




前言
在目前而言,神經網絡恐怕是機器學習尤其是深度學習最爲熱門的一個方向,故筆者將其放在較後的位置予以論述。神經網絡(Neural Network)顧名思義就是模擬人類(爲什麼不是其它動物?)生物特徵上的大腦神經元的結構,故可以認爲這實際上是一種人工智能或機器學習的結構主義,其主要代表人物是Hinton教授等人,但在人工神經網絡大熱的今天,爲什麼這派人物似乎沒有得到計算機界最高獎項——圖靈獎,這個恐怕就不太好解釋,筆者思考其原因可能和神經網絡本身一樣不太具有解釋性有極大關係(即在數學上沒法完全說得清楚有關,其主要過程可能還是依賴於經驗,即對各種參數組合的調整並觀察以獲得較好結果;難道這派人物的數學都不太好?如果拿Hinton和Vapnik比,確實如此,或還是缺少更爲高級的數學理論以支撐,而不僅僅是分析學或概率學),故其與如複雜性理論、密碼學(基於數論基礎或其它諸如橢圓曲線等)等可能就存在天然的理論鴻溝。
從分類上看,人工神經網絡所包含的類型很多,除了我們最熟悉的反向傳播神經網絡(BPNN,本文還是以此爲主要內容)、卷積神經網絡(CNN)、遞歸神經網絡(RNN)、受限玻爾茲曼機(RBM)等等,還有不勝枚舉的上述神經網絡的各種變形,但究其根本任務還是進行分類和迴歸,當然還有用於編碼、壓縮以及特徵抽取的。
從結構上看,絕大多數人工神經網絡的結構都是相似的,它們都是層次式的,每層都包含若干個所謂的神經元,各層的神經元之間有相互聯繫的邊,只不過或多或少而已;神經元包含了值和偏置,而連接的邊則有所謂的權重,除了上述這些,每個神經元還有激勵函數和其有關,這個激勵函數一般是非線性的,如果是線性的就存在一些問題,當然在目前深度學習神經網絡盛行,其激勵函數也可能是線性的,如ReLU及其各種變種,大約常用的有二十多種之多,而非線性的激勵函數主要是Sigmoid、雙曲正切等,而在網絡的輸出部分可能還會用不同的函數類型(這裏考慮的是歸一化問題),主要是Softmax。
另外,特別對於反向傳播神經網絡等分類網絡而言,其最終的評價函數也可以採用不同的形式,比如最爲常見的MSE方法或者交叉熵方法等。
最後對於神經網絡而言,其主要有幾個顯著的特徵,第一爲非線性,第二爲非侷限性,第三是非常定性以及第四爲非凸性;以下就以反向傳播神經網絡爲主要的論述對象。
反向傳播神經網絡
基本結構和目標
 與大部分人工神經網絡類似,反向傳播神經網絡也是被組織成多個層次,以下使用L表示網絡共有多少層,而使用l表示關於層的循環變量,而每一層均有若干個神經元,同層之間的神經元之間沒有任何聯繫(這個與RNN不同,在RNN中同層之間的神經元有連接),第一層和最後一層分別被稱作輸入層和輸出層,而中間的各個層均被稱作隱層,每層之間的神經元是全連接關係(在卷積神經網絡中並非如此),即如果l-1層有N1個神經元,而l層有N2個神經元,則連接的邊有N1* N2條,故總體的連接的邊數爲: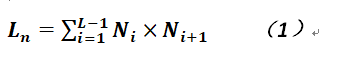
在前文也提到過,對於每個神經元(反向傳播神經網絡中)而言,其中包含有神經元的值和偏置,它們一般爲浮點數,而連接的邊一般具有權重,它們一般也是浮點數,在實際應用中會根據情況將它們的取值範圍約束在0和1之間或者-1和1之間。
