




原文:What Are Transformer Models and How Do They Work?
Transformer模型是機器學習中最令人興奮的新發展之一。它們在論文Attention is All You Need中被介紹。Transformer可以用於寫故事、文章、詩歌,回答問題,翻譯語言,與人類聊天,甚至可以通過對人類來說很難的考試!但是它們到底是什麼呢?你會很高興地知道,Transformer模型的架構並不複雜,它只是一些非常有用組件的串聯,並且每個組件都有自己的功能。在本篇文章中,您將瞭解所有這些組件。
此博客文章包含簡單概念性介紹。關於Transformer模型及其工作原理更詳細描述,請查看Cohere公司Jay Alammar撰寫的這兩篇優秀文章!
簡而言之,Transformer的作用是什麼?想象一下你在手機上寫短信。每輸入一個單詞後,你可能會得到三個建議的單詞。例如,如果你輸入“Hello, how are”,手機可能會建議下一個單詞爲“you”或“your”。當然,如果你繼續選擇手機中的建議單詞,很快就會發現這些單詞組成的信息毫無意義。如果你看每一組連續的3或4個單詞,則它們可能有意義,但這些單詞並不構成任何有意義的句子。這是因爲手機使用的模型沒有攜帶消息整體上下文,只是預測最近幾個字後更可能出現哪個字。相反地,“Transformer”可以跟蹤所編寫內容背景,並且這就是它們編寫文本使其具有意義之處所在。

手機可以建議在短信中使用下一個單詞,但沒有生成連貫文本的能力。
我必須對你誠實,第一次發現Transformer逐字建立文本時,我簡直不敢相信。首先,這不是人類構成句子和思想的方式。我們首先形成一個基本思想,然後開始完善它並添加單詞。這也不是ML模型完成其他任務的方式。例如,圖像不是以這種方式構建的。大多數基於神經網絡的圖形模型會形成圖像的粗略版本,並逐漸完善或添加細節直到完美爲止。那麼爲什麼Transformer模型要逐字構建文本呢?一個答案是因爲這樣做非常有效。更令人滿意的答案是因爲Transformer非常擅長跟蹤上下文,所以它選擇下一個單詞時恰好符合保持某個想法進行所需。
