




內存屏障是一種基礎語言,在不同的計算機架構下有不同的實現細節。本文主要在x86_64處理器下,通過Linux及其內核代碼來分析和使用內存屏障
對大多數應用層開發者來說,“內存屏障”(memory Barrier)是一種陌生,甚至有些詭異的技術。實際上,他機制常被用在操作系統內核中,用於實現同步、驅動程序利用它,能夠實現高效的無鎖數據結構,提高多線程程序的性能表現。本文首先探討了內存屏障的必要性,之後介紹如何利用內存屏障實現一個無鎖喚醒振盪器(隊列),用於在多個線程間進行高效的數據交換。
理解內存屏障
開發者顯然不明白一個事實——程序實際運行時很可能並不完全按照開發者編寫的順序訪問內存。例如:
|
|
這裏,y = 1很可能先於x = r執行。這就是內存亂序訪問。內存亂序訪問發生的原因是爲了提升程序運行時的性能。編譯器和CPU都可能引起內存亂序訪問:
- 編譯時,編譯器優化進行指令重排而導致內存亂序訪問;
- 運行時,多CPU間交互引入內存亂序訪問。
編譯器和CPU引入內存亂序訪問通常不會帶來什麼問題,但在一些特殊情況下(主要是多線程程序中),邏輯的正確性依賴於內存訪問順序,接下來,內存亂序訪問會帶來邏輯上的錯誤,例如:
|
|
ok初始化爲0,線程1等待ok被設置爲1後執行do函數。假設,線程2對內存的寫操作亂序執行,如果x判斷晚於ok完成判斷,那麼do函數接受的實參很有可能出乎開發者的意料,不爲42。
我們可以引入內存屏障來避免上述問題的出現。內存屏障可以讓CPU或者編譯器在內存訪問上進行。內存屏障之前的內存訪問操作一定要先於其之後的完成。內存屏障包括兩類:編譯器屏障和CPU內存屏障。
編譯時內存亂序訪問
編譯器對代碼進行優化時,可能會改變實際執行指令的順序(例如g++下O2或者O3都會實際執行指令的順序),改變看一個例子:
|
|
首先直接編譯次源文件:g++ -S test.cpp。我們得到相關的編譯代碼如下:
|
|
這裏我們可以看到,x = r並且y = 1並沒有亂序執行。現使用優化選項O2(或O3)編譯上面的代碼(g++ -O2 –S test.cpp),生成代碼如下:
|
|
我們可以清楚地看到經過編譯器優化之後,movl $1, y(%rip)先於movl %eax, x(%rip)執行,這意味着,編譯器優化導致了內存亂序訪問。避免次次行爲的辦法就是使用編譯器屏障(又叫優化屏障)。Linux內核提供了函數barrier(),用於讓編譯器保證其之前的內存訪問先於其之後的內存訪問完成。(這個強制保證順序的需求在哪裏?換句話說亂序會帶來什麼問題? – 一個線程執行了 y =1 ,但實際上 x=r 還沒有執行完成,此時被另一個線程搶佔,另一個線程執行,發現y =1,認爲此時x必定=r,執行相應邏輯,造成錯誤)內核實現barrier()如下:
|
|
現在把這個編譯器barrier加入代碼中:
|
|
再編譯,就會發現內存亂序訪問已經不存在了。除了barrier()函數外,本例還可以使用volatile這個關鍵字來避免編譯時內存亂序訪問(且只能避免編譯時的亂序訪問) ,爲什麼呢,可以參考前面部分的說明,編譯器對於 volatile 聲明到底做了什麼 – volatile 關鍵字對於編譯器而言,是開發者告訴編譯器,這個變量內存的修改,可能不再是你可視範圍了內部修改,不要對這個變量相關的代碼進行優化)。volatile關鍵字允許對易失性變量之間的內存進行訪問,這裏可以x和y的定義來解決問題:
|
|
