




優酷視頻網站架構
一、網站基本數據概覽
據2010年統計,優酷網日均獨立訪問人數(uv)達到了8900萬,日均訪問量(pv)更是達到了17億,優酷憑藉這一數據成爲google榜單中國內視頻網站排名最高的廠商。
硬件方面,優酷網引進的戴爾服務器主要以 PowerEdge 1950與PowerEdge 860爲主,存儲陣列以戴爾MD1000爲主,2007的數據表明,優酷網已有1000多臺服務器遍佈在全國各大省市,現在應該更多了吧。
二、網站前端框架
從一開始,優酷網就自建了一套CMS來解決前端的頁面顯示,各個模塊之間分離得比較恰當,前端可擴展性很好,UI的分離,讓開發與維護變得十分簡單和靈活,下圖是優酷前端的模塊調用關係: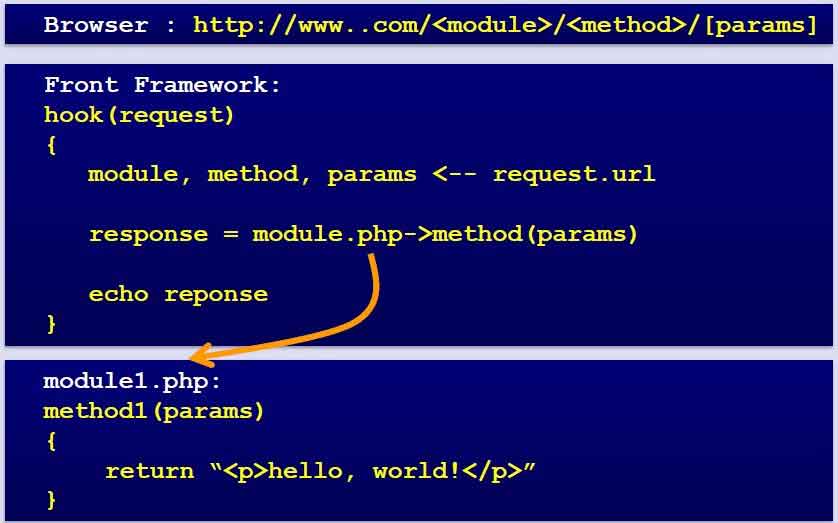
這樣,就根據module、method及params來確定調用相對獨立的模塊,顯得非常簡潔。下面附一張優酷的前端局部架構圖:
三、數據庫架構
應該說優酷的數據庫架構也是經歷了許多波折,從一開始的單臺MySQL服務器(Just Running)到簡單的MySQL主從複製、SSD優化、垂直分庫、水平sharding分庫,這一系列過程只有經歷過纔會有更深的體會吧,就像MySpace的架構經歷一樣,架構也是一步步慢慢成長和成熟的。
1、簡單的MySQL主從複製:
MySQL的主從複製解決了數據庫的讀寫分離,並很好的提升了讀的性能,其原來圖如下: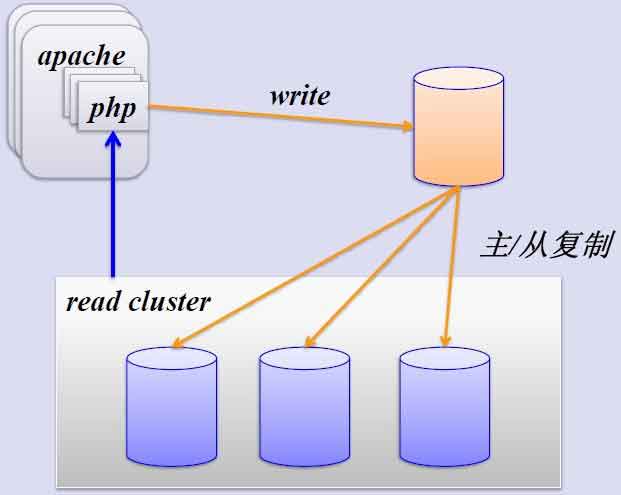
其主從複製的過程如下圖所示: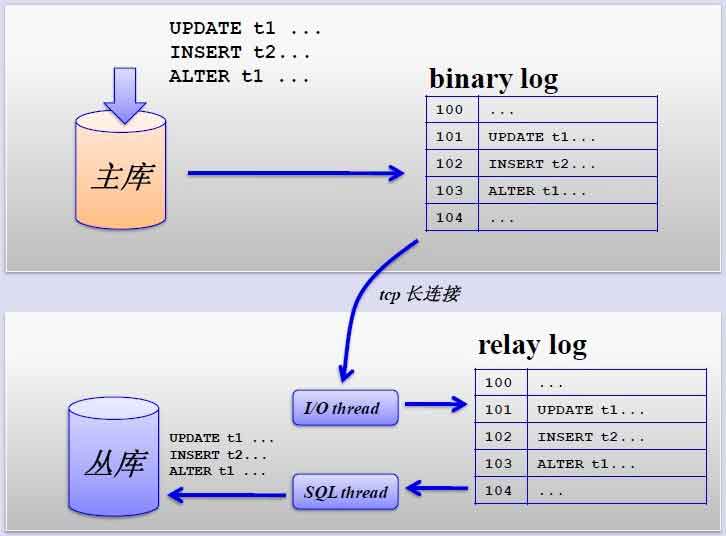
但是,主從複製也帶來其他一系列性能瓶頸問題:
-寫入無法擴展
-寫入無法緩存
-複製延時
-鎖表率上升
-表變大,緩存率下降
那問題產生總得解決的,這就產生下面的優化方案,一起來看看。
2、MySQL垂直分區
如果把業務切割得足夠獨立,那把不同業務的數據放到不同的數據庫服務器將是一個不錯的方案,而且萬一其中一個業務崩潰了也不會影響其他業務的正常進行,並且也起到了負載分流的作用,大大提升了數據庫的吞吐能力。經過垂直分區後的數據庫架構圖如下: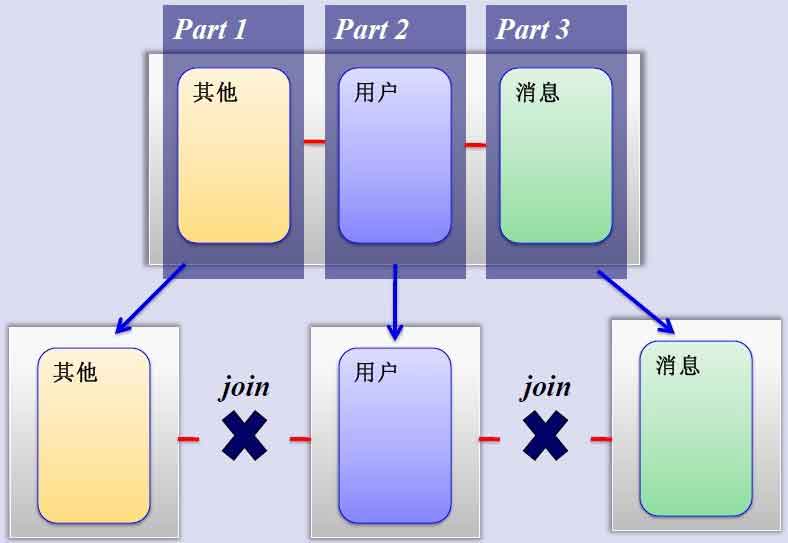
然而,儘管業務之間已經足夠獨立了,但是有些業務之間或多或少總會有點聯繫,如用戶,基本上都會和每個業務相關聯,況且這種分區方式,也不能解決單張表數據量暴漲的問題,因此爲何不試試水平sharding呢?
3、MySQL水平分片(Sharding)
這是一個非常好的思路,將用戶按一定規則(按id哈希)分組,並把該組用戶的數據存儲到一個數據庫分片中,即一個sharding,這樣隨着用戶數量的增加,只要簡單地配置一臺服務器即可,原理圖如下:
如何來確定某個用戶所在的shard呢,可以建一張用戶和shard對應的數據表,每次請求先從這張表找用戶的shard id,再從對應shard中查詢相關數據,如下圖所示: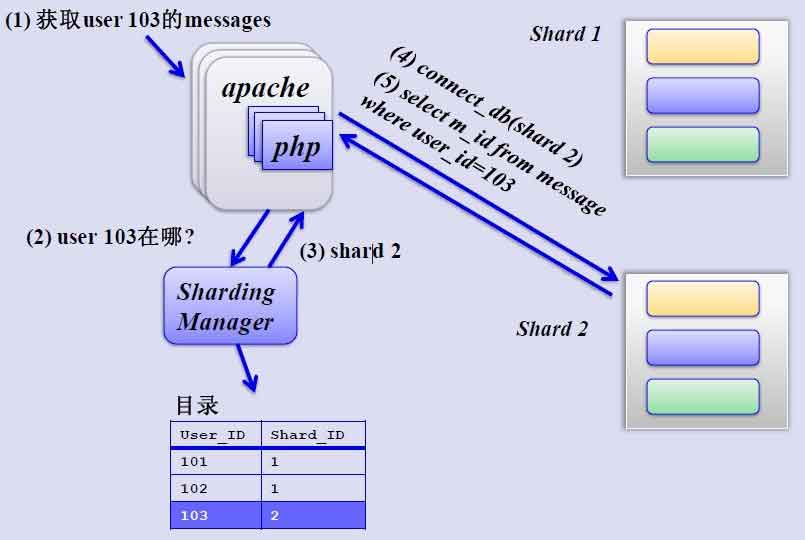
但是,優酷是如何解決跨shard的查詢呢,這個是個難點,據介紹優酷是儘量不跨shard查詢,實在不行通過多維分片索引、分佈式搜索引擎,下策是分佈式數據庫查詢(這個非常麻煩而且耗性能)
四、緩存策略
貌似大的系統都對“緩存”情有獨鍾,從http緩存到memcached內存數據緩存,但優酷表示沒有用內存緩存,理由如下:
避免內存拷貝,避免內存鎖
如接到老大哥通知要把某個視頻撤下來,如果在緩存裏是比較麻煩的
而且Squid 的 write() 用戶進程空間有消耗,Lighttpd 1.5 的 AIO(異步I/O) 讀取文件到用戶內存導致效率也比較低下。
但爲何我們訪問優酷會如此流暢,與土豆相比優酷的視頻加載速度略勝一籌?這個要歸功於優酷建立的比較完善的內容分發網絡(CDN),它通過多種方式保證分佈在全國各地的用戶進行就近訪問——用戶點擊視頻請求後,優酷網將根據用戶所處地區位置,將離用戶最近、服務狀況最好的視頻服務器地址傳送給用戶,從而保證用戶可以得到快速的視頻體驗。這就是CDN帶來的優勢,就近訪問,有關CDN的更多內容,請大家Google一下。
