




密度分析
密度分析是根據輸入要素數據計算整個區域的數據聚集狀況。
密度分析是通過離散點數據或者線數據進行內插的過程,根據插值原理不同,主要是分爲核密度分析和普通的點\線密度分析。核密度分心中,落入搜索區的點具有不同的權重,靠近搜索中心的點或線會被賦予較大的權重,反之,權重較小,它的計算結果分佈較平滑。在普通的點\線密度分析中,落在搜索區域內的點或線有相同的權重,先對其求和,再除以搜索區域的大小,從而得到每個點的密度值。

ArcGIS 的空間分析工具箱中提供了密度分析工具集中的三個工具:

1. Kernel Density(核密度分析)

輸入值可以是點或者線。
工作原理引自幫助:
概念上,每個點/線上方均覆蓋着一個平滑曲面。在點/線所在位置處表面值最高,隨着與點的距離的增大表面值逐漸減小,在與點/線的距離等於搜索半徑的位置處表面值爲零。僅允許使用圓形鄰域。曲面與下方的平面所圍成的空間的體積等於此點的 Population 字段值,如果將此字段值指定爲 NONE 則體積爲 1。每個輸出柵格像元的密度均爲疊加在柵格像元中心的所有核表面的值之和。核函數以 Silverman 的著作(1986 年版,第 76 頁,方程 4.5)中描述的二次核函數爲基礎。
對於點,如果 population 字段設置使用的是除 NONE 之外的值,則每項的值用於確定點被計數的次數。例如,值 3 會導致點被算作三個點。值可以爲整型也可以爲浮點型。
對於線,如果 population 字段使用的是除 NONE 之外的值,則線的長度將由線的實際長度乘以此線的 population 字段的值而得出。
2. Point Density / Line Density(點、線密度分析):

這兩個工具的輸出與核密度工具的輸出的區別在於:
對於點密度和線密度,需要指定一個鄰域,以便計算出各輸出像元周圍像元的密度。而核密度則可將各點的已知總體數量從點位置開始向四周分散。在覈密度中,在各點周圍生成表面所依據的二次公式可爲表面中心(點位置)賦予最高值,並在搜索半徑距離範圍內減少到零。對於各輸出像元,將計算各分散表面的累計交匯點總數。
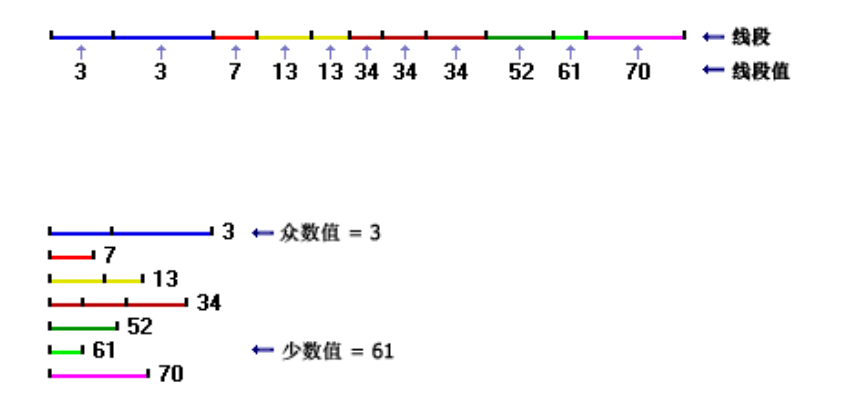
1)點密度分析
每個柵格像元中心的周圍都定義了一個鄰域(鄰域可以使用圓形、矩形、環形、楔形的形狀來定義),將鄰域內點的數量相加,然後除以鄰域面積,即得到點要素的密度。如果 Population 字段設置使用的是 NONE 之外的值,則每項的值用於確定點被計數的次數。例如,值爲 3 的項會導致點被算作三個點。值可以爲整型也可以爲浮點型。
2)線密度分析
使用搜索半徑以各個柵格像元中心爲圓心繪製一個圓。每條線上落入該圓內的部分的長度與 Population 字段值相乘。對這些數值進行求和,然後將所得的總和除以圓面積。

上圖中顯示的是柵格像元與其圓形鄰域。線 L1 和 L2 表示各條線上落入圓內部分的長度。相應的 population 字段值分別爲 V1 和 V2。因此:
Density = ((L1 * V1) + (L2 * V2)) / (area_of_circle)
如果 population 字段使用的是除 NONE 之外的值,則線的長度將等於線的實際長度乘以其 population 字段的值。
距離分析
距離分析相關的工具:

ArcGIS中,主要可以通過如下的幾種方式進行距離分析:
1) 歐氏距離分析
2) 成本加權距離分析
3) 用於垂直移動限制和水平移動限制的成本加權距離分析
4) 獲取最短路徑
使用ArcGIS空間分析擴展實現距離分析,最主要的是歐氏距離分析和成本加權距離分析兩類工具。
一、歐氏距離工具
歐氏距離工具測量每個像元距離最近源的直線距離(像元中心至像元中心的距離)。
歐氏距離(Euclidean Diatance)—— 求得每個像元至最近源的距離。
歐氏方向(Euclidean Direction)—— 求得每個像元至最近源的方向。
歐氏分配(Euclidean Allocation)—— 求得每個像元的最近的源。
TIPS:
1. 源(Source)
可以是感興趣的地物的位置,數據方面,既可以是柵格數據,也可以是矢量數據。但注意:如果數據選用了柵格數據,數據中必須僅包含表示源的像元,其他像元需要是Nodata。如果選用矢量,在執行工具之時,內部會將其先轉成柵格。
2. 歐氏距離的算法
簡單理解爲:工具會求得每個像元至每個源的距離,然後取得每個像元至每個源的最短距離以輸出。其中,歐氏距離是像元中心與源像元的中心的直線距離。

如果像元與兩個或更多源之間的距離相等,則計算都基於像元掃描過程中遇到的第一個源。無法控制該掃描過程。
幫助中有這樣的描述:工具在實際執行的過程中,進行兩次順序掃描。這樣,工具的執行速度與源像元的數目、分佈以及最大距離無關。影響工具執行速度的唯一因素是柵格的大小。計算時間與“分析”窗口中的像元數成線性比例。暫且不知道進行了什麼樣的兩次順序掃描。
3. 歐氏距離輸出柵格結果
投影平面上,像元與最近源之間的最短直線距離。如下圖:

4. 歐氏方向輸出柵格結果
像元與最近源之間的方位角方向(以度爲單位)。使用 360 度圓,刻度 360 指北,90指東,從刻度 1 順時針增加。值 0 供源像元使用。如下圖:

5. 歐氏分配輸出柵格結果
輸出的每個像元都是距其最近源的值。如下圖:

二、成本加權距離工具
成本加權距離工具可以看成是對歐氏直線距離的進一步修改,將經過某個像元的距離賦以成本因素。舉個簡單的例子,翻過一座山到達目的地是最短的直線距離,繞行這座山距離較長,但是更節省時間和體力,那就後者的成本加權距離最短了。
1)成本距離(Cost Distance):求得每個像元至最近源的成本距離。
2)成本回溯鏈接(Cost back link):求的一個方向柵格,可以從任意像元沿最小成本路徑返回最近源。
3)成本分配(Cost Allocation):求得每個像元的最近的源。
4)成本路徑(Cost Patch):求的任意像元到最近源的最小成本路徑。
TIPS:
1. 成本柵格可以是整形或者浮點型,但是其值中不能含有負值或者0。成本柵格中的Nodata視爲障礙。
2. 成本距離輸出柵格數據
這裏的簡單示例中,下面一層黑白渲染的是成本柵格,顏色深的像元代表成本比較高,反之較低。結果如下:

2. 成本距離回溯鏈接
要注意的是,它並不會求的要返回哪一個源像元以及如何返回。而是記錄從任意像元回溯到最近源的路徑上,每個像元向下一個像元指向的方向,這個方向以0-8的代碼形式記錄。如下圖:


3. 成本距離分配
這個類似於前面的歐氏距離分配,得到的是每個像元至最近源的成本距離。

三、路徑距離工具
路徑距離工具與成本距離相似,也可以確定從某個源到柵格上各像元位置的最小累積行程成本。但是,路徑距離不僅可計算成本表面的累積成本,而且會考慮到行駛的實際曲面距離,和影響到移動總成本的水平和垂直因子。主要包含這幾個工具
1)路徑距離(Path Distance)
2)路徑回溯鏈接(Path back link)
3)路徑分配(Path Allocation)
這些工具生成的累積成本表面可用於擴散模型、流動和最低成本路徑分析。
四、 獲得最短路徑
1. 成本距離路徑
任意像元到最近源的最小成本路徑,需要引用到上面工具中生成的成本距離和成本回溯鏈接柵格數據。如下圖:

2. 廊道
另外要說的是廊道分析工具(Corridor)。此工具用於計算兩個成本柵格的累積成本柵格結果,爲了求得從一個源到另一個源且經過該像元位置的最小成本路徑。
輸出柵格不是單個最小成本路徑,但會得到源之間累積成本的範圍。
最後我們可以配合其他工具將小於某一閾值的結果提取出來,例如工具Extract by Attribute提取,或者通過Con進行條件賦值等等方法,獲取結果。
如下如所示:
學校A、B成本距離分析結果:

學校C、D、E的成本距離分析結果:

有此兩個距離成本結果,來分析得到A、B到C、D、E之間的廊道,也就是兩組源之間的最小累積成本距離。

然後結果中我們可以按照一定的閾值來提取結果。例如累積成本在75以下的我才能接受:

常用工具
空間分析擴展模塊中提供了很多方便柵格處理的工具,其中提取(Extraction)、綜合(Generalization)等工具集中提供的功能是在分析處理數據中經常會用到的。
一、提取(Extraction)
顧名思義,這組工具就是方便我們將柵格數據按照某種條件來篩選提取。
工具集中提供瞭如下工具:

xtract by Attribute:按屬性提取,按照SQL表達式篩選像元值。
Extract by Circle:按圓形提取,定義圓心和半徑,按圓形提取柵格。
Extract by Mask:按掩膜提取,按指定的柵格數據或者矢量數據的形狀的提取像元。
Extract by Point:按點提取,按給定座標值列表進行提取。
Extract by Polygon:按多邊形提取,按給定座標序列作爲節點的多邊形進行提取。
Extract by Rectangle:按矩形提取,按給定的圖層的Extent,或者定義了四至的矩形進行提取。
Extract Value to Point :按照點要素的位置提取對應的(一個/多個)柵格數據的像元值,其中,提取的Value可以使用像元中心值或者選擇進行雙線性插值提取。
Extract Multi Value to Point:同上,只是提取多個柵格的像元值。
Sample:採樣,根據給定的柵格或者矢量數據的位置提取像元值,採樣方法可選:最鄰近分配法(Nearest)、雙線性插值法(Bilinear)、三次卷積插值法(Cubic)。
以上工具用來提取柵格中的有效值、興趣區域\點等很有用的。
二、綜合(Generalization)
這組工具主要用來清理柵格數據,可以大致分爲三個方面的功能:更改數據的分辨率、對區域進行概化、對區域邊緣進行平滑。
這些工具的輸入都要求爲整型柵格。

1. 更改數據分辨率:
Aggregate: 聚合,生成降低分辨率的柵格。
其中,Cell Factor需要是一個大於1的整數,表示生成柵格的像元大小是原來的幾倍。
生成新柵格的像元值可選:新的大像元所覆蓋的輸入像元的總和值、最小值、最大值、平均值、中間值。
效果如下,Cell factor設置爲 6:

2. 對區域進行概化:
Expand: 擴展,按指定的像元數目擴展指定的柵格區域。


Shrink: 收縮,按指定像元數目收縮所選區域,方法是用鄰域中出現最頻繁的像元值替換該區域的值。同Expand。
Nibble: 用最鄰近點的值替換掩膜範圍內的柵格像元的值。
Thin: 細化,通過減少表示要素寬度的像元數來對柵格化的線狀對象進行細化。
Region Group: 區域合併,記錄輸出中每個像元所屬的連接區域的標識。每個區域都將被分配給唯一編號。
工作原理:掃描的第一個區域接收值 1,第二個區域接收值 2,依此類推,直到所有區域都已賦值。掃描將按從左至右、從上至下的順序進行。被賦予輸出區域的值取決於系統在掃描過程中是在什麼時候遇到它們的。
其中,添加鏈接選項爲“真”時。這將在輸出柵格的屬性表中創建名爲 LINK 的項,其保留輸入柵格的每個像元的原始值。

如下圖,原始數據具有相同值的區域有的並不連通,這時會新生成很多Region:


3. 對區域邊緣進行平滑:
Boundary Clean: 邊界清理,通過擴展和收縮來平滑區域間的邊界。該工具會去更改X或Y方向上所有少於三個像元的位置。
Majority Filter: 衆數濾波,根據相鄰像元數據值的衆數替換柵格中的像元。可以認爲是“少數服從多數”,太突兀的像元被周圍的大部隊幹掉了。其中“大部隊”的參數可設置,相鄰像元可以4鄰域或者8鄰域,衆數可選,需要大部分(3/4、5/8)還是過半數即可。
TIPS: 這兩個工具僅支持整形柵格輸入。
看如下示例,清理後,還是有明顯變化的,細碎像元已經被處理掉了。


表面分析

坡向(Aspect):獲得柵格表面的坡向。求得每個像元到其相鄰像元方向像元值的變化率最大的下坡方向。
等值線(Contour):根據柵格表面創建等值線(等值線圖)的線要素類。
等值線序列(Contour List):根據柵格表面創建所選等值線值的要素類。
含障礙的等值線(Contour with Barriers):根據柵格表面創建等值線。如果包含障礙要素,則允許在障礙兩側獨立生成等值線。
曲率(Curvature):計算柵格表面的曲率,包括剖面曲率和平面曲率。
填挖方(Cut Fill):計算兩表面間體積的變化。通常用於執行填挖操作。
山體陰影(HillShade):通過考慮照明源的角度和陰影,根據表面柵格創建地貌暈渲。
視點分析(Observer Point):識別從各柵格表面位置進行觀察時可見的觀察點。
坡度(Slope):判斷柵格表面的各像元中的坡度(梯度或 z 值的最大變化率)。
視域(Viewshed):確定對一組觀察點要素可見的柵格表面位置。
下面分類來看一下這些工具:
一、 各種等值線工具
1) 等值線(Contour)
根據柵格表面數據創建等值線線要素類。可以指定起算線和間隔。

