




前序
記得第一次上編譯原理這門課時,老師曾慷慨激昂的說:“學好編譯原理能讓你們享用一生,你們要好好學啊”。不過學完編譯原理也有一段時間了,平時也找一些編譯原理方面的資料學習,卻始終感受不到學習編譯原理的效用。究其原因還是自己學的太單薄了,畢竟像這種“內功”可不是一天兩天就能練出來的!只是感覺這門課挺有意思,權當一門興趣來學了。
正文
本文將介紹六大節的內容,其中每個部分又分爲若干小節,如下圖描述:
![]()
第一節 編譯程序概覽
1.編譯程序的定義:將高級語言編寫的源程序翻譯成目標語言的程序。
例如用Pascal語言、C語言、C++語言等編寫的程序,都是高級語言程序。而這些程序不能直接被計算機理解和執行,必須經過等價的轉換,變成機器能理解與執行的機器語言才能執行。
2.編譯程序的過程:詞法分析、語法分析、語義分析與中間代碼生成、代碼優化、目標代碼生成。
①.詞法分析:直白的說,就是識別單詞。如關鍵字、標示符、常數、特殊符號。
②.語法分析:在詞法分析的基礎上將單詞序列組合成各類語法短語。如語句、表達式等等。
③.語義分析和中間代碼生成:
語義分析是對源程序進行上下文有關性質的檢查,看源程序有無語義錯誤。例如:變量是否定義、類型是否正確。
中間代碼:含義明確、便於處理的記號系統。這種記號系統於源程序和機器語言之間,容易將它翻譯成目標代碼。如三元式、四元式、逆波蘭式等。
④.代碼優化:對程序代碼進行等價(不改變程序的運行結果)變換。優化的目的是使最終生成的目標代碼在時間和空間上效率更高。
⑤.目標代碼生成:指把語法分析後或優化後的中間代碼變換成目標代碼。目標代碼有三種形式:
⑴.可以立即執行的機器語言代碼,所有地址都重定位;
⑵.待裝配的機器語言模塊,當需要執行時,由連接裝入程序把它們和某些運行程序連接起來,轉換成能執行的機器語言代碼;
⑶.彙編語言代碼,須經過彙編程序彙編後,成爲可執行的機器語言代碼。
這就是編譯過程的一般分法,不過並非所有的編譯過程都分爲這五個階段。可將語義分析與中間代碼生成、代碼優化這兩個階段省去以加快編譯速度。
3.編譯程序的開發技術:自編譯、交叉編譯、自展、移植等。
第二節 理論基礎
1.文法
①.文法的定義:對語言結構的定義和描述。例如,“The cat ate a house”。
②.文法的組成:
⑴.終結符:用小寫字母表示,記爲VT。
⑵.非終結符:用大寫字母表示,記爲VN。
⑶.文法規則集合:規則一般表示爲:A->a。
一個形式文法是四元有序組G = (VN, VT, S, P)。其中,S爲文法的開始符號,P是規則集。很顯然,見下圖:
![]()
記得第一次上編譯原理這門課時,老師曾慷慨激昂的說:“學好編譯原理能讓你們享用一生,你們要好好學啊”。不過學完編譯原理也有一段時間了,平時也找一些編譯原理方面的資料學習,卻始終感受不到學習編譯原理的效用。究其原因還是自己學的太單薄了,畢竟像這種“內功”可不是一天兩天就能練出來的!只是感覺這門課挺有意思,權當一門興趣來學了。
正文
本文將介紹六大節的內容,其中每個部分又分爲若干小節,如下圖描述:

第一節 編譯程序概覽
1.編譯程序的定義:將高級語言編寫的源程序翻譯成目標語言的程序。
例如用Pascal語言、C語言、C++語言等編寫的程序,都是高級語言程序。而這些程序不能直接被計算機理解和執行,必須經過等價的轉換,變成機器能理解與執行的機器語言才能執行。
2.編譯程序的過程:詞法分析、語法分析、語義分析與中間代碼生成、代碼優化、目標代碼生成。
①.詞法分析:直白的說,就是識別單詞。如關鍵字、標示符、常數、特殊符號。
②.語法分析:在詞法分析的基礎上將單詞序列組合成各類語法短語。如語句、表達式等等。
③.語義分析和中間代碼生成:
語義分析是對源程序進行上下文有關性質的檢查,看源程序有無語義錯誤。例如:變量是否定義、類型是否正確。
中間代碼:含義明確、便於處理的記號系統。這種記號系統於源程序和機器語言之間,容易將它翻譯成目標代碼。如三元式、四元式、逆波蘭式等。
④.代碼優化:對程序代碼進行等價(不改變程序的運行結果)變換。優化的目的是使最終生成的目標代碼在時間和空間上效率更高。
⑤.目標代碼生成:指把語法分析後或優化後的中間代碼變換成目標代碼。目標代碼有三種形式:
⑴.可以立即執行的機器語言代碼,所有地址都重定位;
⑵.待裝配的機器語言模塊,當需要執行時,由連接裝入程序把它們和某些運行程序連接起來,轉換成能執行的機器語言代碼;
⑶.彙編語言代碼,須經過彙編程序彙編後,成爲可執行的機器語言代碼。
這就是編譯過程的一般分法,不過並非所有的編譯過程都分爲這五個階段。可將語義分析與中間代碼生成、代碼優化這兩個階段省去以加快編譯速度。
3.編譯程序的開發技術:自編譯、交叉編譯、自展、移植等。
第二節 理論基礎
1.文法
①.文法的定義:對語言結構的定義和描述。例如,“The cat ate a house”。
②.文法的組成:
⑴.終結符:用小寫字母表示,記爲VT。
⑵.非終結符:用大寫字母表示,記爲VN。
⑶.文法規則集合:規則一般表示爲:A->a。
一個形式文法是四元有序組G = (VN, VT, S, P)。其中,S爲文法的開始符號,P是規則集。很顯然,見下圖:

舉個例子,設VN={A},VT={a,b,c},S=A,P={A->aAb, A->c}。這樣就構成了文法G = ({A}, {a,b,c}, A, P)。
③.文法的分類:0型文法,1型文法,2型文法,3型文法。
0型文法:也叫短語結構文法。辨別依據:當有α->β時,左邊α中必須含有非終結符,形如A->β等。
1型文法:也叫上下文有關文法。辨別依據:在0型文法的基礎上,當有α->β時,定有
|α| <= |β|,其中|α| 和|β|分別表示其長度。如有A->Ba,則|α|=1,|β|=2符合1型文法要求。反之,如aA->a,則不符合1型文法。
附註:雖然要求|α| <= |β|,但有一特例:α->ε也滿足1型文法。
2型文法:也叫上下文無關文法。辨別依據:在1型文法的基礎上,當有α->β時,α必是終結符。如A->Ba,符合2型文法要求。 如果是Aa->Ba這樣的形式,那麼就不滿足了,因爲Aa不是一個非終結符。
3型文法:也叫正則文法。辨別依據:在2型文法的基礎上需滿足:A->a|aB(右線性)或A->a|Ba(左線性)。
![]()
![]()
③.文法的分類:0型文法,1型文法,2型文法,3型文法。
0型文法:也叫短語結構文法。辨別依據:當有α->β時,左邊α中必須含有非終結符,形如A->β等。
1型文法:也叫上下文有關文法。辨別依據:在0型文法的基礎上,當有α->β時,定有
|α| <= |β|,其中|α| 和|β|分別表示其長度。如有A->Ba,則|α|=1,|β|=2符合1型文法要求。反之,如aA->a,則不符合1型文法。
附註:雖然要求|α| <= |β|,但有一特例:α->ε也滿足1型文法。
2型文法:也叫上下文無關文法。辨別依據:在1型文法的基礎上,當有α->β時,α必是終結符。如A->Ba,符合2型文法要求。 如果是Aa->Ba這樣的形式,那麼就不滿足了,因爲Aa不是一個非終結符。
3型文法:也叫正則文法。辨別依據:在2型文法的基礎上需滿足:A->a|aB(右線性)或A->a|Ba(左線性)。


由此便可得出四類文法的關係:見下圖
![]()
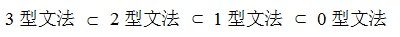
④.文法的二義性:對於某文法的同一個句子存在兩種不同的語法樹。如下圖:
![]()
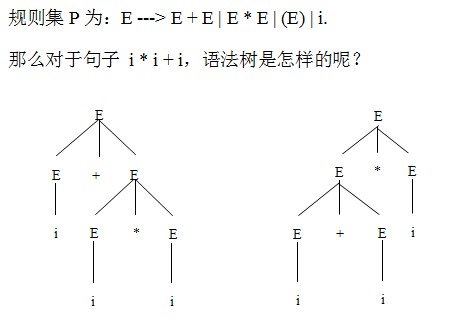
由語法樹我們得出句子“i+i*i”是二義性的。
既然文法會出現二義性,那麼怎麼解決二義性呢?辦法有二:修改編譯算法;修改文法。
2.自動機
自動機:能識別或生成語言的識別器。
在談有限自動機之前,先解釋一下術語狀態轉換。所謂狀態轉換,就是當讀入一個字符時,使狀態改變爲另一狀態,改變後的狀態稱爲後繼狀態。
①.確定優先自動機(DFA):只有一個初始狀態,可以有不止一個終止狀態。轉換的後繼狀態都是唯一的。例:
![]()
既然文法會出現二義性,那麼怎麼解決二義性呢?辦法有二:修改編譯算法;修改文法。
2.自動機
自動機:能識別或生成語言的識別器。
在談有限自動機之前,先解釋一下術語狀態轉換。所謂狀態轉換,就是當讀入一個字符時,使狀態改變爲另一狀態,改變後的狀態稱爲後繼狀態。
①.確定優先自動機(DFA):只有一個初始狀態,可以有不止一個終止狀態。轉換的後繼狀態都是唯一的。例:
P集爲: Z -> Za | Aa | Bb
A -> Ba | a
B -> Ab | b
構造的狀態轉換圖如下圖:A -> Ba | a
B -> Ab | b

