




更多可以阅读https://blog.csdn.net/column/details/23835.html
Neo4j
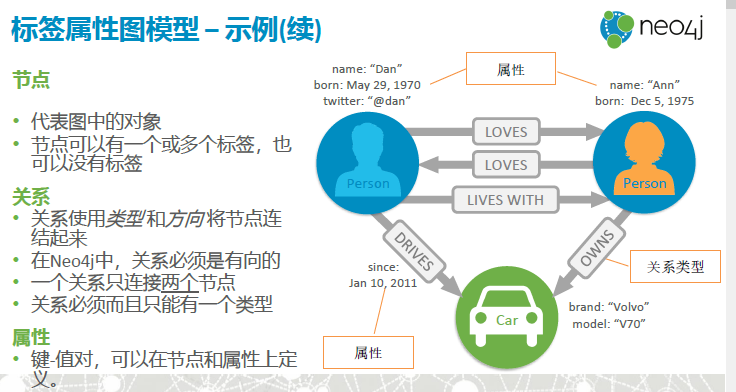
标签属性图模型
• Nodes – 节点。在其他图模型中称作“点”、“顶点”、“对象”。
• Relationships – 关系。在其他图模型中也称作“边”、“弧”、“线”。关系拥有类型。
• Properties – 属性,可以定义在节点和关系上。
• Labels – 标签,代表节点的类别。

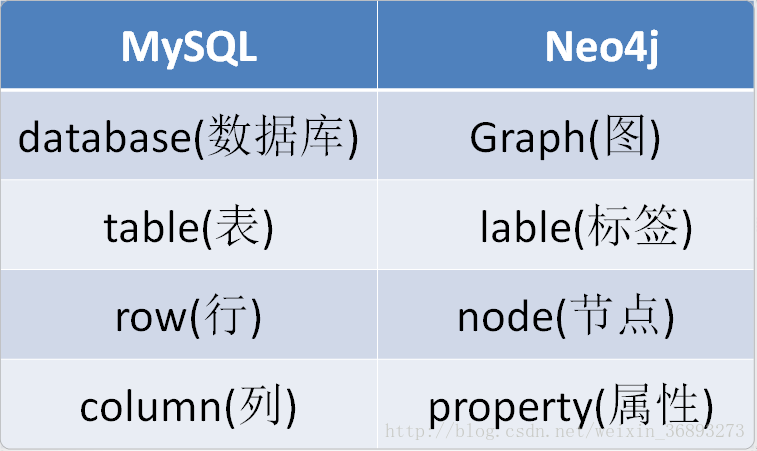
Neo4j与MySQL
这里有列出了一些与关系型数据库对应的概念方便理解:
动机
类似与关系型数据库,创建了多个数据库
想要像访问关系型数据库那样来可以无缝切换多个数据库
然而,在neo4j 3.0都暂时没有办法做到:每次启动neo4j,它只能读取一个数据库。
比如,现在有两个数据库graph.db,graph2.db。假设neo4j默认的数据库为graph.db,启动neo4j,这时候想要访问graph2.db,必须修改neo4j的配置文件,将数据库改为graph2.db,重启,此时才可以访问graph2.db.
那么,如何可以比较neat地切换数据库呢?
配置
Linux环境 同 博客:neo4j远程访问
方法
方法一:修改配置文件
这是官方文档方法
大概思路是:
新建一个conf_test文件
修改neo4j.conf:
# The name of the database to mount
dbms.active_database=graph2.db //你的数据库将新的neo4j的配置文件的路径设为当前session的环境变量。
重启neo4j
问题 来了,我每次都要先新建一个conf文件夹,修改conf文件,再设置环境变量,据麻烦!!!
方法二:建立graph.db的软连接【推荐!!!】
(突然走向了大甩卖的风格了 -_-#)
不需要修改配置文件,不需要设置环境变量
首次修改:
// 请将$NEO4j_HOME改为你的neo4j的安装路径
cd $NEO4j_HOME/data/databases/
// 保存原来数据库
mv graph.db graph1.db
//建立指向新数据库的软件接
ln -s graph2.db graph.db
//重启neo4j
cd $NEO4j_HOME/bin
./neo4j restart再次修改
倘若我想访问graph3.db,就很简单了
//建立指向新数据库的软件接
ln -s graph3.db graph.db
//重启neo4j
cd $NEO4j_HOME/bin
./neo4j restartCQL基本简介
Neo4j使用Cypher查询图形数据,Cypher是描述性的图形查询语言,语法简单,功能强大,由于Neo4j在图形数据库家族中处于绝对领先的地位,拥有众多的用户基数,使得Cypher成为图形查询语言的事实上的标准
CQL代表Cypher查询语言。 像Oracle数据库具有查询语言SQL,Neo4j具有CQL作为查询语言。
Cypher语言的关键字不区分大小写,但是属性值,标签,关系类型和变量是区分大小写的。

