




歡迎各位同學學習python信用評分卡建模視頻系列教程(附代碼, 博主錄製) :

(微信二維碼掃一掃報名)
什麼是訓練和測試分組? 這是將數據集分爲多個部分。我們使用一個零件訓練模型,而在另一個零件上測試其有效性。
在本文中,我們的重點是爲2種資產之間的關係建模的正確方法。
我們將檢查債券是否可用作標準普爾500指數的領先指標。
目錄
建模中的數據拆分是什麼?
什麼是訓練集?
什麼是驗證集?
什麼是測試儀?
爲什麼我們需要拆分數據?
前瞻性偏見
過度擬合
不合身
如何訓練我們的模型?
我們如何使用驗證集?
使用驗證集進行超參數調整
我們如何在測試集中測試模型?
什麼是交叉驗證,爲什麼要使用它?
標準數據的交叉驗證
K折交叉驗證
具有K折交叉驗證的超參數調整
問題數據的替代技術
分層K折
組K折
時間序列數據的交叉驗證
前向嵌套式交叉驗證
建模中的數據拆分是什麼?

數據拆分是將數據拆分爲3組的過程:
- 我們用於設計模型的數據(訓練集)
- 我們用於完善模型的數據(驗證集)
- 我們用來測試模型的數據(測試集)
如果不拆分數據,則可以使用與訓練模型相同的數據來測試模型。
例
如果該模型是專門爲2008年蘋果股票設計的交易策略,並且我們在2008年對其在蘋果股票上的有效性進行了測試,那麼它當然會做得很好。
我們需要根據2009年的數據進行測試。因此,2008年是我們的訓練集,2009年是我們的測試集。
回顧什麼是訓練,驗證和測試集…
什麼是訓練集?
訓練集是我們分析(訓練)以設計模型中的規則的數據集。
訓練集也稱爲樣本內數據或訓練數據。
什麼是驗證集?
驗證集是我們訓練模型時用來評估這些規則對新數據的執行情況的有效數據。
它也是我們用來調整模型參數和輸入特徵的集合,以便爲我們提供新數據可能獲得的最佳性能。
什麼是測試儀?
測試集是我們沒有用來訓練模型的數據集,也不是在驗證集中使用的數據集,這些信息用來告知我們對參數/輸入特徵的選擇。
一旦我們決定了最終模型,我們將把它用作最終測試,以最佳估計我們的模型在全新數據上的成功程度。
測試集也稱爲樣本外數據或測試數據。
爲什麼我們需要拆分數據?
爲了防止前瞻性偏見,過度擬合和過度擬合。
- 前瞻性偏見:基於未知數據構建模型。
- 過度擬合:這是設計模型的過程,該模型是如此緊密地適應歷史數據,以至於將來變得無效。
- 欠擬合:這是設計模型的過程,該模型過於寬鬆地適應了歷史數據,以至於將來變得無效。
前瞻性偏見
讓我們用一個例子來說明。
這是2013年至2020年亞馬遜的股票表現。
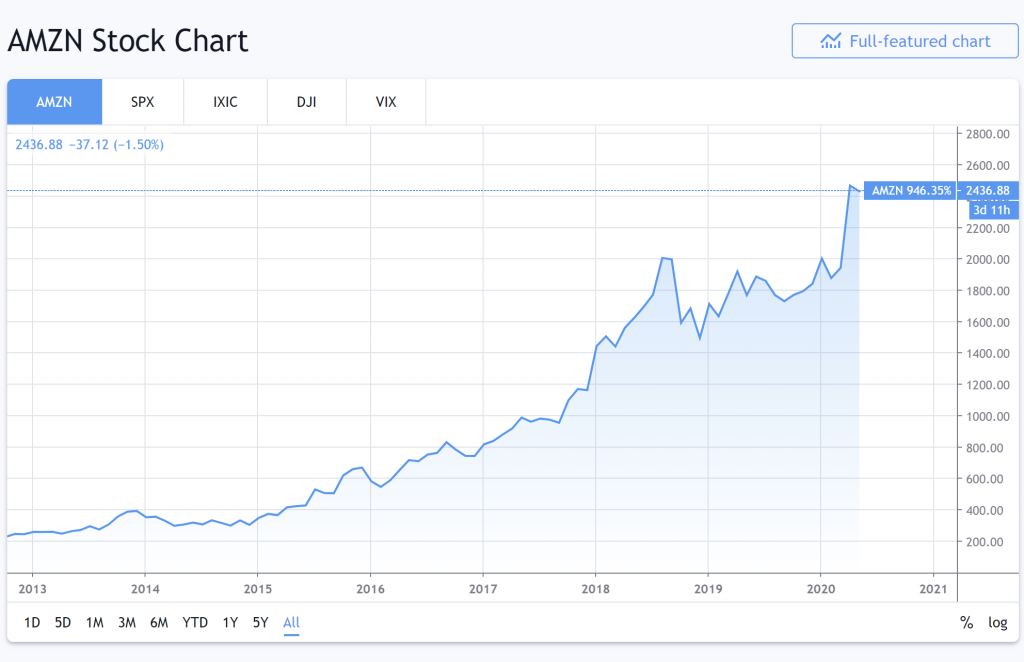
資料來源:Tradingview.com
哇,它的發展趨勢相當平穩。我將設計一種交易模型,隨着它的發展趨勢向亞馬遜投資。
然後,我在同一數據集(2013年至2020年)上測試我的交易模型。
令我驚訝的是,該模型的表現出色,我賺了很多假想的錢。你不說!