這是一個完整的PDF:http://www.blogkid.net/qconppt/youkuqiudanqconbeijing-090423080809-phpapp01.pdf
轉自:http://www.kaiyuanba.cn/html/1/131/147/7541.htm
YouTube網站架構
YouTube發展迅速,每天超過1億的視頻點擊量,但只有很少人在維護站點和確保伸縮性。這點和PlentyOfFish類似,少數人維護龐大系統。是什麼原因呢?放心絕對不是靠人品,也不是靠寂寞,下面就來看看YouTube的整體技術架構吧。
平臺
1、Apache
2、Python
3、Linux(SuSe)
4、MySQL
5、psyco,一個動態的Python到C的編譯器
6、lighttpd代替Apache做視頻查看
狀態
1、支持每天超過1億的視頻點擊量
2、成立於2005年2月
3、於2006年3月達到每天3千萬的視頻點擊量
4、於2006年7月達到每天1億的視頻點擊量
5、2個系統管理員,2個伸縮性軟件架構師
6、2個軟件開發工程師,2個網絡工程師,1個DBA
Web服務器
1,NetScaler用於負載均衡和靜態內容緩存
2,使用mod_fast_cgi運行Apache
3,使用一個Python應用服務器來處理請求的路由
4,應用服務器與多個數據庫和其他信息源交互來獲取數據和格式化html頁面
5,一般可以通過添加更多的機器來在Web層提高伸縮性
6,Python的Web層代碼通常不是性能瓶頸,大部分時間阻塞在RPC
7,Python允許快速而靈活的開發和部署
8,通常每個頁面服務少於100毫秒的時間
9,使用psyco(一個類似於JIT編譯器的動態的Python到C的編譯器)來優化內部循環
10,對於像加密等密集型CPU活動,使用C擴展
11,對於一些開銷昂貴的塊使用預先生成並緩存的html
12,數據庫裏使用行級緩存
13,緩存完整的Python對象
14,有些數據被計算出來併發送給各個程序,所以這些值緩存在本地內存中。這是個使用不當的策略。
應用服務器裏最快的緩存將預先計算的值發送給所有服務器也花不了多少時間。只需弄一個代理來監聽更改,預計算,然後發送。
視頻服務
1,花費包括帶寬,硬件和能源消耗
2,每個視頻由一個迷你集羣來host,每個視頻被超過一臺機器持有
3,使用一個集羣意味着:
-更多的硬盤來持有內容意味着更快的速度
-failover。如果一臺機器出故障了,另外的機器可以繼續服務
-在線備份
4,使用lighttpd作爲Web服務器來提供視頻服務:
-Apache開銷太大
-使用epoll來等待多個fds
-從單進程配置轉變爲多進程配置來處理更多的連接
5,大部分流行的內容移到CDN:
-CDN在多個地方備份內容,這樣內容離用戶更近的機會就會更高
-CDN機器經常內存不足,因爲內容太流行以致很少有內容進出內存的顛簸
6,不太流行的內容(每天1-20瀏覽次數)在許多colo站點使用YouTube服務器
-長尾效應。一個視頻可以有多個播放,但是許多視頻正在播放。隨機硬盤塊被訪問
-在這種情況下緩存不會很好,所以花錢在更多的緩存上可能沒太大意義。
-調節RAID控制並注意其他低級問題
-調節每臺機器上的內存,不要太多也不要太少
視頻服務關鍵點
1,保持簡單和廉價
2,保持簡單網絡路徑,在內容和用戶間不要有太多設備
3,使用常用硬件,昂貴的硬件很難找到幫助文檔
4,使用簡單而常見的工具,使用構建在Linux裏或之上的大部分工具
5,很好的處理隨機查找(SATA,tweaks)
縮略圖服務
1,做到高效令人驚奇的難
2,每個視頻大概4張縮略圖,所以縮略圖比視頻多很多
3,縮略圖僅僅host在幾個機器上
4,持有一些小東西所遇到的問題:
-OS級別的大量的硬盤查找和inode和頁面緩存問題
-單目錄文件限制,特別是Ext3,後來移到多分層的結構。內核2.6的最近改進可能讓 Ext3允許大目錄,但在一個文件系統裏存儲大量文件不是個好主意
-每秒大量的請求,因爲Web頁面可能在頁面上顯示60個縮略圖
-在這種高負載下Apache表現的非常糟糕
-在Apache前端使用squid,這種方式工作了一段時間,但是由於負載繼續增加而以失敗告終。它讓每秒300個請求變爲20個
-嘗試使用lighttpd但是由於使用單線程它陷於困境。遇到多進程的問題,因爲它們各自保持自己單獨的緩存
-如此多的圖片以致一臺新機器只能接管24小時
