




Pytorch打怪路(一)pytorch進行CIFAR-10分類(2)定義卷積神經網絡

注:官方文檔地址-- http://pytorch.org/docs/0.3.0/index.html
我的系列博文
Pytorch打怪路(一)pytorch進行CIFAR-10分類(1)CIFAR-10數據加載和處理
Pytorch打怪路(一)pytorch進行CIFAR-10分類(2)定義卷積神經網絡(本文)
Pytorch打怪路(一)pytorch進行CIFAR-10分類(3)定義損失函數和優化器
Pytorch打怪路(一)pytorch進行CIFAR-10分類(4)訓練
Pytorch打怪路(一)pytorch進行CIFAR-10分類(5)測試
1、簡述
官網tutorial中顯示圖片的那部分我就直接省略了,因爲跟訓練網絡無關,只是for fun
這一步驟雖然代碼量很少,但是卻包含很多難點和重點,執行這一步的代碼需要包含以及神經網絡工具箱torch.nn、以及神經網絡函數torch.nn.functional,如果有興趣的同學去看一下官網的Docs,會發現這倆模塊所佔的篇幅是相當相當的長啊,不知道一下午能不能看完….
所以我在這裏也就簡要地、根據此例所給的代碼,來講解一下即可,更多的內容還是參考官方文檔更實在,雖然更費時……
所以我在這裏也就簡要地、根據此例所給的代碼,來講解一下即可,更多的內容還是參考官方文檔更實在,雖然更費時……
注意:雖然官網給的程序有這麼一句 from torch.autograd import Variable,但是此步中確實沒有顯式地用到variable,只能說網絡裏運行的數據確實要以variable的形式存在,在後面我們會講解這個內容
所以這節先不討論,當然代碼寫在那裏是沒問題的,反正後面會用
2.代碼
# 首先是調用Variable、 torch.nn、torch.nn.functional
from torch.autograd import Variable # 這一步還沒有顯式用到variable,但是現在寫在這裏也沒問題,後面會用到
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module): # 我們定義網絡時一般是繼承的torch.nn.Module創建新的子類
def __init__(self):
super(Net, self).__init__() # 第二、三行都是python類繼承的基本操作,此寫法應該是python2.7的繼承格式,但python3裏寫這個好像也可以
self.conv1 = nn.Conv2d(3, 6, 5) # 添加第一個卷積層,調用了nn裏面的Conv2d()
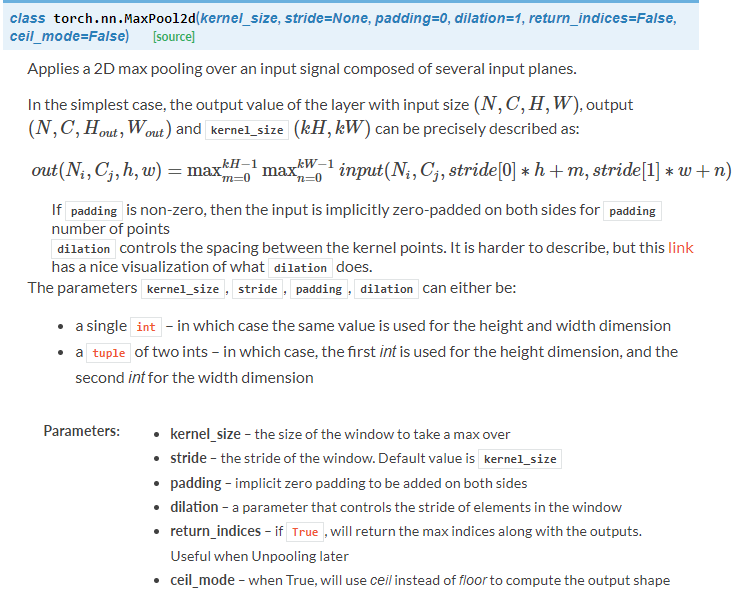
self.pool = nn.MaxPool2d(2, 2) # 最大池化層
self.conv2 = nn.Conv2d(6, 16, 5) # 同樣是卷積層
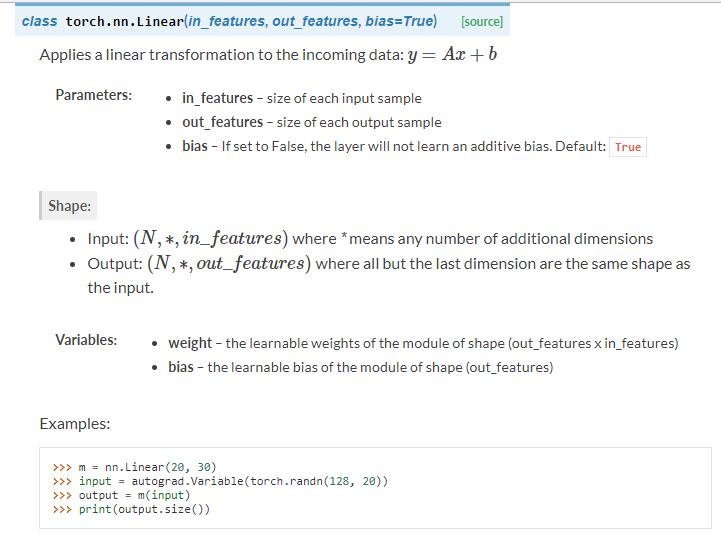
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 接着三個全連接層
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): # 這裏定義前向傳播的方法,爲什麼沒有定義反向傳播的方法呢?這其實就涉及到torch.autograd模塊了,
# 但說實話這部分網絡定義的部分還沒有用到autograd的知識,所以後面遇到了再講
x = self.pool(F.relu(self.conv1(x))) # F是torch.nn.functional的別名,這裏調用了relu函數 F.relu()
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5) # .view( )是一個tensor的方法,使得tensor改變size但是元素的總數是不變的。
# 第一個參數-1是說這個參數由另一個參數確定, 比如矩陣在元素總數一定的情況下,確定列數就能確定行數。
# 那麼爲什麼這裏只關心列數不關心行數呢,因爲馬上就要進入全連接層了,而全連接層說白了就是矩陣乘法,
# 你會發現第一個全連接層的首參數是16*5*5,所以要保證能夠相乘,在矩陣乘法之前就要把x調到正確的size
# 更多的Tensor方法參考Tensor: http://pytorch.org/docs/0.3.0/tensors.html
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 和python中一樣,類定義完之後實例化就很簡單了,我們這裏就實例化了一個net
net = Net()
3.涉及知識點
①神經網絡工具箱 torch.nn
這是一個轉爲深度學習設計的模塊,我們來看一下官方文檔中它的目錄
可以看到,nn模塊中有很多很多的子模塊,其中較爲重要的,也是在咱們上面的程序中出現過的一些內容包括:
a. Container中的Module,也即nn.Module
看一下nn.Module的詳細介紹
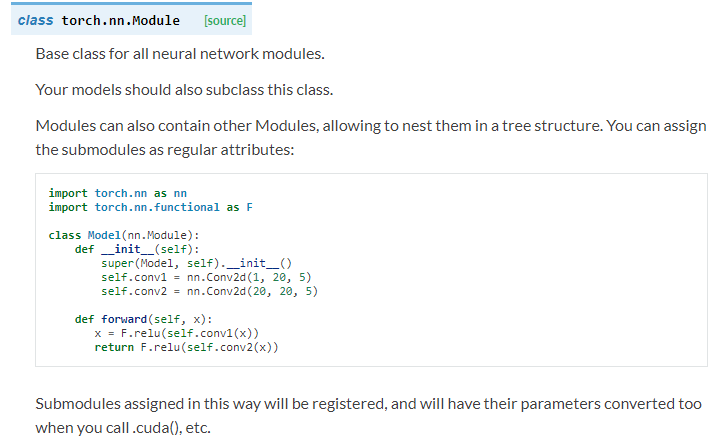
可知,nn.Module是所有神經網絡的基類,我們自己定義任何神經網絡,都要繼承nn.Module!class Net(nn.Module):
b. convolution layers
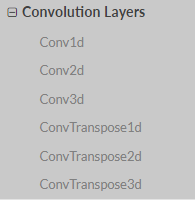
我們在上面的代碼塊中用到了Conv2d: self.conv1 = nn.Conv2d(3, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5)