從2013年開始測試交易模型時,它知道亞馬遜2014年的股票表現如何,因爲在設計交易模型時我們考慮了2014年的數據。
據說該模型已經“展望了未來”。
因此,我們的模型存在前瞻性偏差。我們基於不應該知道的數據構建了一個模型。
過度擬合
從最簡單的意義上講,訓練時,模型會嘗試學習如何將輸入要素(可用數據)映射到目標(我們要預測的目標)。
過度擬合是用於描述模型何時對訓練數據“太好”學習了這種關係的術語。
“太好了”,我們的意思是說它已經太緊密地瞭解了這種關係-它所看到的趨勢/相關性/聯繫比實際存在的要多。
我們可以將其視爲一個模型,該模型吸收了訓練數據中過多的“噪聲”,學習將訓練數據的確切和非常特定的特徵映射到目標,而實際上這些都是一次性事件/關聯,不能代表數據中通常存在的更廣泛的模式。
這樣,該模型對於訓練數據表現非常好,但與新數據相比卻比較困難。從訓練數據中得出的模式不能很好地推廣到新的看不見的數據。
這幾乎總是使模型過於複雜的結果-使其相對於數據中存在的“實際”數量的模式具有太多的規則和/或特徵。這也可能是由於我們要訓練的觀測值(訓練數據)具有太多特徵的結果。
例如,在極端情況下,假設我們有1000條訓練數據,而模型中有1000條“規則”。從本質上講,它可以學習構建說明以下內容的規則:
- 規則1:將所有特徵非常接近x1,y1,z1(恰好是訓練數據1的特徵)的數據映射到訓練數據1的目標值。
- 規則2:將特徵非常接近x2,y2,z2的所有數據映射到訓練數據的目標值2。
- …
- 規則1000:將特徵非常接近x1000,y1000,z1000的所有數據映射到訓練數據1000的目標值。
這樣的模型在訓練數據上將表現出色,但在任何與訓練示例略有不同的新數據上可能幾乎毫無用處。
您可以在這裏閱讀有關過度擬合的更多信息:什麼是過度擬合交易?
不合身
相比之下,欠擬合是模型過於不明確的情況。也就是說,它還沒有真正瞭解到訓練數據和目標變量之間的任何有意義的關係。
這樣的模型在訓練數據或任何新數據上都不會表現良好。
在實踐中,這比過度擬合更爲罕見,並且通常是因爲模型太簡單了,例如,假設將線性迴歸模型擬合到非線性數據,或者將最大深度爲2的隨機森林模型擬合到具有存在許多功能。
通常,您想開發一個模型,以捕獲訓練數據中儘可能多的模式,這些模式仍然可以很好地概括(適用於)新的看不見的數據。
換句話說,我們希望模型既不過度擬合也不過度擬合,而恰到好處。
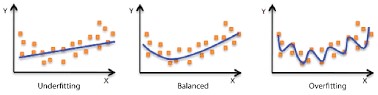
如何訓練我們的模型
要了解這些概念如何在現實中發揮作用,讓我們嘗試構建一個實際模型。
我們的模型:檢查昨天的2-10債券價差能否預測今天的SPX價格。
我們將使用一些稱爲:
- “ 2-10債券利差”,即10年期美國國庫券固定期限利率與2年期美國國庫券固定期限利率之間的差額)和
- “ SPX,SPCFD:比較”,它是500家最大的美國上市公司的市值加權指數。
在視覺上,我們的數據如下所示:
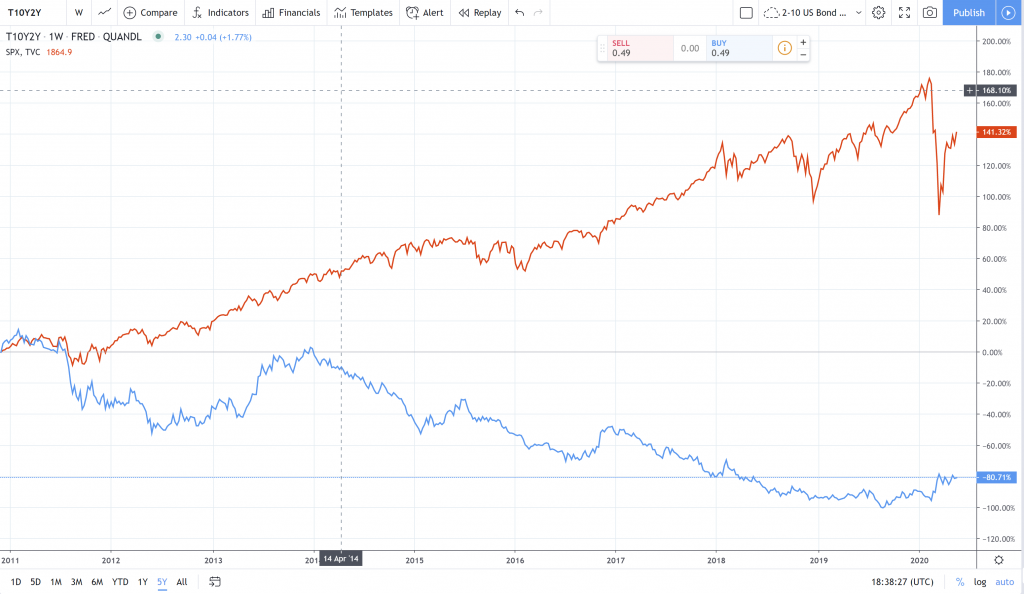
藍色債券利差,紅色SPX價格
讓我們繼續進行一些示例性的市場數據,以2日至10年期美國國債兌SPX債券的收盤價差:
import numpy as np
import pandas as pd
from pathlib import Path
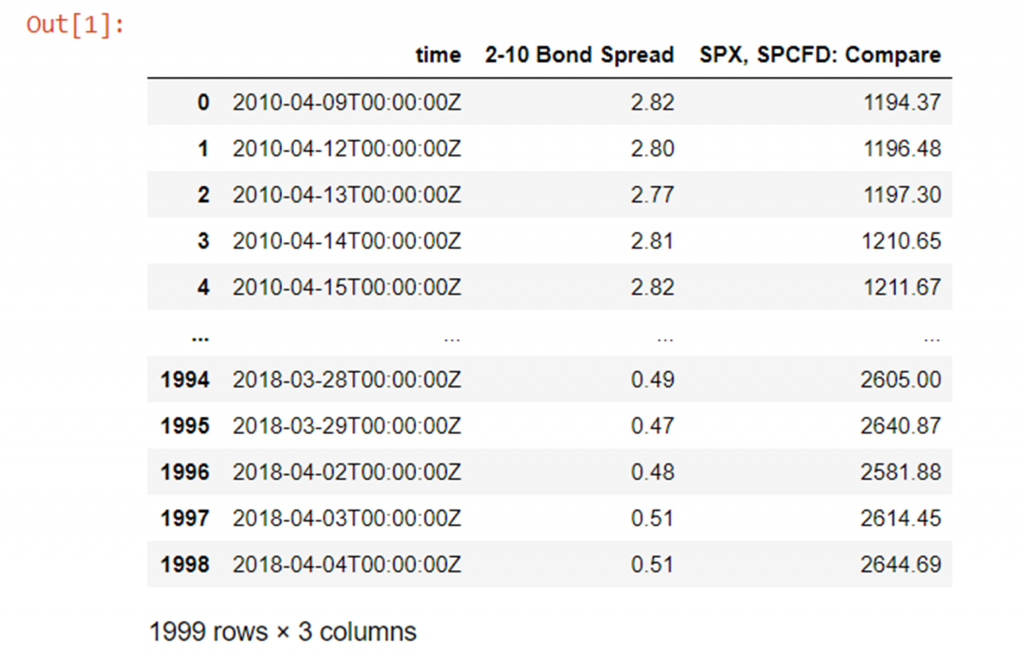
df = pd.read_csv(Path("QUANDL_FRED_T10Y2Y, 1D 80PERCENT.csv"))
請注意,在進行任何建模之前,我們要使2-10(t-1)的SPX(t)迴歸,因此將2-10美國債券的利差滯後1天,因爲正如我們所說,我們要檢查昨天的2- 10值對今天的SPX值有任何影響。我們還應該使用收益(從最後一天開始的比例價格變化),而不是今天的實際價格。
改變債券利差,以便使昨天的債券利差相對於今天的價格進行迴歸:
df['2-10 Bond Spread'] = df['2-10 Bond Spread'].shift(1)
從昨天的價格而不是今天的絕對價格減去(百分比)變化的迴歸:
df['returns']=df['SPX, SPCFD: Compare']/df['SPX, SPCFD: Compare'].shift(1) - 1 df

現在,通過刪除第一行進行清理,因爲第一行現在在“ 2-10 Bond Spread”和“ returns”列中均不適用,因爲我們將“ 2-10 Bond Spread”上移了一個:
df = df[1:] # remove first row with an N/A df

最後,將數據幀的索引設置爲時間列的值而不是任意整數將很方便,因爲數據的時間順序很重要。
請注意,時間列的類型當前爲字符串(您可以使用type(x)函數自行檢查),因此我們首先將其設置爲datetime64,然後將索引設置爲時間列:
df['time'] = df['time'].astype('datetime64[ns]') # change "time" column type from str to datetime64
df.set_index('time', inplace=True) # set time column as the index
df

現在,讓我們使用所有數據來構建我們的模型,然後使用相同的數據測試我們的模型,看看會發生什麼。
首先,爲了說明起見,從sklearn導入一個非常易於使用的迴歸模型,而mean_squared_error函數可幫助我們生成均方根評估函數以測試模型:
from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error
請注意,在sklearn中,您經常會找到同一算法的“迴歸”和“分類”版本(例如,在本例中爲RandomForest)。當您要預測有限數量的類別(例如馬,鞋,鴨)時,您只想使用分類器版本;而當您嘗試預測連續的數值輸出時(如我們在此處),則只需要使用迴歸器版本。
