




JAVA併發-Disruptor框架
Disruptor簡介
最好的方法去理解Disruptor就是將它和容易理解並且相似的隊列,例如BlockingQueue。Disruptor其實就像一個隊列一樣,用於在不同的線程之間遷移數據,但是Disruptor也實現了一些其他隊列沒有的特性,如:
- 同一個“事件”可以有多個消費者,消費者之間既可以並行處理,也可以相互依賴形成處理的先後次序(形成一個依賴圖);
- 預分配用於存儲事件內容的內存空間;
- 針對極高的性能目標而實現的極度優化和無鎖的設計;
Disruptor核心架構組件
- Ring Buffer:Ring Buffer在3.0版本以前被認爲是Disruptor的核心組件,但是在之後的版本中只是負責存儲和更新數據。在一些高級使用案例中用戶也能進行自定義
- Sequence:Disruptor使用一組Sequence來作爲一個手段來標識特定的組件的處理進度( RingBuffer/Consumer )。每個消費者和Disruptor本身都會維護一個Sequence。雖然一個 AtomicLong 也可以用於標識進度,但定義 Sequence 來負責該問題還有另一個目的,那就是防止不同的 Sequence 之間的CPU緩存僞共享(Flase Sharing)問題。
- Sequencer:Sequencer是Disruptor的真正核心。此接口有兩個實現類 SingleProducerSequencer、MultiProducerSequencer ,它們定義在生產者和消費者之間快速、正確地傳遞數據的併發算法。
- Sequence Barrier:保持Sequencer和Consumer依賴的其它Consumer的 Sequence 的引用。除此之外還定義了決定 Consumer 是否還有可處理的事件的邏輯。
- Wait Strategy:Wait Strategy決定了一個消費者怎麼等待生產者將事件(Event)放入Disruptor中。
- Event:從生產者到消費者傳遞的數據叫做Event。它不是一個被 Disruptor 定義的特定類型,而是由 Disruptor 的使用者定義並指定。
- EventProcessor:持有特定的消費者的Sequence,並且擁有一個主事件循環(main event loop)用於處理Disruptor的事件。其中BatchEventProcessor是其具體實現,實現了事件循環(event loop),並且會回調到實現了EventHandler的已使用過的實例中。
- EventHandler:由用戶實現的接口,用於處理事件,是 Consumer 的真正實現
- Producer:生產者,只是泛指調用 Disruptor 發佈事件的用戶代碼,Disruptor 沒有定義特定接口或類型。

事件廣播(Multicast Events)
這是Disruptor和隊列最大的區別。當你有多個消費者監聽了一個Disruptor,所有的事件將會被髮布到所有的消費者中,相比之下隊列的一個事件只能被髮到一個消費者中。Disruptor這一特性被用來需要對同一數據進行多個並行操作的情況。如在LMAX系統中有三個操作可以同時進行:日誌(將數據持久到日誌文件中),複製(將數據發送到其他的機器上,以確保存在數據遠程副本),業務邏輯處理。也可以使用WokrerPool來並行處理不同的事件。
消費者依賴關係圖(Consumer Dependency Graph)
爲了支持真實世界中的業務並行處理流程,Disruptor提供了多個消費者之間的協助功能。回到上面的LMAX的例子,我們可以讓日誌處理和遠程副本賦值先執行完之後再執行業務處理流程,這個功能被稱之爲gating。gating發生在兩種場景中。第一,我們需要確保生產者不要超過消費者。通過調用RingBuffer.addGatingConsumers()增加相關的消費者至Disruptor來完成。第二,就是之前所說的場景,通過構造包含需要必須先完成的消費者的Sequence的SequenceBarrier來實現。