2) 等值線列表(Contour list)
根據柵格表面創建所指定等值線值的要素類。
3)含障礙的等值線(Contour with Barriers)
根據柵格表面創建等值線。如果包含障礙要素,則允許在障礙兩側獨立生成等值線。
TIPS: 關於等值線的質量問題
少數情況下,所創建等值線的輪廓可能會呈方形或不均勻,看起來猶如沿着柵格像元的邊界。出現這種情況可能是因爲各柵格的值爲整數且恰好落在等值線上。這並不是個問題,該等值線不過是原樣呈現數據而已。
如果希望等值線更平滑,可行的方法包括對源數據進行平滑處理或調整起始等值線。
二、表面特徵相關工具
1) 坡向(Aspect)

此工具求得每個像元到其相鄰的各個像元方向的 z 值上變化率最大的下坡方向。
從概念上講,坡向工具將根據要處理的像元或中心像元周圍一個 3 x 3 的像元鄰域的 z 值擬合出一個平面。該平面的朝向就是待處理像元的坡向。
輸出柵格的值將是坡向的羅盤方向。坡向由 0 到 359.9 度之間的正度數表示,以北爲基準方向按順時針進行測量。會爲輸入柵格中的平坦(具有零坡度)像元分配 -1 坡向。

2) 坡度(Slope)
坡度是指各像元中 z 值的最大變化率。
從概念上講,該工具會將一個平面與要處理的像元或中心像元周圍一個 3 x 3 的像元鄰域的 z 值進行擬合。該平面的坡度值通過最大平均值法來計算。
如果鄰域內某個像元位置的 z 值爲 NoData,則將中心像元的 z 值指定給該位置。如果直接鄰域(3 x 3 窗口)中的中心像元爲 NoData,則輸出將爲 NoData。

確定輸出坡度數據的測量單位(度或百分比)。
DEGREE — 坡度傾角,單位:度,範圍:0 ~ 90。
PERCENT_RISE — 高程增量百分比,也稱爲百分比坡度,範圍:0 ~ ∞。
該工具可與其他類型的連續數據(如人口)配合使用,用來識別值的急劇變化。
關於工具的詳細算法:http://help.arcgis.com/zh-cn/arcgisdesktop/10.0/help/index.html#/na/009z000000vz000000/
3) 曲率(Curvature)
主要輸出結果爲每個像元的表面曲率。曲率是表面的二階導數,或者可稱之爲坡度的坡度。曲率爲正說明該像元的表面向上凸。曲率爲負說明該像元的表面開口朝上凹入。值爲 0 說明表面是平的。
可供選擇的輸出曲率類型爲:剖面曲率(沿最大斜率的坡度)和平面曲率(垂直於最大坡度的方向)。
從應用的角度看,該工具的輸出可用於描述流域盆地的物理特徵,從而便於理解侵蝕過程和徑流形成過程。坡度會影響下坡時的總體移動速率。坡向將決定流向。剖面曲率將影響流動的加速和減速,進而將影響到侵蝕和沉積。平面曲率會影響流動的匯聚和分散。

三、 填挖方(Cut Fill)
計算兩表面間體積的變化。通常用於執行填挖操作。
默認情況下,將使用專用渲染器來高亮顯示執行填挖操作的位置。該渲染器將被挖的區域繪製成藍色,將被填的區域繪製成紅色。沒有變化的區域將顯示爲灰色。



四、 山影(Hillshade)

此工具考慮的主要因素是太陽(照明源)在天空中的位置。看下此工具的參數設置:

方位角(Azimuth)指的是太陽的角度方向,是以北爲基準方向在 0 到 360 度範圍內按順時針進行測量的。90º 的方位角爲東。
此工具默認方向角爲 315º (NW)。

高度(Altitude)指的是太陽高出地平線的角度或坡度。高度的單位爲度,範圍爲 0(位於地平線上)到 90(位於頭上)之間。
此工具默認值爲 45 度。

Model sahdows
通過對選擇 Model sahdows,可計算局部照明度以及像元是否落入陰影內。陰影值爲0,所有其他像元的編碼爲介於 1 和 255 之間的整數。
Z 因子(Z factor)
z 單位與輸入表面的 x,y 單位不同時,可使用 z 因子調整 z 單位的測量單位。計算最終輸出表面時,將用 z 因子乘以輸入表面的 z 值。
如果 x,y 單位和 z 單位採用相同的測量單位;則 z 因子爲 1。這是默認值。此外,z 因子還可用於地形誇大。
例如,如果 z 單位是英尺而 x,y 單位是米,則應使用 z 因子 0.3048 將 z 單位從英尺轉換爲米(1 英尺 = 0.3048 米)
關於工具的詳細算法:http://help.arcgis.com/zh-cn/arcgisdesktop/10.0/help/index.html#/na/009z000000z2000000/
五、可見性分析
1) 視點分析

視點工具生成的是在觀測點處能夠看到哪些位置的像元的二進制編碼信息。觀察點被限制爲最多16 個。此工具僅支持點要素輸入。
可見性信息存儲在 VALUE 項中。如果要顯示通過視點 3 能看到的所有柵格區域,就打開輸出柵格屬性表,然後選擇視點 3 (OBS3) 等於 1 而其他所有視點等於 0 的記錄。
例如,如下是7個觀測點的可視性分析結果的屬性表:

2) 視域

視域工具會創建一個柵格數據,以記錄可從輸入視點 或 視點折線要素 位置看到每個區域的次數。該值記錄在輸出柵格表的 VALUE 項中。

TIPS:控制可見性分析
通過在要素屬性數據集中指定不同的項,可限制所檢查的柵格區域。共有九項:SPOT、OFFSETA、OFFSETB、AZIMUTH1、AZIMUTH2、VERT1、VERT2、RADIUS1 和 RADIUS2。
附圖幫助理解:



這些值的默認值:
選項 默認值 參數意義
SPOT 使用雙線性插值進行估計 觀測點位置的高程
OFFSETA 1 觀測點高(例如,儀器高),必須爲正數
OFFSETB 0 各像元高(例如,目標高),必須爲正數
AZIMUTH1 0 觀測起始方位角
AZIMUTH2 360 觀測終止方位角
VERT1 90 觀測起始豎直角
VERT2 -90 觀測終止豎直角
RADIUS1 0 起始可見半徑
RADIUS2 無窮大 終止可見半徑
如果視點要素數據集是點要素類,則每個觀測點都可具有屬性表中的唯一一組觀測約束。如果視點要素數據集是折線要素類,則沿輸入折線的每個折點都會使用屬性表的折線記錄中包含的相同觀測約束。如果某項不存在,將使用默認值。

ArcGIS 的空間分析擴展中,提供了這樣一組鄰域分析工具:

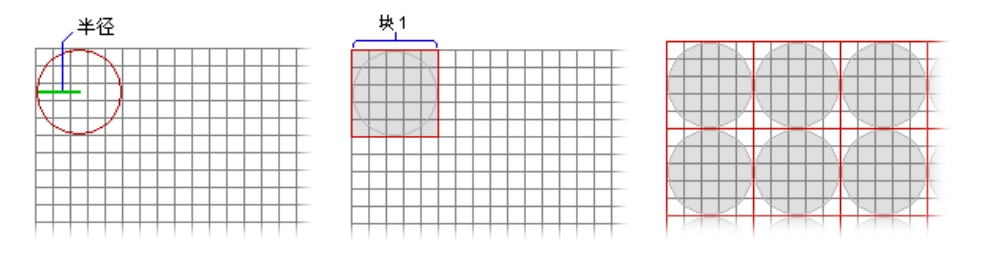
1. 塊統計(Block Statistics)
分塊統計,按照指定鄰域類型計算區域統計值,輸出區域爲指定鄰域類型的外接矩形。
以下爲鄰域的形式:
- NbrAnnulus({innerRadius}, {outerRadius}, {CELL | MAP})
- NbrCircle({radius}, {CELL | MAP}
- NbrRectangle({width}, {height}, {CELL | MAP})
- NbrWedge({radius}, {start_angle}, {end_angle}, {CELL | MAP})
- NbrIrregular(kernel_file)
- NbrWeight(kernel_file)
Irregular與Weight鄰域類型需要指定核文件( .txt 文件)。
可以進行統計的計算類型:
- MEAN/平均值;
- MAJORITY/衆數(出現次數最多的值);
- MAXIMUM/最大值;
- MEDIAN/中值;
- MINIMUM/最小值;
- MINORITY/少數(出現次數最少的值);
- RANGE/範圍(最大值和最小值之差)。
- STD/標準差。
- SUM/總和。
- VARIETY/變異度(唯一值的數量)。
例如,輸入爲圓形鄰域,輸出爲外接矩形的像元範圍:
2. 濾波器(Filter)
對柵格執行平滑(低通)濾波器或邊緣增強(高通)濾波器。
濾波器工具既可用於消除不必要的數據,也可用於增強數據中不明顯的要素的顯示。
低通濾波(平滑邊界):
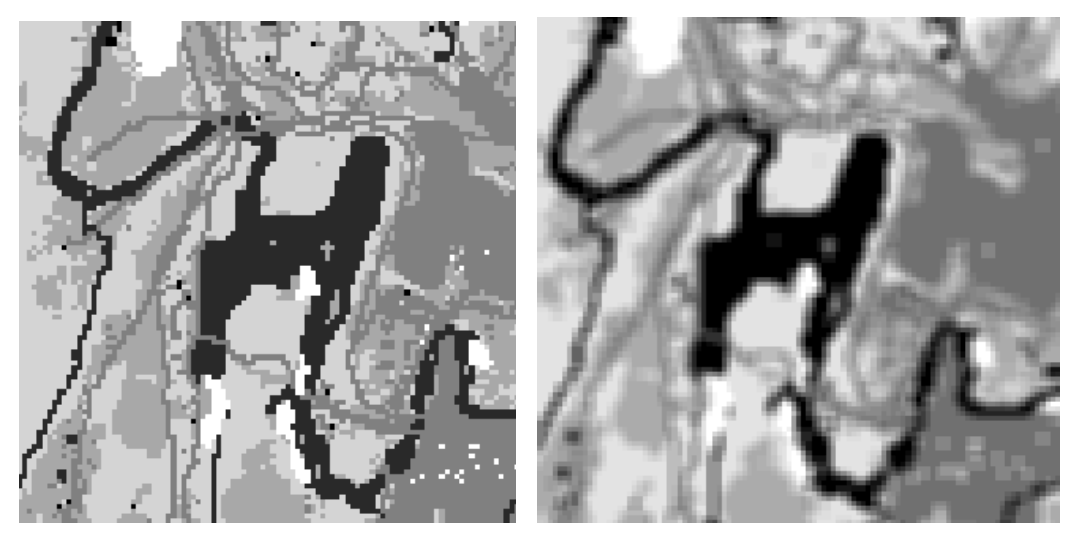
高通濾波(邊緣增強):

3. 焦點流(Focal Flow)
焦點流工具使用直接的 3 x 3 鄰域來確定一個像元的八個相鄰點中哪一個流向此像元。
焦點流也可以是液體由高到低流動的方向,也可以是定義的任何移動(比如污染物向污染濃度較低的地方流入)。
舉個例子,各個方向流向像元中心像元的值總和是最終值。

