量】:30 【庫存量】:10 暫時不能執行生產任務! 【要消費的產品數量】:20 【庫存量】:10 暫時不能執行生產任務! 【要消費的產品數量】:50 【庫存量】:10 暫時不能執行生產任務! 【已經生產產品數】:10 【現倉儲量爲】:20 【已經生產產品數】:10 【現倉儲量爲】:30 【要消費的產品數量】:50 【庫存量】:30 暫時不能執行生產任務! 【已經消費產品數】:20 【現倉儲量爲】:10 【要消費的產品數量】:30 【庫存量】:10 暫時不能執行生產任務! 【已經生產產品數】:10 【現倉儲量爲】:20 【要消費的產品數量】:50 【庫存量】:20 暫時不能執行生產任務! 【要消費的產品數量】:30 【庫存量】:20 暫時不能執行生產任務! 【已經生產產品數】:10 【現倉儲量爲】:30 【已經消費產品數】:30 【現倉儲量爲】:0 【要消費的產品數量】:50 【庫存量】:0 暫時不能執行生產任務! 【已經生產產品數】:10 【現倉儲量爲】:10 【要消費的產品數量】:50 【庫存量】:10 暫時不能執行生產任務! 【已經生產產品數】:80 【現倉儲量爲】:90 【已經消費產品數】:50 【現倉儲量爲】:40
Hashcode的作用。
http://c610367182.iteye.com/blog/1930676
以Java.lang.Object來理解,JVM每new一個Object,它都會將這個Object丟到一個Hash哈希表中去,這樣的話,下次做Object的比較或者取這個對象的時候,它會根據對象的hashcode再從Hash表中取這個對象。這樣做的目的是提高取對象的效率。具體過程是這樣:
-
new Object(),JVM根據這個對象的Hashcode值,放入到對應的Hash表對應的Key上,如果不同的對象確產生了相同的hash值,也就是發生了Hash key相同導致衝突的情況,那麼就在這個Hash key的地方產生一個鏈表,將所有產生相同hashcode的對象放到這個單鏈表上去,串在一起。
-
比較兩個對象的時候,首先根據他們的hashcode去hash表中找他的對象,當兩個對象的hashcode相同,那麼就是說他們這兩個對象放在Hash表中的同一個key上,那麼他們一定在這個key上的鏈表上。那麼此時就只能根據Object的equal方法來比較這個對象是否equal。當兩個對象的hashcode不同的話,肯定他們不能equal.
String, StringBuffer and StringBuilder
1. 可變性
- String 不可變
- StringBuffer 和 StringBuilder 可變
2. 線程安全
- String 不可變,因此是線程安全的
- StringBuilder 不是線程安全的
- StringBuffer 是線程安全的,內部使用 synchronized 進行同步
try catch finally,try裏有return,finally還執行麼?
會執行,在方法 返回調用者前執行。Java允許在finally中改變返回值的做法是不好的,因爲如果存在finally代碼塊,try中的return語句不會立馬返回調用者,而是紀錄下返回值待finally代碼塊執行完畢之後再向調用者返回其值,然後如果在finally中修改了返回值,這會對程序造成很大的困擾,
String是如何保證不可變的?保證不可變有什麼好處?