-重啓機器需要6-10小時來緩存
5,爲了解決所有這些問題YouTube開始使用Google的BigTable,一個分佈式數據存儲:
-避免小文件問題,因爲它將文件收集到一起
-快,錯誤容忍
-更低的延遲,因爲它使用分佈式多級緩存,該緩存與多個不同collocation站點工作
-更多信息參考Google Architecture,GoogleTalk Architecture和BigTable
數據庫
1,早期
-使用MySQL來存儲元數據,如用戶,tags和描述
-使用一整個10硬盤的RAID 10來存儲數據
-依賴於信用卡所以YouTube租用硬件
-YouTube經過一個常見的革命:單服務器,然後單master和多read slaves,然後數據庫分區,然後sharding方式
-痛苦與備份延遲。master數據庫是多線程的並且運行在一個大機器上所以它可以處理許多工作,slaves是單線程的並且通常運行在小一些的服務器上並且備份是異步的,所以slaves會遠遠落後於master
-更新引起緩存失效,硬盤的慢I/O導致慢備份
-使用備份架構需要花費大量的money來獲得增加的寫性能
-YouTube的一個解決方案是通過把數據分成兩個集羣來將傳輸分出優先次序:一個視頻查看池和一個一般的集羣
2,後期
-數據庫分區
-分成shards,不同的用戶指定到不同的shards
-擴散讀寫
-更好的緩存位置意味着更少的IO
-導致硬件減少30%
-備份延遲降低到0
-現在可以任意提升數據庫的伸縮性
數據中心策略
1,依賴於信用卡,所以最初只能使用受管主機提供商
2,受管主機提供商不能提供伸縮性,不能控制硬件或使用良好的網絡協議
3,YouTube改爲使用colocation arrangement。現在YouTube可以自定義所有東西並且協定自己的契約
4,使用5到6個數據中心加CDN
5,視頻來自任意的數據中心,不是最近的匹配或其他什麼。如果一個視頻足夠流行則移到CDN
6,依賴於視頻帶寬而不是真正的延遲。可以來自任何colo
7,圖片延遲很嚴重,特別是當一個頁面有60張圖片時
8,使用BigTable將圖片備份到不同的數據中心,代碼查看誰是最近的
學到的東西
1,Stall for time。創造性和風險性的技巧讓你在短期內解決問題而同時你會發現長期的解決方案
2,Proioritize。找出你的服務中核心的東西並對你的資源分出優先級別
3,Pick your battles。別怕將你的核心服務分出去。YouTube使用CDN來分佈它們最流行的內容。創建自己的網絡將花費太多時間和太多money
4,Keep it simple!簡單允許你更快的重新架構來回應問題
5,Shard。Sharding幫助隔離存儲,CPU,內存和IO,不僅僅是獲得更多的寫性能
6,Constant iteration on bottlenecks:
-軟件:DB,緩存
-OS:硬盤I/O
-硬件:內存,RAID
7,You succeed as a team。擁有一個跨越條律的瞭解整個系統並知道系統內部是什麼樣的團隊,如安裝打印機,安裝機器,安裝網絡等等的人。
With a good team all things are possible。
轉自:http://www.kaiyuanba.cn/html/1/131/147/7540.htm
Twitter網站架構
一、twitter網站基本情況概覽
截至2011年4月,twitter的註冊用戶約爲1.75億,並以每天300000的新用戶註冊數增長,但是其真正的活躍用戶遠遠小於這個數目,大部分註冊用戶都是沒有關注者或沒有關注別人的,這也是與facebook的6億活躍用戶不能相提並論的。
twitter每月有180萬獨立訪問用戶數,並且75%的流量來自twitter.com以外的網站。每天通過API有30億次請求,每天平均產生5500次tweet,37%活躍用戶爲手機用戶,約60%的tweet來自第三方的應用。
平臺:Ruby on Rails 、Erlang 、MySQL 、Mongrel 、Munin 、Nagios 、Google Analytics 、AWStats 、Memcached
下圖是twitter的整體架構設計圖: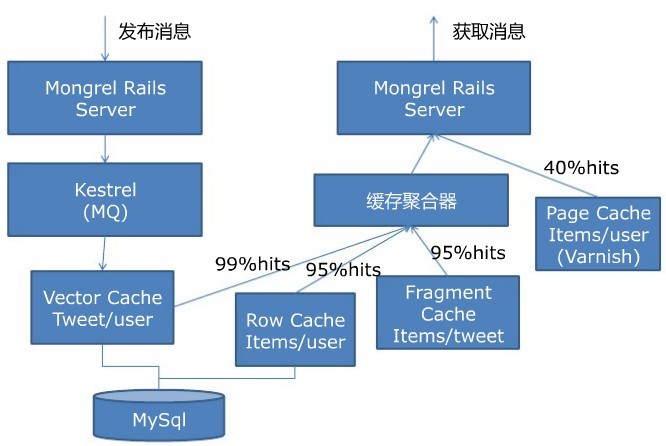
