




閱讀對象
只要你想讀,你就讀唄!最好點個贊再走。。。:-)
本文儘量通過例子和直觀描述,來說明人工智能中機器學習和數據挖據的主要概念,分類,和使用方法,並通過例子描述如何使用它來促進公司業務發展。雖然標題偏技術,但內容涵蓋面較廣,涉及業務,產品,技術等多方面。主要目的是說清楚公司如何使用數據挖據爲業務提速,所以推薦的閱讀對象,是公司中高級運營管理人員,創始人。但並不一定合適人工智能,數據挖據的技術專家,因爲它基本不涉及人工智能和數據挖據的底層技術,也不涉及深層次的數學原理和算法研究。
前言
近年來,人工智能,大數據是一個非常熱門的詞彙。與一些更加前沿的科技例如量子計算,神經網絡,虛擬現實,區塊鏈等等不同,這一類技術裏面,已經有一些分類,實實在在地被商用並且產生了可觀的效益。簡單地說,本文所描述的數據挖據相關內容,事實上就是人工智能和大數據的一種結合。
哪兒有數據挖掘哪兒就有“啤酒與尿布”, “沃爾瑪啤酒和尿布的故事”這個經典的案例是從事這行研究的人都知道的一個故事,說的是沃爾瑪超市(Walmart)會在週末時把啤酒移到尿布貨架的未端,這是因爲沃爾瑪的數據挖掘專家告訴老闆,他們的研究結果顯示男士通常會在週末購買尿布,而他們同時也喜歡在週末喝啤酒,如果放在一起那肯定會提升銷售,老闆照做了,結果啤酒銷售果然增加了40%以上。。。很想知道這個經典案例是真實的還是爲了宣傳數據挖掘而製造的,也不知道這個案例是沃爾瑪自己說的還是別人說的,沃爾瑪有明確的官方聲明麼。。。?
反正聽着很提神。
現在世界上幾乎所有的大型公司都在使用數據挖掘,並且目前尚未使用數據挖掘的公司已經或在不久的將來,就會發現自己處於極大的劣勢。成爲Low逼是肯定的,直接失去業務機會和競爭力,也是肯定的。
那麼,如何能讓我們的公司跟上數據挖掘的大潮呢?
本文彙總了四個最有用和常用的數據挖據方法,同時使用了一個叫WEKA(Waikato Environment for Knowledge Analysis)的人工智能+數據挖據研究工具(這個工具是JAVA語言開發的),來做一些實實在在的開發和演示,來研究並確定一下這個沃爾瑪神話的可信性和可行性有多高。
讓我們現在就開始。
概念和準備工作
什麼是數據挖掘?
數據挖掘,就其核心而言,是指將大量數據轉變爲有實際意義的模型和規則。並且,它還可以分爲兩種類型:直接的和間接的。
在 直接的 數據挖掘中,我們會嘗試預測一個特定的數據點 — 比如,以給定的一個房子的售價來預測鄰近地區內的其他房子的售價,或者,用以往的車輛銷售成交數據,來預測一輛車的成交價格或者由此制定最合理的定價。
在 間接的 數據挖掘中,公司會嘗試收集和創建數據羣組或找到現有數據內的模式 — 比如,創建 “中產階級白領女性人羣”,或者收集一批“最近5年買過某某車的用戶”,然後去分析和預測他們的行爲。
現代的數據挖掘開始於 20 世紀 90 年代,那時候計算的強大以及計算和存儲的成本均到達了一種很高的程度,各公司開始可以自己進行計算和存儲,而無需再借助外界的計算幫助。
此外,術語數據挖掘是全方位的,可指代諸多查看和轉換數據的技術和過程。本文只觸及能用數據挖掘實現的常用功能和概念。當然,數據挖掘的專家往往是數據統計方面的博士,並在此領域有 N 年(10年以上)的研究經驗。
這會給大家留下一種印象,即只有大公司才能負擔得起數據挖掘。
多年來,我腦海中經常浮現《功夫熊貓》中烏龜大師的一句名言: Your mind is like this water, my friend , when it is agitated ,it becomes difficult to see ,but if you allow it to settle , the answer becomes clear. (你的思想就如同水,我的朋友,當水波搖曳時,很難看清,不過當它平靜下來,答案就清澈見底了。)
思想如此,很多時候,科技也是如此。所以,事實上數據挖據在使用上並非如此難,當然它不像打印一張電子數據統計表那麼簡單,但也不像有些人想的那樣難,難到靠自己或者自己公司團隊根本無法實現。
其實很多時候,在一個從事業務型的公司,我們只需要所謂的技術專家的 10% 的專業知識就能創建具有 90% 效力的產品和服務。而無須去補上剩下的 10% 的服務。因爲那10%基本是沒有用戶關心的,而爲了彌補那10%去創建一個完美的技術模型將需要 90% 甚至更多的額外的時間和資源投入,或者長達 10年,20 年,這,還是留給一些專門從事某方面研究的科技研究公司或者高校去完成吧。
“我們不生產水,我們只是水的搬運工”
數據挖掘的最終目標,是要創建一個模型,這個模型可改進解讀現有數據並正確預測將來的數據。在閱讀了本文章後 ,您應該能夠自己根據自己的數據集正確決定要使用的技術,然後採取必要的步驟對它進行優化。您將能夠爲您自己的數據創建一個足夠好的模型。
在本文中,我們將研究四種數據挖據技術和如何在自己的JAVA系統中,導入weka.jar做數據挖掘開發:
**1、 “迴歸模型”及其WEKA實現
2、 “分類模型”及其WEKA實現
3、 “羣集/聚類模型”及其WEKA實現
4、 “最近鄰模型”及其WEKA實現
5、 將weka.jar 使用到自己的程序
我們將分別舉例子來說明這四種技術對業務的幫助。
什麼是WEKA及WEKA的安裝
有一種軟件可以實現那些價格不菲的數據挖據商業軟件所能實現的全部功能 — 這個軟件就是 WEKA(請上百度搜索相關說明)。WEKA 誕生於 University of Waikato(新西蘭)並在 1997 年首次以其現代的格式實現。它使用了 GNU General Public License (GPL)。該軟件以 Java™ 語言編寫幷包含了一個圖形界面來與數據文件交互並生成可視結果(比如表和曲線)。
WEKA除了作爲一個獨立PC應用外,它居然還有一個通用 API weka.jar,所以我們可以像嵌入其他的庫一樣將 WEKA 嵌入到自己的應用程序以完成諸如服務器端自動數據挖掘這樣的任務。。。哇哇哇,這應該就是程序員最想要的,世界上總有那麼一批好人提供免費的餡餅!!!