現在讓我們創建訓練數據框和目標數據框:
# set the training data columns and target variable y_train = df["returns"] X_train = df.drop(columns=["SPX, SPCFD: Compare", "returns"])
並初始化帶有幾個超參數值集的RandomForestRegressor。注意:
- random_state只是控制算法的初始化參數-如果我們明確定義它,我們將獲得完全可重複的結果,否則將對其進行隨機選擇,因此最終模型每次都會略有變化
- max_depth是一個變量,用於控制在森林中生成的決策樹的深度-深度越大,模型可以在數據上進行的拆分越多-作爲2 ^(max_depth)的函數,使模型變得更加複雜
- n_estimators是“森林”中單個決策樹的數量
random_forest = RandomForestRegressor(max_depth=5, n_estimators=100, random_state=1)
讓我們在所有數據上擬合(訓練)模型:
random_forest.fit(X_train, y_train)
並在完全相同的相同數據上檢查擬合模型的均方根精度:
root_mean_squared_error = np.sqrt(mean_squared_error(y_train, random_forest.predict(X_train))) root_mean_squared_error
0.009310731251200473好的,所以我們的模型的基準性能有0.00993的誤差。
請注意,這非常可怕,因爲平均回報率(您可以使用(np.abs(y_train).mean()進行計算)爲0.0065,因此我們的平均誤差約爲每日平均回報率的143%,因此顯然我們的模型不是很準確。
不過,這並不令人感到意外,因爲我們只使用單個數值(昨天的債券利差)和未經校準的(也許是不合適的類型)模型來估計每日收益-如果市場真的很容易預測我們都會有錢的!
不過,這並不重要,出於本文的目的,我們將忽略客觀上令人震驚的結果-重點是使用數據集爲我們正在探索的主題提供說明性代碼,而不是模型的實際技能。
無論如何,我們仍然可以擺弄模型的超參數來嘗試改善性能。
例如,我們可以增加隨機森林的最大深度(如果我們記得允許模型對數據進行更多分割,從而變得更加複雜):
random_forest = RandomForestRegressor(max_depth=10, n_estimators=100, random_state=1) random_forest.fit(X_train, y_train) root_mean_squared_error = np.sqrt(mean_squared_error(y_train, random_forest.predict(X_train))) root_mean_squared_error
0.009083679274932605好的,大約有2.4%的改善。
並使其更加複雜:
random_forest = RandomForestRegressor(max_depth=50, n_estimators=100, random_state=1) random_forest.fit(X_train, y_train) root_mean_squared_error = np.sqrt(mean_squared_error(y_train, random_forest.predict(X_train))) root_mean_squared_error
0.008943288173833334從我們的出發點開始,現在幾乎提高了4%。
因此,既然我們已經對其進行了一些改進,那麼當暴露於全新數據時該模型的性能如何?
在這裏,我們將假裝在實時情況下部署模型,並在野外遇到了一些新數據。我們將從同一個源(但從訓練數據開始按時間順序向前移動的時間點)加載更多數據,並執行完全相同的預處理步驟:
unseen_data = pd.read_csv(Path("unseen_data.csv"))
unseen_data['2-10 Bond Spread'] = unseen_data['2-10 Bond Spread'].shift(1)
unseen_data['returns']= unseen_data['SPX, SPCFD: Compare']/unseen_data['SPX, SPCFD: Compare'].shift(1) - 1
unseen_data = unseen_data[1:]
unseen_data['time'] = unseen_data['time'].astype('datetime64[ns]') # change "time" column type from str to datetime64
unseen_data.set_index('time', inplace=True) # set time column as the index
unseen_data

最後,再次設置輸入變量和目標變量,並測試一些新數據的性能:
y_unseen = unseen_data["returns"] X_unseen = unseen_data.drop(columns=["SPX, SPCFD: Compare", "returns"]) root_mean_squared_error = np.sqrt(mean_squared_error(y_unseen, random_forest.predict(X_unseen))) root_mean_squared_error
0.018704827013423832這使我們的均方根誤差約爲我們以前用於訓練和測試的數據的〜2 09%,不如我們可能希望/期望的那麼好……
這清楚地表明瞭過度行動。
我們如何使用驗證集?