二、twitter的平臺
twitter平臺大致由twitter.com、手機以及第三方應用構成,如下圖所示: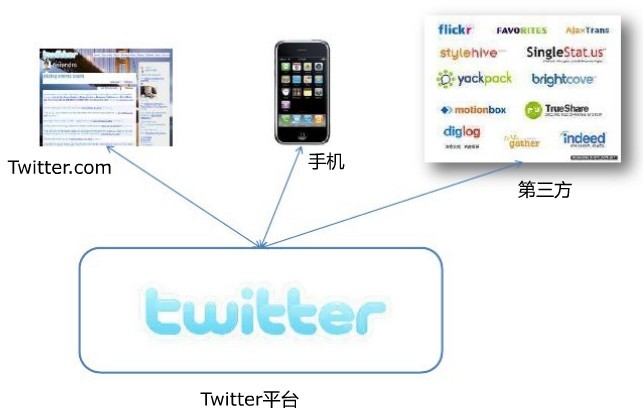
其中流量主要以手機和第三方爲主要來源。
Ruby on Rails:web應用程序的框架
Erlang:通用的面向併發的編程語言,開源項目地址:http://www.erlang.org/
AWStats:實時日誌分析系統:開源項目地址:http://awstats.sourceforge.net/
Memcached:分佈式內存緩存組建
Starling:Ruby開發的輕量級消息隊列
Varnish:高性能開源HTTP加速器
Kestrel:scala編寫的消息中間件,開源項目地址:http://github.com/robey/kestrel
Comet Server:Comet是一種ajax長連接技術,利用Comet可以實現服務器主動向web瀏覽器推送數據,從而避免客戶端的輪詢帶來的性能損失。
libmemcached:一個memcached客戶端
使用mysql數據庫服務器
Mongrel:Ruby的http服務器,專門應用於rails,開源項目地址:http://rubyforge.org/projects/mongrel/
Munin:服務端監控程序,項目地址:http://munin-monitoring.org/
Nagios:網絡監控系統,項目地址:http://www.nagios.org/
三、緩存
講着講着就又說到緩存了,確實,緩存在大型web項目中起到了舉足輕重的作用,畢竟數據越靠近CPU存取速度越快。下圖是twitter的緩存架構圖: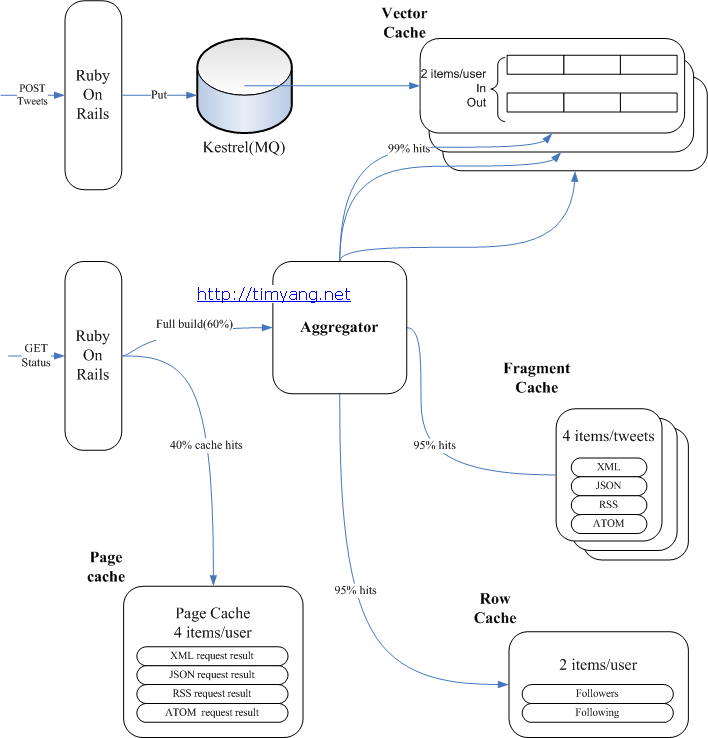
大量使用memcached作緩存
例如,如果獲得一個count非常慢,你可以將count在1毫秒內扔入memcached
獲取朋友的狀態是很複雜的,這有安全等其他問題,所以朋友的狀態更新後扔在緩存裏而不是做一個查詢。不會接觸到數據庫
ActiveRecord對象很大所以沒有被緩存。Twitter將critical的屬性存儲在一個哈希裏並且當訪問時遲加載
90%的請求爲API請求。所以在前端不做任何page和fragment緩存。頁面非常時間敏感所以效率不高,但Twitter緩存了API請求
在memcached緩存策略中,又有所改進,如下所述:
1、創建一個直寫式向量緩存Vector Cache,包含了一個tweet ID的數組,tweet ID是序列化的64位整數,命中率是99%
2、加入一個直寫式行緩存Row Cache,它包含了數據庫記錄:用戶和tweets。這一緩存有着95%的命中率。
3、引入了一個直讀式的碎片緩存Fragmeng Cache,它包含了通過API客戶端訪問到的sweets序列化版本,這些sweets可以被打包成json、xml或者Atom格式,同樣也有着95%的命中率。
4、爲頁面緩存創建一個單獨的緩存池Page Cache。該頁面緩存池使用了一個分代的鍵模式,而不是直接的實效。
四、消息隊列
大量使用消息。生產者生產消息並放入隊列,然後分發給消費者。Twitter主要的功能是作爲不同形式(SMS,Web,IM等等)之間的消息橋
使用DRb,這意味着分佈式Ruby。有一個庫允許你通過TCP/IP從遠程Ruby對象發送和接收消息,但是它有點脆弱
移到Rinda,它是使用tuplespace模型的一個分享隊列,但是隊列是持久的,當失敗時消息會丟失
嘗試了Erlang
移到Starling,用Ruby寫的一個分佈式隊列
分佈式隊列通過將它們寫入硬盤用來挽救系統崩潰。其他大型網站也使用這種簡單的方式
五、總結
1、數據庫一定要進行合理索引
2、要儘可能快的認知你的系統,這就要你能靈活地運用各種工具了
3、緩存,緩存,還是緩存,緩存一切可以緩存的,讓你的應用飛起來。
部分轉自:http://timyang.net/architecture/twitter-cache-architecture/
這裏還有一份根據英文翻譯的:http://hideto.iteye.com/blog/130044
JustinTV網站架構
Justin.TV每月有3000萬個獨立訪問量,在遊戲視頻上傳領域打敗了YouTube ,他們每天每分鐘新增30個小時的視頻,而YouTube只有23。