除輸入層的神經元之外,每層神經元的取值是通過如下公式獲得的: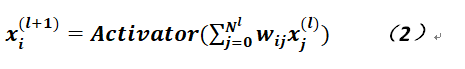
在上式中,等式左邊爲第l+1層的某個神經元,而等式右邊的Activator爲激活函數,一般可以使用Sigmoid或其它類似函數,如常見的三角函數,它的作用是將線性輸出變成非線性的並約束了輸出,而函數內部則是兩層神經元連接的權重乘以相應的上層神經元的值,這裏需要注意的是將偏置轉變成了wi0(沒有使用常見的b),而x0爲1,所以j的下標是從0開始的,其內涵是沒有任何差別的。
如果將公式2寫成向量形式則如下: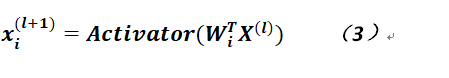
故可以看出公式3更爲簡練一點,而且可以從向量空間(其實可能更爲準去地說是賦範空間,這裏對於角度反而沒什麼要求)的角度理解神經網絡的結構,其實每一層都是一個來自與實數積空間的一個向量,只不過每層的維度不太一樣罷了。
 那麼對於一組輸入樣本,反向傳播神經網絡的目標一般是爲了進行分類,故令樣本的個數爲N,每個樣本都有分類標籤,我們將其記爲(xk,yk),在這裏輸入的樣本一般是向量,而輸出的一般也是向量,而分類標籤基本上標量,則我們可以將其擴張成One-hot的向量,比如對於MNIST庫手寫數字的識別,可以將標籤從0,1,2,...,9改成諸如(1,0,0,0,0,0,0,0,0,0)的向量,上邊這個向量代表數字0。 再對標籤進行向量化後,我們就可以非常方便的指定目標函數。對於分類任務,我們希望最後的結果就是總體輸入樣本和最終分類的距離越小越好,故可以想見只要整體距離近乎爲0,這裏可以取賦範空間的相關範數進行計算,期望如下: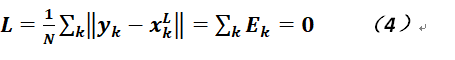
其中x_k^L是最後一層、也就是輸出層的輸出向量,顯然它應和樣本標籤在同一個空間中(即至少維度是相同的),而Ek也就是分類的誤差。當然,我們肯定希望是沒有誤差最好,但這隻能是美好的願望(至少在反向傳播神經網絡中是如此)。
在實際應用中,這個範數當然可以取空間的1範數或無窮範數,但是由於它們是不可導的,故常用2範數,那麼公式4就可以變成如下形式(加入1/2也只是爲了消去常數):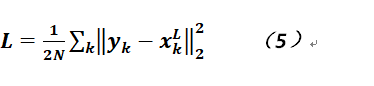
以下就是對公式5的求導並利用梯度下降法逼近各個參數,這些參數也就是各個連接邊的權重以及神經元的偏置。
反饋
 其實所謂反饋的目的就是爲了調整各個參數,使之達到最優化,其具體手段不外對這些參數求導並利用梯度下降法進行;爲了說明清楚,我們再把公式5按照歐氏空間(難道是賦範空間變成了距離空間?)的距離方式再重寫一下,使之更易理解: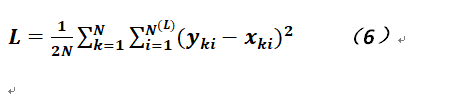
在公式6中,N(L)爲輸出層的神經元數量,其實就是輸出層的維度,那麼如果對上式求取偏導,則不是非常明顯,如果綜合公式2和公式6就能一目瞭然了,爲了不使公式過長,現針對某個樣本、某個輸出神經元給出樣例,則公式如下(僅針對一個樣本,故分母中沒有N):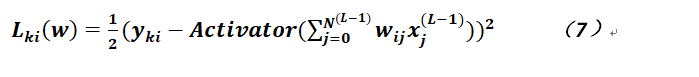