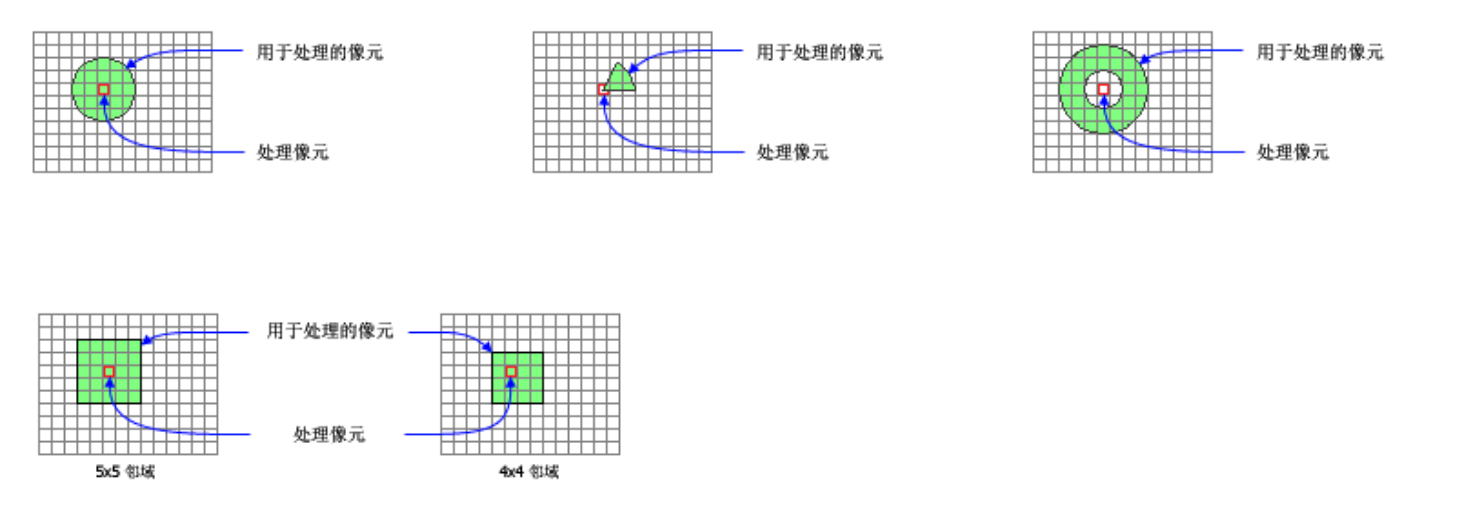
4. 焦點統計(Focal Statistics)
爲每個輸入像元位置計算其周圍指定鄰域內的值的統計數據。
統計類型與鄰域形狀與塊統計是相同的,區別在於,塊統計的輸出是整個鄰域的外接矩形範圍,而焦點統計的輸出,是鄰域內的焦點柵格。如下圖:
5. 線統計
工具用於爲每個輸出柵格像元周圍的圓形鄰域內所有線的指定字段值計算統計量。
可用的統計量類型有:均值、衆數、最大值、中位數、最小值、少數、範圍、標準差以及變異度。只有衆數、少數和中位數統計量是根據線長度進行加權的。
還沒有想到此工具的應用場景,以後有了再來追加。
6. 點統計
該工具類似於焦點統計工具,不同之處在於它直接對點要素而非柵格進行操作。直接對要素進行操作的其中一個優點在於,即使點距離過近,在轉換成柵格時點也不會丟失。
區域分析
空間分析擴展中,有關區域分析,提供瞭如下工具:
可以將其分爲這樣幾類:
一、確定區域中類的面積的工具
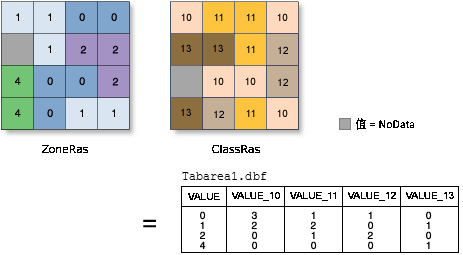
面積製表(Tabulate Area)
面積製表工具以表的形式進行輸出。在此表中:
1)區域數據集的每個唯一值均有一條記錄。
2)類數據集的每個唯一值均有一個字段。
3)每個記錄將存儲每個區域內每個類的面積。
TIPS:
使用此工具的常見錯誤:
1.“一個或多個輸入沒有關聯屬性表” 錯誤
此錯誤通常是由於區域輸入中沒有所需的屬性表而導致的。
如果區域輸入是一個柵格數據,請先使用構建柵格屬性表爲其創建一個屬性表。
如果區域輸入是一個要素數據集,則在內部轉換爲柵格的過程中會自動創建屬性表。
2.“無法分配內存” 錯誤
程序使用內部表執行面積計算。如果區域輸入的值域非常大(百萬級別),則處理這些表的內存需求可能會接近或超出指定的系統分頁文件大小。
如果所配置的內存總量不足,操作將失敗,並將顯示“無法分配內存”消息。此問題通常有兩種解決方法:
A) 您可增大虛擬內存設置以避免出現此錯誤。但是,要注意的是,工具執行完畢後,操作系統不會立即釋放其所佔用的虛擬內存。從而可能會降低計算機的總體性能。
B) 另一種方法是減小區域的值域(建議方法)。步驟如下:首先向區域屬性表添加一個新項和一個索引值,然後對該項使用面積製表,最後再將結果與原始區域輸入相關聯。
例如,如有僅有三個區域值 2,120,000、4,070,000 和 9,540,000,則可將它們除以 10,000,從而得到區域值 212、407 和 954。
3.輸出面積小於預計結果
輸出表中的某些面積值可能小於預計結果。
這通常與輸入中的 NoData 像元有關,經重採樣以匹配其他更爲粗糙的輸入之後,這些具有高分辨率的像元將變爲更大的 NoData 區域。
爲避免此情況,請對較粗糙的輸入柵格進行重採樣以使其與較精細的輸入柵格的分辨率相匹配,或者將像元大小柵格分析環境設置爲輸入的最小值。
二、填充指定區域的工具
區域填充(Zonal Fill )
輸入區域柵格數據可以爲整型或浮點型。使用權重柵格數據沿區域邊界的最小像元值填充區域。
區域填充可用作水文分析的一部分,將窪地填充至分水嶺邊界的最小高程。
此工具有待實踐,結合水文分析學習。
三、作用於區域形狀的工具
分區幾何統計(Zonal Geometry)
這裏說的區域是指具有相同值的所有像元。各區無需相連。柵格和要素數據集都可用於工具的輸入。
這個工具的亮點在於可以統計區的總面積(AREA)、總周長(PERIMETER)、厚度(THICKNESS)、質心(CENTROID)。其他三個比較好理解,我們看下厚度的概念。
分區厚度分析可計算輸入柵格上各個區域中最深或最厚點距其周圍像元的距離。
實際上,厚度就是可在各個區域中(不包括區域外部的任何像元)繪製的最大圓的半徑(以像元爲單位)。如下圖:

以表格顯示分區幾何統計(Zonal Geometry as Table)
將上述統計結果輸出到Table表中。
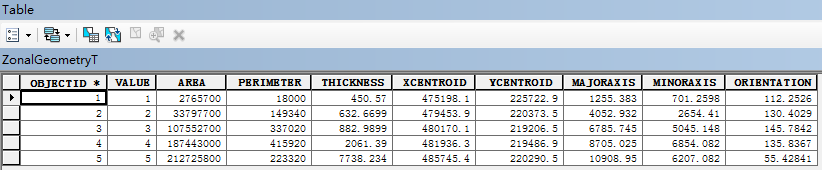
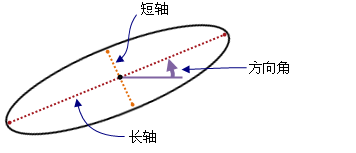
其中,最後三個參數,用於描述各個區域的橢圓近似的形狀。定義橢圓形狀和大小的參數爲長軸、短軸和方向。各橢圓的面積與爲其分配的區域的面積相等。
MAJORAXIS:長軸的長度;MINORAXIS:短軸的長度。以地圖單位表示。
ORIENTATION 值的單位爲度,取值範圍爲 0 至 180。方向定義爲 x 軸與橢圓長軸之間的角度。方向的角度值以逆時針方向增加,起始於東方向(右側水平位置)的 0 值,在長軸垂直時通過 90 位置。如果某個特定區域僅由一個像元組成,或者該區域爲單個像元方塊,那麼會將橢圓(在此情況下爲圓)的方向設置爲 90 度。
四、確定某輸入柵格值在另一區域中的頻數分佈的工具
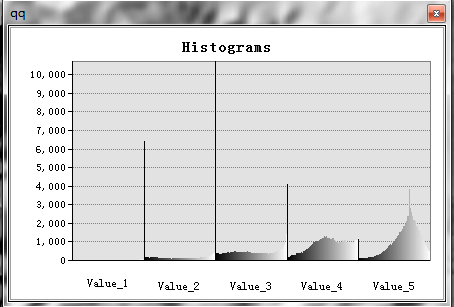
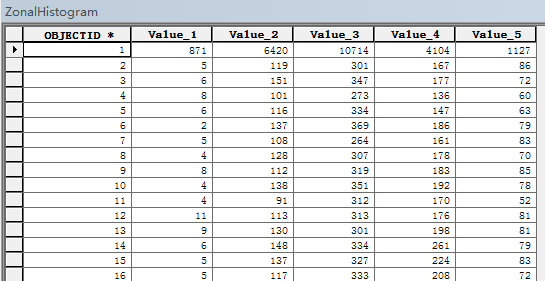
區域直方圖(Zonal Histogram)
創建顯示各唯一區域值輸入中的像元值頻數分佈的表和直方圖(Graph類型)。
區域字段必須爲整型或字符串類型。
五、作用於區域屬性的工具
分區統計(Zonal Statistics)
以表格顯示分區統計(**Zonal Statistics as Table**)
這兩個工具是,計算在另一個數據集的區域內柵格數據值的統計信息。這裏的區域定義爲輸入中具有相同值的所有區。各區無需相連。柵格和要素數據集都可用於區域輸入。
前者生成柵格數據,後者生成統計表。


多元分析
通過多元統計分析可以探查許多不同類型的屬性之間的關係。
有兩種可用的多元分析:分類(監督分類與非監督分類/Supervised&Unsupervised))和主成分分析/Principal Component Analysis (PCA)。
ArcGIS 提供瞭如下工具:

一、波段集統計工具(Band Collection Statistics)
柵格波段必須具有一個公共交集。如果不存在公共交集,則會出現錯誤,且不會創建任何輸出。
如果柵格波段的範圍不同,統計數據將以所有輸入柵格波段的共同的空間範圍來計算。默認情況下,像元大小爲輸入柵格的最大像元的大小;否則,將取決於柵格分析環境設置。
此工具計算每個圖層的基本統計測量值(最小值、最大值、平均值和標準差),如果勾選協方差和相關矩陣,還可以得到這兩個值。

二、創建特徵(Create Signature)
創建由輸入樣本數據和一組柵格波段定義的類的 ASCII 特徵文件。該工具可創建將用作其他多元分析工具的輸入參數的文件。
該文件由兩部分組成:
1) 所有類的常規信息,例如圖層數、輸入柵格名稱和類別數。
2) 每個類別的特徵文件,由樣本數、平均值和協方差矩陣組成。
三、編輯特徵(Edit Signature)
通過合併、重新編號和刪除類特徵來編輯和更新特徵文件。
輸入特徵重映射文件是 ASCII 文件,其每一行有兩列值與之對應,以冒號分隔。第一列是原始類 ID 值。第二列包含用於在特徵文件中更新的新類 ID。文件中的所有條目必須基於第一列以升序進行排序。
編輯特徵文件的寫法是固定的,如下:
只有需要編輯的類才必須被放入特徵重映射文件;任何在重映射文件中不存在的類將保持不變。
要合併一組類,原類 ID:新類 ID。
要刪除類特徵,使用 -9999 作爲該類第二列的值。
要重新編號,將類 ID 重新編號爲某個不存在於輸入特徵文件中的值。
示例:
1 2 3 4 |
2 : 3 4 : 11 5 : -9999 9 : 3 |
上例將使用 3 合併類 2 和 類 9,使用 11 合併類 4,並將刪除類 5。
四、樹狀圖(Dendrogram)
構造可顯示特徵文件中連續合併類之間的屬性距離的樹狀圖。
有關其工作原理,詳見:http://help.arcgis.com/zh-cn/arcgisdesktop/10.0/help/index.html#/na/009z000000q6000000/
五、最大似然法分類(Maximum Likelihood Classification)
最大似然法分類工具所用的算法基於兩條原則:
1) 每個類樣本中的像元在多維空間中呈正態分佈
2) 貝葉斯決策理論
TIPS:工具中有幾個參數需要注意:
reject_fraction:將因最低正確分配概率而得不到分類的像元部分。
默認值爲 0.0;將對每個像元進行分類。共有 14 個有效輸入:0.0、0.005、0.01、0.025、0.05、0.1、0.25、0.5、0.75、0.9、0.95、0.975、0.99 和 0.995。
a_priori_probabilities:指定將如何確定先驗概率。
- EQUAL — 所有類將具有相同的先驗概率。
- SAMPLE — 先驗概率將與特徵文件內所有類中採樣像元總數的相關的各類的像元數成比例。
- FILE — 先驗概率將會分配給輸入 ASCII 先驗概率文件中的各個類。
以下是通過三類樣本的特徵文件,分類的柵格數據的示例:

六、Iso 聚類(Iso Cluster)
Iso表示:iterative self-organizing –迭代自組織方法。
Iso聚類工具對輸入波段列表中組合的多元數據執行聚類。所生成的特徵文件(*.gsg)可用作生成非監督分類柵格的分類工具(例如最大似然法分類)的輸入。
類數的最小有效值爲二。不存在最大聚類數。通常情況下,聚類越多,所需的迭代就越多。
七、Iso 聚類非監督分類(Iso Cluster Unsupervised Classification)
此工具爲腳本工具,此工具結合了 Iso 聚類工具與最大似然法分類工具的功能。輸出經過分類的柵格。
八、類別概率(Class Probability)
如果發現分類中的某些區域被分配給某一類的概率不是很高,則說明可能存在混合類。
例如,根據分類概率波段,一個已被分類爲森林的區域屬於森林類的概率只有 55%。您又發現同一區域屬於草地類的概率卻有 40%。顯然,該區域既不屬於森林類也不屬於草地類。它更可能是一個森林草地混合類。對於使用分類概率工具生成的分類概率,最好檢查分類結果。
生成的多波段柵格數據的波段數等於類別數,每個波段表示某種分類的可能概率,像元值從0至100。
九、主成分分析(Principal Components)
對一組柵格波段執行主成分分析 (PCA) 並生成單波段柵格作爲輸出。此工具生成的是波段數與指定的成分數相同的多波段柵格。
主成分分析工具用於將輸入多元屬性空間中的輸入波段內的數據變換到相對於原始空間對軸進行旋轉的新的多元屬性空間。新空間中的軸(屬性)互不相關。之所以在主成分分析中對數據進行變換,主要是希望通過消除冗餘的方式來壓縮數據。
以上提到的幾個工具,在ArcGIS 10.x版本中,除了在ArcToolbox中可以找到,在 Image Classification 工具條中也可以找到對應的功能,如下圖:
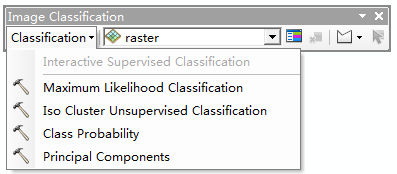
這個工具集涉及很多遙感的理論知識,僅僅使用工具是不夠的,後面需要多多學習……
插值分析
在實際工作中,由於成本的限制、測量工作實施困難大等因素,我們不能對研究區域的每一位置都進行測量(如高程、降雨、化學物質濃度和噪聲等級)。這時,我們可以考慮合理選取採樣點,然後通過採樣點的測量值,使用適當的數學模型,對區域所有位置進行預測,形成測量值表面。插值之所以可稱爲一種可行的方案,是因爲我們假設,空間分佈對象都是空間相關的,也就是說,彼此接近的對象往往具有相似的特徵。
ArcGIS的空間分析中,提供了插值(Interpolation)工具集,如下:

- 1. 反距離權重法(IDW–Inverse Distance Weighted)
- 2. 克里金法(Kriging)
- 3. 自然鄰域法(Natural Neighbor)
- 4. 樣條函數(Spline)
- 5. 含障礙的樣條函數(Spline with Barriers)
- 6. 地形轉柵格(Topo to Raster)
- 7. 趨勢(trend)
1. 反距離權重法(IDW–Inverse Distance Weighted)
此方法假定所映射的變量因受到與其採樣位置間的距離的影響而減小。
冪參數:
IDW主要依賴於反距離的冪值。基於距輸出點的距離,冪參數可以控制已知點對內插值的影響。冪參數是一個正實數,默認值爲 2,一般在0.5至3之間取值。隨着冪值的增大,內插值將逐漸接近最近採樣點的值。指定較小的冪值,將對距離較遠的周圍點產生更大影響,會產生更加平滑的表面。由於反距離權重公式與任何實際物理過程都不關聯,因此無法確定特定冪值是否過大。作爲常規準則,認爲值爲 30 的冪是超大冪,因此不建議使用。此外還需牢記一點,如果距離或冪值較大,則可能生成錯誤結果。
障礙:
障礙是一個用作可限制輸入採樣點搜索的隔斷線的折線 (polyline) 數據集。一條折線 (polyline) 可以表示地表中的懸崖、山脊或某種其他中斷。僅將那些位於障礙同一側的輸入採樣點視爲當前待處理像元。
注意事項:
(1)因爲反距離權重法是加權平均距離,所以該平均值不可能大於最大輸入或小於最小輸入。因此,如果尚未對這些極值採樣,便無法創建山脊或山谷。
(2)此工具最多可處理約 4,500 萬個輸入點。如果輸入要素類包含 4,500 萬個以上的點,工具可能無法創建結果。
工具執行截圖:

2. 克里金法(Kriging)
克里金法假定採樣點之間的距離或方向可以反映可用於說明表面變化的空間相關性。克里金法是一個多步過程;它包括數據的探索性統計分析、變異函數建模和創建表面,還包括研究方差表面。該方法通常用在土壤科學和地質中。
3. 自然鄰域法(Natural Neighbor)
可找到距查詢點最近的輸入樣本子集,並基於區域大小按比例對這些樣本應用權重來進行插值。該插值也稱爲 Sibson 或“區域佔用 (area-stealing)”插值。
4. 樣條函數(Spline)
使用二維最小曲率樣條法將點插值成柵格表面。生成的平滑表面恰好經過輸入點。
5. 含障礙的樣條函數(Spline with Barriers)
通過最小曲率樣條法利用障礙將點插值成柵格表面。障礙以面要素或折線要素的形式輸入。樣條函數法工具所使用的插值方法使用可最小化整體表面曲率的數學函數來估計值。
6. 地形轉柵格(Topo to Raster)
將點、線和麪數據插值成符合真實地表的柵格表面。
依據文件實現地形轉柵格(Topo to Raster by file)
通過文件中指定的參數將點、線和麪數據插值成符合真實地表的柵格表面。通過這種技術創建的表面可更好的保留輸入等值線數據中的山脊線和河流網絡。
7. 趨勢(trend)
使用趨勢面法將點插值成柵格曲面。趨勢表面會逐漸變化,並捕捉數據中的粗尺度模式。
以上是插值工具的簡單說明與比較,這些工具的背後都有龐大的理論基礎和複雜的算法,需要進一步學習整理和補充。
水文分析
接收雨水的區域以及雨水到達出水口前所流經的網絡被稱爲水系。流經水系的水流只是通常所說的水文循環的一個子集,水文循環還包括降雨、蒸發和地下水流。水文分析工具重點處理的是水在地表上的運動情況。“水文分析”工具用於爲地表水流建立模型。

盆域分析(Basin):創建描繪所有流域盆地的柵格。
填窪(Fill):通過填充表面柵格中的匯來移除數據中的小缺陷。
流量(Flow Accumulation):創建每個像元累積流量的柵格。可選擇性應用權重係數。
流向(Flow Direction):創建從每個像元到其最陡下坡相鄰點的流向的柵格。
水流長度(Flow length):計算沿每個像元的流路徑的上游(或下游)距離或加權距離。
匯(Sink):創建識別所有匯或內流水系區域的柵格。
捕捉傾瀉點(Snap pour point):將傾瀉點捕捉到指定範圍內累積流量最大的像元。
河流連接(Stream link):向各交匯點之間的柵格線狀網絡的各部分分配唯一值。
河網分級(Stream Order):爲表示線狀網絡分支的柵格線段指定數值順序。
柵格河網矢量化(Stream to Feature):將表示線狀網絡的柵格轉換爲表示線狀網絡的要素。
分水嶺(Watershed):確定柵格中一組像元之上的匯流區域。
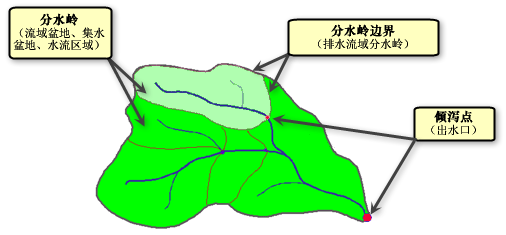
瞭解水系的術語,如下圖:
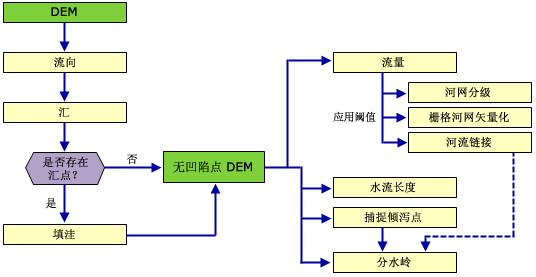
以下流程圖顯示的是從數字高程模型 (DEM) 中提取水文信息(如分水嶺邊界和河流網絡)的過程:
現在就以手中的這個DEM爲例來依次使用工具集中的工具,來學習這部分功能:
一、流向(Flow Direction)
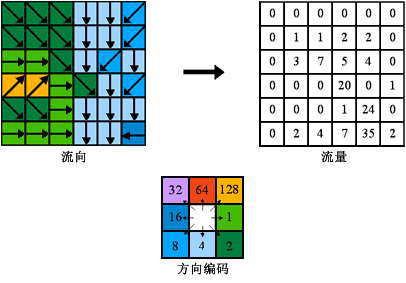
流向工具的輸出是值範圍介於 1 到 255 之間的整型柵格。從中心出發的各個方向值爲:
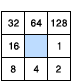
例如,如果最陡下降方向位於當前處理像元的左側,則將該處理像元的流向編碼將爲 16。
如果像元的 z 值在多個方向上均發生相同變化,並且該像元是凹陷點的一部分,則該像元的流向將被視爲未定義。此時,該像元在輸出流向柵格中的值將爲這些方向的總和。例如,如果 z 值向右(流向 = 1)和向下(流向 = 4)的變化相同,則該像元的流向爲 1 + 4 = 5。可以使用匯工具將具有未定義流向的像元標記爲凹陷點。