String 被聲明爲 final,因此它不可被繼承。
在 Java 8 中,String 內部使用 char 數組存儲數據。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
在 Java 9 之後,String 類的實現改用 byte 數組存儲字符串,同時使用 coder 來標識使用了哪種編碼。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final byte[] value;
/** The identifier of the encoding used to encode the bytes in {@code value}. */
private final byte coder;
}
value 數組被聲明爲 final,這意味着 value 數組初始化之後就不能再引用其它數組。並且 String 內部沒有改變 value 數組的方法,因此可以保證 String 不可變。
String不可變的好處
1. 可以緩存 hash 值
因爲 String 的 hash 值經常被使用,例如 String 用做 HashMap 的 key,由於其不可變,因此其hash 值也不可變,這樣就只需要進行一次計算。
2. String Pool 的需要
如果一個 String 對象已經被創建過了,那麼就會從 String Pool 中取得引用。只有 String 是不可變的,纔可能使用 String Pool。

3. 安全性
String 經常作爲參數,String 不可變性可以保證參數不可變。
4. 線程安全
String 不可變性天生具備線程安全,可以在多個線程中安全地使用。
String Pool
字符串常量池(String Pool)保存着所有字符串字面量(literal strings),這些字面量在編譯時期就確定。不僅如此,還可以使用 String 的 intern() 方法在運行過程中將字符串添加到 String Pool 中。
當一個字符串調用 intern() 方法時,如果 String Pool 中已經存在一個字符串和該字符串值相等(使用 equals() 方法進行確定),那麼就會返回 String Pool 中字符串的引用;否則,就會在 String Pool 中添加一個新的字符串,並返回這個新字符串的引用。
下面示例中,s1 和 s2 採用 new String() 的方式新建了兩個不同字符串,而 s3 和 s4 是通過 s1.intern() 方法取得一個字符串引用。intern() 首先把 s1 引用的字符串放到 String Pool 中,然後返回這個字符串引用。因此 s3 和 s4 引用的是同一個字符串。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
String s4 = s1.intern();
System.out.println(s3 == s4); // true
如果是採用 "bbb" 這種字面量的形式創建字符串,會自動地將字符串放入 String Pool 中。
String s5 = "bbb";
String s6 = "bbb";
System.out.println(s5 == s6); // true
在 Java 7 之前,String Pool 被放在運行時常量池中,它屬於永久代。而在 Java 7,String Pool 被移到堆中。這是因爲永久代的空間有限,在大量使用字符串的場景下會導致 OutOfMemoryError 錯誤。
java中的參數傳遞
java中是值傳遞,傳對象參數時本質上傳的是對象的地址。因此在方法中使指針引用其它對象,那麼這兩個指針此時指向的是完全不同的對象,在一方改變其所指向對象的內容時對另一方沒有影響。
public class Dog {
private int age;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
private static void change(Dog dog){
System.out.println(dog.toString());
dog = new Dog();
System.out.println(dog.toString());
dog.setAge(20);
}
public static void main(String []args){
Dog dog = new Dog();
System.out.println(dog.toString());
dog.setAge(10);
change(dog);
System.out.println(dog.getAge());
}
}
如果是下面,就是20
private static void change(Dog dog){
System.out.println(dog.toString());
dog.setAge(20);
}
public static void main(String []args){
Dog dog = new Dog();
System.out.println(dog.toString());
dog.setAge(10);
change(dog);
System.out.println(dog.getAge());//20
}
float與double:double字面量不能直接賦值float,因此java默認不能隱式向下轉型
float f = 1.1 //報錯
float f = 1.1f
隱式類型轉換
因爲字面量 1 是 int 類型,它比 short 類型精度要高,因此不能隱式地將 int 類型下轉型爲 short 類型。
short s1 = 1; // s1 = s1 + 1;但是使用 += 或者 ++ 運算符可以執行隱式類型轉換。
s1 += 1; // s1++;上面的語句相當於將 s1 + 1 的計算結果進行了向下轉型:
s1 = (short) (s1 + 1);
接口和抽象類的比較
相同點:都不能實例化
區別:
- 從使用上來看,一個類可以實現多個接口,但是不能繼承多個抽象類。
- 接口的字段只能是 static 和 final 類型的,而抽象類的字段沒有這種限制。
- 接口的成員只能是 public 的,而抽象類的成員可以有多種訪問權限。