例如Conv2d(1,20,5)的意思就是說,輸入是1通道的圖像,輸出是20通道,也就是20個卷積核,卷積核是5*5,其餘參數都是用的默認值
c. pooling layers
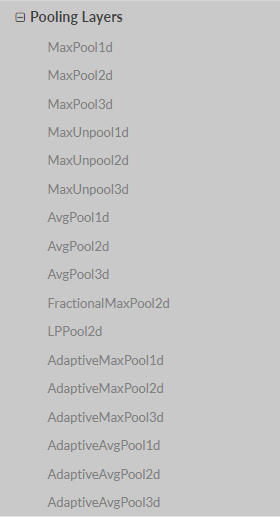
可以看到有很多的池化方式,我們上面的代碼採用的是Maxpool2d: self.pool = nn.MaxPool2d(2, 2)
d. Linear layer
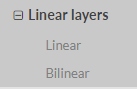
我們代碼中用的是線性層Linear: self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10)
e. Non-linear Activations
要注意,其實這個例子中的非線性激活函數用的並不是torch.nn模塊中的這個部分,但是torch.nn模塊中有這個部分,所以我還是提一下。
此例中的激活函數用的其實是torch.nn.functional 模塊中的函數。它們是有區別的,區別下文繼續講。現在先瀏覽一下這個部分的內容即可:
可以看出,torch.nn 模塊中其實也有很多激活函數的,只不過我們此例用的不是這裏的激活函數!!!
②torch.nn.functional
這個模塊包含的內容如圖所示
torch.nn中大多數layer在torch.nn.funtional中都有一個與之對應的函數。二者的區別在於:
torch.nn.Module中實現layer的都是一個特殊的類,可以去查閱,他們都是以class xxxx來定義的,會自動提取可學習的參數
而nn.functional中的函數,更像是純函數,由def function( )定義,只是進行簡單的數學運算而已。
說到這裏你可能就明白二者的區別了,functional中的函數是一個確定的不變的運算公式,輸入數據產生輸出就ok,
而深度學習中會有很多權重是在不斷更新的,不可能每進行一次forward就用新的權重重新來定義一遍函數來進行計算,所以說就會採用類的方式,以確保能在參數發生變化時仍能使用我們之前定好的運算步驟。
所以從這個分析就可以看出什麼時候改用nn.Module中的layer了:
如果模型有可學習的參數,最好使用nn.Module對應的相關layer,否則二者都可以使用,沒有什麼區別。
比如此例中的Relu其實沒有可學習的參數,只是進行一個運算而已,所以使用的就是functional中的relu函數,
而卷積層和全連接層都有可學習的參數,所以用的是nn.Module中的類。
不具備可學習參數的層,將它們用函數代替,這樣可以不用放在構造函數中進行初始化。
定義網絡模型,主要會用到的就是torch.nn 和torch.nn.funtional這兩個模塊,這兩個模塊值得去細細品味一番,希望大家可以去讀一下官方文檔