接下來我們來安裝 WEKA。因爲它基於 Java,所以如果您在計算機上沒有安裝Java環境,那麼請下載一個包含 JRE 的 WEKA 版本,如果有了,就下載不包含JRE的包,它會小的多,不過要注意JDK版本的兼容。
看一看,下面是我下載的安裝包(需要安裝包的自行搜索下載,別問我要哦):
我下載的時間是2018年2月份,到那時爲止WEKA最新版本 weka-3-8-2。
本來機器上有JKD1.7,但是安裝WEKA後報錯,版本不對,需要JDK1.8,於是下載了1.8。
雙擊安裝,然後啓動,看到如下KEKA開始屏幕界面。

在啓動 WEKA 時,會彈出圖形界面選擇器,讓您選擇使用 WEKA 和數據的四種方式。對於本文章系列中的例子,我們只選擇了 Explorer 選項。對於我們要在這些系列文章中所需實現的功能,這已經足夠。點 Explorer ,將看到如下界面:
在安裝和啓動 WEKA 後,我們就可以來研究我們的人工智能 之 機器學習 之 數據挖據了。
我們來看看我們的第一個數據挖掘:迴歸模型。
模型一。迴歸模型
迴歸模型的使用場景,一般是用來確定有某一些因素確定的某一個商品的價值,比如房價的估計。
迴歸是比較簡單易用的一個概念。此模型數學上是一種輸入和輸出之間的線性關係,可以簡單到只有一個輸入變量和一個輸出變量。當然,也可以遠比此複雜,可以包括很多輸入變量。實際上,所有迴歸模型均符合同一個通用模式。多個“自變量”綜合在一起可以生成一個結果 — 一個“因變量”。在分析大量歷史數據後生成一個迴歸模型,然後用這個迴歸模型根據給定的這些自變量的值預測一個未知的因變量的結果。
其實我們每個人都可能使用過或看到過迴歸模型,甚至曾在頭腦裏創建過一個迴歸模型。只是我們自己不這麼認爲而已。
在如今的社會,人們能立即想到的一個例子大概是給房子定價了。房子的價格(因變量)是很多自變量 — 房子的面積、佔地的大小、位置、裝修狀況等等組合的結果。所以,不管是購買過一個房子還是銷售過一個房子,我們大腦中都會創建一個迴歸模型來爲房子定價。這個模型建立在鄰近地區內的其他有可比性的房子的售價的基礎上(模型),然後再把新的房子的值放入此模型來產生一個預期價格。
一個長期從事某個地區×××中介工作的人,會自然而然在大腦中形成一個正確的模型,告知他/她相關的參數,也就是告訴他/她你房子的基本情況,他/她就可以立即告訴你合理的估價。聯繫到人工智能方面,這其實是一個典型機器學習(監督學習)的過程加上數據挖據的過程。
讓我們繼續以這個房屋定價的迴歸模型爲例,創建一些真實的數據。假定最近我有一個房子想要出售,我試圖找到我自己房子的合理價格。我不是一個長期從事房屋交易的中介,同時因爲一些合理的原因,也並不是很相信中介給我提供的價格,那將如何是好?在這裏,事情將變得比較很容易,你將很容易解決這個問題。
首先,你需要通過一些途徑,詢問一下你周邊鄰居或者同一個地段的房子,包括他們的價格和一些影響價格的主要因素,因爲是同一個地段,所以影響價格的因素就相對簡單了很多。
這裏先羅列彙總一下影響房價的幾個主要因素:
1、小區位置,小區所在的地理位置
2、樓座位置,某棟樓所在的位置
3、交通情況,交通是否便利
4、小區基礎設施,物業和小區基礎設施是否好
5、周邊設施,周邊生活學習是否方便
6、環境綠化,綠化程度
7、房齡,房屋年齡
8、面積,房子多大
9、房屋朝向,是否朝南
10、房座位置,位於一棟樓兩邊還是中間,位於兩邊的認爲採光較好
11、裝修情況,裝修的情況
因爲在本例中,我是想通過和鄰近房子比較,來預估自己的房子價格,所以在上面11個因素中,其實只需要關心2、8、9、10、11三個就可以了,因爲其它方面都可以認爲是一樣的。
然後我們將因素和值表示一下:
面積:具體面積數字,平方米
樓座位置:分爲靠馬路1和不靠馬路2
朝向:朝南1,不朝南2
房座位置:兩邊1,中間2
裝修:1豪華,2精裝,3普通,4毛坯
接下來,必須花一些時間,瞭解了一下週邊房屋售價情況,假定獲得的數據如下。
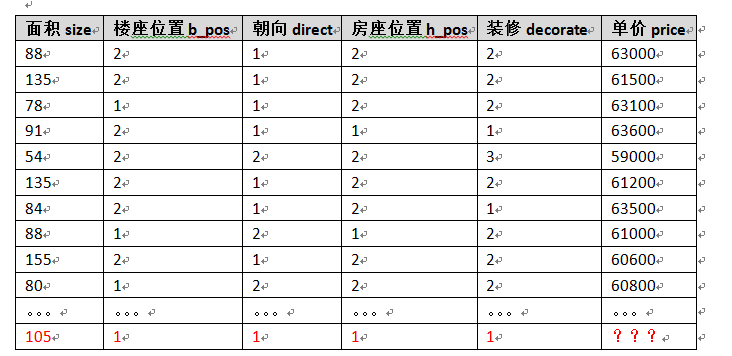
最後那個,紅色的,假定就是我的房子,我想知道單價應該是多少呢?