那麼Transformer如何訓練呢?使用了大量數據,事實上包括互聯網上所有數據。因此當您將“你好嗎”輸入到轉換器中時,它只需要根據互聯網上所有文本知道最佳下一個單詞就是“你”。如果您給出更復雜的命令,則可能會確定使用良好的下一個單詞,“曾經”。然後它將該單詞添加到命令中,並確定下一個好單詞是“在……之上”,以此類推。逐字逐句,直到它寫出一篇故事爲止。
命令:Write a story.
迴應:Once
下一條命令:Write a story. Once
迴應:upon
下一條命令:Write a story. Once upon
迴應:a
下一條命令:Write a story. Once upon a
迴應:time
下一條命令: Write a story. Once upon a time
回覆: there
等等…
現在我們知道了transformers的作用,讓我們來看一下它們的架構。如果你已經看過transformer模型的架構,你可能會像我第一次看到時那樣驚歎不已,因爲它看起來非常複雜!然而,當你將其分解成最重要的部分時,就沒有那麼難了。Transformer有4個主要部分:
1.分詞 2.嵌入 3.位置編碼 4.Transformer塊(其中包含多個) 5.Softmax
其中第四個Transformer塊是最複雜的。可以連接多個這樣的塊,並且每一個都包含兩個主要組件:Attention(注意力)和Feedforward(前饋)組件。
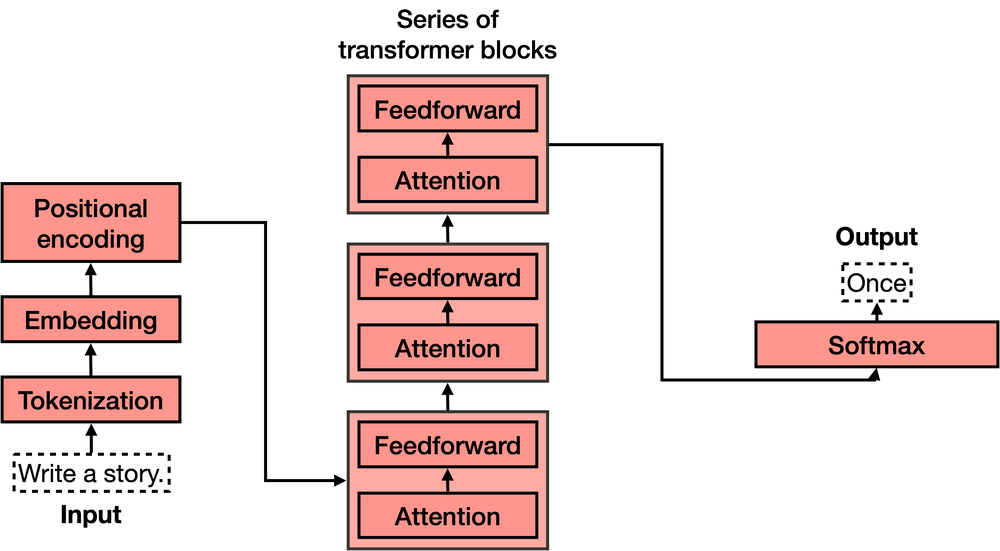
讓我們逐個學習這些部分。
1.Tokenization
Tokenization (分詞)是最基本的步驟。它包括一個大型的標記數據集,其中包含所有單詞、標點符號等。分詞步驟將每個單詞、前綴、後綴和標點符號都發送到庫中已知的Token。