通過上述公式的變形,就可以清晰地看出需要對哪些參數求取偏導,則我們先對連接邊的權重進行,可得: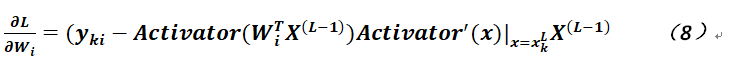
注意在公式8中,爲了方便起見,對於權重是寫成向量形式,而且不包含偏置,即其實是沒有j=0這項的;另外,對於偏置的偏導,則如以下公式: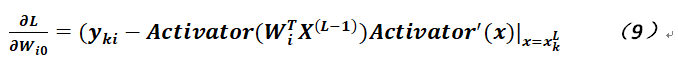
可以看出公式8和公式9差別不是太大,僅僅相差一個上層神經元的值;如果選擇激活函數爲Sigmoid,並用σ記之,由於這個函數有比較好的性質,因爲容易計算,其導數爲:σ(x) (1-σ(x)),故可將公式8和公式9改寫成如下形式: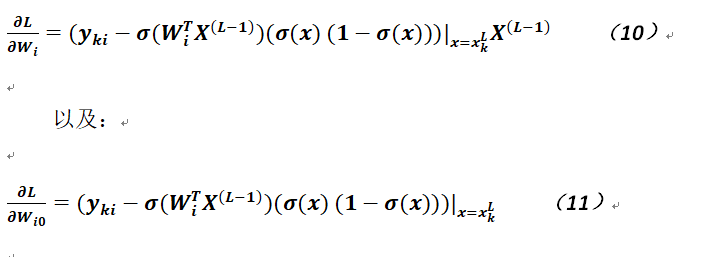
通過以上相關的推導,就能得到各個參數的偏導,則利用梯度下降法分別可以得到相關參數的更新公式,如下: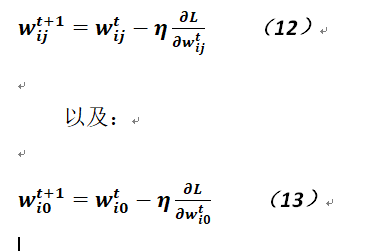
在以上公式中,η被稱作學習率,一般是一個小於1的正實數,但在網絡訓練初期,這個學習率不宜取得的太小,這樣可以加快模型的收斂速度,但在經過若干次迭代後,爲了減少抖動,可以將其慢慢變小,也就是說學習率可以不必是一個固定數值,可以取其對迭代次數的減函數。
當然,需要說明的一點是相關參數的更新肯定不是訓練完一個樣本就立即更新,而一般是對所有樣本訓練完後再更新一次,或者爲了加快收斂速度,也可以訓練完一個樣本子集就更新,這時在編寫程序中應注意保留這些參數變化的結果(一般把它們加起來就可以了),然後在變更參數時,將變化和除以被訓練樣本的數量即可。
讀者看過上述的推導後,可能會產生一個疑問,因上面的過程中實際上只涉及到了輸出層到最後一個隱層之間的關係,而沒有從輸出層逐層觸發到輸入層和第一個隱層之間的關係,其實這個推導也比較簡單,就是如果隱層越多則公式越長,這裏做個比喻,這個遞推公式就像是一棵樹的結構,而不是線性的;以下再給出最後一個隱層到倒數第二個隱層(如果網絡中確實存在,即神經網絡至少是四層的)的變化公式: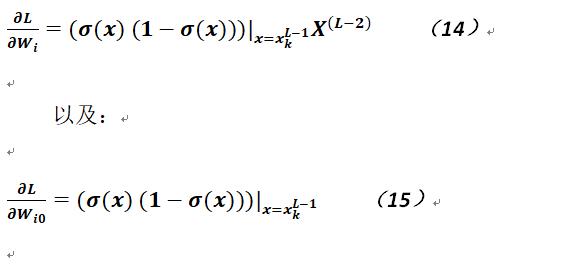
需要注意的是,上述公式中的參數是最後一個隱層和倒數第二個隱層之間連接的邊的權重,這個與公式10和11不同(因爲顯然那是最後一個隱層和輸出層各神經元連接的邊的權重),如果還有其它隱層,則公式的形式完全一樣,這裏其實可以明確看出公式10和14是乘積求和的關係,因爲下一層神經元的取值恰恰來自於上一層所有神經元的取值。故可以想見所謂梯度消失是怎麼來的(針對多個隱層而言),因爲激活函數的導函取數一般是小於1的(如果使用Sigmoid),故在連乘多次後,值將趨近於零,這將導致梯度(即變化情況)無法傳導到網絡中前面的相關隱層,所以在多次迭代後仍無法收斂,而如果採用其它的激活函數則可能造成梯度爆炸(即每次計算的導函數值一般都大於1),不過解決梯度爆炸要比解決梯度消失略好,因爲可以給出一個梯度變化的上限值。
所以通過上述分析,可以看出爲什麼基於反饋的神經網絡沒有太深層次的,最一般的應用一般也就是三層,即只包含一個隱層,而超過五層的網絡幾乎無法訓練或使用;那麼這時提高網絡分類準確性的辦法則只有增加隱層神經元的數量這一幾乎是唯一的途徑,故其在上個世紀一度走入了死衚衕。
算法基本流程