下面從Justin.TV的實時視頻系統使用到的平臺,他們的架構細節,從他們身上應該學到的東西等幾個方面逐一展開。
使用到的平臺
Twice —— 代理服務系統,主要用緩衝優化應用服務器負載
XFS —— 文件系統
HAProxy —— 用於TCP/HTTP負載平衡
LVS stack and Idirectord —— 高可靠性
Ruby on Rails —— 應用服務器系統
Nginx —— web服務器系統
PostgreSQL —— 數據庫,用於用戶和meta數據
MongoDB —— 數據庫,用於內部分析
MemcachedDB —— 數據庫,用於存放經常要修改的數據
Syslog-ng —— 日誌服務系統
RabitMQ —— job系統
Puppet —— 創建服務
Git —— 源代碼管理
Wowza —— Flash/H.264視頻服務器和許多Java寫的custome modules
Usher —— 播放視頻流的邏輯控制服務器
S3 —— 用於存儲小型鏡像
Justin.TV的一些統計數據
有覆蓋全美的4個數據中心
在任何時候都有2000多個同時流入的數據流
每天每分鐘新增30個小時的視頻
每月有3000萬個獨立訪問量(不計同一用戶多次訪問)
每秒實時的網絡流量在45G左右
實時視頻結構詳述

實時視頻結構
1.使用了P2P和CDN
一般人認爲,只需要不斷提高帶寬,把傳來的數據都放入內存,不斷的接收數據流就可以了,事實並非如此。實時視頻要求不能打斷,這就意味着你不可以超負荷的使用帶寬。YouTube只需要讓播放器緩衝一下,就可以用8G的帶寬解決10G通道的需求,但在實時視頻裏,你不能緩衝,如果在信道上的流量超過了它的傳輸能力,哪怕只是一瞬間,那麼所有的正在看的用戶在那一刻都會卡。如果你在它的極限能力上再加入了一點兒負載,所有人立刻就會進入緩衝狀態。
Justin.TV使用了點對點的結構來解決這個問題,當然他們也有更好的解決辦法,CDN(內容分發網絡)便是之一。當用戶的流量負載超過Justin.TV的負載能力時,Justin.TV便很巧妙的將超標流量引入到一個CDN中去,Usher控制着這個處理邏輯,一旦接到了超標用戶的負載請求,Usher便立刻將這些新用戶轉發到CDN中去。
2.100%可用時間和維護的矛盾
實時視頻構建的系統既要保證100%的可用時間,又要保證機器可以進行維護。與一般網站不同,一般網站維護時出現的問題只有少數人會發現、關注,而實時視頻網站不同,用戶很快就會發現維護時帶來的任何問題,並且互相傳播的非常快。這就使得沒有什麼問題可以隱瞞用戶,面對現在用戶的挑剔,你必須避免維護時出問題。對一個服務器維護時,你不能主動結束用戶的進程,必須等待所有在這個服務器上的用戶自己結束服務才能開始,而這個過程往往非常緩慢。
3.Usher與負載均衡
Justin.TV遇到的最大的麻煩是即時擁塞,當大量的用戶同時看同一個欄目的時候,便會突然產生突發網絡擁塞。他們開發了一個實時的服務器和數據中心調度系統,它就是Usher。
Justin.TV的系統在突發的高峯擁塞上做了很多。他們的網絡每秒可以處理大量的鏈入連接。用戶也參與了負載均衡,這也是Justin.TV需要用戶使用Justin.TV自己的播放器的原因之一。至於TCP,由於它的典型處理速度就是百kbps級的,所以也不用對TCP協議做什麼修改。
相對於他們的流量,他們的視頻服務器看來來有些少,原因是他們可以使用Usher把每個視頻服務器的性能發揮到最好,負載均衡可以確保流量從不會超過他們的負載極限。負載大部分是在內存中,因此這個系統可以讓網絡的速度發揮到極限。服務器他們是一次從Rackable(SGI服務器的一個系列)買了一整套,他們做的僅僅是從所有預置的裏面做了下挑選。
Usher是Justin.TV開發的一款定製化軟件,用來管理負載平衡,用戶認證和其他一些流播放的處理邏輯。Usher通過計算出每個流需要多少臺服務器提供支持,從而分配資源,保證系統處於最優狀態,這是他們的系統和別家不同之處。Usher通常會從下面幾個指標計算、衡量某個流媒體所需要的服務器:
每個數據中心的負載是多少
每個服務器的負載是多少
延遲優化的角度
當前這個流可用的服務器列表
用戶的國家(通過IP地址獲得)
