




一行命令實現看圖說話|Google的im2txt模型
1.項目介紹
這次給大家介紹一個google的深度學習模型im2txt,這個模型的作用跟它的名字一樣,image-to-text,把圖像轉爲文字,也就是圖片描述。
這個模型是使用 2015 MSCOCO Image Captioning Challenge 的數據集訓練出來的
我對原始googel的項目做了很多簡化,減少了項目前期準備,優化了效果展示。
im2txt模型是一個深度神經網絡模型,可以實現如下圖像描述的效果:

對於生活中常見的一些場景,它還是可以比較正確地描述出圖片中的情況。
該模型是一個encoder-decoder模型。encoder是編碼器,它是一個CNN模型,常用於圖像識別,目標檢測等領域。各種常見的卷積網絡都可以,比如,VGG,Inception,ResNet等等。這裏我們用的是使用 ILSVRC-2012-CLS數據集訓練出來的Inception-V3模型。把圖片輸入Inception-V3中,可以得到一個固定長度的向量,這個向量可以看成是從圖像中提取出來的特徵。
decoder是×××,它是一個LSTM模型,常用於語言模型或機器翻譯等領域。我們把encoder中輸出的固定長度的向量輸入到decoder中,獲得關於圖像的描述。如下圖所示:
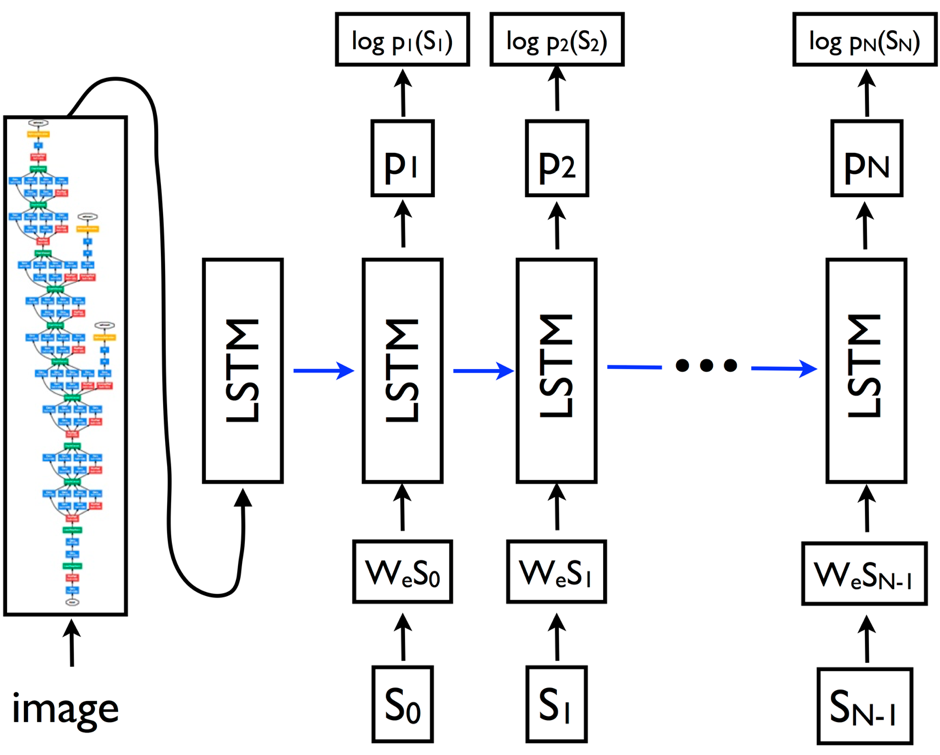
圖中的{s0, s1, ..., sN-1} 表示圖像的描述,每個s代表一個詞,圖中的{wes0, wes1, ..., wesN-1} 是每個詞的詞向量,比如word2vec。輸出的{p1, p2, ..., pN} 表示LSTM模型預測句子中的下一個詞所對應的概率分佈。{log p1(s1), log p2(s2), ..., log pN(sN)}表示正確詞的對數似然估計。
2.環境準備
我的實驗環境爲:
- Python-3.6
- Tensorflow-1.12
其他版本的軟件基本上也適用。
Python的安裝建議使用Anaconda
Anaconda下載
Tensorflow的安裝在Anaconda安裝完以後使用命令 pip install tensorflow 安裝。
3.模型準備
因爲github上放模型不方便,所以訓練好的模型我存放在我的百度雲盤上,大家可以通過雲盤下載。
百度雲盤鏈接
密碼:khtx
模型下載好之後解壓,然後把幾個模型相關的文件存入項目文件夾的根目錄中的model文件夾中,如下圖: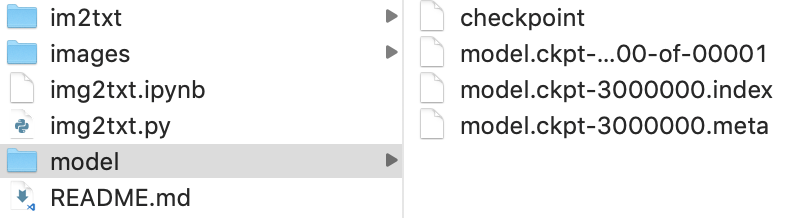
4.運行模型
- im2txt文件夾中是項目主要程序
- images文件夾中是需要測試的圖片
- model文件夾中是訓練好的模型
- img2txt.py是可以直接執行的python文件
- img2txt.ipynb是jupyter文件,推薦使用
顯示看圖說話只需要執行一行命令,在項目文件根目錄執行:python img2txt.py或者用jupyter打開img2txt.ipynb,在jupyter中運行可以更方便查看運行結果。
5.運行效果
我隨機着了一些照片來測試,其中包含一張我養的貓的照片。圖片的標題爲模型給出的預測結果。