爲 WEKA 構建數據集
爲了將數據加載到 WEKA,我們必須將數據放入一個我們能夠理解的格式。WEKA 建議的加載數據的格式是 Attribute-Relation File Format (ARFF),您可以在其中定義所加載數據的類型,然後再提供數據本身。在這個文件內,我們定義了每列以及每列所含內容。對於迴歸模型,只能有 NUMERIC 或 DATE 列。最後,以逗號分割的格式提供每行數據。我們爲 WEKA 使用的 ARFF 文件如下所示。請注意在數據行內,並未包含我的房子。因爲我們在創建模型,我房子的價格還不知道,所以我當然不能輸入我的房子。
WEKA 文件格式
@RELATION house@ATTRIBUTE size NUMERIC
@ATTRIBUTE b_pos NUMERIC
@ATTRIBUTE direct NUMERIC
@ATTRIBUTE h_pos NUMERIC
@ATTRIBUTE decorate NUMERIC
@ATTRIBUTE price NUMERIC
@DATA
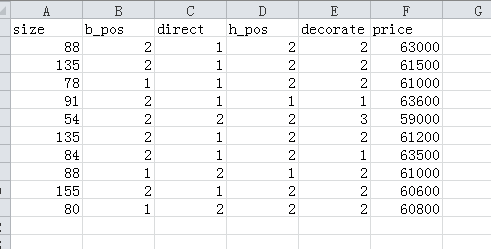
88,2,1,2,2,63000
135,2,1,2,2,61500
78,1,1,2,2,63100
91,2,1,1,1,63600
54,2,2,2,3,59000
135,2,1,2,2,61200
84,2,1,2,1,63500
88,1,2,1,2,61000
155,2,1,2,2,60600
80,1,2,2,2,60800
如何將你的統計轉換成WEKA認識的arff格式。
你的統計文件最有可能的是txt,excel格式文件。
如果是如下格式的txt:
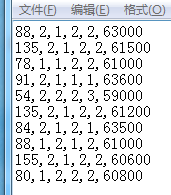
首先導入excel,變成如下格式:
注意第一行,是你添加的屬性行,然後保存爲csv 格式。
接下來就容易了,用WEKA explorer ,打開 csv文件,然後保存爲 arff格式即可。我這裏保存爲house.arff

將數據載入 WEKA
數據創建完成後,就可以開始創建我們的迴歸模型了。啓動 WEKA,然後選擇 Explorer。將會出現 Explorer 屏幕,其中 Preprocess 選項卡被選中。選擇 Open File 按鈕並選擇在上一節中創建的 house.arff 文件。在選擇了文件後,WEKA Explorer 應該類似於下圖所示的這個屏幕快照。
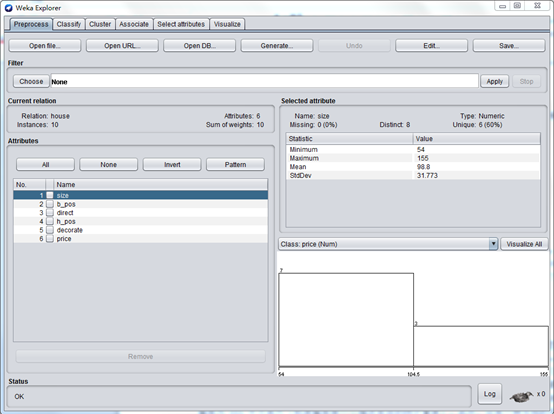
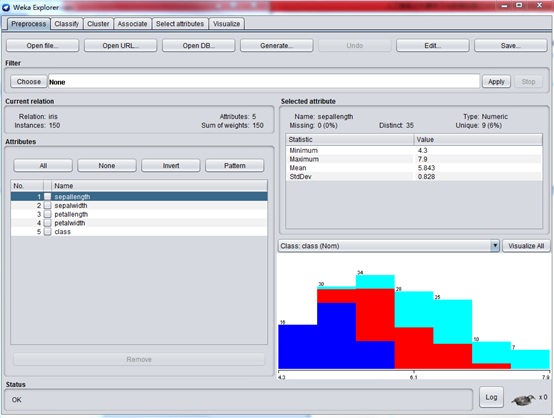
在這個視圖中,WEKA 允許您查閱正在處理的數據。在 Explorer 窗口的左邊,給出了您數據的所有列(Attributes)以及所提供的數據行的數量(Instances)。若選擇一列,Explorer 窗口的右側就會顯示數據集內該列數據的信息。比如,通過選擇左側的 size 列(它應該默認選中),屏幕右側就會變成顯示有關該列的統計信息。它顯示了數據集內此列的最大值爲 155 平方米,最小值爲 54 平方米。平均大小爲 98.8 平方米,標準偏差爲 31.773平方米(標準偏差是一個描述差異的統計量度)。此外,還有一種可視的手段來查看數據,單擊 Visualize All 按鈕即可。由於在這個數據集內的行數有限,因此可視化的功能顯得沒有更多數據點(比如,有數百個)時那麼功能強大。
好了,對數據的介紹已經夠多了。讓我們立即創建一個模型來獲得我房子的價格。
用 WEKA 創建一個迴歸模型
爲了創建這個模型,單擊 Classify 選項卡。第一個步驟是選擇我們想要創建的這個模型,以便 WEKA 知道該如何處理數據以及如何創建一個適當的模型:
單擊 Choose 按鈕,然後擴展 functions 分支。
選擇 LinearRegression 。
這會告訴 WEKA 我們想要構建一個迴歸模型。除此之外,還有很多其他的選擇,這說明可以創建的的模型有很多。我們之所以選擇LinearRegression而不是SimpleLinearRegression,是因爲目前我們這個模型有五個變量,需要輸出一個因變量。迴歸分析中,只包括一個自變量和一個因變量,且二者的關係可用一條直線近似表示,這種迴歸分析稱爲一元線性迴歸分析。如果迴歸分析中包括兩個或兩個以上的自變量,且因變量和自變量之間是線性關係,則稱爲多元線性分析。很明顯我們這個是多元的。