用戶是否有可用的對等網(通過在路由數據庫中查詢IP地址獲得)
請求來自於哪個數據中心
Usher使用這些指標便可以在服務淨成本上來優化,把服務放在比較空閒的服務器上,或者把服務放在離用戶較近的服務器上,從而給用戶帶來更低的延遲和更好的表現。Usher有很多個可以選擇的模式從而達到很細的控制粒度。
Justin.TV系統的每個服務器都可以做邊緣服務器,直接爲用戶輸出視頻流,同時每個服務器也可以做源服務器,爲其他服務器傳遞視頻流。這個特性,使得視頻流的負載結構成了動態的,經常改變的一個過程。
4.服務器形成了加權樹
服務器之間由視頻流的拷貝而產生的聯繫和加權樹非常相似。數據流的數量經常被系統取樣、統計,如果觀看某個視頻流的用戶數量飛速上漲,系統便將其拷貝很多份到一些其他的服務器上去。這個過程反覆執行,最終就形成了一個樹狀的結構,最終會將網絡中所有的服務器都畫在裏面。Justin.TV的視頻流從源服務器出發,被拷貝到其他服務器,或者拷貝到用戶的整個過程中,都處於內存中,沒有硬盤路徑的概念。
5.RTMP和HTTP
Justin.TV儘可能的使用了Flash,因爲它使用RTMP協議,對每個視頻流,系統都有一個獨立的Session去維護它。由於使用這個協議,成本就相當高。由於ISP不支持下載流,因而無法使用多路廣播和P2P技術。Justin.TV確實想過用多路廣播在內部服務器之間拷貝數據流,然而由於他們的系統控制覆蓋整個網絡,而且內部有大量的很便宜的帶寬可以使用,這樣使用多路廣播的技術就並沒有產生多少效益。同時,由於他們的優化算法是將每個服務器上的流數都最小化,這就使得在很細的力度上做些事情會非常麻煩,甚至超過了他們能得到收益。
Justin.TV的Usher使用HTTP請求去控制某個服務器負載哪個視頻流,從而控制了服務的拓撲結構。Justin.TV在流數據上使用HTTP,但存在的一個問題是它沒有延遲和實時方面的性能。有些人說實時的定義就是5-30秒,然而,面對數千人做實時視頻的時候這顯然不行,因爲他們還需要實時的討論,交流,這意味着延遲不能高於1/4秒。
6.從AWS到自己的數據中心
起初Justin.TV使用AWS,後來遷移到Akamai(雲服務供應商),最後到了自己的數據中心。
離開AWS到Akamai的原因有:1,成本;2,網速不能滿足他們的需求。視頻直播對帶寬非常敏感,因此有一個快速的,可靠的,穩定的和低延遲的網絡非常關鍵。使用AWS時,你不能控制這些,它是一個共享的網絡,常常超負載,AWS的網速不會比300Mbps更快。他們對動態範圍改動和雲API很重視,然而在性能和成本問題上沒有做什麼。
3年前,Justin.TV計算他們每個用戶的成本,CDN是$0.135,AWS是0.0074,Datacenter是$0.001如今,他們的CDN成本降低了,但他們的數據中心的成本卻仍然一樣。
擁有多個數據中心的關鍵是爲了能夠接近所有的主要交換節點,他們選擇國內最好的位置從而使得他們爲國內最多的節點提供了入口,而且節約了成本,構建了這些數據中心後,他們就直接連入了這些其他的網絡,從而就省去了之前處理這些中轉流量的費用,還提高了性能,他們直接連入了他們所謂的"eyeball"網絡,這個網絡中包含了大量的cable/DSL用戶,和"content"網絡連接有些類似,Justin.TV的"eyeball"連接的流量主要來自終端用戶,在大多數情況下,這些都是免費的,不用任何花一分錢,要做的就是連進來就行。Justin.TV有一個主幹網,用於在不同的數據中心傳輸視頻流,因爲要到一個可用節點的選拔過程是去找願意和你做對等節點的過程,這通常是很困難的。
7.存儲
視頻流不是從磁盤形成,而是要存到磁盤上去。源服務器將一個傳入的視頻流在本地磁盤上覆制一份,之後便將這個文件上傳到長期存儲器上,視頻的每一秒都被錄下來並且存檔了。
存儲設備和YouTube類似,就是一個磁盤庫,使用XFS文件系統。這個結構用於記錄通過服務器傳播的廣播。默認的視頻流是保存7天,用戶可以手動的設置,甚至你可以保存到永遠(如果公司沒有倒閉的話)。
8.實時轉碼
增加了實時的轉碼功能,可以將任何一種流式數據轉化爲傳輸層數據或者是代碼,並且可以用新的格式將它重新編爲流媒體。有一個轉碼集羣,用來處理轉換工作轉,換的會話使用job系統進行管理。如果需要的轉碼服務超過了集羣的處理能力,那所有的服務器都可以用作轉碼服務器。