通過 volatile 關鍵字,使得 x 相對 y、y 相對 x 在內存訪問上是集羣的。實際上,Linux 內核中,宏ACCESS_ONCE可以避免編譯器對於連續的ACCESS_ONCE實例進行指令重排,其就是通過volatile實現的:
|
|
此代碼只是將變量轉換爲易失性的最後。現在我們有了第三個修改方案:
|
|
到這裏,基本上就闡述完成了編譯時內存亂序訪問的問題。下面看看CPU有怎樣的行爲。
運行時內存亂序訪問
運行時,CPU本身是會亂序執行指令的。早期的處理器爲陣列處理器(in-order ports),總是按開發者編寫的順序執行指令,如果指令的輸入操作對象(input operands)不可用(通常由於需要從內存中獲取),那麼處理器不會轉而執行那些輸入操作對象可用的指令,而是當前等待輸入操作對象可用。相比之下,亂序處理器(out-of) -順序處理器)會先處理那些可用的輸入操作對象的指令(而不是順序執行)從而避免了等待,提高了效率。現代計算機上,處理器運行的速度比內存快很多,小區處理器花在等待可用的數據時間裏已可處理大量指令了。即使現代處理器會亂序執行,但在單個CPU上,指令可以通過指令隊列順序獲取並執行,結果利用隊列順序返回註冊堆(詳情可參考http ) ://en.wikipedia.org/wiki/Out-of-order_execution),這使得程序執行時所有的內存訪問操作看起來像是按程序代碼編寫的順序執行的,因此內存屏障是沒有必要使用的(前提是不考慮編譯器優化的情況下)。
SMP架構需要內存接口的進一步解釋:從體系結構上來看,首先在SMP架構下,每個CPU與內存之間,都分配了自己的高速緩存(Cache),以減少訪問內存時的衝突
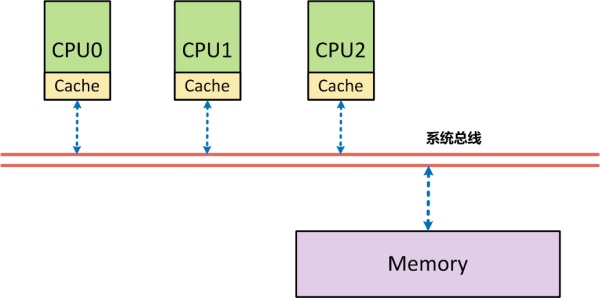
採用高速服務器的寫操作有兩種模式:(1).由於(Write through)模式,每次寫時,都直接將數據寫回內存中,效率相對較低;(2).回寫(Write back)模式,寫的時候先寫回告訴存儲,然後由高速存儲的硬件再週轉複用緩衝線(Cache Line)時自動將數據寫回內存,或者由軟件主動“沖刷”有關的緩衝線(Cache Line)。出於性能的考慮,系統往往採用的是模式2來完成數據寫入。由於存在高速緩存這一層,由於採用了Write back模式的數據寫入,才導致在 SMP 架構下,對高速存儲的運用可能會改變對內存操作的順序。上面的一個簡單代碼如下:
|
|
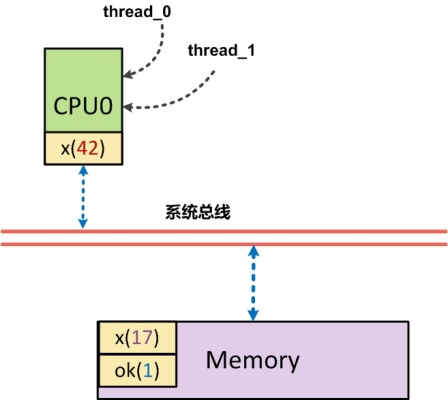
這裏CPU1執行時,x一定是打印出42嗎?讓我們來看看以下圖爲例的說明:

假設,正好CPU0的高速緩存中有x,此時CPU0就將x=42寫入到了高速緩存中,另外一個ok也在高速緩存中,但由於週轉複用高速緩衝線(Cache Line)而導致會ok=1刷會到了內存中,此時CPU1首先執行對ok內存的讀取操作,他讀到了ok爲1的結果,然後跳出循環,讀取x的內容,而此時,由於實際讀取的x(42)還僅在CPU0的高速緩存中,導致CPU1讀到的數據爲x(17)。程序中編排好的內存訪問順序(指令序號:program ordering)是先寫x,再寫y。而實際上出現在該CPU外部,即系統進程上的順序(處理器順序:processor ordering),卻是先寫入y,再寫入x(這個例子中x裝載)。在SMP架構中,每個CPU都只知道自己什麼時候會改變內存的內容,但是不知道其他CPU會在什麼時候改變內存的內容,也不知道自己本地的高速緩存中的內容是否與內存中的內容交互。