CQL数据类型
| S.No. | CQL数据类型 | 用法 |
|---|---|---|
| 1. | boolean | 用于表示布尔文字:true,false。 |
| 2. | byte | 用于表示8位整数。 |
| 3. | short | 用于表示16位整数。 |
| 4. | int | 用于表示32位整数。 |
| 5. | long | 用于表示64位整数。 |
| 6. | float | I用于表示32位浮点数。 |
| 7. | double | 用于表示64位浮点数。 |
| 8. | char | 用于表示16位字符。 |
| 9. | String | 用于表示字符串。 |
常用CQL命令与函数
通过常用命令实现图数据的增删改查
| S.No. | CQL命令/条 | 用法 |
|---|---|---|
| 1。 | CREATE 创建 | 创建节点,关系和属性 |
| 2。 | MATCH 匹配 | 检索有关节点,关系和属性数据 |
| 3。 | RETURN 返回 | 返回查询结果 |
| 4。 | WHERE 哪里 | 提供条件过滤检索数据 |
| 5。 | DELETE 删除 | 删除节点和关系 |
| 6。 | REMOVE 移除 | 删除节点和关系的属性 |
| 7。 | ORDER BY 以…排序 | 排序检索数据 |
| 8。 | SET 组 | 添加或更新标签 |
常用函数
| S.No. | 定制列表功能 | 用法 |
|---|---|---|
| 1。 | String 字符串 | 它们用于使用String字面量。 |
| 2。 | Aggregation 聚合 | 它们用于对CQL查询结果执行一些聚合操作。 |
| 3。 | Relationship 关系 | 他们用于获取关系的细节,如startnode,endnode等。 |
图数据的形式
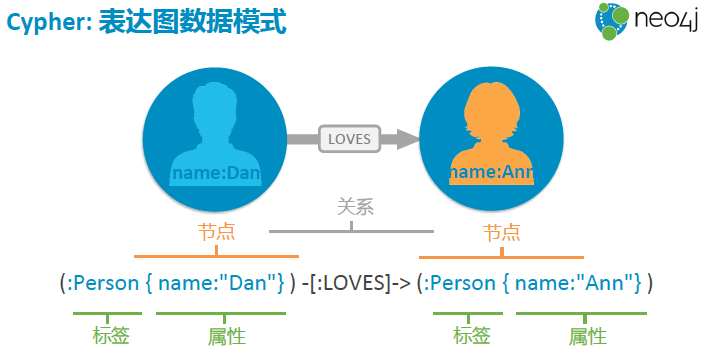


基本语法
节点
节点必须包含在括号 () 内
(n:Label1:Label2)• 标签名前必须有冒号
• 节点可以有多个标签
• 标签对节点进行分类,似关系数据库中的表 标签对节点进行分类,类似关系数据库中的表
(n)节点可以没有或者不指定标签
(n:Label {prop: 'value'})节点可以有属性
关系
关系两端各有一个短横线 /减号,用方括包含关系类型 ,关系类型名前面必须有冒号 (:) 。在其中一端用 >或 < 代表关系的方向,也可以没有方向
- - ,<- -,- ->
-[:DIRECTED]- ->关系以短划线\减号和方括号包含
与标签一样关系类型前必须要有“:”
- ->或 -[r:TYPE] ->关系在创建时必须指定方向
关系在查询时可以不指定方向表示双向关系
< >指定关系的方 向关系也可以有属性
-[:KNOWS {since: 2010}]模式
模式是由关系连接起来的节点构成的表达式,关系可以是有方向的,也可以没有方向,双向的
() -[] -()
() -[] ->()
()< -[] -()模式的例子
(n:Label {prop:'value'})-[:TYPE]- >(m:Label)- 最基本的模式:由一类关系连接两个节点 最基本的模式:
- 由一类关系连接两个节点
(p1:Person {name:'Alice'}) -[:KNOWS][->(p2:Person {name:'Bob'})如果存在从Alice到Bob的、类型为KNOWS的关系,那么上面模式会将匹配的节点保存在 p1 和p2中。
Cypher查询的组成部分
eg1.

eg 2.

eg 3.

图查询的结果 vs表状数据结果
eg 4.


命名规范

参考文献:Neo4j Inc. APAC 2018年 俞方桦
参考文献:https://www.cnblogs.com/wenruo/p/7850120.html