




FP-growth算法
項目背景/目的
對於廣告投放而言,好的關聯會一定程度上提高用戶的點擊以及後續的諮詢成單
對於產品而言,關聯分析也是提高產品轉化的重要手段,也是大多商家都在做的事情,尤其是電商平臺
曾經我用SPSS Modeler做過Apriori關聯分析模型,也能滿足需求,但是效果自然是不及python了,這裏分享一下操作流程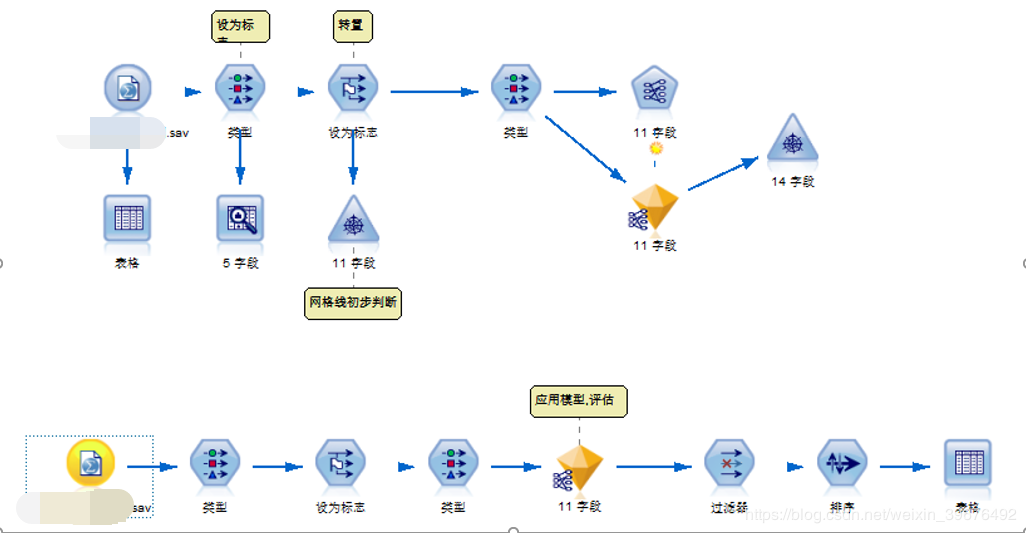
還有一週就雙十一了,那不妨去看看產品關聯背後的原理
項目原理
步驟一 數據處理
1.遍歷所有的數據集合,計算所有項的支持度(次數)
2.丟棄非頻繁項(次數小於2)
3.再對所有出現次數降序排列
4.對所有的數據集按照支持度排序,並丟棄非頻繁項
~ 到這一步整個數據就處理好了,後面就是生成FP tree以及節點鏈表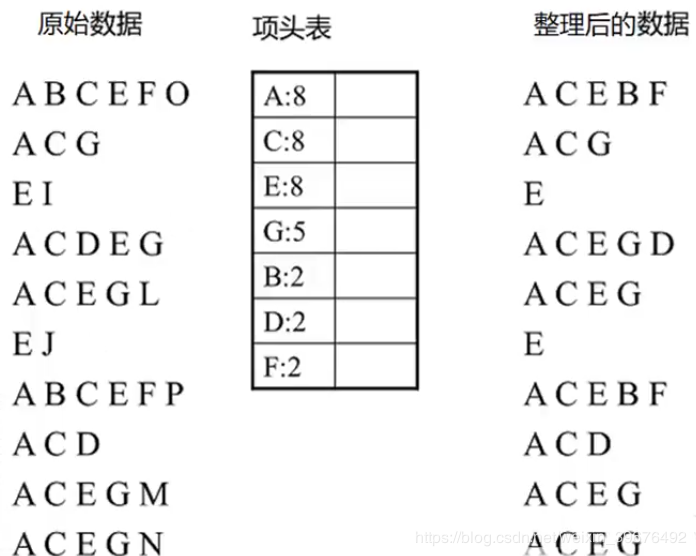
步驟二 FP樹創建
1.讀取每個集合插入FP樹中,同時用一個頭部鏈表數據結構維護不同集合的相同項,這裏講根節點設置爲null,就是指根節點不包括任何的項,是爲了任何一個數據集進來都被視爲空項開始的
2.每新增一個計數加1,沒有重合則新增一個節點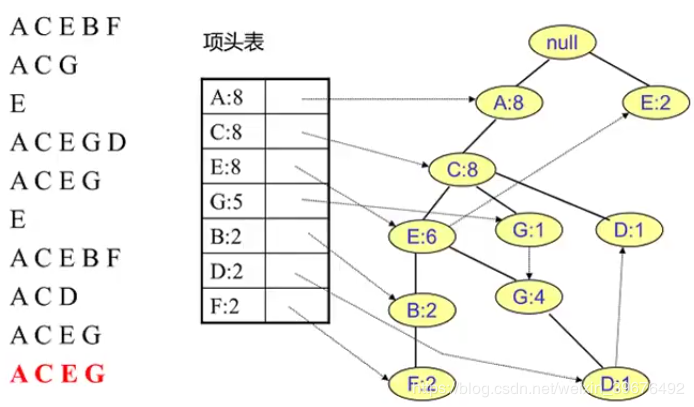
步驟三 從FP數中挖掘頻繁項集
1.對頭部鏈表進行降序排序
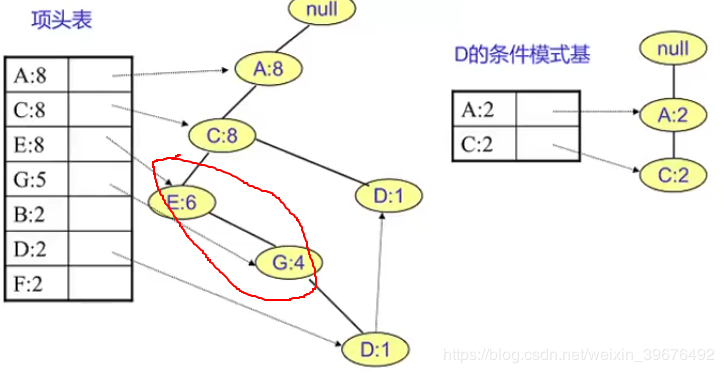
2.對頭部鏈表節點從小到大遍歷,得到條件模式基,同時獲得一個頻繁項集
也就是說對項頭表頻率最小的開始,找對其對於的葉子節點並計數,也就是其對應的條件模式基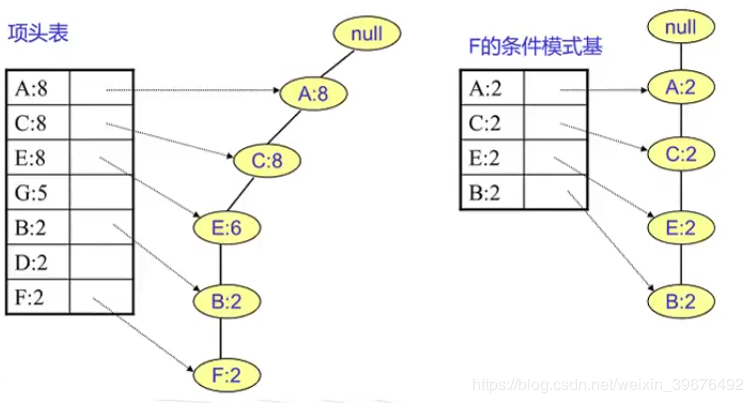
這裏的葉子節點計數爲 {A:2,C:2,E:1,G:1,D:1},刪除閾值小於2的 故只有A,C
代碼解釋
FP樹的節點結構
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue # 節點名稱