反過來,每個CPU都可能因爲改變了內存內容,而使得其他CPU的高速緩存變的不一致。在SMP架構下,由於高速緩存的存在而導致內存訪問順序(讀或寫都可能書序被改變) )的改變很可能會影響到CPU間的同步與互斥。因此需要有一種手段,使得在某些操作之前,把這種“欠下”的內存操作(本例中的x=42的內存寫入)入)全部最終地、物理地完成,就希望把欠下的債都結清,然後再開始新的(通常是比較重要的)活動一樣。這種手段就是內存屏障,其本質原理就是對系統交互加鎖。
回過頭來,我們再來看看爲什麼非SMP架構(UP架構)下,運行時內存亂序訪問不存在。在單處理器架構下,各個進程在宏上是一堆的,但在少數上卻是串是的,因爲在同一時間點上,只有一個進程真正在運行(系統中只有一個處理器)。在這種情況下,我們接下來看看上面提到的例子:
thread0和完成thread1的指令都會在CPU0上按照指令順序執行。thread0通過CPU0x=42的高速緩存寫入後,再將ok=1寫入內存,此後串行的將thread0換出,thread1換入,此時x=42明顯讀取內存,但由於thread1的執行仍然是在CPU0上執行,他仍然訪問的是CPU0的高速緩存,因此,及時x=42先寫回到內存中,thread1勢還是先從高速緩存中讀到x=42,再從內存中讀到ok=1
綜上所述,在單CPU上,多線程執行不存在運行時內存亂序訪問,我們從內核源碼也可以得到類似的結論(代碼未完全摘錄)
|
|
這裏可以看到對內存屏障的定義,如果是SMP架構,smp_mb定義爲mb(),mb()爲CPU內存屏障(接下來要談的),不是SMP架構時(高通UP架構),直接使用編譯器屏障,運行時內存亂序訪問並不存在。
多CPU情況下會存在內存亂序訪問?我們知道每個CPU都存在Cache,當一個特定的數據第一次被其他CPU獲取時,這個數據爲什麼明顯不在對應CPU的Cache中(這就是Cache Miss)。這意味着CPU要從內存中快速獲取數據(這個過程需要CPU等待幾百個週期),這個數據會被加載到CPU的Cache中,這樣後續就可以直接從Cache上訪問。當某個CPU進行寫時操作修改時,他必須確保其他CPU已將數據從他們的Cache中移除(以便保證一致性),只有在操作完成後移除,此CPU才能安全地數據。顯然,存在多個Cache時,必須通過一個緩存一致性協議來避免數據不一致的問題,而這個通信的過程就可能導致亂序訪問的出現,甚至運行時內存亂序訪問。受篇幅所限,這裏不再深入討論整個細節,有興趣的讀者可以研究一下《內存屏障:軟件黑客的硬件觀點》這篇文章,它詳細分析了整個過程。
現在通過一個例子來仔細說明多CPU下內存亂序訪問的問題:
|
|
變量x、y、r1、r2均被初始化爲0,run1和run2運行在不同的線程中。如果run1和run2在同一個cpu下執行完成,那麼就如我們所料,r1和r2的值不會同時爲0,而假設run1而run2在不同的CPU下執行完成後,由於存在內存亂序訪問的可能,那麼r1和r2可能同時爲0。我們可以利用CPU內存屏障來運行時避免內存亂序訪問(x86_64):
|
|