因此很明顯,我們不能僅僅使用模型的訓練數據來評估模型在新數據上的表現。
我們需要根據一些未經訓練的數據來評估其性能,以更好地瞭解其在野外的性能。
輸入驗證集。
從現在開始,我們將訓練數據分爲兩組。我們將保留大部分數據用於訓練,但會分離出一小部分以供驗證。
一個好的經驗法則是在70:30到80:20 training:validation拆分之間使用一些東西。
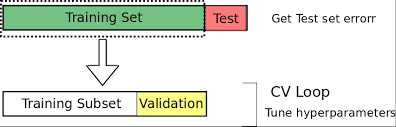
爲此,我們可以簡單地將數據長度的特定部分四捨五入爲整數,然後將數據幀分成兩部分,如下所示:
y = df["returns"] X = df.drop(columns=["SPX, SPCFD: Compare", "returns"]) train_fraction = 0.8 split_point = int(train_fraction *len(X)) # (len(X) and len(y) are the same anyway) X_train = X[0:split_point] X_valid = X[split_point:] y_train= y[0:split_point] y_valid= y[split_point:]
或者如您在許多地方可能看到的那樣,使用sklearn有用的預建train_test_split函數,如下所示:
from sklearn.model_selection import train_test_split X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8,test_size=0.2, random_state=101)
如果只填寫一個,則train_size和test_size會自動互補,而random_state是數據拆分方式的種子-如果將來使用相同的種子,則可以確保每個數據中的數據完全相同訓練和驗證集與以前一樣。
print("len(df): {}, split_point: {}, len(X_train): {}, len(X_valid): {}, len(y_train): {}, len(y_valid): {}".format(len(df), split_point, len(X_train), len(X_valid), len(y_train), len(y_valid)))
len(df): 1998, split_point: 1598, len(X_train): 1598, len(X_valid): 400, len(y_train): 1598, len(y_valid): 400
驗證集實質上使我們能夠檢查模型的“過度擬合”或“不足擬合”。
它使我們既可以將模型的複雜性調整到最佳點,又可以更好地估計該模型在不可見數據的情況下的性能,因爲該模型不使用驗證數據進行訓練。
請注意,驗證準確性將比訓練準確性低是完全正常的(甚至是可能的)。實際上,如果它們非常相似,則可以很好地表明您的模型可能不夠複雜(擬合不足)。
也就是說訓練的準確性並不重要。
唯一重要的是獲得最佳的驗證準確性,因爲這實際上在某種程度上反映了模型在野外的性能。
一般而言,增加模型複雜度應(通常不考慮隨機性)通常會導致訓練精度提高,並且隨着模型發現更多更好的模式,增加模型複雜度還會導致驗證精度提高。
但是,最終,這些模式將變得過於特定於訓練數據,無法很好地推廣,因此驗證準確性將開始下降。
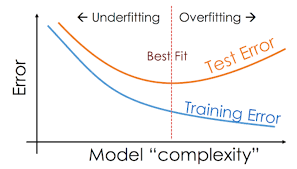
使用驗證集進行超參數調整
我們將使用驗證集將模型的複雜性磨練到最佳位置,如下圖所示:
現在讓我們開始處理我們的數據。
下面,我們簡單地遍歷max_depths列表,將模型擬合到每個最大深度,然後評估訓練集和驗證集上的誤差並繪製出這些圖。我們要更改以更改模型複雜度的唯一變量是max_depth,其他所有內容每次都保持不變,因此max_depth唯一負責模型的複雜性。
Matplotlib.pyplot是Python中使用的“標準”繪圖庫。如果您以前從未遇到過,這是製作一些簡單繪圖的快速速成課程:https : //matplotlib.org/tutorials/introductory/pyplot.html
import matplotlib.pyplot as plt
train_errors = []
valid_errors = []
param_range = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,20,30,40,50,75,100]
for max_depth in param_range:
random_forest = RandomForestRegressor(max_depth=max_depth, n_estimators=100, random_state=1)
random_forest.fit(X_train, y_train)
train_errors.append(np.sqrt(mean_squared_error(y_train, random_forest.predict(X_train))))
valid_errors.append(np.sqrt(mean_squared_error(y_valid, random_forest.predict(X_valid))))
plt.xlabel('max_depth')
plt.ylabel('root mean_squared_error')
plt.plot(param_range, train_errors, label="train rmse")
plt.plot(param_range, valid_errors, label="validation rmse")
plt.legend()
plt.show()

正如預期的那樣,隨着我們增加max_depth(增加模型的複雜性),訓練精度在整個1-100範圍內一直在不斷提高-首先是迅速提高,但之後仍然緩慢提高。
另一方面,驗證準確性會立即變差,並且隨着我們增加max_depth而不會停止變差。
這表明模型已經“太複雜”(或處於最佳複雜度),最大深度爲1。
通常,我們希望驗證準確性至少會提高一小段時間,然後再從一個非常簡單的模型迴歸到非常複雜的模型,但是通常,我們還是希望使用包含多個數據的訓練數據來學習從這樣的最大深度1開始,返回最佳驗證性能幾乎可以肯定是輸入數據非常簡單和/或缺乏訓練數據的結果。
無論如何,讓我們繼續以max_depth爲1重新擬合模型,並準確查看其性能。
請注意,由於我們擁有理論上最好的max_depth,因此我們將恢復爲在此處使用X和y(完整數據集)來重新訓練模型,從而使訓練數據與第一個針對未見數據截斷而預測的模型的數據完全匹配如此小的數據集的20%(因爲我們最近進行了訓練:驗證拆分)可能會導致我們的模型在不考慮最大深度的情況下表現更差。這樣我們就可以保持比較一致:
random_forest = RandomForestRegressor(max_depth=1, n_estimators=100, random_state=1) random_forest.fit(X, y) root_mean_squared_error = np.sqrt(mean_squared_error(y, random_forest.predict(X))) root_mean_squared_error
0.00942170960852716最大深度爲50時,比我們在訓練集上取得的最好成績差約5.4%
root_mean_squared_error = np.sqrt(mean_squared_error(y_unseen, random_forest.predict(X_unseen))) root_mean_squared_error
0.017679233094329314但是,看不見的數據要好約5.5%!