對於反向傳播神經網絡的實現而言,一般包含如下幾個主要的步驟(其實可能大多數人工神經網絡算法也都包含這幾步),其一是將訓練數據進行一些處理,比如讀入、整理或歸一化等,在一些常用的機器學習框架中就直接包含了這些內容,如Tensorflow、R、Caffe等;其二爲正向運算,即從網絡的第一層開始,逐層進行運算,當然這是在對各參數進行初始化基礎上進行的,初始化參數可以利用均勻分佈在-1到1的區間上或者0到1的區間上生成;其三自然就是從輸出層逐層向前進行反饋。
在訓練完一次樣本集後,對各個參數並進行重新訓練,如此反覆進行,一直到滿足的精度爲止或者達到迭代的上限。而訓練萬網絡後,可利用測試數據對網絡的分類能力進行驗證,用錯誤分類的樣本個數除以測試樣本總數即可得到分類的準確性,具體如下:
總體流程
算法:訓練反向傳播神經網絡
輸入:規格化後的N個樣本
輸出:反向傳播神經網絡(主要是各層連接邊的權值及其偏置)
初始化各層的相關參數,即對於層變量l=2,3...,L而言,用隨機數初始化w_ij^l向量(這裏j從0開始,爲偏置);令T爲迭代次數上限,t爲迭代次數;令E爲誤差下限,e爲誤差;
while(t < T or |e| > E) {
for(x_k∈X) {
正向傳遞計算;
計算誤差並累計至中間變量;
反向傳播;
}
e =累計誤差除以樣本總數;
按公式調整相關權值參數及偏置;
t = t+1;
}正向傳遞
 相較於反向傳播而言,樣本點的正向傳遞算法相更加直觀些,其主要就是利用公式3對層間相關神經元相互關係進行計算並將每次的計算結果保存,以下算法假定神經元的激活函數就是Sigmoid,則相關計算方法如下(注意第一層爲0,每層的神經元下標也是從0開始):算法:反向傳播神經網絡正向計算
輸入:一個樣本點及L層帶權神經網絡
輸出:神經網絡輸出向量
for(l = 1;l < L; l++) {
for(i = 0; i < N(l); i++) {
neuron[l][i].value = 0;
for(j=0; j < N(l-1); j++){
neuron[l][i].value += w[i][j]*neuron[l-1][j].value;
}
neuron[l][i].value = σ (neuron[l][i].value+ neuron[l][i].bias);
}
}反向傳播
 對於反向傳播而言,顧名思義就是從網絡的最後一層開始,逐層向前推進,計算各個參數需要調整的數量,並暫時累計之,待訓練完一個迭代後統一調整並在下一個迭×××始前清除累積量。算法:反向傳播神經網絡逆向反饋計算
輸入:一個樣本點及L層帶權神經網絡
輸出:待調整參數偏差累計和(對於一個樣本點而言暫時不會調整各個參數)
// 累計誤差,使用歐式距離
e += (y_k-x_k )^T (y_k-x_k);
for(l = L-1;l > 0; l--) {
for(i = 0; i < N(l); i++) {
for(j = 0; j < N(l-1); j++) {
// 如果是最後一層
if(l == L-1) {
// 累計權重變化
w[i][j].delta_weight_sum += (y_ki-σ(W_i^T X^((l-1) ))(σ(x) (1-σ(x)))|_(x=x_k^L ) X^((l-1) );