 Tokenization :將單詞一個個裝進token. 例如,如果句子是“Write a story.”,那麼對應的4個token將是<Write>, <a>, <story>, and <.>。
Tokenization :將單詞一個個裝進token. 例如,如果句子是“Write a story.”,那麼對應的4個token將是<Write>, <a>, <story>, and <.>。
2.Embedding
一旦輸入內容被tokenized,就該將單詞轉換成數字了。爲此,我們使用embedding(嵌入)。Embedding是任何大型語言模型中最重要的部分之一;它是實現文本與數字轉換的橋樑。由於人類善於處理文本而計算機善於處理數字,因此這個橋樑越強大,語言模型就越強大。
簡而言之,文本嵌入將每個文本轉換爲一個向量。如果兩個文本片段相似,則其對應向量中的數字也相似(逐位意味着同一位置上的每對數字都相似)。否則,如果兩個文本片段不同,則其對應向量中的數字也不同。如果您想了解更多信息,請查看有關文本嵌入的文章和視頻。
儘管嵌入是數值化的,但我喜歡從幾何角度來想象它們。試想一下存在一個非常簡單的嵌入方式,可以將每個單詞映射到長度爲2(即包含2個數值) 的向量上。如果我們按照這兩個數值所表示座標定位每個單詞(比如在街道和大道上),那麼所有單詞都站在一個巨大平面上。在這張平面上,相似的單詞會靠近彼此,而不同的單詞則會遠離。例如,在下面這個嵌入中,“cherry”的座標是[6,4],與“strawberry” [5,4] 接近但與“castle” [1,2] 相距較遠。
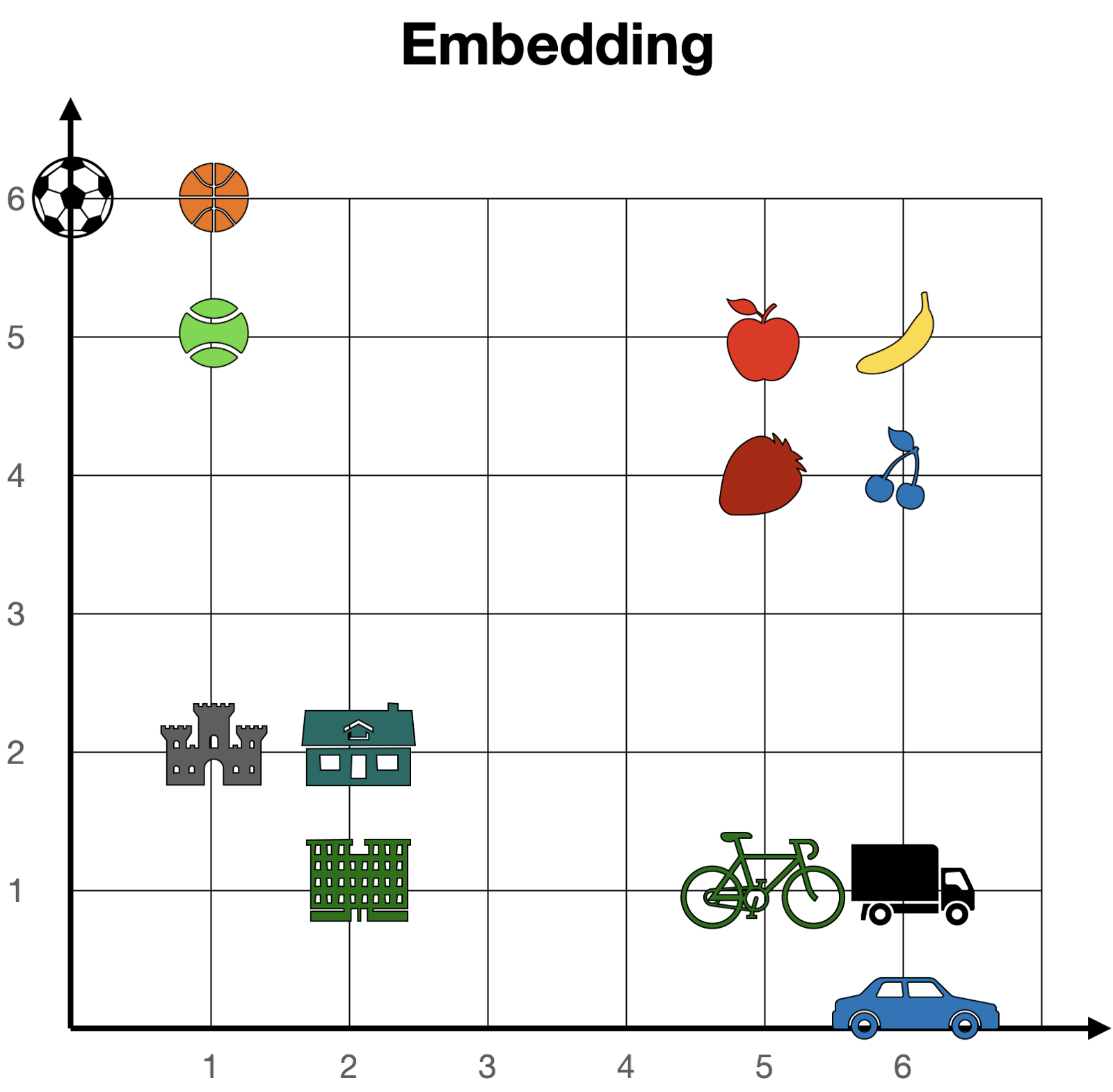
在更大的embedding情況下,每個單詞都被賦值到一個更長的向量(比如長度爲4096),那麼這些單詞不再存在於二維平面上,而是存在於一個大的4096維空間中。然而,在這個高維大空間中,我們仍然可以認爲單詞之間有近有遠,因此embedding概念仍然具有意義。