在這裏,我們已成功地將驗證集用於這兩個方面:
- 讓我們更好地估計如何處理看不見的數據。
- 通過減少過擬合/欠擬合來改善樣本外(看不見)數據的性能。
我們如何在測試集中測試模型?
因此,如果模型從不對驗證數據進行訓練,那麼驗證數據不是對模型在野外如何執行的完美估計嗎?
好吧,差不多。
但不完全是。
原因是,通過使用驗證數據將我們的模型調整爲最佳的通用性能,我們固有地顯示出對模型超參數值和專門針對此驗證集優化性能的數據特徵的輕微偏差。
實際上,我們已經過度擬合了驗證集。
請注意,與訓練數據相比,該數據集的過擬合程度要小得多,並且驗證數據集的性能通常會爲野外性能提供一個粗略的估算(假設您創建的驗證數據集沒有數據泄漏,更多內容請參見稍後!)。
正是出於這個原因,雖然我們從現有的數據中分離出進一步的測試集,我們不碰,直到我們有我們的模型的最終版本完全功能設計和調整。
進行其他拆分後,原始可用數據現在應如下所示:
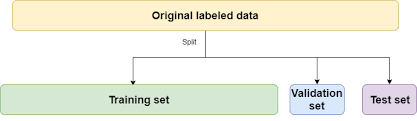
我們現在可以使用類似70:20:10的比例。我們可以使用任何想要分割數據幀的方式,但是一個選擇是隻使用train_test_split()兩次。
請注意,0.875 * 0.8 = 0.7,所以這兩個拆分的最終效果是將原始數據按70:20:10的比例拆分爲訓練/驗證/測試集:
# split the full data 80:20 into training:validation sets
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, random_state=101)
# split training data 87.5:12.5 into training:testing sets
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, train_size=0.875, random_state=101)
print("len(X): {} len(y): {} \nlen(X_train): {}, len(X_valid): {}, len(X_test): \
{} \nlen(y_train): {}, len(y_valid): {}, len(y_test): {}".format(len(X), len(y),\
len(X_train), len(X_valid), len(X_test), len(y_train), len(y_valid), \
len(y_test)))
len(X): 1998 len(y): 1998
len(X_train): 1398, len(X_valid): 400, len(X_test): 200
len(y_train): 1398, len(y_valid): 400, len(y_test): 200我們可以根據需要花費大量時間和精力來優化驗證集的性能。
但是我們必須誠實地說-當我們完成時,我們必須完成,並且必須將隨後在測試集上得到的任何結果作爲我們對新數據的可能結果。
然後,我們無法繼續嘗試再次進行優化以進一步提高測試集的性能。這樣做將再次產生過度擬合的偏見。
什麼是交叉驗證,爲什麼要使用它?
太好了,因此我們現在將數據分爲三種方式-我們將大量數據用於訓練,保留合理數量的數據進行驗證,並保留少量用於最終測試的保留數據。
但是您可能會想,我們現在是否會丟失大量可用於訓練的數據?這會不會降低我們的模型精度?
另外,有什麼方法可以避免過度擬合驗證集?
那麼,所有三個問題的答案都是肯定的!
除了使用單個驗證集,我們還可以使用許多驗證集。
我們可以進行許多訓練:驗證拆分,並循環我們每次用於驗證的數據的哪一部分,以便最終,在每次訓練:驗證拆分相結合時,所有數據至少已被用於驗證一次,並且至少已被用於一次驗證訓練。
對於標準數據和時間序列數據,執行交叉驗證的方式有所不同,但通常可以爲我們帶來以下好處:
- 我們(在多個分組中)將100%的訓練+驗證數據用於訓練,這可以消除初始訓練集可能高度偏向並且包含許多極端數據類型/發生率示例,或者不包含任何示例的問題重要數據類型/出現的示例
- 我們要(逐段)驗證所有數據:不要屈服於小型驗證集中的任何高方差實例,在這些情況下,驗證集中同樣包含異常事件的異常高或異常低。
- 我們將對所有數據的平均性能進行平均,從而使我們對模型技能的估計以及對模型對輸入數據的擾動有多大的實際印象更加自信。
- 由於我們試圖在許多驗證集(而不是一個特定的驗證集)上最大化平均性能,因此我們被迫自動構建了一個不太適合的模型(因此更具通用性),因此我們不能無意中調整僅用於超參數設置的設置。適用於非常具體的驗證集。
標準數據的交叉驗證
我們可以通過幾種不同的方式執行交叉驗證,但是對於非時間序列數據,最流行(且易於理解和有效)的技術之一是K折交叉驗證。
請注意,這裏確實有時間序列數據,因此K折交叉驗證實際上是不適合使用的技術(由於原因,我們將在短期內進行討論),但現在爲了生成一些數據,我們暫時將其忽略。具有相同數據集的示例代碼。
K折交叉驗證
通過K折交叉驗證,我們將訓練數據分成了k個大小相等的集合(“折數”),將一個集合作爲我們的驗證集合,並將另一個集合合併爲我們的訓練集合。然後,我們循環使用哪個摺疊作爲驗證集,直到我們進行了k次訓練和驗證爲止-每次使用唯一的train:validation拆分。
您可以選擇任何喜歡的k值,但根據所有數據科學家的集體經驗,k = 5或k = 10(以及介於兩者之間的所有值)是常見且有效的選擇:k = 5表示80:20的訓練:validation split和k = 10 a 90:10 split等
該過程可以總結如下:
- 從數據中分離出最終的保持測試集(如果我們有大量數據,則可能約爲10%)。