} else {
// 如果是其它層
// 累計權重變化
w[i][j].delta_weight_sum += (σ(x) (1-σ(x)))|_(x=x_k^l ) X^((l-1) );
}
} // end of for j
// 累計偏置變化
if(l == L - 1) {
neuron[l][i].delta_bias_sum += (y_ki-σ(W_i^T X^((l-1) ))(σ(x) (1-σ(x)))|_(x=x_k^L );
} else {
neuron[l][i].delta_bias_sum += (σ(x) (1-σ(x)))|_(x=x_k^l );
}
} // end of for i
} 由於上述算法都是對於相關參數的變化量累計值而言的,故在最後調整參數時應該將這些累積量除以樣本的總數;另外,在實際實現時應注意偏置是跟隨神經元的(輸入層沒有偏置),而神經元之間的連接則可以採用單獨的變量進行記錄或者也可以將其放入神經元數據結構之中。其它
 如果讀者自己實現一個反向傳播的神經網絡會發現其實它的計算還是相當耗時的,尤其在樣本很多(如MNIST就包含5萬個訓練樣本和1萬個測試樣本,而新的圖形庫也相當巨大)而且迭代次數較高時(比如至少迭代2000次)整體訓練過程就會比較長,這時可以考慮使用多線程的併發訓練或這乾脆使用分佈式訓練,另外使用CUDA也可以在很大程度上縮短訓練的時間,但CUDA畢竟存在一定侷限性(必須是NIVIDA的顯卡),而且在虛機上不一定有效。
 當採用多線程併發或者分佈式訓練,一般可以將大的樣本集進行一定粒度的切分,然後定期對參數進行統一調整並再次同步或下發這些參數。
 最終訓練好的網絡可以採用XML格式或者JSON格式存儲,在加上序列化和反序列化接口就能較好地進行實用了。
 另外,在計算整體誤差時,也可以不使用平方差公式,而採用交叉熵的形式進行,其公式如下:

 在上式中,p爲神經網絡輸出層的維度,ln爲自然對數,當然在實現時要避免其值小於等於零,否則是沒有意義的,故選擇何種激勵函數、參數初值就變得尤爲重要,如若不然會得到很多錯誤。優化方法
 在按本文的相關方法或者類似的方法,實際實現基於反向傳播的人工神經網絡時,會發現可能實際效果並不是特別理想,其準確了可能盡在百分之九十左右徘徊,即沒有你使用Tensorflow等框架在同樣的數據集上獲得的效果理想,這個也是比較正常的結果。
 因爲我們暫時還沒有考慮其它一些相關的優化方法。在對數據進行訓練時可能會出現一些所謂的過擬合及欠擬合現象,而尤以前者最爲常見。過擬合(Overfitting)的原因比較複雜,其主要表現是在訓練的時候準確率較高,當網絡應用在訓練數據以外的數據時,表現較差;它的產生可能有如下原因,第一爲訓練數據不足或樣本標籤錯誤,第二爲數據中可能存在較大的噪音,第三迭代次數過多,存在過分訓練(Overtraining)的因素。下面簡單地給出幾種解決的方案或思路,以對抗過擬合。正則化
 首先,回憶下我們在對一般線性迴歸模型的參數求解中遇到的相關問題及解決方法,即可以在一般線性迴歸模型中使用LASSO迴歸和嶺迴歸,同樣地我們可以在反向傳播神經網絡的誤差評估函數中同樣使用1-範數和2-範數正則化手段,即將公式6和公式16分別變形爲如下形式(2-範數,即使用類似嶺迴歸的方法):