重寫和重載的含義和區別
Overload:它可以表現類的多態性,存在於同一個類中,指一個方法與已經存在的方法名稱上相同,但是參數類型、個數、順序至少有一個不同。應該注意的是,返回值不同,其它都相同不算是重載
Override:在子類繼承父類的時候子類中可以定義某方法與其父類有相同的名稱和參數,當子類在調用這一函數時自動調用子類的方法,而父類相當於被覆蓋(重寫)了。重寫有以下三個限制:
- 子類方法的訪問權限必須大於等於父類方法;
- 子類方法的返回類型必須是父類方法返回類型或爲其子類型。
- 子類方法拋出的異常類型必須是父類拋出異常類型或爲其子類型。
final關鍵字
1.修飾數據:對於基本類型,final 使數值不變,即無法修改;
對於引用類型,final 使引用不變,也就是不能引用其它對象,但是被引用的對象本身是可以修改的。
2.修飾方法:無法被子類重寫
3.修飾類:類不能被繼承
Static關鍵字
1.靜態變量:類所有的實例都共享靜態變量,可以直接通過類名來訪問它,其在內存中只存在一份。
2.靜態方法:類加載的時候就存在,它不依賴於任何實例。所以靜態方法必須要實現,也就是說它不能是抽象方法,並且只能訪問所屬類的靜態字段和靜態方法,方法中不能有 this 和 super 關鍵字。
3. 靜態語句塊:類初始時運行一次
public class A {
static {
System.out.println("123");
}
public static void main(String[] args) {
A a1 = new A();
A a2 = new A();
}
}
//只有一個123打印
4.靜態內部類:非靜態內部類依賴於外部類的實例,而靜態內部類不需要。靜態內部類不能訪問外部類的非靜態的變量和方法。
public class OuterClass {
class InnerClass {
}
static class StaticInnerClass {
}
public static void main(String[] args) {
// InnerClass innerClass = new InnerClass(); // 'OuterClass.this' cannot be referenced from a static context
OuterClass outerClass = new OuterClass();
InnerClass innerClass = outerClass.new InnerClass();
StaticInnerClass staticInnerClass = new StaticInnerClass();
}
}
5.靜態導包:在使用靜態變量和方法時不用再指明 ClassName,從而簡化代碼,但可讀性大大降低
import static com.xxx.ClassName.*
6.初始化執行順序:靜態變量和靜態語句塊優先於實例變量和普通語句塊,靜態變量和靜態語句塊的初始化順序取決於它們在代碼中的順序。
public class Dog {
public static String staticField = "靜態變量";//1
static {
System.out.println("靜態語句塊");//2
}
public String field = "實例變量";//3
public Dog() {
System.out.println("構造函數");//5
}
{
System.out.println("普通語句塊");//4
}
public static void main(String []args){
Dog dog = new Dog();
}
}
反射機制
它允許運行中的 Java 程序獲取自身的信息,並且可以操作類或對象的內部屬性,反射的核心是 JVM 在運行時才動態加載類或調用方法/訪問屬性,它不需要事先(寫代碼的時候或編譯期)知道運行對象是誰。
java 反射主要提供以下功能:
- 在運行時判斷任意一個對象所屬的類;
- 在運行時構造任意一個類的對象;
- 在運行時判斷任意一個類所具有的成員變量和方法(通過反射甚至可以調用private方法);
- 在運行時調用任意一個對象的方法
反射最重要的用途就是開發各種通用框架。很多框架(比如 Spring)都是配置化的(比如通過 XML 文件配置 Bean),爲了保證框架的通用性,它們可能需要根據配置文件加載不同的對象或類,調用不同的方法,這個時候就必須用到反射,運行時動態加載需要加載的對象。
Class 和 java.lang.reflect 一起對反射提供了支持,java.lang.reflect 類庫主要包含了以下三個類:
- Field :可以使用 get() 和 set() 方法讀取和修改 Field 對象關聯的字段;
- Method :可以使用 invoke() 方法調用與 Method 對象關聯的方法;
- Constructor :可以用 Constructor 創建新的對象。
反射的優點:
- 可擴展性 :應用程序可以利用全限定名創建可擴展對象的實例,來使用來自外部的用戶自定義類。
- 類瀏覽器和可視化開發環境 :一個類瀏覽器需要可以枚舉類的成員。可視化開發環境(如 IDE)可以從利用反射中可用的類型信息中受益,以幫助程序員編寫正確的代碼。
- 調試器和測試工具 : 調試器需要能夠檢查一個類裏的私有成員。測試工具可以利用反射來自動地調用類裏定義的可被發現的 API 定義,以確保一組測試中有較高的代碼覆蓋率。
反射的缺點:
儘管反射非常強大,但也不能濫用。如果一個功能可以不用反射完成,那麼最好就不用。在我們使用反射技術時,下面幾條內容應該牢記於心。
-
性能開銷 :反射涉及了動態類型的解析,所以 JVM 無法對這些代碼進行優化。因此,反射操作的效率要比那些非反射操作低得多。我們應該避免在經常被執行的代碼或對性能要求很高的程序中使用反射。
-
安全限制 :使用反射技術要求程序必須在一個沒有安全限制的環境中運行。如果一個程序必須在有安全限制的環境中運行,如 Applet,那麼這就是個問題了。
-
內部暴露 :由於反射允許代碼執行一些在正常情況下不被允許的操作(比如訪問私有的屬性和方法),所以使用反射可能會導致意料之外的副作用,這可能導致代碼功能失調並破壞可移植性。反射代碼破壞了抽象性,因此當平臺發生改變的時候,代碼的行爲就有可能也隨着變化。