- 隨機混洗剩餘數據。
- 將此數據拆分爲k個大小相等的集合/摺疊。
- 對於每個獨特的摺痕:
- 使用此摺疊作爲驗證摺疊
- 結合其他k-1折作爲訓練數據
- 用訓練數據擬合模型
- 用驗證倍數評估模型
- 保留評估得分,丟棄模型,並以新的驗證折數從4.1重新開始
- 根據整個k個驗證分數評估模型,如果您不滿意,請進行調整並從1開始重複。
- 當您最終滿意時,將所有k摺合併爲一個完整的訓練數據集,再次進行訓練,然後對保持測試集進行最終測試。
從圖形上看,該過程如下所示:
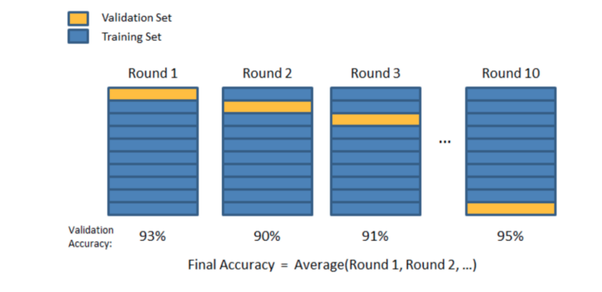 約瑟夫·尼爾森(Joseph Nelson)的視覺表示-@josephofiowa
約瑟夫·尼爾森(Joseph Nelson)的視覺表示-@josephofiowa
因此,現在整個訓練/驗證/測試拆分過程如下所示:
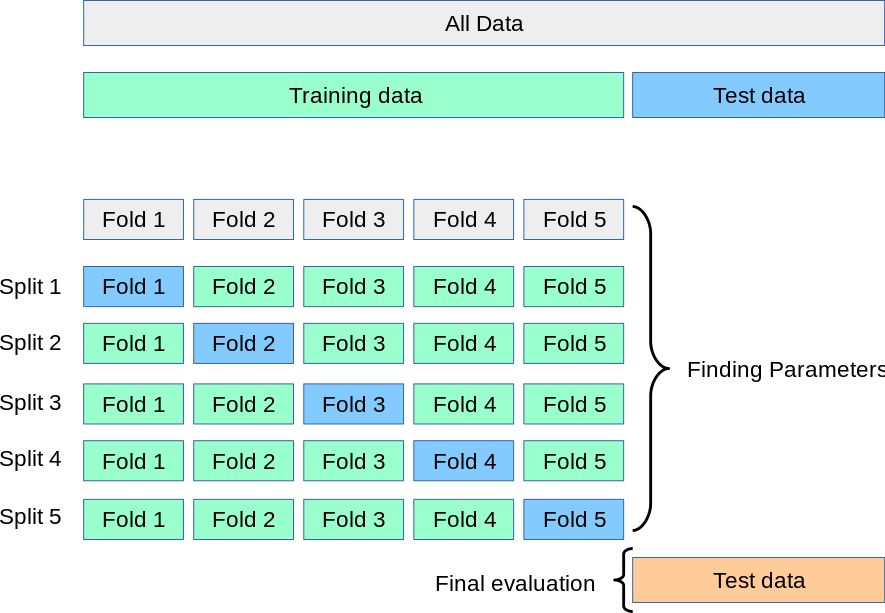
https://scikit-learn.org/stable/modules/cross_validation.html
讓我們嘗試將K折交叉驗證與我們的數據集結合起來!
雖然我們可以編寫許多(簡單但冗長的)代碼來從頭開始實現這樣的過程,但幸運的是sklearn庫再次藉助方便的預構建函數來幫助我們!
(您可以在此處瞭解更多信息:https : //scikit-learn.org/stable/modules/cross_validation.html)
from sklearn.model_selection import cross_val_score
這個神奇的功能將爲我們非常輕鬆地處理整個過程,但是請深入閱讀文檔以瞭解其工作原理以及可用的變體!
無論如何,讓我們向模型傳遞cross_val_score()函數以及所需參數,X和y數據(應該是所有數據減去最終保持測試集),一種評分方法(我們將使用neg_mean_squared_error並調整爲RMSE),以及要使用的k值(即“ cv”參數):
cross_val_scores = cross_val_score(RandomForestRegressor(max_depth=1, n_estimators=100, random_state=1),\
X, y, scoring='neg_mean_squared_error', cv=5)
將分數從負均方誤差調整爲均方根誤差,以與我們之前的分數一致:
cross_val_scores = np.sqrt(np.abs(cross_val_scores))
print(cross_val_scores)
print("mean:", np.mean(cross_val_scores))
[0.01360711 0.00861119 0.00715738 0.00947426 0.0067502 ]
mean: 0.009120025719774182如您所見,針對不同的訓練,我們的驗證分數波動很大:驗證分裂!最糟糕的錯誤是〜102% 更大的比最小的!
這些瘋狂的差異可能主要是由於我們的數據集太小而引起的,以及K折交叉驗證不適用於時間序列數據的事實(因此,我們的某些訓練:驗證拆分可能比其他方法更合適),但事實並非如此。着重說明了性能在各個分割之間的差異可能很大,因此對所有模型/分割取平均值非常重要,因爲最終所有數據都會用於一次驗證!
請注意,作爲一個事實,即很小的驗證集會導致較高的方差(因爲其中包含的少量數據每次拆分都會發生很大變化),我們可以設置k = 50並再次運行交叉驗證:
cross_val_scores = cross_val_score(RandomForestRegressor(max_depth=1, n_estimators=100, random_state=1),\
X_train, y_train, scoring='neg_mean_squared_error', cv=50)
# change neg_mean_squared error to mean_squared_error
cross_val_scores = np.sqrt(np.abs(cross_val_scores))
print(cross_val_scores)
print("mean:", np.mean(cross_val_scores))
[0.01029598 0.00922735 0.00553913 0.00900553 0.0110392 0.01333214
0.0115197 0.00933864 0.00664628 0.004857 0.0135743 0.00595552
0.00706495 0.00944506 0.01080077 0.00842491 0.01044174 0.0126128
0.00869932 0.00846706 0.00762137 0.01478009 0.00772207 0.01305496
0.00673948 0.00801689 0.01060272 0.01137826 0.0069177 0.01071186
0.0083437 0.00905157 0.00803609 0.00893249 0.01002789 0.00802375
0.00934506 0.01199787 0.00686557 0.01114371 0.00862676 0.00830973
0.00935762 0.00815328 0.00868262 0.00938199 0.00926949 0.00627161
0.00922161 0.00771521]
mean: 0.00921180787871304請注意,均值非常相似,但是方差甚至更大-性能最差的結果的誤差比最優結果大204%!