選擇了正確的模型後,WEKA Explorer 應該類似於下圖。
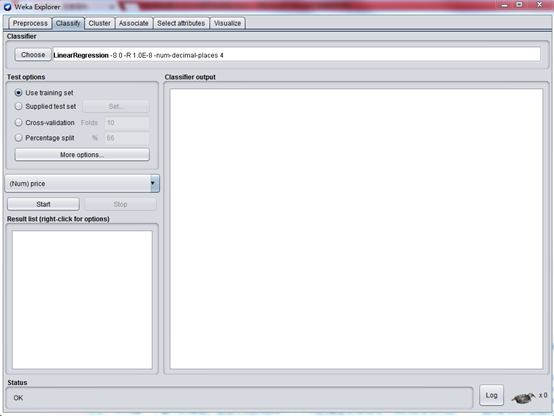
現在,選擇了想要的模型後,我們必須告訴 WEKA 它創建這個模型應該使用的數據在哪裏。雖然很顯然我們想要使用在 ARFF 文件內提供的那些數據,但實際上有不同的選項可供選擇,有些甚至遠比我們將要使用的選項高級。其他的三個選擇是:Supplied test set 允許提供一個不同的數據集來構建模型; Cross-validation 讓 WEKA 基於所提供的數據的子集構建一個模型,然後求出它們的平均值來創建最終的模型;Percentage split WEKA 取所提供數據的百分之一來構建一個最終的模型。這些不同的選擇對於不同的模型非常有用,我們在本系列後續文章中會看到這一點。對於迴歸,我們可以簡單地選擇 Use training set。這會告訴 WEKA 爲了構建我們想要的模型,可以使用我們在 ARFF 文件中提供的那些數據。
創建模型的最後一個步驟是選擇因變量(即我們想要預測的列)。在本例中指的就是房屋的銷售單價,因爲那正是我們想要的。在這些測試選項的正下方,有一個組合框,可用它來選擇這個因變量。列 price 應該默認選中。
我們準備好創建模型後,單擊 Start。下圖顯示了輸出結果。
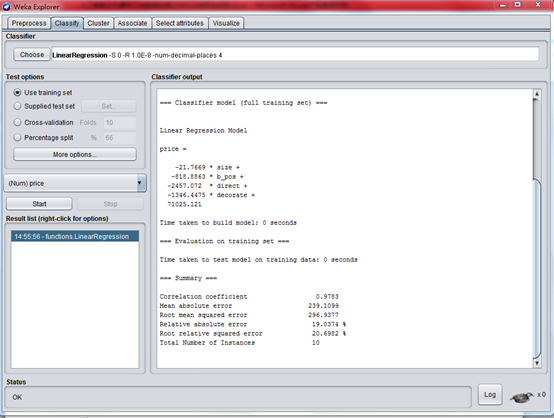
放大,直接看模型公式:

讓我們來算算我那個房子的單價:
price =
-21.7669 105 +
-818.8863 1 +
-2457.072 1 +
-1346.4475 1 +
71025.121 = 64094 元
數據挖掘絕不是僅僅是爲了輸出一個數值:它關乎的是識別模式和規則。它不是嚴格用來生成一個絕對的數值,而是要創建一個模型來讓您探測模式、預測輸出並根據這些數據得出結論。讓我們更進一步來解讀一下我們的模型除了房屋價格之外告訴我們的模式和結論:
• 房坐位置無關緊要 — WEKA 將只使用在統計上對模型的正確性有貢獻的那些列。它將會拋棄並忽視對創建好的模型沒有任何幫助的那些列。所以這個迴歸模型告訴我們,房子處於一棟樓的兩邊還是中間,似乎並不會影響房子的價格。就我個人的經驗是,兩邊的房子比較明亮通透,但也面臨着牆壁更容易漏水的危險。
• 裝修的影響是非常大的 — 看看裝修數字對房價的影響就知道了,隨着數字增大,也就是裝修質量變差,房價是嘩嘩往下降啊。爲什麼我的房子那麼貴,豪裝啊!有道理!!
• 較大的房子單價反而低 — WEKA 告訴我們房子越大,銷售單價越低?這可以從 size 變量前面負的係數看出來。此模型告訴我們房子每多出一平方米都會使房單價減少 21元,雖然影響的並不明顯,但的確如此。這個怎麼說呢,正確的應該說是在一定範圍之外,比如超過某個面積後,的確是單價會隨着房屋面積變大而變小,按照經驗這個情況是存在的,因爲總價高麼。
迴歸模型結束語
本章探討了第一個數據挖掘模型:迴歸模型(特指線性迴歸多變量模型),另外還展示瞭如何在 WEKA 中使用它。這個迴歸模型很容易使用,並且可以用於很多數據集。您會發現這個模型是我們日常工作生活中最有用的一個。
然而,數據挖掘不僅侷限於簡單的迴歸,在不同的數據集及不同的輸出要求的情況下,您會發現其他的模型也許是更好的解決方案。接下來我們看看其它模型。
模型二。分類模型
分類模型的使用場景,是根據已有的屬性和分類結果的歷史記錄,生成一個模型,這個模型能對新的已知屬性但不知道分類的用戶,物品或商品推算出其分類結果。所以我們這裏的分類模型生成,是屬於監督學習。
說到分類,就會說到決策樹。決策樹是一種十分常用的和直觀的方法分類方法。它是一種監督學習,所謂監督學習就是給定一堆樣本,每個樣本都有一組屬性和一個類別,這些類別是事先確定的,那麼通過學習得到一個分類器,這個分類器能夠對新出現的對象給出正確的分類。
決策樹的思維,其實在我們日常工作和思考中,都會存在。。。比如一個有經驗的推銷人員,看到一個用戶,通過一眼觀察和簡單聊天,就能推算出這個用戶有沒有可能轉換成自己的客戶。在比如,當有人給適婚男女介紹一個朋友的時候,他們的腦子裏面都會有類似如下的決策樹來考慮要不要見見:

當簡單的現象上升到高科技層面的時候,決策樹就會有很多種算法:CHAID,CART,C4.5,C5.0。不過決策樹的核心理論都其實差不多,本文不去研究每個算法的實現而是通過例子,去使用和比較這些算法。
首先舉個最簡的的決策樹例子:
假定有如下11個人的完整資料如下,現在需要判斷第12個人,是東方人還是西方人?