泛型
1. Java中的泛型是什麼 ? 使用泛型的好處是什麼?
泛型,就是允許在定義類、接口、方法時使用類型形參,在聲明變量、創建對象、調用方法時再傳入實際的類型參數。像List代表了只能存放String類型的對象的List集合。
如果沒有泛型,那麼我們很容易在運行時出現ClassCastException,因爲本身編譯期不報錯,泛型防止了那種情況的發生。它提供了編譯期的類型安全,確保你只能把正確類型的對象放入集合中。
所以總結起來泛型的好處是:
• 能夠在編譯時檢查類型安全
• 所有的強制轉換都是自動和隱式的,取出代碼後,不用再進行強制類型轉換
2. Java的泛型是如何工作的 ? 什麼是類型擦除 ?
泛型是通過類型擦除來實現的,編譯器在編譯時擦除了所有類型相關的信息,所以在運行時不存在任何類型相關的信息。例如List<String>在運行時僅用一個List來表示。這樣做的目的,是確保能和Java 5之前的版本開發二進制類庫進行兼容。你無法在運行時訪問到類型參數,因爲編譯器已經把泛型類型轉換成了原始類型。
3. 什麼是泛型中的限定通配符和非限定通配符 ?
限定通配符對類型進行了限制。有兩種限定通配符,一種是<? extends T>它通過確保類型必須是T的子類來設定類型的上界,另一種是<? super T>它通過確保類型必須是T的父類來設定類型的下界。泛型類型必須用限定內的類型來進行初始化,否則會導致編譯錯誤。另一方面<?>表示了非限定通配符,因爲<?>可以用任意類型來替代。
4. List<? extends T>和List <? super T>之間有什麼區別 ?
這兩個List的聲明都是限定通配符的例子,List<? extends T>可以接受任何繼承自T的類型的List,而List<? super T>可以接受任何T的父類構成的List。例如List<? extends Number>可以接受List<Integer>或List<Float>。
5. 如何編寫一個泛型方法、泛型類?
編寫泛型方法並不困難,你需要用泛型類型來替代原始類型,比如使用T, E or K,V等被廣泛認可的類型佔位符。
public class GenericClass<F>{
private F mContent;
public GenericClass(F content){
mContent = content;
}
/*
泛型方法
*/
public F getContent(){
return mContent;
}
public void setContent(F content){
mcontent = content;
}
/*
泛型接口
*/
public interface GenericInterface<T>{
void doSomething(T t);
}
}
7. 你可以把List<String>傳遞給一個接受List<Object>參數的方法嗎?
如果不用泛型,這樣做的話會導致編譯錯誤。
List<Object> objectList;
List<String> stringList;
objectList = stringList; //compilation error incompatible types
8. Array中可以用泛型嗎?
Array並不支持泛型,而List支持泛型,可以提供編譯期的類型安全保證,而Array卻不能。
9. 如何阻止Java中的類型未檢查的警告?
如果你把泛型和原始類型混合起來使用,例如下列代碼,Java 5的javac編譯器會產生類型未檢查的警告,例如
List<String> rawList = new ArrayList(),這種警告可以使用@SuppressWarnings(“unchecked”)註解來屏蔽。
Java 與 C++ 的區別
- Java 是純粹的面嚮對象語言,所有的對象都繼承自 java.lang.Object,C++ 爲了兼容 C 即支持面向對象也支持面向過程。
- Java 通過虛擬機從而實現跨平臺特性,但是 C++ 依賴於特定的平臺。
- Java 沒有指針,它的引用可以理解爲安全指針,而 C++ 具有和 C 一樣的指針。
- Java 支持自動垃圾回收,而 C++ 需要手動回收。
- Java 不支持多重繼承,只能通過實現多個接口來達到相同目的,而 C++ 支持多重繼承。
- Java 不支持操作符重載,雖然可以對兩個 String 對象執行加法運算,但是這是語言內置支持的操作,不屬於操作符重載,而 C++ 可以。
- Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto。
- Java 不支持條件編譯,C++ 通過 #ifdef #ifndef 等預處理命令從而實現條件編譯。
JRE or JDK
- JRE 是 一個JVM 程序, Java應用需要運行在JRE.上.
- JDK 是 JRE的超集, JRE +工具 來發展java程序,比如它提供編譯期 "javac"