




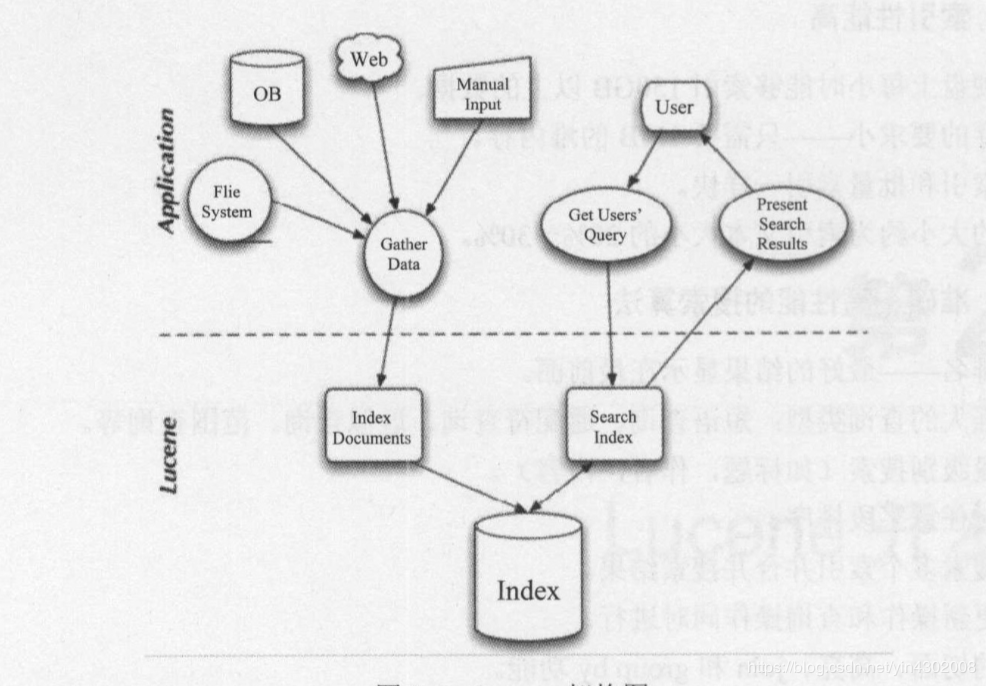
先整體上看一下Lucene的架構設計圖(見下圖),先看上層應用,首先是信息採集的過程,文件系統、數據庫、萬維網以及手工輸入的文件都可以作爲信息採集的對象,也是要搜索的文檔的來源,採集萬維網上的信息一般使用網絡爬蟲。完成信息採集之後到Lucene層面有兩大任務:索引文檔和搜索文檔,索引文檔的過程完成由原始文檔到倒排索引的構建過程,搜索文檔用以處理用戶查詢。應用層的第三部分就是用戶接口,用戶輸入查詢關鍵字,Lucen完成文檔搜索任務,經過分詞、匹配、評分、排序等一系列過程之後返回用戶想要的文檔。
一次完整的搜索從用戶輸入要查詢的關鍵詞開始到系統根據用戶輸入的關鍵字返回相關信息。一次檢索大致可分爲4步:
第一步:查詢分析
正常情況下用戶輸入正確的查詢,例如輸入“python”這個關鍵詞,用戶輸入正確完成一次搜索,但是搜索需求通常都是全開放的,任何的用戶需求都是有可能的,很大一部分還是非常口語化和個性化的,有時候還會存在拼寫錯誤,假如不小心把”python“達成“pythno”,這個時候就需要用自然語言處理技術來做拼寫糾錯等處理,以正確理解用戶需求。
第二步:分詞技術
這一步利用自然語言處理技術將用戶輸入的查詢語句進行分詞,如標準分詞會把“lucene,全文檢索框架”分成lucene|全|文|檢|索|框|架,空格分詞會分成:lucene,|全文檢索框架|,二分法會變成:lucene|全文|文檢|檢索|索框|框架|,還有簡單分詞等多種分詞方法。
第三步:關鍵字檢索
提交關鍵詞後在倒排索引庫中進行匹配,倒排索引就是關鍵詞和文檔之間等對應關係,就像給文檔貼上標籤。比如文檔集中含有lucene關鍵詞的有文檔1,文檔6,文檔9,含有全文檢索的有文檔1、文檔6,那麼做與運算,同時含有lucene和全文檢索的文檔的就是1和6,在實際的搜索中會有更復雜的文檔匹配模型。
第四步:搜索排序
對多個相關文檔進行相關度計算、排序,返回給用戶檢索結果。