Web結構

Web 結構
1.Justin.TV前端使用Ruby on Rails。
2.用Twice做緩存
系統個每個頁面都使用了他們自己定製的Twice緩存系統,Twice扮演的角色是輕量級反向代理服務器和模板系統的合併角色。思路是對每一個用戶,緩存每一個頁面,然後將每個頁面的更新再併入其中。使用Twice以後,每個進程每秒可以處理150條請求,同時可以在後臺處理10-20個請求,這就擴展了7-10倍之前的服務器可以處理的網頁的數量。大部分動態網頁訪問都在5ms以內。Twice有一個插件結構,所以它可以支持應用程序的一個特點,例如添加地理信息。
不用觸及應用服務器,便能自動緩存像用戶名一樣的數據。
Twice是一個爲Justin.TV的需求和環境而定製化開發的。如果開發一個新的Rails應用,使用Varnish或許是一個更好的主意。
3.網絡流量由一個數據中心服務,其他的數據中心爲視頻服務。
4.Justin.TV 對所有的操作都做了監控.每一個點擊,查看頁面和每一個動作都被記錄下來,這樣就可以不斷提高服務。前端,網絡呼叫或者一個應用服務器的日誌消息都被轉換成系統日誌消息,通過syslog-ngto轉發。他們掃描所有的數據,將它裝入MongoDB,使用Mongo執行查詢。
5.Justin.TV的API來自網站的應用服務器,它使用相同緩衝引擎,通過擴展網站來擴展他們的API。
6.PostegreSQL是他們最主要的數據庫。結構是簡單的主從結構,由一個主機和多個從屬讀數據庫組成。
由於他們網站的類型,他們不需要許多寫數據庫,緩衝系統控制着這些讀數據庫。他們發現PostgreSQL並不擅長處理寫操作,因此Justin.TV就是用MemcachedDB去處理那些經常要寫的數據,例如計數器。
7.他們有一個聊天服務器集羣,專門用來爲聊天功能服務。如果用戶進入了一個頻道,用戶就會有5個不同的聊天服務器爲他服務,擴展聊天功能要比擴展視頻功能簡單的多,用戶可以被劃分到不同的房間,這些房間又由不同的服務器負載。他們也不會讓100,000個人同時在一起聊天。他們限制每個房間200人,這樣就可以在一個小組裏進行更有意義的交談。這同時對擴展也很有幫助,這真的是一個很聰明的策略。
8.AWS用於存儲文檔鏡像。他們沒有爲存儲許多小鏡像而開發專門的系統,他們使用了S3。它非常方便,而且很便宜,這就不用在他們上面花更多的時間了。他們的鏡像使用頻率很高,所有他們是可緩衝的,也沒有留下什麼後續問題。
網絡拓撲結構設計
網絡拓撲結構非常簡單,每個服務器機架頂都有一對1G的卡,每個機架都有多個10G的接口,接口連接到外部的核心路由器。他們使用Dell Power Edge交換機,這些交換機對L3(TCP/IP)並不是完全支持,但是比L2(ethernet)要好的多。每個交換機每天要傳輸20G的數據,而且很便宜。核心路由器是思科的6500的系列。Justin.TV想要將節點最小化,從而讓延遲降低,並且降低每個packet的處理時間。Usher管理着所有的接入控制和其他的邏輯,而不僅僅限於網絡硬件。
使用多個數據中心可以充分利用對等網的優勢,把流量轉移到離用戶最近的地方。和其他的網絡和節點的連接非常多。這樣就有多個可選的傳輸途徑,所以可以使用最好的那個路徑。如果他們遇到了網絡的擁塞,就可以選擇一條別的路。他們可以通過IP地址和時間,找到對應的ISP。
開發和部署
他們使用Puppet服務器主機,有20中不同種類的服務器。從數據庫中出來的任何東西都要經過緩存器,使用Puppet他們可以把這個緩存器變成他們想要的任何東西。
他們有兩個軟件隊伍。一個是產品隊伍,另一個是硬件基礎設施隊伍。他們的隊伍非常小,大概每個隊伍只有7-8個人,每個隊伍都有一個產品經理。他們僱傭一般的技術員,但卻僱傭了網絡結構和數據庫相關的專家。
他們使用了基於網絡的開發系統,所以每個新的改動都會在幾分鐘內完成。QA必須在變成產品之前完成,在這裏通常需要5-10分鐘。
Justin.TV使用Git管理源代碼。Justin.TV喜歡Git的這個功能,你可以寫一個程序副本,20-30行,然後它可以融合到其他人手裏正在修改的副本。這個工作是獨立的,模塊化的。在你不得不撤銷你提交的副本時,你可以很容易就修改或者撤銷你的代碼。每過幾天每個人都會試着將自己的代碼副本融入到主代碼中去消除衝突。他們每天對軟件做5-15個修改,範圍從1行代碼中的bug到大範圍的測試都有。