引用上面的例子來說,有三個消費者監聽來自RingBuffer的事件。這裏有一個依賴關係圖。ApplicationConsumer依賴JournalConsumer和ReplicationConsumer。這個意味着JournalConsumer和ReplicationConsumer可以自由的併發運行。依賴關係可以看成是從ApplicationConsumer的SequenceBarrier到JournalConsumer和ReplicationConsumer的Sequence的連接。還有一點值得關注,Sequencer與下游的消費者之間的關係。它的角色是確保發佈不會包裹RingBuffer。爲此,所有下游消費者的Sequence不能比ring buffer的Sequence小且不能比ring buffer 的大小小。因爲ApplicationConsumers的Sequence是確保比JournalConsumer和ReplicationConsumer的Sequence小或等於,所以Sequencer只需要檢查ApplicationConsumers的Sequence。在更爲普遍的應用場景中,Sequencer只需要意識到消費者樹中的葉子節點的的Sequence即可。
事件預分配(Event Preallocation)
Disruptor的一個目標之一是被用在低延遲的環境中。在一個低延遲系統中有必要去減少和降低內存的佔用。在基於Java的系統中,需要減少由於GC導致的停頓次數(在低延遲的C/C++系統中,由於內存分配器的爭用,大量的內存分配也會導致問題)。
爲了滿足這點,用戶可以在Disruptor中爲事件預分配內存。所以EventFactory是用戶來提供,並且Disruptor的Ring Buffer每個entry中都會被調用。當將新的數據發佈到Disruptor中時,Disruptor的API將會允許用戶持有所構造的對象,以便用戶可以調用這些對象的方法和更新字段到這些對象中。Disruptor將確保這些操作是線程安全。
可選擇的無鎖
無鎖算法實現的Disruptor的所有內存可見性和正確性都使用內存屏障和CAS操作實現。只僅僅一個場景BlockingWaitStrategy中使用到了lock。而這僅僅是爲了使用Condition,以便消費者線程能被park住當在等待一個新的事件到來的時候。許多低延遲系統都使用自旋(busy-wait)來避免使用Condition造成的抖動。但是自旋(busy-wait)的數量變多時將會導致性能的下降,特別是CPU資源嚴重受限的情況下。例如,在虛擬環境中的Web服務器。
等待策略
BlockingWaitStrategy
Disruptor的默認策略是BlockingWaitStrategy。在BlockingWaitStrategy內部是使用鎖和condition來控制線程的喚醒。BlockingWaitStrategy是最低效的策略,但其對CPU的消耗最小並且在各種不同部署環境中能提供更加一致的性能表現
SleepingWaitStrategy
SleepingWaitStrategy 的性能表現跟 BlockingWaitStrategy 差不多,對 CPU 的消耗也類似,但其對生產者線程的影響最小,通過使用LockSupport.parkNanos(1)來實現循環等待。一般來說Linux系統會暫停一個線程約60µs,這樣做的好處是,生產線程不需要採取任何其他行動就可以增加適當的計數器,也不需要花費時間信號通知條件變量。但是,在生產者線程和使用者線程之間移動事件的平均延遲會更高。它在不需要低延遲並且對生產線程的影響較小的情況最好。一個常見的用例是異步日誌記錄。
YieldingWaitStrategy
YieldingWaitStrategy是可以使用在低延遲系統的策略之一。YieldingWaitStrategy將自旋以等待序列增加到適當的值。在循環體內,將調用Thread.yield(),以允許其他排隊的線程運行。在要求極高性能且事件處理線數小於 CPU 邏輯核心數的場景中,推薦使用此策略;例如,CPU開啓超線程的特性。