詞embedding可以推廣到文本embedding,包括整個句子、段落甚至更長的文本都會被賦值到一個向量中。然而,在transformer的情形中,我們將使用詞嵌入,這意味着句子中的每個單詞都會被賦值到相應的向量中。更具體地說,輸入文本中的每個token都將被定位到其對應的embedding向量中。
例如,如果我們正在考慮的句子是“Write a story.”並且標記是<Write>, <a>, <story>, and <.>,那麼每個標記都將被賦值到一個向量中,並且我們將有四個向量。

3.Positional encoding(位置編碼)
一旦我們獲得了與句子中每個token對應的向量,下一步就是將它們全部轉換爲一個向量進行處理。將一堆向量轉換爲一個向量最常見的方法是逐分量相加。也就是說,我們單獨添加每個座標。例如,如果這些(長度爲2)向量分別是[1,2]和[3,4],則它們對應的總和爲[1+3, 2+4],即[4,6]。這種方法可以工作,但有一個小細節需要注意:加法滿足交換律,也就是說如果你以不同順序添加相同的數字,則會得到相同的結果。在這種情況下,“我不難過我很開心”和“我不開心我很難過”兩句話將得到相同的向量結果(假設它們具有相同單詞但順序不同)。這並不好。因此我們必須想出一些方法來給出兩個句子不同的向量表示方式。多種方法可行,在本文中我們選擇其中之一:位置編碼(Positional Encoding) 。位置編碼包括將預定義序列中的一系列向量添加到單詞嵌入(embedding) 向量上去,並確保我們獲得每個句子都有唯一表示形式且具有相似語義結構、僅單詞順序不同的句子將被分配到不同的向量。在下面的示例中,“Write”、“a”、“story”和“.”所對應的向量成爲帶有位置信息標籤“Write(1)”,“a(2)”,“story(3)”和“. (4)”的修改後向量。