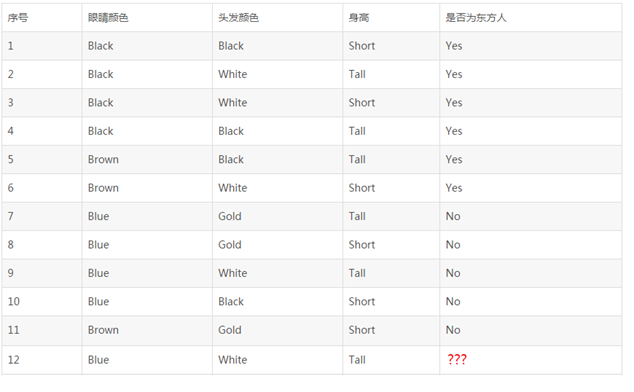
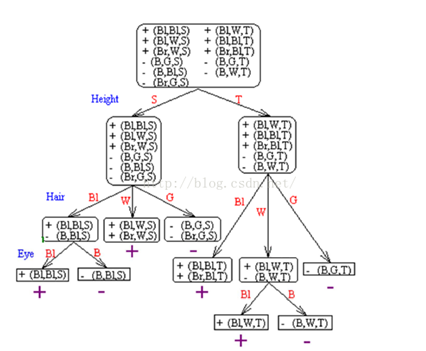
首先,我們根據前面11個人的資料,生成一個決策樹,如下:
或者入下:
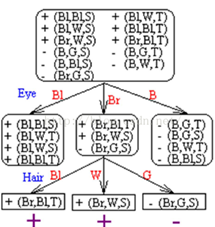
然後把第12個人的資料,按照他的屬性代入這兩個棵決策樹中間的任何一棵,結果就會發現,這個人是西方人。
再次說明,我們不討論這棵樹的實現方法,現實中的決策也不會那麼簡單,用於生成決策樹的歷史記錄也不會那麼少。如何根據已經有的資料,生成最合理的決策樹,是算法需要考慮的問題,WEKA就是專門做這個事情的,等會我們再舉例說明。
我們這裏需要了解的是,各種分類算法,哪種分類算法生成的決策樹,最符合我們的需要,還有就是,生成的決策樹模型,其分類正確率是多少,是否符合公司的業務需要和場景。
下面我們用工具WEKA,嘗試建立一個較爲複雜的決策樹模型。
打開WEKA,載入其安裝目錄下面 data目錄下的 iris.arff
這是一個經典的鳶尾花分類決策樹例子。
鳶尾花有三種類型:setosa,versicolor,virginica這三種類型基本上靠其花瓣和花萼的四種外形來決定。下面是 arff 文件的例子截圖:
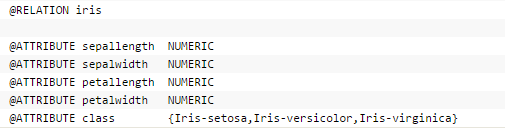

載入 iris.arff
選擇Classify ,選擇tree - J48分類算法
在 Test options 下面,選擇 Cross-validation ,Folds填寫10,這個表示生成模型後交叉驗證模型。WEKA會將數據分成10份,一份用於生成決策樹模型,一份用來驗證正確度。
在生成決策樹模型中,一般會需要選擇Cross-validation ,通過對未知數據的預測結果驗證,來驗證模型的通用性。
一切設定好後,按“Start”。。。界面如下:
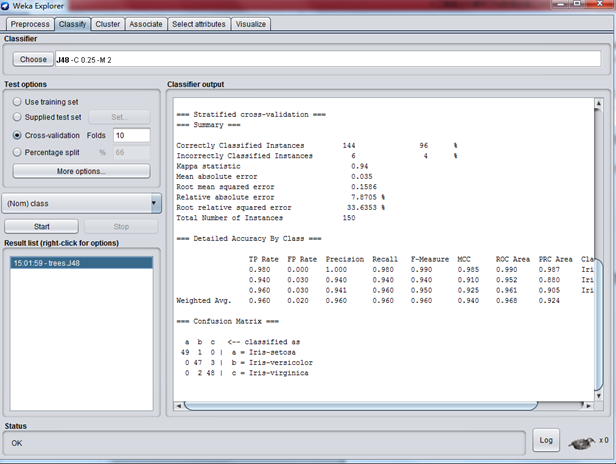
最需要了解的是這一條信息:
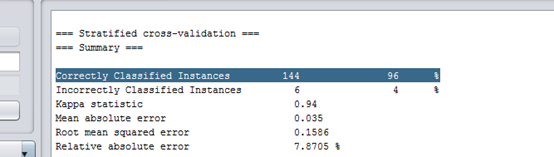
這表示這個模型分類正確率是 96% ,應該是比較高的了。
我們再來直觀地看看WEKA生成的樹吧:
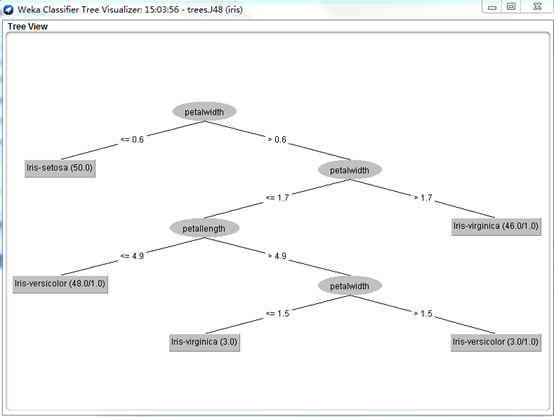
分類模型結束語
決策樹或者分類樹就是要創建一個具有分支、節點和枝葉的樹,能夠讓我們拿一個未知的數據點,將此數據點的屬性應用到這個樹並順着這個樹下移,直到到達一個葉子並且數據點的未知輸出可以斷定。爲了創建一個好的分類樹模型,我們必須要有一個輸出已知的現有數據集,從這個數據集才能構建我們的模型。我們還看到了我們需要將我們的數據集分成兩個部分:一個用來創建模型的訓練集 ;一個用來驗證模型是否正確且沒有過擬合的測試集。因爲在某些時候,即便是創建了一個自己認爲正確的數據模型,它也可能不正確,所以需要驗證。
在有些時候,我們也有可能必須要摒棄原來的整個模型和算法以尋找更好的模型和算法解決方案。因爲有時候同一個業務目標,其實可以有不同的數據挖掘方法,這個我們會在第三章 - 最近鄰算法裏面提到並作一些比較。
模型三。羣集模型(聚類模型)
對於一般的用戶,羣集有可能是最爲有用的一種數據挖掘方法。它可以迅速地將整個數據集分成組,讓我們快速發現並且提取某個組的共同特徵,快速得出結論和做相應的改善。個人覺得,羣集模型對於商業拓展和業務、產品指導方面,肯定是最有效的數據挖掘模型之一。
就人工智能而言,羣集模型屬於非監督算法,也就是我們採集或者獲得一組數據後,雖然對這個數據有一定了解,但也許並不知道它應該怎麼分類,也不知道這些數據有哪些特徵,這也是使用羣集模型的一個難點。
所以,使用羣集的一個主要劣勢是用戶需要提前知道他想要創建的組的數量。若用戶對其數據知之甚少,這可能會很困難。是應該創建三個組?五個組?還是十個組?所以在決定要創建的理想組數之前,可能需要進行幾個步驟的嘗試和出錯。這要求用戶對採集的數據目的比較明確。
就算法而言,簡單說來,羣集或聚類算法核心,是通過計算各個數據之間的距離,將距離比較近的數據歸在一起。當然,說起來比較簡單,實現起來不是那麼簡單。有一個比較簡單的例子,可以幫助我們瞭解集羣的算法核心:
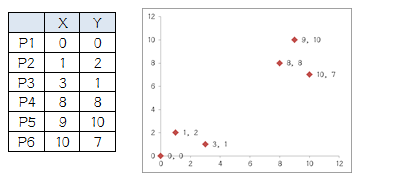
上圖是平面座標裏面的6個點,分成兩個組。如果通過我們的眼睛來看,憑經驗判斷,那是非常簡單了,左下角三個點一組,右上角三個點一組,一秒鐘的事情。如果要通過羣集算法怎麼實現呢?下面就是步驟:
1.選擇初始大哥:
我們就選P1和P2
2.計算小弟和大哥的距離:
P3到P1的距離從圖上也能看出來(勾股定理),是√10 = 3.16;P3到P2的距離√((3-1)^2+(1-2)^2 = √5 = 2.24,所以P3離P2更近,P3就跟P2混。同理,P4、P5、P6也這麼算,如下:
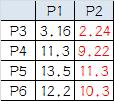
P3到P6都跟P2更近,所以第一次站隊的結果是:
• 組A:P1
• 組B:P2、P3、P4、P5、P6
3.人民代表大會:
組A沒啥可選的,大哥還是P1自己
組B有五個人,需要選新大哥,這裏要注意選大哥的方法是每個人X座標的平均值和Y座標的平均值組成的新的點,爲新大哥,也就是說這個大哥是“虛擬的”。
因此,B組選出新大哥的座標爲:P哥((1+3+8+9+10)/5,(2+1+8+10+7)/5)=(6.2,5.6)。
綜合兩組,新大哥爲P1(0,0),P哥(6.2,5.6),而P2-P6重新成爲小弟
4.再次計算小弟到大哥的距離:
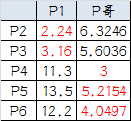
這時可以看到P2、P3離P1更近,P4、P5、P6離P哥更近,所以第二次站隊的結果是:
• 組A:P1、P2、P3
• 組B:P4、P5、P6(虛擬大哥這時候消失)
5.第二屆人民代表大會:
按照上一屆大會的方法選出兩個新的虛擬大哥:P哥1(1.33,1) P哥2(9,8.33),P1-P6都成爲小弟
6.第三次計算小弟到大哥的距離:
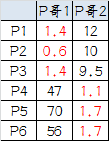
這時可以看到P1、P2、P3離P哥1更近,P4、P5、P6離P哥2更近,所以第二次站隊的結果是:
• 組A:P1、P2、P3
• 組B:P4、P5、P6
我們發現,這次站隊的結果和上次沒有任何變化了,說明已經收斂,聚類結束,聚類結果和我們最開始設想的結果完全一致。
以上就是羣集或者聚類算法的基本思想。
WEKA演示
加載數據文件 bank.arff
選擇Cluster選項,然後選擇 SimpleKMeans算法。
點算法選擇框,在彈出框的 numClusters 裏面輸入6 ,表示生成6個組。
然後按Start,可以看到輸出結果如下:
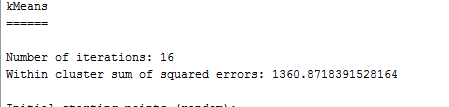
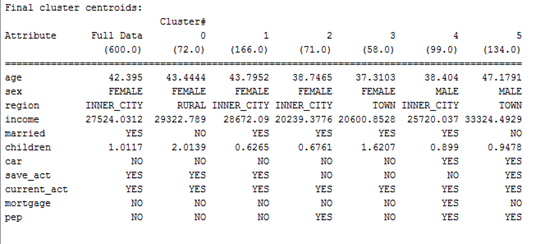
這裏我們很快會不可避免地提出兩個問題,第一,我們怎麼知道將數據集分成幾個組呢,第二,分成不同組以後,怎麼去分析不同組的特性,並發現規律呢?
我也不是很清楚,比如上面的分組,我對銀行業務沒有了解,所以實在是的不出什麼結論。網上有這麼一段話可以參考。
在聚類數據挖掘中,業務專家的作用非常大,主要體現在聚類變量的選擇和對於聚類結果的解讀:
- 比如要對於現有的客戶分羣,那麼就要根據最終分羣的目的選擇不同的變量來分羣,這就需要業務專家經驗支持。如果要優化客戶服務的渠道,那麼就應選擇與渠道相關的數據;如果要推廣一個新產品,那就應該選用用戶目前的使用行爲的數據來歸類用戶的興趣。算法是無法做到這一點的
- 欠缺經驗的分析人員和經驗豐富的分析人員對於結果的解讀會有很大差異。其實不光是聚類分析,所有的分析都不能僅僅依賴統計學家或者數據工程師。
下面有一個羣集的例子,帶有分組業務分析。
話說有一家寶馬經銷店。這個經銷店保留了人們如何在經銷店以及展廳行走、他們看了哪些車以及他們最終購車的機率的記錄。經銷店期望通過尋找數據內的模式挖掘這些數據並使用羣集來判斷其客戶是否有某種行爲特點。歷史記錄中有 100 行數據,並且每個列都描述了顧客在他們各自的 BMW 體驗中所到達的步驟,比如列中的 1 表示到達這一步的顧客看過這輛車,0 表示他們不曾到達看過車的這一步。下面清單顯示了在 WEKA 中所使用的 ARFF 數據。
@attribute Dealership numeric
@attribute Showroom numeric
@attribute ComputerSearch numeric
@attribute M5 numeric
@attribute 3Series numeric
@attribute Z4 numeric
@attribute Financing numeric
@attribute Purchase numeric
@data
1,0,0,0,0,0,0,0
1,1,1,0,0,0,1,0
經過一番操作後,得到下面的輸出:

下面是業務分析:
羣集 0— 這個組我們可以稱之爲 “Dreamers”,因他們圍着經銷店徘徊,查看在停車場上停着的車,卻不步入店面內,且更糟的是,他們沒有購買過任何東西。
羣集 1— 我們將這一組稱爲是 “M5 Lovers”,因爲他們常常會徑直走到 M5 車型區,對 3-系列的車型和 Z4 均視而不見。不過,他們也沒有多高的購買率 — 只有 52 %。這表明存在潛在問題,也是經銷店今後改進的重點,比如可以派更多的銷售人員到 M5 區。
羣集 2— 這個組很小,我們可以稱之爲 “Throw-Aways”,因爲他們沒有統計意義上的相關性,我們也不能從其行爲得出任何好的結論。(這種情況若在羣集上發生,可能表明應該減少所創建的羣集的數量。)
羣集 3— 這個組,我們稱之爲 “BMW Babies”,因爲他們總是會購買一輛車而且還會支付車款。正是在這裏,數據向我們顯示了一些有趣的事情:他們一般會在停車場內查看各種車型,然後返回到經銷店內的計算機處搜索中意的車型是否有貨。他們最終會購買 M5 或 Z4 車型(但從不購買 3-系列的)。這個羣集告訴經銷店它應該考慮讓它的搜索計算機在停車場處就能很容易地被看到(或安置一臺室外的搜索計算機),並且讓 M5 或 Z4 在搜索結果中更爲醒目。一旦顧客決定購買汽車,他總是符合購車款的支付條件並能夠圓滿完成這次購買。
羣集 4— 這個組我們將稱之爲 “Starting Out With BMW”,因爲他們總是看 3-系列的車型,從不看貴很多的 M5。他們會徑直步入展廳,而不會在停車場處東看西看,而且也不會使用計算機搜索終端。他們中有 50 % 會到達支付車款的階段,但只有 32 % 會最終成交。經銷店可以得出這樣的結論:這些初次購買 BMW 車的顧客知道自己想要的車型是哪種( 3-系列的入門級車型)而且希望能夠符合購車款的支付條件以便買得起。經銷店可以通過放鬆購車款的支付條件或是降低 3- 系列車型的價格來提高這一組的銷售。
羣集模型結束語
總覺得“分類”和“聚類”,往往可以配合使用。我們做一下發散性思維。考慮上面提到的寶馬經銷店,如果是一家不差錢的大型店,我們考慮設置這麼一套系統。
在店門口和店內,幾個重要的點安裝上人臉自動之別系統,此係統同時和銀行或者政府個人資料庫關聯,當一個人經過的時候,可以自動識別身份,並且瞬間獲知其年齡,收入,婚姻,×××等等信息。採集這些信息,並且記錄此人從店門口經過開始到入店(也可能不進店),離開店的全部過程。後面對接一個“羣集模型”和“分類模型”數據挖掘系統。
我們不難想象,這個經銷商店可以在經銷方面做到多麼細緻。馬路上走過來一個人,立馬可以計算出他/她對什麼最有可能購買,並且知道他/她當前的經濟情況,合適推薦什麼相關服務和金融方案。對店內的設備和佈置來說,可以根據集羣得出的結論,正確設計展臺,選擇展品車型,佈局各種展品的位置,增加一些有趣味的高科技設計,採取多種方法提高進店率等等。
永遠不要忘記,我們使用“數據挖掘”的目的是爲了服務於業務這一個基本點。
模型四。最近鄰模型
最近鄰思想的提出和應用場景非常典型,假定一個客戶登錄了某購物網站,我們怎麼給他/她推薦商品呢?或者說我們怎麼知道他/她最有可能買什麼商品呢?