BusySpinWaitStrategy
性能最好,適合用於低延遲的系統。在要求極高性能且事件處理線程數小於CPU邏輯核心樹的場景中,推薦使用此策略;例如,CPU開啓超線程的特性。
寫入RingBuffer
ProducerBarriers
Disruptor 代碼給 消費者 提供了一些接口和輔助類,但是沒有給寫入 Ring Buffer 的 生產者 提供接口。這是因爲除了你需要知道生產者之外,沒有別人需要訪問它。儘管如此,Ring Buffer 還是與消費端一樣提供了一個 ProducerBarrier 對象,讓生產者通過它來寫入 Ring Buffer。
寫入 Ring Buffer 的過程涉及到兩階段提交 (two-phase commit)。首先,你的生產者需要申請 buffer 裏的下一個節點。然後,當生產者向節點寫完數據,它將會調用 ProducerBarrier 的 commit 方法。
那麼讓我們首先來看看第一步。 “給我 Ring Buffer 裏的下一個節點”,這句話聽起來很簡單。的確,從生產者角度來看它很簡單:簡單地調用 ProducerBarrier 的 nextEntry() 方法,這樣會返回給你一個 Entry 對象,這個對象就是 Ring Buffer 的下一個節點。
ProducerBarrier 如何防止 Ring Buffer 重疊
在後臺,由 ProducerBarrier 負責所有的交互細節來從 Ring Buffer 中找到下一個節點,然後才允許生產者向它寫入數據。

在這幅圖中,假設只有一個生產者寫入 Ring Buffer。過一會兒再處理多個生產者的複雜問題。
ConsumerTrackingProducerBarrier 對象擁有所有正在訪問 Ring Buffer 的 消費者 列表。這看起來有點兒奇怪-我從沒有期望 ProducerBarrier 瞭解任何有關消費端那邊的事情。但是等等,這是有原因的。因爲我們不想與隊列“混爲一談”(隊列需要追蹤隊列的頭和尾,它們有時候會指向相同的位置),Disruptor 由消費者負責通知它們處理到了哪個序列號,而不是 Ring Buffer。所以,如果我們想確定我們沒有讓 Ring Buffer 重疊,需要檢查所有的消費者們都讀到了哪裏。
在上圖中,有一個 消費者 順利的讀到了最大序號 12(用紅色/粉色高亮)。第二個消費者 有點兒落後——可能它在做 I/O 操作之類的——它停在序號 3。因此消費者 2 在趕上消費者 1 之前要跑完整個 Ring Buffer 一圈的距離。
現在生產者想要寫入 Ring Buffer 中序號 3 佔據的節點,因爲它是 Ring Buffer 當前遊標的下一個節點。但是 ProducerBarrier 明白現在不能寫入,因爲有一個消費者正在佔用它。所以,ProducerBarrier 停下來自旋 (spins),等待,直到那個消費者離開。
申請下一個節點
現在可以想像消費者 2 已經處理完了一批節點,並且向前移動了它的序號。可能它挪到了序號 9(因爲消費端的批處理方式,現實中我會預計它到達 12,但那樣的話這個例子就不夠有趣了)。

上圖顯示了當消費者 2 挪動到序號 9 時發生的情況。在這張圖中我已經忽略了ConsumerBarrier,因爲它沒有參與這個場景。
ProducerBarier 會看到下一個節點——序號 3 那個已經可以用了。它會搶佔這個節點上的 Entry(我還沒有特別介紹 Entry 對象,基本上它是一個放寫入到某個序號的 Ring Buffer 數據的桶),把下一個序號(13)更新成 Entry 的序號,然後把 Entry 返回給生產者。生產者可以接着往 Entry 裏寫入數據。
提交新的數據
兩階段提交的第二步是——對,提交。

綠色表示最近寫入的 Entry,序號是 13 ——厄,抱歉,我也是紅綠色盲。但是其他顏色甚至更糟糕。
當生產者結束向 Entry 寫入數據後,它會要求 ProducerBarrier 提交。