這張照片識別效果還是很好的,正確描述了圖片中的主要物體鳥,並且正確識別了鳥的數量兩隻,圖片的背景水也識別出來了。
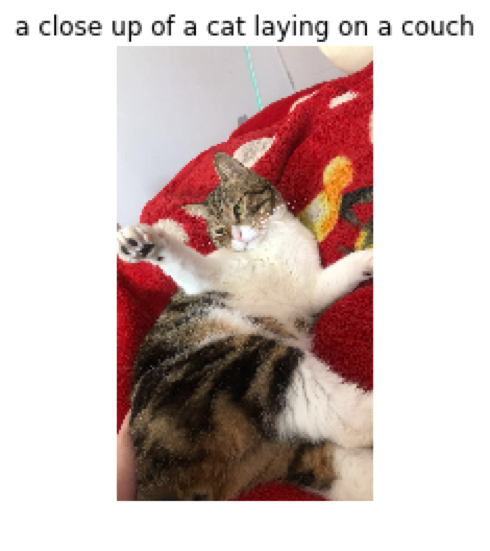
我家的貓,模型給出的描述是“一張貓的特寫圖片,一隻貓躺在沙發上”,描述基本上也算是比較正確。

預測結果是“一個年輕的男孩在草地上踢足球”,這個描述完全正確。

預測結果是“一個男人在衝浪板上衝浪”,描述也比較正確。
上面都是一些好的結果,當然也會很多識別不好的結果,比如下面這些:

預測結果爲“一個女人穿着粉紅色的雨傘站在人行道上”,因爲模型本身沒有日常的生活常識,所以它不知道人是不會穿着粉紅色雨傘在身上的。同時它對動作的描述不夠準確,這個人穿着芭蕾舞裙,並且她是在跳舞。

預測結果爲“水上衝浪板上的人”,這次模型的預測結果就錯得離譜了。因爲圖中沒有人,也沒有衝浪板。我們看到這幅圖第一感覺應該是被圖中漂亮的極光所吸引,不過模型還不具備欣賞美景的能力,所以它的沒有注意到天上綠綠的光,和漫天星空,它只看到了這個石頭有點像人,石頭旁邊的陸地有點像衝浪板。
總的看來,這個模型可以比較好的識別比較簡單的場景的,不過由於它不具備推理能力,沒有生活常識,欣賞能力,所以一些複雜情況的圖片它就不能很好的判斷了。
6.視頻描述
既然AI可以做圖像描述,那麼視頻描述肯定也是可以的。
video2txt.py是可以直接執行的python文件,可以傳入一個視頻並生成一個帶有描述的新的視頻
video2txt.ipynb是對應的jupyter文件
我找到星爺的經典電影大話西遊來做測試,我們理想的效果應該是:

但實際上是:



很顯然AI現在還看不懂電影,大家純屬娛樂就可以。
視頻:
視頻鏈接
完整項目代碼可以到我的github下載
我的github
喜歡的朋友,記得star和follow哦。