x86/64 系統架構提供了三中內存屏障指令:(1) sfence ; (2) 柵欄; (3) mfence。(參考介紹: http: //peeterjoot.wordpress.com/2009/12/04/intel-memory-ordering-fence-instructions-and-atomic-operations/以及Intel文檔:http://www .intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-vol-3a-part-1-manual.pdf和http://www .intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html)
-
sfence
對 SFENCE 指令之前發出的所有存儲到內存指令執行序列化操作。此序列化操作保證在 SFENCE 指令之後的任何存儲指令全局可見之前,按程序順序位於 SFENCE 指令之前的每個存儲指令都是全局可見的。 SFENCE 指令按照存儲指令、其他 SFENCE 指令、任何 MFENCE 指令和任何序列化指令(例如 CPUID 指令)排序。它沒有根據加載指令或 LFENCE 指令進行排序。表示sfence確保:sfence指令前置的讀取(store/release)指令,按照在sfence前置的指令順序進行執行。寫內存提供屏障這樣的保證:所有出現在屏障之前的STORE操作都將先於所有在界面之後出現的 STORE 操作被系統中的其他組件所感知。
[!]注意,寫屏障一般需要與讀屏障或數據依賴屏障使用;請參閱“SMP內存界面配置”章節。 (原文注:因爲寫屏障只保證自己提交的順序,而無法影響其他代碼讀內存的順序。所以配置使用很重要。其他類型的屏障亦是同理。)
-
lfence
對 LFENCE 指令之前發出的所有從內存加載指令執行序列化操作。此序列化操作保證在 LFENCE 指令之後的任何加載指令全局可見之前,按程序順序位於 LFENCE 指令之前的每個加載指令都是全局可見的。 LFENCE 指令相對於加載指令、其他 LFENCE 指令、任何 MFENCE 指令和任何序列化指令(例如 CPUID 指令)進行排序。它不是根據存儲指令或 SFENCE 指令來排序的。也就是說lfence確保:lfence指令對稱的讀取(load/acquire)指令,按照在mfence對稱的指令順序進行執行。讀屏障包含數據依賴屏障的功能,並且保證所有出現在屏障之前的LOAD操作都將首先,所有出現在屏幕中的 LOAD 操作都被系統中的其他組件所獲取。
[!]注意,讀屏障一般要跟寫屏障使用;請參閱“SMP 內存接口的設置使用”章節。
-
mfence
對在 MFENCE 指令之前發出的所有從內存加載和存儲到內存的指令執行序列化操作。此序列化操作保證在 MFENCE 指令之後的任何加載或存儲指令全局可見之前,按程序順序位於 MFENCE 指令之前的每個加載和存儲指令全局可見。 MFENCE 指令相對於所有加載和存儲指令、其他 MFENCE 指令、任何 SFENCE 和 LFENCE 指令以及任何序列化指令(例如 CPUID 指令)進行排序。也就是說mfence指令:確保所有mfence指令的寫入(store/release)指令之前,都在該mfence指令之後的寫入(store/release)指令之前(指令序,Program Order)執行;同時,他還確保所有mfence指令之後的讀取(load/acquire)指令,都在該mfence指令之前的讀取(load/acquire)指令之後執行。即:既保證寫者能夠按照指令完成順序讀取數據,也保證讀卡器能夠按照指令順序完成數據讀取。通用內存保證所有出現在屏障之前的 LOAD 和 STORE 操作都將先於所有出現在屏障之後的 LOAD 和 STORE 操作被系統中的其他組件所採集。