ProducerBarrier 先等待 Ring Buffer 的遊標追上當前的位置(對於單生產者這毫無意義-比如,我們已經知道遊標到了 12 ,而且沒有其他人正在寫入 Ring Buffer)。然後 ProducerBarrier 更新 Ring Buffer 的遊標到剛纔寫入的 Entry 序號-在我們這兒是 13。接下來,ProducerBarrier 會讓消費者知道 buffer 中有新東西了。它戳一下 ConsumerBarrier 上的 WaitStrategy 對象說-“喂,醒醒!有事情發生了!”(注意-不同的 WaitStrategy 實現以不同的方式來實現提醒,取決於它是否採用阻塞模式。)
現在消費者 1 可以讀 Entry 13 的數據,消費者 2 可以讀 Entry 13 以及前面的所有數據,然後它們都過得很 happy。
ProducerBarrier 上的批處理
有趣的是 Disruptor 可以同時在生產者和 消費者 兩端實現批處理。還記得伴隨着程序運行,消費者 2 最後達到了序號 9 嗎?ProducerBarrier 可以在這裏做一件很狡猾的事-它知道 Ring Buffer 的大小,也知道最慢的消費者位置。因此它能夠發現當前有哪些節點是可用的。

如果 ProducerBarrier 知道 Ring Buffer 的遊標指向 12,而最慢的消費者在 9 的位置,它就可以讓生產者寫入節點 3,4,5,6,7 和 8,中間不需要再次檢查消費者的位置。
多個生產者的場景
在上面的圖中我稍微撒了個謊。我暗示了 ProducerBarrier 拿到的序號直接來自 Ring Buffer 的遊標。然而,如果你看過代碼的話,你會發現它是通過 ClaimStrategy 獲取的。我省略這個對象是爲了簡化示意圖,在單個生產者的情況下它不是很重要。
在多個生產者的場景下,你還需要其他東西來追蹤序號。這個序號是指當前可寫入的序號。注意這和“向 Ring Buffer 的遊標加 1”不一樣-如果你有一個以上的生產者同時在向 Ring Buffer 寫入,就有可能出現某些 Entry 正在被生產者寫入但還沒有提交的情況。
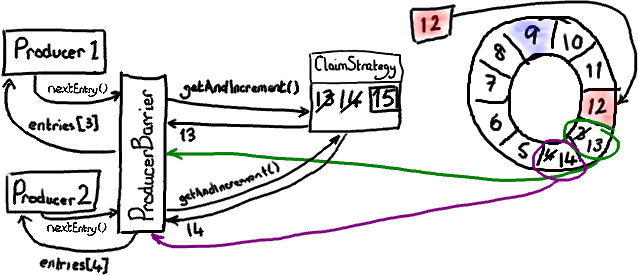
讓我們複習一下如何申請寫入節點。每個生產者都向 ClaimStrategy 申請下一個可用的節點。生產者 1 拿到序號 13,這和上面單個生產者的情況一樣。生產者 2 拿到序號 14,儘管 Ring Buffer的當前遊標僅僅指向 12。這是因爲 ClaimSequence 不但負責分發序號,而且負責跟蹤哪些序號已經被分配。
現在每個生產者都擁有自己的寫入節點和一個嶄新的序號。
我把生產者 1 和它的寫入節點塗上綠色,把生產者 2 和它的寫入節點塗上可疑的粉色-看起來像紫色。
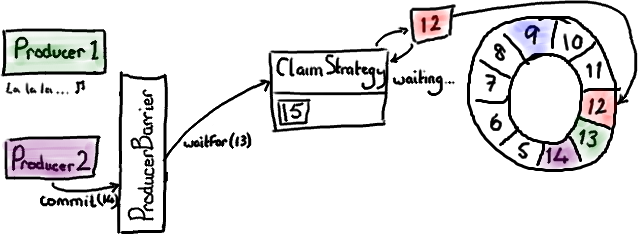
現在假設生產者 1 還生活在童話裏,因爲某些原因沒有來得及提交數據。生產者 2 已經準備好提交了,並且向 ProducerBarrier 發出了請求。
就像我們先前在 commit 示意圖中看到的一樣,ProducerBarrier 只有在 Ring Buffer 遊標到達準備提交的節點的前一個節點時它纔會提交。在當前情況下,遊標必須先到達序號 13 我們才能提交節點 14 的數據。但是我們不能這樣做,因爲生產者 1 正盯着一些閃閃發光的東西,還沒來得及提交。因此 ClaimStrategy 就停在那兒自旋 (spins), 直到 Ring Buffer 遊標到達它應該在的位置。
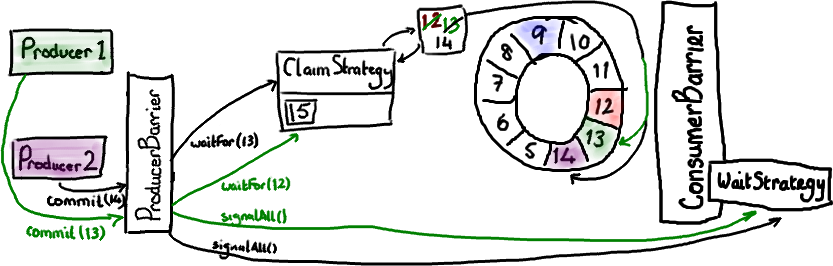
現在生產者 1 從迷糊中清醒過來並且申請提交節點 13 的數據(生產者 1 發出的綠色箭頭代表這個請求)。ProducerBarrier 讓 ClaimStrategy 先等待 Ring Buffer 的遊標到達序號 12,當然現在已經到了。因此 Ring Buffer 移動遊標到 13,讓 ProducerBarrier 戳一下 WaitStrategy 告訴所有人都知道 Ring Buffer 有更新了。現在 ProducerBarrier 可以完成生產者 2 的請求,讓 Ring Buffer 移動遊標到 14,並且通知所有人都知道。