數據庫模式通過手動更新完成。將他們複製的數據庫副本遷移到一起就會形成一個最新的動態記錄的版本。在把改動最終應用到產品之前會在許多不同的環境下對其進行測試。
Puppet管理配置文件。每個小的改動基本上就是一個實驗,他們會追蹤每個對核心文件的改動的影響和之前的版本。這些測試很重要,因爲通過它他們可以找出哪些改動是真正提高他們關心的指標。
Justin.TV的未來
他們的目標是增加一個數量級。首先要切分他們的視頻元數據系統,由於流數據和服務器的大幅增長,他們的元數據負載也指數級的爆發增長,因此,他們需要將其大範圍進行切分,對於網絡數據庫,將使用Cassandra對其進行拆分。其次,爲了災後恢復,要對核心數據中心進行備份。
學到的東西
自己開發還是購買。他們在這個問題上已經做了很多錯誤的決策。例如,他們起初應該買一臺視頻服務器而不是自己去做了一臺。軟件工程師喜歡將軟件做的個性化,然後使用開源社區維護的東西卻有很多益處。因此他們提出了一個更好的流程去做這個決定:1.這個項目是活動?還是維護?還是修補漏洞?2.有其他的人要用它麼?你能向別人請教下該如何定義它?3.擴展性的問題,他們必須去做改變。4.如果我們自己開發,我們可以做到更快,更好,還是我們可以獲得更多我們需要的特性呢? 就像使用Usher,他們考慮他們可否創造一個新的外部特性,並且和另外一個系統交互。把Usher做爲視頻擴展性的核心針對相對笨拙的視頻服務器來說是一個非常好的決策的例子。
關注自己做的事情,不要在意別人怎麼幹。他們的目標是有用最好的系統,最多的服務時間和最完美的擴展性。他們用了3年去開發能管理百萬個廣播併發的技術。
不要外包。你學到的核心價值在於經驗,而不是代碼或者硬件。
把一切都當做實驗來做。對所有的東西都進行測量,局部測試,追蹤,測量。這很划算。從一開始就做,使用優秀的測量工具。例如,他們在複製的URL上附加一個標籤,然後就可以知道你是否分享了這個鏈接。他們從不測量的走到了如今高度測量。通過重寫廣播進程,使得他們的會話數量增長了700%。他們想要網站運行更快,響應更快,網頁裝載更快,視頻服務更好,系統擠出的每一毫秒的延遲都帶來了更多的廣播者。他們有40個實驗,如果他們希望讓一個用戶變成一個廣播者,對每個實驗他們都想要看一下廣播後的留存率,廣播的可用性,會話率,然後對每個改動都做一個明智的決策。
最重要的一件事是理解你的網站如何共享服務,怎麼優化它。他們通過減少共享的鏈接在菜單中的深度,成功的提高了500%的分享率。
使用公共的構建模塊和基礎設施意味着系統將立刻識別什麼是重要的,然後執行。具有網絡能力很重要,這也是他們應該從開始就關注的地方。
讓系統忙起來。使用系統的所有能力,爲什麼要把錢放在桌子上呢?構建可以通過應答對系統進行合理的分配的系統。
對不重要的事情不要浪費時間。如果它非常方便並且不用花費多少,就沒有必要在它上面花費時間。使用S3去存儲鏡像就是一個很典型的例子。
試着爲用戶想做的事情提供支持,而不是做你認爲用戶該這樣使用的東西。Justin.TV的終極目標似乎是把所有人都變成一個廣播點。在用戶實驗時,通過儘可能的走出用戶的使用方式,他們試着讓這個過程變得儘可能簡單。在這過程中,他們發現,遊戲是一個巨大的作用力。用戶喜歡將Xbox截圖出來,並且與大家分享,討論它,很有可能有些東西是你沒想過要放在商務計劃裏的。
爲負載峯值做設計。如果你只爲了靜態的狀態做了設計,之後你的網站將會在峯值來臨時垮掉。在實時視頻上,這通常是一個大事,如果你陷入了這個麻煩,很快人們就開始傳播對你不利的話。爲峯值負載進行設計需要使用一個所有層次的技術。
讓網絡結構保持簡單。使用多數據中心,使用點對點網絡連接結構。
不要擔心將東西劃分到更多的可擴展塊中去。例如,與其使用一個100,000人的頻道,不如將他們劃分到更多的社會和可擴展的頻道去。
實時系統不能隱藏來自用戶的任何問題,這就是的說服用戶你的網站很可靠變的很困難。由於他們和實時系統之間的聯繫是固定的,這會使的系統的每個問題和故障都讓大家知道,你藏不住。每個人都會發現,並且每個人都會通過交流傳播發生了什麼,很快,用戶就會有一個你的網站有很多問題的感覺。在這種情況下,和你的用戶交流就變得很重要,從一開始就構建一個可信賴的,高質量的,可擴展的,高性能的系統,設計一個用戶用起來儘可能簡單和舒服的系統。