這就是爲什麼我們喜歡在5到10之間選擇一個k值的原因:驗證集足夠大,不會顯示太多設置方差的設置,但又不算太大,以至於它們佔用了大量訓練數據,訓練數據集中的偏見嚴重,缺少訓練所需的數據。
具有K折交叉驗證的超參數調整
因此,您可能還記得,交叉驗證的要點之一是減少訓練集中的偏差和驗證集中的差異。
另一個重要方面是通過迫使我們找到在許多驗證集上提供最佳平均性能的超參數值來減少對驗證集的過度擬合。
在我們發現針對我們的特定訓練:驗證拆分之前,max_depth爲1導致最佳性能,因此我們得出結論,此max_depth將爲我們提供新數據的最佳性能。
讓我們回想一下它的外觀:
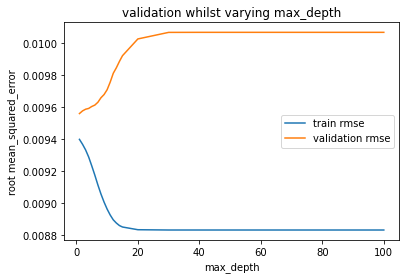
也就是說,完全有可能max_depth僅1對於該特定驗證集是最佳的-可能不是在許多驗證集上平均的最佳max_depth。
讓我們再次針對max_depth運行超參數校準,但是這次使用5個不同的驗證集上的交叉驗證進行了校準。
爲此,我們將使用sklearn- validation_curve ()中的另一個函數。
from sklearn.model_selection import validation_curve
它與cross_val_scores()非常相似,但是讓我們在運行交叉驗證的同時更改超參數(即,它對我們所變化的超參數的每個特定值執行一次完整的交叉驗證過程):
train_scores, valid_scores = validation_curve(RandomForestRegressor(n_estimators=100, random_state=1), X_train, y_train, "max_depth",
param_range, scoring='neg_mean_squared_error', cv=5)
train_scores = np.sqrt(np.abs(train_scores))
valid_scores = np.sqrt(np.abs(valid_scores))
train_scores_mean = np.mean(train_scores, axis=1)
valid_scores_mean = np.mean(valid_scores, axis=1)
plt.title("Validation Curve with Random Forest")
plt.xlabel("max_depth")
plt.ylabel("RMSE")
plt.plot(param_range, train_scores_mean, label="train rmse")
plt.plot(param_range, valid_scores_mean, label="validation rmse")
plt.legend()
plt.show()

好的,結果幾乎完全相同,但是這次我們可以肯定的是,我們做出了一個不錯的選擇!
一般而言,如果我們的數據有些複雜,並且在max_depth的任何級別上的過度擬合都沒有那麼明確,我們可能會發現,當交叉驗證而不是在a上進行驗證時,不同的超參數給出了最佳結果單套。
問題數據的替代技術
K折交叉驗證通常會爲您帶來良好的結果,但有時根據數據的結構/分佈它可能會給我們帶來問題。
首先是在數據中有很多極端的例子,而我們在訓練,驗證和測試集之間卻得不到很好的分配。
例如,分類任務中可能沒有一些類的示例。如果這些(運氣不好)主要只出現在驗證或測試集中,那麼我們的模型將永遠不會/幾乎不會在訓練中遇到它們,並且幾乎肯定會在對它們進行分類時表現不佳。
同樣,在迴歸意義上,如果有一些極端目標值的示例(低或高),並且僅在我們的一些驗證和測試集中出現,那麼我們的模型在遇到它們時也不太可能做得很好。
此外,如果“有問題的”數據僅出現在訓練中,而沒有出現在我們的測試集中,則我們可能會對模型技能獲得過分樂觀的估計,我們希望訓練/驗證/測試分佈是儘可能相似。
分層K折
分層K折是一個很好的解決方案。
這是k倍的變化形式, 每個目標類別的樣本所佔百分比與訓練,驗證和測試集中的完整數據集中的百分比大致相同。
您可以像這樣導入和設置它:
from sklearn.model_selection import StratifiedKFold skfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=1)
請注意,它會返回您應該使用的訓練/測試(或訓練/驗證)拆分的索引,因此,您每次必須手動配置拆分,如下所示:
for train_index, test_index in skfold.split(X, y): X_train, X_test= X[train_index], X[test_index] y_train, y_test= y[train_index], y[test_index] # TRAIN AND VALIDATE WITH THIS SPLIT
分層K折僅可直接用於分類數據,但是要讓它對迴歸數據產生類似效果的一種簡便而又簡便的方法是將回歸目標劃分爲狹窄的帶,從而將問題轉化爲僞隨機數據。分類。
您甚至可以臨時向數據中添加等於合併目標值的新列,將該臨時列分配爲目標變量,基於此創建“分層”摺疊,然後刪除您創建的此額外數據列並恢復爲使用精確的數值作爲實際訓練,驗證和測試的目標變量。
K折
另一個可能的問題是數據中存在明顯的組結構。
例如,我們有一個場景,其中從不同的主題收集數據樣本,但是在某些(或全部)情況下,每個主題收集多個樣本。
可以考慮嘗試估算從貨船上卸下的集裝箱離開碼頭之前在船塢中停留了多長時間。每艘船可能會卸下數百個集裝箱,因此長期來看,有明顯的集裝箱數據分組。如果該模型具有足夠的靈活性來學習高度的集裝箱特定功能,那麼即使將來在訓練/驗證/測試拆分過程中表現出色,該模型也無法很好地推廣到將來從不同船上卸載的集裝箱。同一艘船。
GroupKFold是K折的一種變體,可確保同一組不在不同的集合中表示-即,來自同一組的所有數據實例僅在訓練,驗證或測試集中的一箇中存在。
您可以使用與StratifiedKfold完全相同的方式使用它:
from sklearn.model_selection import GroupKFold
X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"]
groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
gkf = GroupKFold(n_splits=3)
for train, test in gkf.split(X, y, groups=groups):
print("TRAIN INDEXES: {} TEST INDEXES: {}".format(train, test))
TRAIN INDEXES: [0 1 2 3 4 5] TEST INDEXES: [6 7 8 9]
TRAIN INDEXES: [0 1 2 6 7 8 9] TEST INDEXES: [3 4 5]