你會看到,儘管生產者在不同的時間完成數據寫入,但是 Ring Buffer 的內容順序總是會遵循 nextEntry() 的初始調用順序。也就是說,如果一個生產者在寫入 Ring Buffer 的時候暫停了,只有當它解除暫停後,其他等待中的提交纔會立即執行。
呼——。我終於設法講完了這一切的內容並且一次也沒有提到內存屏障(Memory Barrier)。
更新:最近的 RingBuffer 版本去掉了 Producer Barrier。如果在你看的代碼裏找不到 ProducerBarrier,那就假設當我講“Producer Barrier”時,我的意思是“Ring Buffer”。
更新2:注意 Disruptor 2.0 版使用了與本文不一樣的命名。如果你對類名感到困惑,請閱讀我寫的Disruptor 2.0更新摘要。
Disruptor類的handleEventsWith,handleEventsWithWorkerPool方法的區別
在disruptor框架調用start方法之前,往往需要將消息的消費者指定給disruptor框架。
常用的方法是:disruptor.handleEventsWith(EventHandler … handlers),將多個EventHandler的實現類傳入方法,封裝成一個EventHandlerGroup,實現多消費者消費。
disruptor的另一個方法是:disruptor.handleEventsWithWorkerPool(WorkHandler … handlers),將多個WorkHandler的實現類傳入方法,封裝成一個EventHandlerGroup實現多消費者消費。
兩者共同點都是,將多個消費者封裝到一起,供框架消費消息。
不同點在於:
- 對於某一條消息m,handleEventsWith方法返回的EventHandlerGroup,Group中的每個消費者都會對m進行消費,各個消費者之間不存在競爭。handleEventsWithWorkerPool方法返回的EventHandlerGroup,Group的消費者對於同一條消息m不重複消費;也就是,如果c0消費了消息m,則c1不再消費消息m。
- 傳入的形參不同。對於獨立消費的消費者,應當實現EventHandler接口。對於不重複消費的消費者,應當實現WorkHandler接口。
因此,根據消費者集合是否獨立消費消息,可以對不同的接口進行實現。也可以對兩種接口同時實現,具體消費流程由disruptor的方法調用決定。
清除Ring Buffer中的對象
通過Disruptor傳遞數據時,對象的生存期可能比預期的更長。爲避免發生這種情況,可能需要在處理事件後清除事件。如果只有一個事件處理程序,則需要在處理器中清除對應的對象。如果您有一連串的事件處理程序,則可能需要在該鏈的末尾放置一個特定的處理程序來處理清除對象。
Copyclass ObjectEvent<T>
{
T val;
void clear()
{
val = null;
}
}
public class ClearingEventHandler<T> implements EventHandler<ObjectEvent<T>>
{
public void onEvent(ObjectEvent<T> event, long sequence, boolean endOfBatch)
{
// Failing to call clear here will result in the
// object associated with the event to live until
// it is overwritten once the ring buffer has wrapped
// around to the beginning.