二、匯(Sink)
匯是指流向柵格中流向無法被賦予八個有效值之一的一個或一組空間連接像元。匯被視爲具有未定義的流向,並被賦予等於其可能方向總和的值。
匯工具的輸出是一個整型柵格,其中每個匯都被賦予一個唯一值。匯的編號介於 1 到匯的數量之間。
三、填窪(Fill)
通過填充表面柵格中的匯來移除數據中的小缺陷。
凹陷點是指具有未定義流域方向的像元;其周圍的像元均高於它。傾瀉點相對於凹陷點的匯流區域高程最低的邊界像元。如果凹陷點中充滿了水,則水將從該點傾瀉出去。
TIPS:有關填充的Z限制
要填充的凹陷點與其傾瀉點之間的最大高程差。如果凹陷點與其傾瀉點之間的 z 值差大於 z 限制,則不會填充此凹陷點。
默認情況下將填充所有凹陷點(不考慮深度)。
四、流量(Flow Accumulation)
創建每個像元累積流量的柵格。流量累積將基於流入輸出柵格中每個像元的像元數。
高流量的輸出像元是集中流動區域,可用於標識河道。流量爲零的輸出像元是局部地形高點,可用於識別山脊。
流量工具不遵循壓縮環境設置。輸出柵格將始終處於未壓縮狀態。
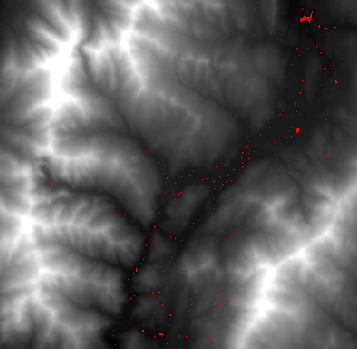
通過上面的填窪,求流向,得到如下流量圖,看到了河道:
五、河網分級(Stream Order)
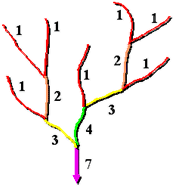
河網分級是一種將級別數分配給河流網絡中的連接線的方法。此級別是一種根據支流數對河流類型進行識別和分類的方法。僅需知道河流的級別,即可推斷出河流的某些特徵。
河網分級工具有兩種可用於分配級別的方法。這兩種方法由 Strahler (1957) 和 Shreve (1966) 提出。在這兩種方法中,始終將 1 級分配給上游河段。
Strahler 河流分級方法:
在 Strahler 法中,所有沒有支流的連接線都被分爲 1 級,它們稱爲第一級別。當級別相同的河流交匯時,河網分級將升高。
因此,兩條一級連接線相交會創建一條二級連接線,兩條二級連接線相交會創建一條三級連接線,依此類推。但是,級別不同的兩條連接線相交不會使級別升高。例如,一條一級連接線和一條二級連接線相交不會創建一條三級連接線,但會保留最高級連接線的級別。
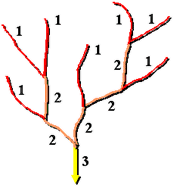
Shreve 河流分級方法:
Shreve 法考慮網絡中的所有連接線。與 Strahler 法相同,所有外連接線都被分爲 1 級。但對於 Shreve 法中的內連接線,級別是增加的。例如,兩條一級連接線相交會創建一條二級連接線,一條一級連接線和一條二級連接線相交會創建一條三級連接線,而一條二級連接線和一條三級連接線相交則會創建一條五級連接線。
因爲級別可增加,所以 Shreve 法中的數字有時指的是量級,而不是級別。在 Shreve 法中,連接線的量級是指上游連接線的數量。
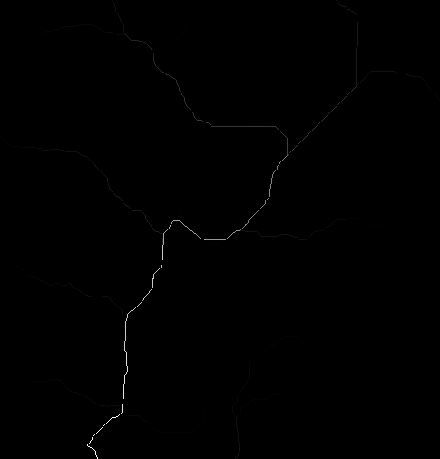
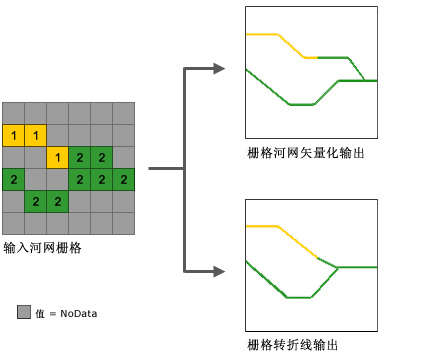
六、柵格河網矢量化(Stream to Feature)
柵格河網矢量化工具使用的算法主要用於矢量化河流網絡或任何表示方向已知的柵格線性網絡的柵格。
該工具使用方向柵格來幫助矢量化相交像元和相鄰像元。可將兩個值相同的相鄰柵格河網矢量化爲兩條平行線。
這與柵格轉折線 (Raster to Polyline) 工具相反,後者通常更傾向於將線摺疊在一起。下圖是兩者的對比:
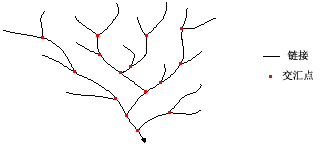
七、河流連接(Stream link)
向各交匯點之間的柵格線狀網絡的各部分分配唯一值。
“連接”是指連接兩個相鄰交匯點、連接一個交匯點和出水口或連接一個交匯點和分水嶺的河道的河段。
八、水流長度(Flow Length)
水流長度工具的主要用途是計算給定盆地內最長水流的長度。該度量值常用於計算盆地的聚集時間。這可使用 UPSTREAM 選項來完成。
該工具也可通過將權重柵格用作下坡運動的阻抗,來創建假設降雨和徑流事件的距離-面積圖。
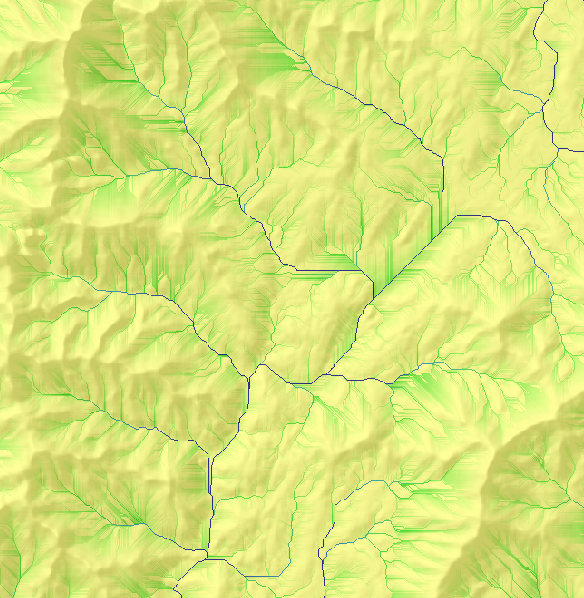
九、捕捉傾瀉點(Snap pour point)
捕捉傾瀉點工具用於確保在使用分水嶺工具描繪流域盆地時選擇累積流量大的點。
捕捉傾瀉點將在指定傾瀉點周圍的捕捉距離範圍內搜索累積流量最大的像元,然後將傾瀉點移動到該位置。
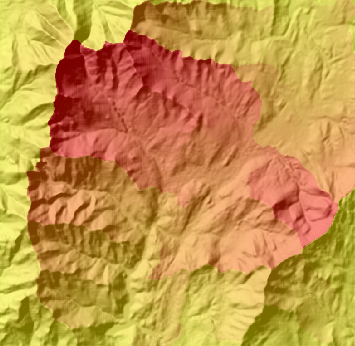
十、分水嶺(Watershed)
確定柵格中一組像元之上的匯流區域。
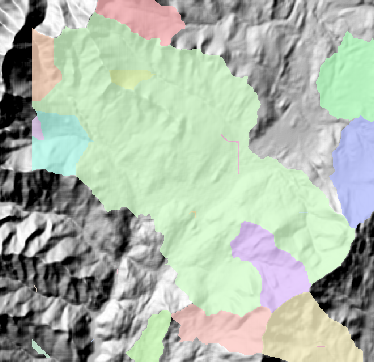
十一、盆域
創建描繪所有流域盆地的柵格。
通過識別盆地間的山脊線,在分析窗口中描繪流域盆地。通過分析輸入流向柵格數據找出屬於同一流域盆地的所有已連接像元組。通過定位窗口邊緣的傾瀉點(水將從柵格傾瀉出的地方)及凹陷點,然後再識別每個傾瀉點上的匯流區域,來創建流域盆地。這樣就得到流域盆地的柵格。
以下是盆域分析示例:

轉自穆曉燕博客,比較喜歡她寫的技術文章,講的很細,也很清楚:http://kikitamap.com/