假定現在手裏有下面這些顧客購買的歷史數據:
Customer Age Income Purchased Product
1 45 46k Book
2 39 100k TV
3 35 38k DVD
4 69 150k Car Cover
現在提出一個問題,下面第5個客戶,最有可能購買什麼商品?
5 58 51k ???
結局這個問題,就要用到“最近鄰”的思想,我們需要考慮這第五個客戶,和哪個客戶最相似,和哪個客戶最相似,我們認爲他就會購買一樣的商品。
步驟1: Determine Distance Formula/確定一個距離計算公式
Distance = SQRT( ((58 - Age)/(69-35))^2) + ((51000 - Income)/(150000-38000))^2 )
步驟2: Calculate the Score/計算每個客戶和新客戶的距離分數
Customer Score Purchased Product
1 .385 Book
2 .710 TV
3 .686 DVD
4 .941 Car Cover
5 0.0 ???
現在我們就可以回答“第 5 個顧客最有可能購買什麼產品”這一問題,答案第5個客戶將最有可能買的是一本書。這是因爲第 5 個顧客與第 1 個顧客之間的距離要比第 5 個顧客與其他任何顧客之間的距離都短(實際上是短很多)。基於這個模型,可以得出這樣的結論:由最像第 5 個顧客的顧客可以預測出第 5 個顧客的行爲。
不過,最近鄰的好處遠不止於此。最近鄰算法可被擴展成不僅僅限於一個最近匹配,而是可以包括任意數量的最近匹配。可將這些最近匹配稱爲是 “N-最近鄰”(比如 3-最近鄰)。回到上述的例子,如果我們想要知道第 5 個顧客最有可能購買的兩個產品,那麼這次的結論以此是書和 DVD。而對於我們曾經提到的亞馬遜的例子,如果想要知道某個顧客最有可能購買的 12 個產品,就可以運行一個 12-最近鄰算法(但亞馬遜實際運行的算法要遠比一個簡單的 12-最近鄰算法複雜)。
下面我們用分類模型同樣的數據集合,來驗證一下其在“最近鄰”模型下面的正確率。
載入鳶尾花 iris.arff ,然後選擇算法 lazy – Ibk,結果如下:
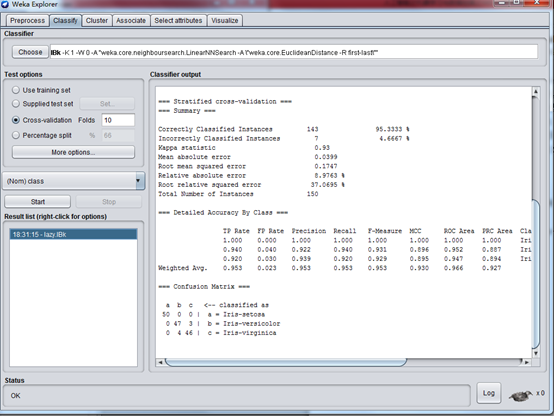
最近鄰模型下的正確率爲 95.33%,接近與用“J48分類”算法的正確率。
而且我把K調到了6,發現正確率變高了,如下圖:
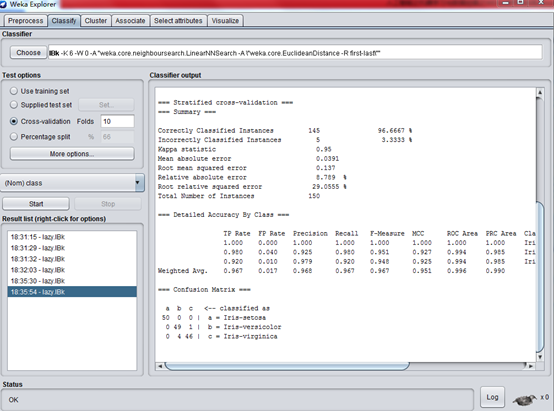
正確率達到了 96.7%。
最近鄰模型結束語
我們在例子中用到的k近鄰法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一種基本分類與迴歸方法。它的工作原理是:存在一個樣本數據集合,也稱作爲訓練樣本集,並且樣本集中每個數據都存在標籤,即我們知道樣本集中每一個數據與所屬分類的對應關係。輸入沒有標籤的新數據後,將新的數據的每個特徵與樣本集中數據對應的特徵進行比較,然後算法提取樣本最相似數據(最近鄰)的分類標籤。一般來說,我們只選擇樣本數據集中前k個最相似的數據,這就是k-近鄰算法中k的出處,通常k是不大於20的整數。最後,選擇k個最相似數據中出現次數最多的分類,作爲新數據的分類。
回到剛開始提到的應用場景,假定我們有一個 2000 萬用戶的購物平臺,此算法將非常準確,因爲數據庫中與某用戶有着類似購買習慣的潛在客戶很多。最近鄰會非常相似。因而,所創建的模型會十分準確和高效。相反,如果能比較的數據點相對很少的話,這個模型很快就會損壞,不再準確。在線電子商務店鋪的初期,比如只有 50 個顧客,那麼產品推薦特性很可能一點都不準確,因爲最近鄰實際上與您本身相差甚遠。
最近鄰技術可能存在的一個挑戰是該算法的計算成本有可能會很高。在一個很大的平臺的例子中,比如對於有 2000 萬客戶的平臺,每個新客戶都必須針對其他的 2000 萬客戶進行計算以便找到最近鄰。首先,如果我們的業務也有 2000 萬的客戶羣,那麼這便不成問題,因爲您會財源廣進。其次,這種類型的計算非常適合用雲來完成,因爲它們能夠被分散到許多計算機上同時完成,並最終完成比較(比如MapReduce)。不過,實際上如果我只是購買了一本書,那麼根本不必針對我對比數據庫內的2000萬個客戶。只需將我與其他的購書者進行對比來尋找最佳匹配,這樣一來,就將潛在的鄰縮小到整個數據庫的一部分。
最後部分。如何用weka.jar直接寫程序
上面我們用到WEKA做一些例子有演示,但作爲開發者來說,WEKA 最酷的一件事情是它不僅是一個獨立的應用程序,而且還是一個完備的 Java JAR 文件,可以將其投入到您服務器的 lib 文件夾並從您自己的JAVA應用代碼進行調用。
這能爲我們的應用程序帶來很多實用的、和重要的功能。您可以添加充分利用了我們到目前所學的全部數據挖掘技術的報告。您可以爲您的電子商務網站/平臺創建一個“產品推薦”小部件,類似於亞馬遜站點上的那個。
現在,我們應該看看如何將它集成到您的自己代碼中。
實際上,我們已經下載了這個 WEKA API JAR,你可以在安裝目錄中找到它 weka.jar它就是您啓動 WEKA Explorer 時調用的那個 JAR 文件。爲了訪問此代碼,讓您的 Java 環境在此類路徑中包含這個 JAR 文件。在您自己的代碼中使用第三方 JAR 文件的步驟如常。
正如您所想,WEKA API 內的這個中心構建塊就是數據。數據挖掘圍繞此數據進行,當然所有我們已經學習過的這些算法也都是圍繞此數據的。
那麼讓我們看看如何將我們的數據轉換成 WEKA API 可以使用的格式。讓我們從簡單的開始,先來看看本系列有關房子定價的第一篇文章中的那些數據。
一.加載數據
// 定義數據屬性
Attribute a1 = new Attribute("houseSize", 0);
Attribute a2 = new Attribute("lotSize", 1);
Attribute a3 = new Attribute("bedrooms", 2);
Attribute a4 = new Attribute("granite", 3);
Attribute a5 = new Attribute("bathroom", 4);
Attribute a6 = new Attribute("sellingPrice", 5);
// 加載屬性
FastVector attrs = new FastVector();
attrs.addElement(a1);
attrs.addElement(a2);
attrs.addElement(a3);
attrs.addElement(a4);
attrs.addElement(a5);
attrs.addElement(a6);
// 加載一條或者多條數據.
Instance i1 = new Instance(6);
i1.setValue(a1, 3529);
i1.setValue(a2, 9191);
i1.setValue(a3, 6);
i1.setValue(a4, 0);
i1.setValue(a5, 0);
i1.setValue(a6, 205000);
....
Instances dataset = new Instances("housePrices", attrs, 7);
dataset.add(i1);
dataset.add(i2);
dataset.add(i3);
dataset.add(i4);
dataset.add(i5);
dataset.add(i6);
dataset.add(i7);
… …
//設定輸出變量,
dataset.setClassIndex(dataset.numAttributes() - 1);
假定現在我們已經將數據載入了 WEKA。看起來比較麻煩一點,但這裏只是個演示,我們可以看到編寫自己的包裝器類來快速從數據庫或者文件提取數據並將其放入一個 WEKA 實例類還是很簡單的。
讓我們把我們的數據通過迴歸模型進行處理並確保輸出與我們使用 Weka Explorer 計算得到的輸出相匹配。實際上使用 WEKA API 讓數據通過迴歸模型得到處理非常簡單,遠簡單于實際加載數據。
// 選擇並初始化模型,實際上我們這裏需要的是多維線性迴歸模型 LinearRegression
LinearRegression linearRegression = new LinearRegression();
// 這個就是根據綁定的數據生成了模型
linearRegression.buildClassifier(dataset);
// 獲取模型參數,爲了計算我們自己的房價
double[] coef = linearRegression.coefficients();
// 把我們自己的房子屬性代入模型公式
double myHouseValue = (coef[0] 3198) +
(coef[1] 9669) +
(coef[2] 5) +
(coef[3] 3) +
(coef[4] * 1) +
coef[6];
//打印出房價,這個房價應該是和通過直接使用WEKA應用程序一致的。
System.out.println(myHouseValue);
// outputs 219328.35717359098
結束語
我們馬上能意識到,將以上代碼嵌入我們的後臺管理系統,就是一個非常專業和智能化的房價定價後臺,這個後臺加以調整,可以分城市,地區甚至分小區生成更佳的定價模型。另外,如果綁定最近3個月的實時成交數據,這個模型公式還會根據最近的成交價格自動調整參數,其價值遠遠大於平均值和人工自定義公式。
對於其它三種模型,我們也可以通過學習weka.jar API 的用法,自動綁定到我們的程序,這樣就可以形成一個強大的數據挖掘和業務支撐系統。
本文是由五個章節,分別向大家介紹了幾個數據挖掘的重要概念,包括迴歸模型,分類模型和聚類(羣集)模型,同時給大家介紹了 WEKA 軟件的使用方法,並且通過使用WEKA例子,使得大家對提到的四種數據挖掘有了直觀感覺。文章的最後一章,給大家演示了將weka API weka.jar接入我們系統的基本方法。
對大多數人來說,並不需要深入研究人工智能或者數據挖掘的算法,成爲這種算法和模型專家,都需要數年甚至十數年的積累,而且你還必須頗具天賦。但作爲一般的產品人員,程序開發人員甚至是公司管理決策人員、創業人員,花一點時間,找到合適的工具,去了解人工智能和數據挖掘相關的概念以及如何在日常工作中應用它,其實並不是非常難的事情,而且是非常有價值的事情。
希望閱讀這篇文章的每個人,都能成爲這方面的專家!