②.不確定有限自動機(NFA):可以有若干個開始狀態,可以有若干個終止狀態。轉換的後繼狀態可有多個。例:
![]()
P集爲: Z -> Za | Aa | Bb
A -> Ba | Za | a
B -> Ab | Ba | b
構造的狀態轉換圖如下圖:A -> Ba | Za | a
B -> Ab | Ba | b

③.NFA到DFA的轉換
轉換法則:由初始狀態S開始,求狀態的轉換,若有新的狀態出現,繼續求新狀態的轉換,直至沒有新的狀態出現爲止。例:
![]()
轉換法則:由初始狀態S開始,求狀態的轉換,若有新的狀態出現,繼續求新狀態的轉換,直至沒有新的狀態出現爲止。例:
P集爲: Z -> Za | Aa | Bb
A -> Ba | Za | a
B -> Ab | Ba | b
構造的NFA的狀態轉換圖如下圖:A -> Ba | Za | a
B -> Ab | Ba | b
由NFA的狀態轉換圖根據轉換法則就可得到DFA的狀態轉換表如下圖:
![]()

由DFA的狀態轉換表就可得到DFA的狀態轉換圖了。狀態轉換圖在這就不展示了,如果你有興趣的話,自己可以畫一下。
④.DFA的化簡:去掉等價狀態和無關狀態。
附註:如果是NFA,則需先將NFA化簡成DFA,而後再化簡即可。
第三節 詞法分析程序之設計原理
1.詞法分析的功能:讀入源程序字符串,從左至右逐個掃描,並從其中識別出具有獨立意義的最小語法單元---單詞。
2.詞法分析的兩種處理結構
①.詞法分析程序作爲主程序,即把詞法分析作爲獨立的一趟來完成。
②.詞法分析程序作爲子程序,即把詞法分析作爲一個供語法分析程序調用的子程序。
3.詞法分析程序的流程
在談流程之前多說兩句,詞法分析在前文中已說過,其實就是識別單詞。那麼此時我們就有必要了解一下單詞符號的種類了。
單詞符號的種類:保留字、標示符、無符號數、界限符。
保留字:也叫關鍵字,如if、else、do、for、return等。
標示符:用來標記常量、變量、函數等的名字,這是由自己定義的,如i,j,max等。
無符號數:如256、0.5、3E2等等。
界限符:如+、-、*、++、--、>=、==等等。
瞭解了單詞,我們就來看看流程圖吧!如下:
![]()
OK,前三節就將完了,後面三節將在下篇文章中繼續。
④.DFA的化簡:去掉等價狀態和無關狀態。
附註:如果是NFA,則需先將NFA化簡成DFA,而後再化簡即可。
第三節 詞法分析程序之設計原理
1.詞法分析的功能:讀入源程序字符串,從左至右逐個掃描,並從其中識別出具有獨立意義的最小語法單元---單詞。
2.詞法分析的兩種處理結構
①.詞法分析程序作爲主程序,即把詞法分析作爲獨立的一趟來完成。
②.詞法分析程序作爲子程序,即把詞法分析作爲一個供語法分析程序調用的子程序。
3.詞法分析程序的流程
在談流程之前多說兩句,詞法分析在前文中已說過,其實就是識別單詞。那麼此時我們就有必要了解一下單詞符號的種類了。
單詞符號的種類:保留字、標示符、無符號數、界限符。
保留字:也叫關鍵字,如if、else、do、for、return等。
標示符:用來標記常量、變量、函數等的名字,這是由自己定義的,如i,j,max等。
無符號數:如256、0.5、3E2等等。
界限符:如+、-、*、++、--、>=、==等等。
瞭解了單詞,我們就來看看流程圖吧!如下:
