




把 Excel 文件導入關係數據庫是數據分析業務中經常要做的事情,但許多 Excel 文件的格式並不規整,需要事先將其中的數據結構化後再用 SQL 語句寫入數據庫。而一般情況下,結構化的工作量會比較大,而且很難通用,每次都要針對文件格式進行分析後再進行開發。
集算器的 SPL 語言是一款高效、靈活的工具,它能夠輕鬆讀取 excel 數據,然後結構化成“序表”後導入數據庫。使用 SPL 語言後,以往需要編寫數千行代碼才能完成的 Excel 數據結構化入庫工作,現在只需要不到 10 行代碼就可以勝任,簡單情況下甚至只需要 2、3 行代碼!真的這麼神奇嗎?下面就來看看神奇之處吧
10行代碼提取複雜Excel數據
下面我們將分情況討論如何利用集算器將Excel數據進行結構化。文中用到的函數請參看集算器文檔《函數參考》。
1. 普通行式
先看最簡單的情況:如下圖所示,Excel文件中第一行是列標題,從第二行開始,每行是一條數據記錄。
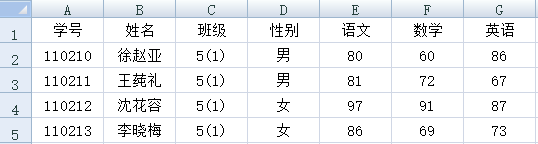
集算器處理這種文件也非常簡單:
A | |
1 | =file( "學生成績表.xlsx" ).xlsimport@t() |
2 | =connect("demo") |
3 | =A2.update(A1,xscj) |
A1 打開“學生成績表.xlsx”文件並導入成序表,選項@t表示文件第一行是列標題
A2 連接demo數據庫
A3 將A1中的序表存入到demo數據庫的xscj表中,由於表中的列名和序表中的字段名一樣,所以只需指定數據表名即可。update函數的更詳細用法請查閱函數文檔。
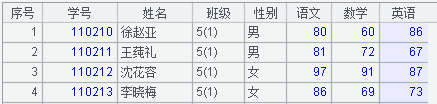
A1中得到的序表如下圖所示:
A2、A3兩步連接數據庫和將序表存入數據庫的方法是通用的,所以後面的例子中將不再寫這兩步,只關注於如何把Excel中的數據結構化成序表。
2. 多行表頭行式
大多數時候,Excel文件都不會象上例那麼簡單,表頭往往比較複雜,有表名、項目名、頁碼、填表人、填寫日期等等。比如這個樣子:

對於這種表,我們在讀取時就要跳過表頭,直接從數據行開始讀。
A | |
1 | =file( "措施項目清單與計價表.xlsx" ).xlsimport(;1,5) |
2 | =A1.rename(#1:序號,#2: 項目編碼,#3: 項目名稱,#4: 計量單位,#5: 數量,#6: 單價,#7: 合價 ) |
A1 打開文件並導入數據成序表,參數“1,5”表示讀第一個 sheet,從第 5 行開始讀,一直讀到文件結尾
A2 將 A1 中讀到的序表列名依次改爲“序號、項目編碼、項目名稱、計量單位、數量、單價、合價”,即要存入的數據表的列名。
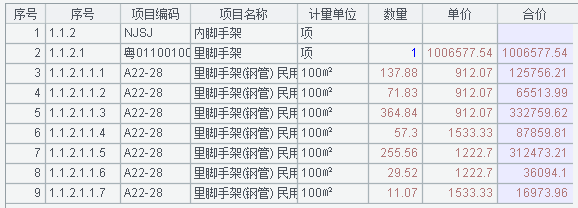
運行後 A2 中的序表如下:
3. 自由格式
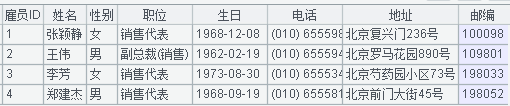
有時Excel文件的數據並不是網格式的規則表,而是字段名後緊跟着字段值的自由格式,如下圖的僱員信息表:
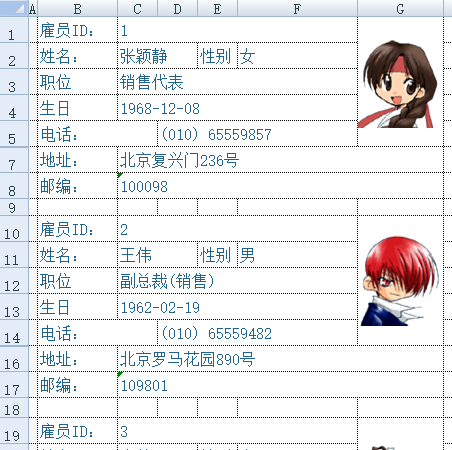
每個僱員信息佔據9行,依次往下排列。對這種文件,該怎麼結構化呢?請看:
A | B | C | |
1 | =create(僱員 ID, 姓名, 性別, 職位, 生日, 電話, 地址, 郵編 ) | ||
2 | =file("僱員信息表.xlsx").xlsopen() | ||
3 | [C,C,F,C,C,D,C,C] | [1,2,2,3,4,5,7,8] | |
4 | for | =A3.(~/B3(#)).(eval($[A2.xlscell(]/~/")")) | |
5 | if len(B4(1))==0 | break | |
6 | >A1.record(B4) | ||
7 | >B3=B3.(~+9) | ||
A1 創建列名爲“僱員 ID, 姓名, 性別, 職位, 生日, 電話, 地址, 郵編”的空序表
A2 打開 Excel 數據文件
A3 定義僱員信息所在單元格列號序列
B3 定義僱員信息所在單元格行號序列
A4 用 for 循環讀取每個僱員信息
B4 A3.(~/B3(#))先算出當前僱員單元格編號序列, 再讀出這些單元格值組成僱員信息序列。第一次循環時爲 [C1,C2,F2,C3,C4,D5,C7,C8],第二次循環時爲[C10,C11,F11,C12,C13,D14,C16,C17]……每次行號加 9。$[A2.xlscell(] 與 "A2.xlscell(" 相同,都是表示一個字符串,它的好處是在 IDE 中編寫程序時,如果 A2 單元格的編號發生了變化,$[A2.xlscell(]中的 A2 會自動變化,比如在 A2 前插入了一行,這個表達式就會變成 $[A3.xlscell(],而用引號的話,就不會自動變了。
B5 判斷僱員 ID 值是否爲空,爲空則退出循環,結束運行
B6 將一條僱員信息存入 A1 序表尾
B7 讓僱員信息的行號序列都加上 9,讀取下一條僱員信息
運行後得到的 A1 序表如下:
4. 交叉表
Excel中還有交叉表格式的數據,如下圖:
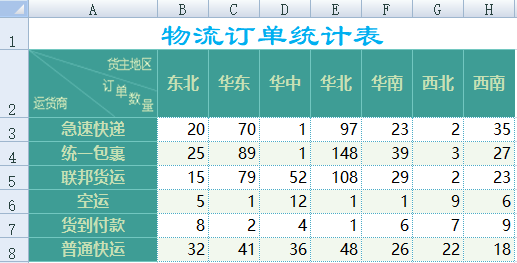
數據結構化程序如下:
A | |
1 | =file("交叉表.xlsx").xlsimport@t(;1,2) |
2 | =A1.rename(#1:運貨商) |
3 | =A2.pivot@r(運貨商;貨主地區,訂單數量) |
A1 打開文件並導入數據成序表,參數“1,2”表示讀第一個 sheet,從第 2 行開始讀,一直讀到文件結尾。選項 @t 表示開始行是列標題。
A2 由於第二行第一個單元格是圖片,讀的數據爲 null,第一列沒有列標題,所以將第一列列名改爲運貨商。
A3 以運貨商爲分組,對序表數據進行行列轉換,選項 @r 表示將列數據轉換爲行數據,轉換後新的列名分別爲“貨主地區”、“訂單數量”。
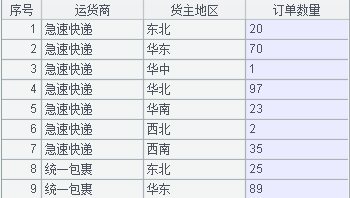
運行後得到的 A3 序表如下:
5. 主子表
在下圖所示的員工信息登記表中,除了有員工本人的信息外,還有他的家庭成員信息。每個 sheet 保存一個員工的相關信息,所以有多少員工,就有多少個 sheet。