event.clear();
}
}
public static void main(String[] args)
{
Disruptor<ObjectEvent<String>> disruptor = new Disruptor<>(
() -> ObjectEvent<String>(), bufferSize, DaemonThreadFactory.INSTANCE);
disruptor
.handleEventsWith(new ProcessingEventHandler())
.then(new ClearingObjectHandler());
}
Disruptor 與 RingBuffer 的關係
- Disruptor 的存儲部分實現了 RingBuffer。
- Disruptor 提供了方法供 Producer 和 Consumer 線程來通過 ringbuffer 傳輸數據。
RingBuffer 的本質
- 固定大小的
- 先入先出的 (FIFO)
- Producer-Consumer 模型的
- 循環使用的一段內存
- 由於進程週期內,可不用重新釋放和分配空間
ring buffer維護兩個指針,“next”和“cursor”,“next”指針指向第一個未填充數據的區塊。“cursor”指針指向最後一個填充了數據的區塊。在一個空閒的 ring bufer 中,它們是彼此緊鄰的。
Disruptor 適用場景
- Producer-Consumer 場景,一生產者多消費者,多生產者多消費者(線程安全)
- 線程之間交換數據
- 輕量化的消息隊列
- 對隊列性能要求高:Disruptor 的速度比 LinkedBlockingQueue 提高了七倍(無鎖設計)
- 同一個“事件”可以有多個消費者,消費者之間既可以並行處理,也可以相互依賴形成處理的先後次序(形成一個依賴圖)
- 典型場景:Canal,從一個 mysql 實例讀取 binlog,放到 Disruptor,下游可有多個併發消費者
Disruptor 爲什麼快而且線程安全
簡單說:
- 它是數組,所以要比鏈表快(添加刪除更簡單,耗費內存更小),且可以利用 CPU 緩存來預加載
- 數組對象本身一直存在,避免了大對象的垃圾回收(當然元素本身還是要回收的)
- 在需要確保線程安全的地方,用 CAS 取代鎖。
- 沒有競爭 = 沒有鎖 = 非常快。
- 所有 Consumer 都記錄自己的序號(Sequence),允許多個 Producer 與多個 Consumer 共享 ringbuffer。
- 在每個對象中都能跟蹤 Sequence(ring buffer,claim Strategy,生產者和消費者),加上 Sequence 的 cache line padding,就意味着沒
爲僞共享和非預期的競爭。
個人覺得最重要的設計就是:
- 每個 Consumer 持有一個 Sequence,各 Consumer 消費獨立。
- Producer 根據所有 Consumer 的 Sequence 位置決定是否能寫入到 ringbuffer,以及寫入到何位置。
- 各 Producer 在併發寫時,通過 CAS 避免鎖。(可參考下面的代碼分析)
代碼分析
僞共享/UNSAFE.putOrderedLong
class LhsPadding {
// 這是僞共享的填充字段
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
// 這是真實的序號值,是一個volatile類型
protected volatile long value;
}
class RhsPadding extends Value {
// 這是僞共享的填充字段
protected long p9, p10, p11, p12, p13, p14, p15;
}
// Sequence 本質上是維護一個數字值,保障其高效可見的讀寫
// zyn 因爲繼承了 RhsPadding Sequence的字段實際爲
// p1, p2, p3, p4, p5, p6, p7, value, p9, p10, p11, p12, p13, p14, p15
// 避免了僞共享
public class Sequence extends RhsPadding {
static final long INITIAL_VALUE = -1L;
private static final Unsafe UNSAFE;
// 反射value字段在類的 offset
// 後方法會基於反射進行賦值
private static final long VALUE_OFFSET;
// 省略非核心代碼
...