sfence我認爲它的動作,可以看做是一定將數據寫回內存,而不是寫到高速緩存中。lfence的動作,可以看做是一定將數據從高速存儲中抹掉,從內存中讀出來,而不是直接從高速緩存中讀取。mfence則正好結合了兩個操作。sfence只保證寫者在將數據(A->B)讀出內存的順序,並不能保證其他人讀(A,B)數據這時,一定是按照先讀A更新後的數據,再讀B更新後的數據這樣的順序,很有可能讀者讀到的順序是A舊數據,B更新後的數據,A更新後的數據(只是這個更新後面的數據出現在讀者的後面,他並沒有“實際”去讀);同理,lfence也能保證讀者在讀入順序時,按照先讀A最新在內存中的數據,再讀B最新的在內存中的數據的順序,但如果沒有寫者圍欄的配合,顯然,即使順序一致,內容還是可能有亂序。
爲什麼僅僅通過保證寫者的寫入順序(sfence),還是可能有問題?還是之前的例子
|
|
如果對於“寫入”操作順序化,實際上,還是有可能使上面的代碼出現r1,r2同時爲0(初始值)的場景:
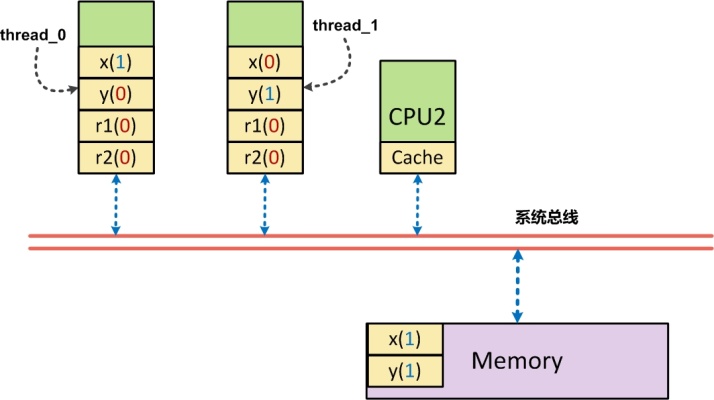
當CPU0上的thread0執行時,x被先行寫回內存中,但如果此時y在CPU0的高速緩存中,則此時y從緩存中寫入,並被賦予r1寫回內存,此時r1爲0。同理,CPU1上的thread1執行時,y被先行寫入到內存中,如果此時x在CPU1的高速緩存中存在,則此時r2被賦予了x的(過時)值0,同樣存在了r1,r2同時爲0。這個現象實際上就是所謂的r1=y讀順序與x=1寫順序存在邏輯上的亂序導致(或者是r2 = x與y=1存在亂序) – 讀操作與寫操作之間存在亂序。而mfence就是這類亂序也亮度掉
如果是Bymfence,是怎樣解決該問題的呢?

當thread1在CPU0上對x=1進行讀取時,x=1被刷新到內存中,由於是mfence,他要求r1的讀取操作從內存讀取數據,而不是從內存中讀取數據,因此,此時如果y更新爲1,則r1 = 1;如果y沒有更新爲1,則r1 = 0,同時由於x更新爲1,r2必須從內存中讀取數據,則此時r2 = 1。總而言之就是r1,r2,一個=0,一個=1。
關於內存界面的一些補充
在實際的應用程序開發中,開發者可能完全不知道內存界面就寫出了正確的多線程程序,這主要是各種同步機制中已隱含了內存界面(但實際的內存界面有模擬)差別),使得不直接使用內存屏障也不會存在任何問題。但如果你希望編寫這樣的無鎖數據結構,那麼內存屏障意義重大。
在Linux內核中,除了前面說到的編譯器屏障—barrier()和ACESS_ONCE(),還有CPU內存屏障:
- 通用接口,保證讀寫操作,包括mb()和smp_mb();
- 寫操作屏障,僅保證寫操作社區,包括wmb()和smp_wmb();
- 讀操作界面,僅保證讀操作社區,包括rmb()和smp_rmb();
注意,所有的CPU內存屏障(除了數據依賴屏障外)都隱含了交叉器屏障(如果使用CPU內存屏障後就消耗再額外添加交叉器屏障了)。這裏的smp開通的內存屏障會根據配置在單處理器上直接使用編譯器屏障,而在SMP上才使用CPU內存屏障(即mb()、wmb()、rmb())。
還需要注意一點是,CPU內存屏障中某些類型的需要屏障成對使用,否則會出錯,詳細來說就是:一個寫操作屏障需要和讀操作(或者數據依賴)屏障一起使用(當然,通用屏障)也可以的),反之亦然。
通常,我們希望在寫屏障出現之前的 STORE 操作始終匹配度屏障或者數據依賴屏障之後出現的 LOAD 操作。以之前的代碼示例爲例:
|
|
我們實際上,是希望在thread2執行到do(x)時(在ok驗證確實=1時),x = 42確實是有效的(寫屏障出現之前的STORE操作),此時do(x),確實是在執行do(42)(讀屏障之後出現的LOAD操作)
利用內存屏障實現無鎖環形
最後,以一個利用內存屏障實現的無鎖環形線(只有一個讀線程和一個寫線程時)來結束本文。本代碼來自於內核FIFO的一個實現,內容如下(略去非關鍵代碼):
代碼來源:linux-2.6.32.63\kernel\kfifo.c
|
|
|
|
這裏__kfifo_put是一個線程用於向fifo中讀取數據,另外一個線程可以調用__kfifo_get,從而fifo安全讀取數據。代碼中in和out的索引用於指定環形動脈實際的頭和尾。具體的in和out所指向的弧形的位置通過與操作來求取(例如:fifo->in & (fifo->size -1)),這樣相比取餘操作來求拂表的做法效率要高顯着。使用與操作求拂表的前提是弧形弧形的大小必須是2的N次方,換算而言,就是說環形曲面的大小爲一個1的二進制數,則index & (size – 1)求取的下標(這不難理解)。
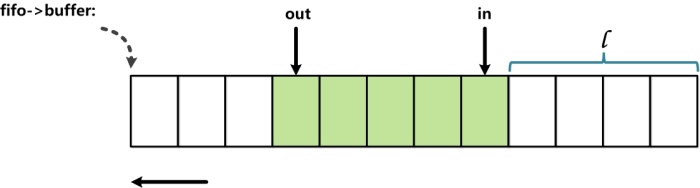
索引in和out被兩個線程訪問。in和out指明瞭拓撲中實際數據的邊界,所以in和out同拓撲數據機制存在訪問上的順序關係,由於不適用同步,所以保證順序關係就需要用到內存屏障了。索引in和out都分別只被一個線程修改,而被兩個線程讀取。__kfifo_put先通過in和out來確定可以向波形中寫入數據量的多少,然後,out索引器先被讀取,才能真正將用戶buffer中的數據寫入溼度,因此這裏應該使用到了smp_mb(),對應的,__kfifo_get也使用smp_mb()來確保修改出索引器之前的溼度表中數據已讀取成功並讀取用戶buffer中了。(我認爲在__kfifo_put中添加的這個smp_mb()是沒有必要的。理由如下,kfifo只支持一寫一讀,這是前提。在這個前提下,in和out兩個變量是有依賴關係的,這也沒錯,而且我們可以看到在put中,in一定會是最新的,因爲put是in的值,而在get中,out一定會是最新的,因爲get修改out的值。這裏的smp_mb ()顯然是希望在運行時,遵循out先加載新值,in再加載新值。確實,這樣做沒錯,但是是否有必要呢?out一定要是最新值嗎?out如果不是最新值會有什麼問題?如果out不是最新值,實際上並不會有什麼問題,在put時,fifo的實際可計算寫入空間要大於put計算出來的空間(因爲out是舊值,導致len在時偏小),這並不影響程序執行的正確性。來自最新linux-3.16-rc3內核的代碼:lib\kfifo.c的實現:__kfifo_in中也可以看出memcpy(fifo->data + off, src, l); memcpy(fifo->data, src + l, len - l);前面的那次smb_mb()已經被省去了,當然更新之前的smb_wmb()還是在kfifo_copy_in中被保留了。爲了省去這次smb_mb()的調用,我想除了省去調用不影響程序正確性之外,是否還有對於性能影響的考慮,儘量減少不必要的mb調用)對於索引,在__kfifo_put中,通過smp_wmb()保證先向係數讀取數據後才修改索引,由於這裏只需要保證讀取操作數組,所以採用寫操作界面,在__kfifo_get中,通過smp_rmb()保證先讀取了索引中的數據(其次在索引中用於確定彩虹中實際存在多少剩餘數據)纔開始讀取彩虹中數據(並讀取用戶緩衝區中),由於這裏指需要保證讀取操作網格,故採用讀取操作屏障。