對這種主子表結構的數據,需要創建兩個序表分別保存主表和子表的數據,集算器程序如下:
A | B | C | |
1 | =create(×××號,姓名,性別,出生日期,民族,手機號,部門,家庭地址,婚姻狀況,入職時間) | ||
2 | =create(×××號,姓名,關係,工作單位,聯繫電話) | ||
3 | [B4,B3,D3,F3,H3,F4,H4,B5,F5,H5] | ||
4 | =file("員工信息表.xlsx").xlsopen() | ||
5 | for A4 | ||
6 | =A3.(eval($[A4.xlscell(]/~/",\""/A5.頁名/"\")")) | >A1.record(B6) | |
7 | =A4.xlsimport@t(家庭成員,姓名,關係,工作單位,聯繫電話;A5.頁名,6) | ||
8 | =B7.rename(家庭成員:×××號) | >B8.run(×××號=B6(1)) | |
9 | >A2.insert@r(0:B8) | ||
A1 創建列名爲“×××號, 姓名, 性別, 出生日期, 民族, 手機號, 部門, 家庭地址, 婚姻狀況, 入職時間”的空序表,用於保存主表員工信息
A2 創建列名爲“×××號, 姓名, 關係, 工作單位, 聯繫電話”的空序表,用於保存子表員工家庭成員信息
A3 定義主表員工信息所在單元格序列
A4 打開 Excel 數據文件
A5 循環讀取 Excel 文件各 sheet 數據
B6 讀取員工信息序列
C6 將 B6 讀取的員工信息保存到序表 A1
B7 從第 6 行開始讀取員工家庭成員信息,只讀指定的“家庭成員, 姓名, 關係, 工作單位, 聯繫電話”5 列
B8 將 B7 序表的家庭成員列改名爲×××號
C8 爲 B8 序表的×××號列賦值爲員工信息中的×××號
B9 將 B8 中的員工家庭成員信息保存到序表 A2
程序運行後,序表 A1 如下圖所示:

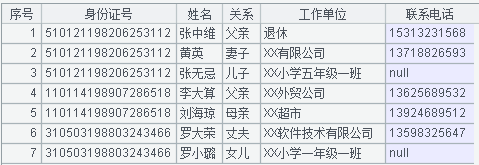
序表 A2 如下圖所示:
上面這些情況基本羅列了常見的 Excel 數據格式,如果遇到更復雜的文件,也可以靈活使用例子中的技巧予以應對。簡單總結一下,集算器提供了非常靈活的在 excel 文件中定位和讀取數據的功能,既可以成片讀取網格數據,也可以精確定位單元格進行讀取。再結合特有的“序表”對象,以往需要編寫數千行代碼才能完成的 Excel 數據結構化入庫工作,現在只需要不到 10 行代碼就可以勝任,簡單情況下甚至只需要 2、3 行代碼!