self.count = numOccur # 節點出現次數
self.nodeLink = None # 不同項集的相同項通過nodeLink連接在一起
self.parent = parentNode # 指向父節點
self.children = {} # 存儲葉子節點
如果需要了解更多機器學習相關內容可以加羣:4 2 5 85 19 55獲取免費資料
def inc(self, numOccur):
"""inc(對count變量增加給定值)
"""
self.count += numOccur
def disp(self, ind=1):
"""disp(用於將樹以文本形式顯示)
"""
print(' '*ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind+1)
def __lt__(self, other):
return self.count < other.count
讀取數據並調用createTree方法,設置頻繁項集(也就是出現次數這裏是100000)
parsedDat = [line.split() for line in open('kosarak.dat').readlines()]
initSet = createInitSet(parsedDat)
myFPtree, myHeaderTab = createTree(initSet, 100000)
如果需要了解更多機器學習相關內容可以加羣:4 2 5 85 19 55獲取免費資料調用mineTree方法
myFreList = []
mineTree(myFPtree, myHeaderTab, 100000, set([]), myFreList)
print(myFreList)
由於代碼量較大就不一一copy上了
結論
最終輸出如下結果,eg:瀏覽(購買)過1的同時也瀏覽(購買)了6,幾百萬的數據量運行也是很快的