在使用這個所謂正則化方法時,如果採用LASSO迴歸則由於其目標函數在零點處不可導,故需要進行一些特殊處理(如使用軟閾收縮算子),而對於嶺迴歸則沒有這種問題,但LASSO方法的效果要略爲好些;另外,在上面四個公式中,w是針對網絡中的所有權值而言的,而不僅僅是某層和某層之間的連接邊的權重;而且,由於評估函數發生了變化,則其導函數相關的計算方法也會相應地產生一點點差異,這裏需要注意。λ被稱作正則化參數,其取值一般是大於1的,經驗表明可以取5。
隨機丟棄
 除了上述正則化方法可以對神經網絡的訓練結果產生一些積極地變化外,我們還可以對各個神經元進行一些修改,這種修改的方法被稱作Dropout。所謂Dropout就是在對神經網絡進行訓練時,可以以一定的概率使網絡中的神經元處於無效狀態,當然這個過程主要是在反向傳播的階段,即隨機進行梯度的傳播,每次好像都在訓練一個不同的網絡。而且這種方法的好處還在於可以縮短訓練的時間(因爲神經元只是原來的子集,數量上減少了)。
 在使用Dropout方法時,可以採用伯努利分佈,其參數就選擇0.5,即每次隨機丟棄50%的神經元,經驗表明(又是經驗!)選擇這個參數效果最好。Dropout技術本身比較簡單,這裏就不給出更多描述了,在各個開源框架中也有相應的實現,而且如果自己實現這個方法也並不複雜。數據擴展
 另外,針對訓練樣本的不足而造成的過擬合,我們可以採用人工生成訓練數據的方法來克服這個問題,即對已有訓練數據實施縮放、旋轉(線性方法)、輕微變形(非線性方法)等手段來擴充訓練數據,這個對於圖形的識別具有較好的效果。結語
 通過本文簡單地對反向傳播神經網絡的描述,讀者可能可以感受到這類基於神經網絡的機器學習算法確實沒有非常強的數學基礎(至少很多問題無法說清楚,可能更多是依賴直覺?),這點和支持向量機略有不同(支持向量機本身就具有嚴格的數學基礎,推導過程也是絲絲入扣),在實際使用中經常也是需要針對不同的應用場景對各類參數的組合進行各種各樣地調整,這個在卷積神經網絡、循環神經網絡(RNN,即Recurrent Neural Network,最主要的變體是長短時記憶網絡,即LSTM)或遞歸神經網絡(也是RNN,不過這裏的R是Recursive的首字母,結構上有些不同)中也是極爲常見的,故訓練的時候還是需要珍惜機器時間。
 另外,由於反向傳播神經網絡在歷史上存在着梯度消失或梯度爆炸問題,故神經網絡在很長的一段時間內幾乎銷聲匿跡了,但隨着相關解決辦法的提出以及硬件的發展,深度學習目前成爲最爲熱門的技術,而在深度神經網絡中除了使用Dropout等技術外,還使用了一些線性的激勵函數,這使深度成爲可能,甚至100多層的網絡也很多見,這個是在以前無法想象的。近期,Hinton教授又宣稱可以不用反饋來訓練網絡,而是採用一種被稱作膠囊(Capsule)的技術來進行,這個可能也是非常令人期待的東西。
 最後推薦一個網站的內容:http://neuralnetworksanddeeplearning.com,這個網站上面的內容要更爲詳細和豐富,從某種程度上來說,可能詳細得有點多餘了,不過這個詳細程度只針對反向傳播神經網絡而言,對於其它深度學習的神經網絡並不詳細,不過還是建議耐心閱讀,不知是否有翻譯過來的書?