什麼時候需要注意考慮記憶互動(補充)
從上面的介紹我們已經可以看出,在SMP環境下,內存中斷非常重要,在多線程併發執行的程序中,一個數據讀取與亂序訪問,就有可能導致邏輯上錯誤,而顯然這不是我們希望看到的。作爲系統程序的實現者,我們涉及到內存屏障的場景主要集中在無鎖編程時的原子操作。執行這些操作的地方,就是我們需要考慮內存屏障的地方。
從我自己的經驗來看,使用原子操作,一般有以下清晰的方式:(1)。直接對int32、int64進行屬性;(2).使用gcc內建的原子操作內存訪問接口;(3).調用第三方atomic庫:libatomic實際內存原子操作。
- 對於第一類原子操作方式,顯然內存交互是需要我們考慮的,例如kernel中kfifo的實現,就必須要在數據讀取和讀取時插入必要的內存交互顯示的考慮,以保證程序執行的順序與我們設定的順序一致。
- 對於使用 gcc 內建的原子操作訪問接口,基本上大多數 gcc 內建的原子操作都自帶內存交互,他可以保證在執行原子內存訪問相關的操作時,執行順序不被打斷。在這種情況下,這些內置函數被認爲是一個完整的障礙。也就是說,任何內存操作數都不會在整個操作中向前或向後移動。此外,將根據需要發出指令,以防止處理器推測整個操作的負載以及操作後對存儲進行排隊。”(http://gcc.gnu.org/onlinedocs/gcc-4.4.5/gcc/Atomic-當然,其中也有幾個容易實現完全屏障,具體情況可以參考gcc文檔對對應接口的說明。同時,gcc還提供了對內存接口的封裝接口:__sync_synchronize (…),這可以作爲應用程序使用內存接口的接口(不用寫接口語句)。
- 用於使用libatomic庫進行原子操作,原子訪問的程序。Libatomic在接口上對於內存接口的設置粒度更新,他幾乎是對每一個原子操作的接口針對不同的平臺都有對應的不同內存接口的綁定。提供多種架構上原子內存更新操作的實現。這允許在相當可移植的代碼中直接使用它們。與早期的類似包不同,這個包明確考慮了內存屏障語義,並允許構建跨各種架構的最小開銷的代碼。”接口實現上分別添加了_release/_acquire/_full等各個後綴,分別代表的該接口的內存接口類型,具體說明可參見libatomic的README說明。如果是調用最賺錢的接口,已AO_compare_and_swap爲例,最終會根據平臺的特性以及宏定義情況調用到:AO_compare_and_swap_fullAO_compare_and_swap_release或者AO_compare_and_swap_release等。我們可以重點關注libatomic在x86_64上的實現,libatomic中,在x86_64架構下,還提供了應用層的內存接口接口:AO_nop_full
綜合以上三點,總結下來就是:如果你在程序中是裸着寫內存,讀內存,則需要顯着地使用內存接口來保證你程序的正確性,gcc內建不提供簡單的封裝了內存接口的內存讀寫只是存在,因此,如果使用gcc內建函數,你仍然裸讀,裸寫,此時你還是必須顯式使用內存屏障。如果你通過libatomic進行內存訪問,在x86_64架構下,使用AO_load /AO_store,你可以不再顯着式的使用內存屏障(但從實際使用的情況來看,libatomic這類接口的效率並不是很高)