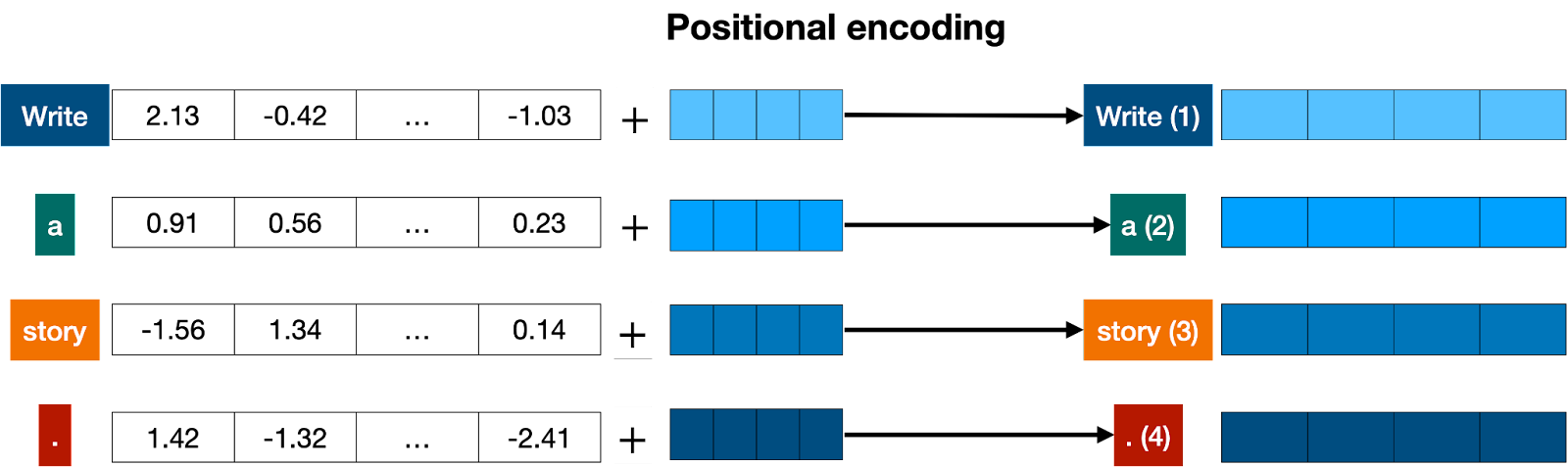
現在我們知道每個句子都有一個獨特的向量,這個向量攜帶了句子中所有單詞及其順序的信息,因此我們可以進入下一步。
4.1 Transformer block
讓我們回顧一下目前爲止的內容。單詞被輸入並轉換成token(分詞),然後考慮到它們的順序(位置編碼)。這給了我們每個輸入模型的token一個向量。現在,下一步是預測這個句子中的下一個單詞。這是通過一個非常大、非常複雜的神經網絡來完成的,該網絡專門訓練用於預測句子中的下一個單詞。
我們可以訓練這樣一個大型網絡,但是通過添加關鍵步驟:Attention(注意力)組件,我們可以極大地改進它。在開創性論文《Attention is All you Need》中引入的注意力機制是Transformer模型的關鍵成分之一,也是它們如此有效的原因之一。下面將解釋注意力機制,但現在先想象它作爲一種向文本中每個單詞添加上下文的方式。
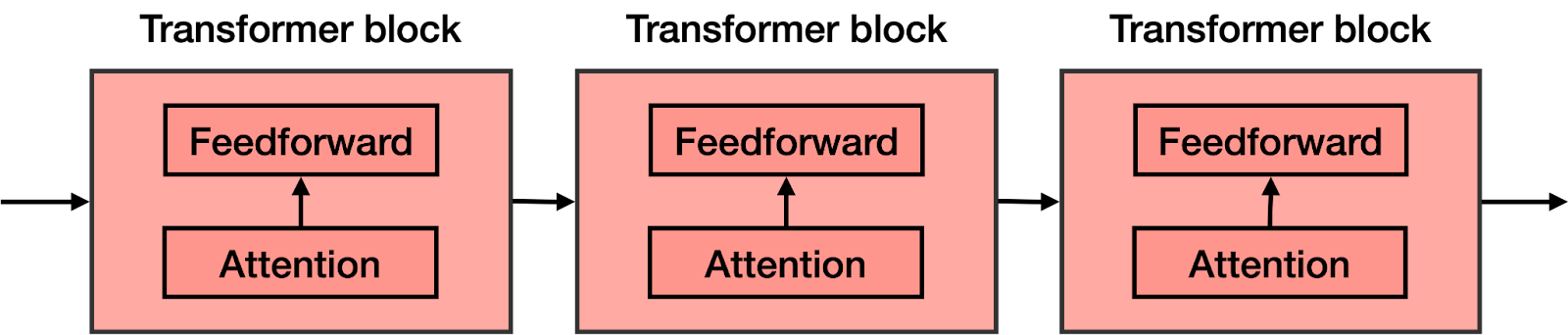
在前饋網絡的每個塊中都添加了注意力組件。因此,如果您想象一個大型前饋神經網絡,其目標是預測下一個單詞,並由幾個較小的神經網絡塊組成,則在每個這些塊中都添加了注意力組件。然後,Transformer的每個組件(稱爲transformer 塊)由兩個主要組件構成:
- 注意力組件
- 前饋組件
Transformer是許多Transformer塊的串聯。
4.2 Attention
Attention步驟涉及一個非常重要的問題:上下文問題。有時,同一個單詞可以用不同的意思。這往往會讓語言模型感到困惑,因爲embedding只是將單詞賦值到向量中,而不知道他們使用的單詞定義。
Attention是一種非常有用的技術,可以幫助語言模型理解上下文。爲了理解Attention的工作原理,請考慮以下兩個句子:
句子1: The bank of the river
句子2: Money in the bank.
正如您所看到的,單詞“bank”在兩個句子中都出現了,但含義不同。在第一個句子中,我們指的是河流旁邊的土地,在第二個句子中則指持有貨幣的機構。計算機對此一無所知,因此我們需要以某種方式將這些知識注入其中。什麼能幫助我們呢?好吧,似乎句子中其他單詞可以拯救我們。對於第一個句子,“the”和“of”這些單詞對我們沒有任何作用。但是,“river”這個單詞讓我們知道正在談論河流旁邊的土地。同樣,在第二個句子中,“money”這個單詞讓我們明白“bank”的意思現在是指持有貨幣的機構。

簡而言之,注意力機制的作用是將句子(或文本片段)中的單詞在詞嵌入中靠近。這樣,在句子“Money in the bank”中,“bank”一詞將被移動到“money”的附近。同樣,在句子“The bank of the river”中,“bank”一詞將被移動到“river”的附近。這樣,兩個句子中修改後的單詞“bank”都會攜帶周圍單詞的某些信息,爲其添加上下文。
Transformer模型中使用的注意力機制實際上更加強大,它被稱爲多頭注意力。在多頭注意力中,使用了幾個不同的嵌入來修改向量併爲其添加上下文。多頭注意力已經幫助語言模型在處理和生成文本時達到了更高的效率水平。如果您想更詳細地瞭解注意力機制,請查看這篇博客文章及其相應視頻。
5.The Softmax Layer
現在你已經知道一個transformer是由許多層transformer塊組成的,每個塊都包含一個attention和一個feedforward層,你可以將它看作是一個大型神經網絡,用於預測句子中的下一個單詞。Transformer爲所有單詞輸出分數,其中得分最高的單詞被賦予最有可能成爲句子中下一個單詞的概率。
Transformer的最後一步是softmax層,它將這些分數轉換爲概率(總和爲1),其中得分最高對應着最高的概率。然後我們可以從這些概率中進行採樣以獲取下一個單詞。在下面的例子中,transformer給“Once”賦予了0.5的最高概率,並給“Somewhere”和“There”賦予了0.3和0.2 的概率。一旦我們進行採樣,“once”就被選定,並且那就是transformer 的輸出結果。
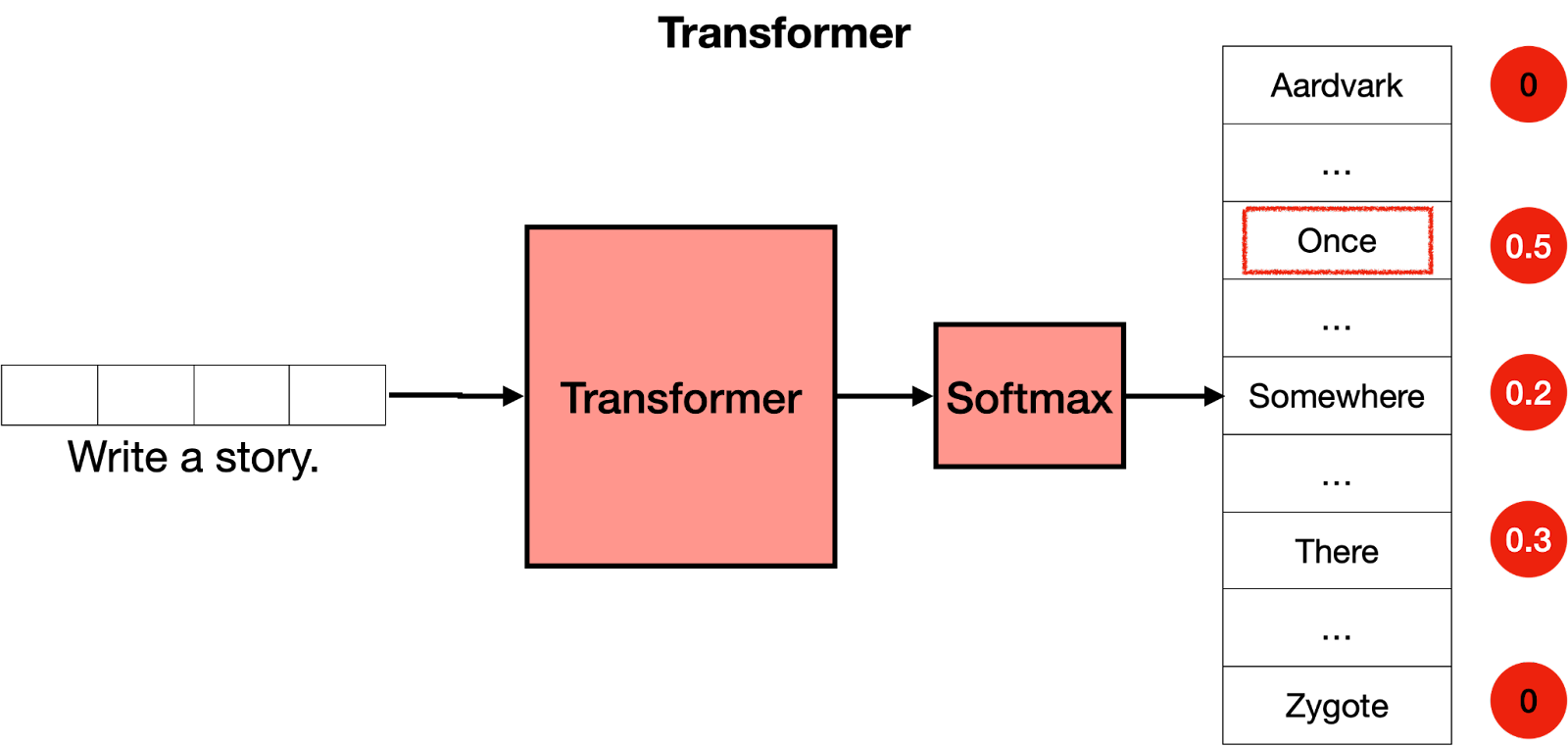
現在怎麼辦?好的,我們重複這個步驟。現在我們將文本“Write a story. Once”輸入模型中,很可能輸出結果是“upon”。再次重複此步驟,Transformer最終會寫出一個故事,例如:“Once upon a time, there was a …”(“從前有一天,有一個……”)。