// 這是一個普通讀
public long get() {
return value;
}
public void set(final long value) {
// 這裏不能直接用普通的方式嗎?可以看到 Sequence.set 並未直接基於 volatile 的賦值
// putOrderedLong 是Store/Store barrier 比 volatile 的 Store/Load barrier 性能消耗更低
// 此處僅僅防止寫的順序重排序,並不會保障立刻可見,用於不需要其他線程立刻可見的場景
UNSAFE.putOrderedLong(this, VALUE_OFFSET, value);
}
public void setVolatile(final long value) {
// 這是採用了 Store/Load barrier
UNSAFE.putLongVolatile(this, VALUE_OFFSET, value);
}
public boolean compareAndSet(final long expectedValue, final long newValue) {
return UNSAFE.compareAndSwapLong(this, VALUE_OFFSET, expectedValue, newValue);
}
// 省略非核心代碼
...
}
在執行消費者事件消費記錄當前消費者最新消費位置時,並未採用高消耗的 setVolatile 而是 Store/Store barrier 的set方法
因爲消費者更新的位置沒必要讓生產線程立刻可見,等待生產線程失效隊列自動更新時可見即可。
// 循環執行
while (nextSequence <= availableSequence) {
event = dataProvider.get(nextSequence);
// 這裏是真實調用 EventHandler 的 onEvent 方法
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}// 執行完成設置新的消費序號
// 這用的是寫屏障,未使用全能屏障,因爲此值無必要讓所有其他線程立刻可見
sequence.set(availableSequence);
多生產類MultiProducerSequencer中next方法【獲取生產序號】
// 消費者上一次消費的最小序號 // 後續第二點會講到
private final Sequence gatingSequenceCache = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);
// 當前進度的序號
protected final Sequence cursor = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);
// 所有消費者的序號 //後續第二點會講到
protected volatile Sequence[] gatingSequences = new Sequence[0];
public long next(int n)
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do
{
// 當前進度的序號,Sequence的value具有可見性,保證多線程間線程之間能感知到可申請的最新值
current = cursor.get();
// 要申請的序號空間:最大序列號
next = current + n;
long wrapPoint = next - bufferSize;
// 消費者最小序列號
long cachedGatingSequence = gatingSequenceCache.get();
// 大於一圈 || 最小消費序列號>當前進度
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)
{
long gatingSequence = Util.getMinimumSequence(gatingSequences, current);
// 說明大於1圈,並沒有多餘空間可以申請
if (wrapPoint > gatingSequence)
{
LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy?
continue;
}
// 更新最小值到Sequence的value中
gatingSequenceCache.set(gatingSequence);
}
// CAS成功後更新當前Sequence的value
else if (cursor.compareAndSet(current, next))
{
break;
}
}
while (true);
return next;
}
終結:
多個 Producer 如何協調把數據寫入到 ringBuffer
有多個生產者時,多個線程共用一個寫指針,此處需要考慮多線程問題,例如兩個生產者線程同時寫數據,當前寫指針=0,運行後其中一個線程應獲得緩衝區0號Slot,另一個應該獲得1號,寫指針=2。對於這種情況,Disruptor使用CAS來保證多線程安全。
Ringbuffer 如何根據各 consumer 消費速度告知各 Producer 現在是否能寫入數據
有多個消費者時,(按Disruptor的設計)每個消費者各自控制自己的指針,依次讀取每個Slot(也就是每個消費者都會讀取到所有的產品),這時只需要保證生產者指針不會超過最慢的消費者(超過最後一個消費者“一圈”)即可,也不需要鎖。
參考:
JAVA併發編程 之 LMAX Disruptor使用實例(高效解決生產者與消費者問題)