TRAIN INDEXES: [3 4 5 6 7 8 9] TEST INDEXES: [0 1 2]如您所見,每個分組的數據完全顯示在訓練集中或測試集中。
時間序列數據的交叉驗證
K倍交叉驗證(及其變體)在時間序列數據上的效果很差,因爲它們不遵守數據的時間順序。
每個訓練,驗證和測試部分的數據都是隨機選擇的,因此我們幾乎總是會在驗證和測試集之前和之後都得到一些訓練數據。
如果數據中的模式高度依賴於它們的發生時間以及其他特徵,那麼這實質上是數據泄漏的一種形式,因爲我們使用未來的一些信息來預測過去和現在,從而導致過於樂觀的估計模型技巧。
在某些情況下這可能是一場災難,因爲在某些情況下,如果之前和之後給出了信息,則在某些中等時間事件中填寫空白會容易得多。
例如,思考市場-一個一百萬美元的問題(或一萬億美元?)來預測它們將如何使用當前數據進行未來變化,但如果給出的話,則更容易猜測在給定時間範圍內的價格波動情況來自問題期前後的價格數據(尤其是在較短的時間範圍內)。
請注意,您的數據中明確存在“數據觀察時間”列並不一定會強制定義是否應將某些數據視爲時間序列。數據中可能有觀察到的時間列,並且數據不是很依賴時間,因此您必須考慮數據的性質。
例如,人類的骨骼測量值與身高的相關關係在整個千年中可能略有變化,但是在數年甚至數十年的時間裏,時間並不是很重要的組成部分,即使在數據中有觀察時間也是如此。另一方面,市場價格走勢對時間高度敏感,甚至是分鐘和秒。
因此,對於時間序列數據,至關重要的是測試集嚴格由按時間順序排列在驗證和訓練集之後的數據組成,同樣,驗證數據按時間順序排列在訓練集之後。
前向嵌套式交叉驗證
爲了實現這一目標,同時仍然能夠使用我們的大部分數據進行驗證(以及本例中的測試和結果),我們可以使用一種稱爲前行嵌套交叉驗證的技術。
這個想法很簡單。
過去,我們僅使用一小部分數據。
然後我們:
- 使用該集中的最新數據作爲我們的測試數據
- 將之前的數據用作驗證集
- 使用之前的所有數據作爲我們的訓練集
- 及時擴展我們的數據集,並重復1-3,直到測試集中的數據趕上今天爲止。
該過程應如下所示:
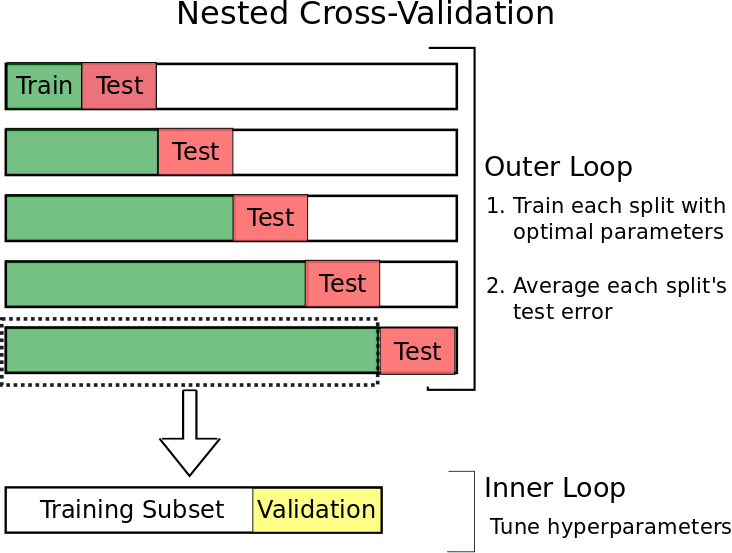
考特尼·科克倫(Courtney Cochrane):https : //towardsdatascience.com/time-series-nested-cross-validation-76adba623eb9
雖然這可能看起來技術上棘手的實施,sklearn有(不出所料)另一個有用的功能來幫助我們解決這個- TimeSeriesSplit() 。
from sklearn.model_selection import TimeSeriesSplit
首先,請確保您的數據框已將其索引設置爲相關的時間序列(我們一開始就已經這樣做了),以確保索引按時間順序排列。
然後使用所需的前向拆分數量創建一個TimeSeriesSplit()對象(n = 5給出5個具有相同大小的測試集的前向循環):
tscv = TimeSeriesSplit(n_splits=5)
當在數據幀上使用時,tscv以生成方式返回training:test的索引。
下面,我創建了一些更簡單的數據來顯示輸出,以便更輕鬆地說明發生了什麼:
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4],[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
for train_index, test_index in tscv.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
TRAIN: [0 1 2 3 4] TEST: [5]
TRAIN: [0 1 2 3 4 5] TEST: [6]
TRAIN: [0 1 2 3 4 5 6] TEST: [7]
TRAIN: [0 1 2 3 4 5 6 7] TEST: [8]
TRAIN: [0 1 2 3 4 5 6 7 8] TEST: [9]這爲我們提供了前瞻性的訓練:測試部門精美。
現在,我們可以簡單地根據每個前向實例中火車集中的最終數據的索引來截取我們想要的任何分數,以形成驗證數據,因爲無論如何它都是按時間序列索引按時間順序排序的:
for train_index, test_index in tscv.split(X):
# 80:20 training:validation inner loop split
inner_split_point = int(0.8*len(train_index))
valid_index = train_index[inner_split_point:]
train_index = train_index[:inner_split_point]
print("TRAIN:", train_index, "VALID:", valid_index, "TEST:", test_index)
X_train, X_valid, X_test = X[train_index], X[valid_index], X[test_index]
y_train, y_valid, y_test = y[train_index], y[valid_index], y[test_index]
TRAIN: [0 1 2 3] VALID: [4] TEST: [5]
TRAIN: [0 1 2 3] VALID: [4 5] TEST: [6]
TRAIN: [0 1 2 3 4] VALID: [5 6] TEST: [7]
TRAIN: [0 1 2 3 4 5] VALID: [6 7] TEST: [8]
TRAIN: [0 1 2 3 4 5 6] VALID: [7 8] TEST: [9]完善!(儘管要注意,我們只需要幾個與n_splits大小有關的數據樣本即可保證所有非空集-但這實際上不太可能成爲問題!)
現在,我們可以在內部循環中每次簡單地以一組(非交叉驗證)方式執行訓練和驗證。我們不會再通過一個示例進行介紹,因爲它可以完全按照“通過驗證集進行的超參數調整”部分中的說明執行。
最後,請注意,一旦完成了所選的訓練變體,交叉驗證和測試模型,就值得將訓練,驗證和測試集的全部三個組合在一起,並在最後進行一次再訓練。
最終的重組使模型可以從中學習的數據最大化(現在我們已經找到了最佳功能和超參數設置),因此可能會導致模型更加有效和健壯!
希望本文能爲您提供一些新的想法,並加深您對訓練,驗證和測試集背後原因的理解。
您可以在此處找到本文中使用的代碼和隨附的數據集:https : //github.com/GregBland/train_val_test_sets_article
參考https://algotrading101.com/learn/train-test-split/
歡迎學習更多python金融風控評分卡模型和數據分析微專業課

(微信二維碼掃一掃報名)