Summary總結
在這篇文章中,您已經學習了transformers的工作原理。它們由幾個塊組成,每個塊都有自己的功能,共同工作以理解文本並生成下一個單詞。這些塊如下:
Tokenizer:將單詞轉換爲token。
Embedding:將token轉換爲數字(向量)。
Positional encoding:在文本中添加單詞順序。
Transformer block:猜測下一個單詞。它由注意力塊和前饋塊組成。
Attention:爲文本添加上下文信息。
Feedforward:是Transformer神經網絡中的一個模塊,用於猜測下一個單詞。
Softmax函數: 將得分轉換爲概率以便採樣出下一個單詞。
重複執行這些步驟就可以寫出您所看到的transformers創建的驚人文本。
Post Training(後期訓練)
現在你已經知道了Transformer是如何工作的,但我們還有一些工作要做。想象一下:你扮演Transformer,“阿爾及利亞的首都是什麼?” 我們希望它回答“阿爾及爾”,然後繼續進行。然而,這個Transformer是在整個互聯網上訓練出來的。互聯網很大,並不一定是最好的問題/答案庫。例如,許多頁面會列出長長的問題列表而沒有答案。在這種情況下,“阿爾及利亞的首都是什麼?”之後的下一個句子可能會是另一個問題,比如“阿爾及利亞人口數量?”,或者“布基納法索首都在哪裏?”。 Transformer不像人類那樣思考他們的迴應,它只是模仿它看到過(或提供過)數據集中所見到內容。
那麼我們該怎樣使Transformer回答問題呢?
答案就在於後期訓練。就像您教導一個人完成某些任務一樣,您可以讓Transformer執行任務。 一旦將Transformer訓練成整個互聯網上使用時,則需要再次對其進行大量數據集培訓以涉及各種問題和相應答案。Transformer(就像人類一樣)對他們最後學到的事情有偏見,因此後期訓練已被證明是幫助Transformer成功完成所要求任務的非常有用的步驟。
後期訓練還可以幫助處理許多其他任務。例如,可以使用大量對話數據集來進行Transformer的後期培訓,以使其作爲聊天機器人表現良好,或者幫助我們編寫故事、詩歌甚至代碼。
如上所述,這是一個概念性的介紹,讓您瞭解transformers如何生成文本。如果您想要深入瞭解transformer背後的數學原理,請觀看以下視頻(YouTube)。正如你所看到的,Transformer的架構並不複雜。它們是由幾個塊連接而成,每個塊都有自己的功能。它們之所以能夠工作得如此出色,主要原因在於它們具有大量參數,可以捕捉上下文中許多方面的信息。