




一、日誌監控概述
二、ElasticSearch簡介
三、安裝
四、API簡介
五、配置文件詳解
六、插件
一、日誌監控概述
1、日誌處理常見的流程
日至收集->數據通道[傳輸]->處理[數據清洗]-->存儲[持久化]>數據可視化
日誌收集:日誌爲半結構化數據,
常見收集客戶端軟件:logstash,Fluentd,Logtail,rsyslog,FileBeat... //在日誌收集方也可以設置感興趣的日誌(定製化)
pull:拉取,爬蟲
push:推送,別人推送過來
數據通道:可以直接發送到處理方,或者使用消息隊列解耦
存儲:HDFS、NFS、HBase、ES自身... ;MySQL使用最左側索引模糊查詢性能不行。
全文索引:任何一個文字進行索引,還可以進行模糊匹配
處理和可視化:
- ELK:ELasticSearch提供搜索、分析、存儲三大主要功能,kibana提供可視化界面
- jstorm/storm:
- Flume:Flume支持在日誌系統中定製各類數據發送方,用於收集數據;同時,Flume提供對數據進行簡單處理,並寫到各種數據接受方(可定製)的能力。 Flume-ng/Flume-og功能差異較大,注意區分
- SkyEye:對java、scala等運行於jvm的程序進行實時日誌採集、索引和可視化,對系統進行進程級別的監控,對系統內部的操作進行策略性的報警、對分佈式的rpc調用進行trace跟蹤以便於進行性能分析
- Scribe:Facebook開源的日誌收集系統,在Facebook內部已經得到大量的應用,分佈式收集,統一處理
- Log Parser:微軟的日誌分析工具
- ...
常見架構組合方式:
- flume+kafka+storm+mysql
- Flume+HDFS+KafKa+Strom
- logstash+ElasticSearch+Kibana
- logtail+jstorm+HBase
本文重點介紹ELK模型
2、監控分類
應用監控:APM產品
- google:dapper
- twitter: zipkin (開源)
- 淘寶:鷹眼
- 京東:hydra (開源)
- 大衆點評:CAT (開源)
- 小米:open-falcon (開源)
- ...
日誌監控:
ELK...
前端監控:
- 聽雲 https://report.tingyun.com
- 360分析 https://fenxi.360.cn
- 百度監控 https://tongji.baidu.com
- 奇雲測 http://ce.cloud.360.cn
- 其他...
二、ElasticSearch簡介
1、搜索引擎
Lucene、Solr、Elasticsearch、Sphinx、LIUS、Egothor、Xapian、ComPass...
常用的搜索引擎:Lucene、Solr、ELasticsearch、Sphinx
Lucene:
- 優勢:成熟、社區活躍、所有的擴展,分佈式,可靠性等都需要自己實現;
- 缺點:非實時,從建索引到可以搜索中間有一個時間延遲,而當前的“近實時”(Lucene Near Real Time search)搜索方案的可擴展性有待進一步完善
Solr:基於Lucene的全文搜索服務器- 優點:成熟、穩定、社區活躍;文檔通過Http利用XML加到一個搜索集合中;支持添加多種格式的索引,如:HTML、PDF、微軟 Office 系列軟件格式以及 JSON、XML、CSV 等純文本格式
- 缺點:建立索引時,搜索效率下降,實時索引搜索效率不高
Elasticsearch:基於Lucene構建的開源,分佈式,RESTful搜索引擎- 優勢:使用Lucene作爲其核心來實現所有索引和搜索的功能,目的是通過簡單的RESTful API來隱藏Lucene的複雜性,從而讓全文搜索變得簡單 Elasticsearch是分佈式的。不需要其他組件,分發是實時的,被叫做”Push replication”
- 缺點:還不夠自動(不適合當前新的Index Warmup API)
Elasticsearch對比Solr
- Solr 利用 Zookeeper 進行分佈式管理,而 Elasticsearch 自身帶有分佈式協調管理功能;
- Solr 支持更多格式的數據,而 Elasticsearch 僅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重於核心功能,高級功能多有第三方插件提供;
- Solr 在傳統的搜索應用中表現好於 Elasticsearch,但在處理實時搜索應用時效率明顯低於 Elasticsearch。
總之,Solr 是傳統搜索應用的有力解決方案,但 Elasticsearch 更適用於新興的實時搜索應用。
圖片搜索引擎:lire 使用Lire(基於Lucene)索引並搜索圖片:http://my.oschina.net/cwalet/blog/55502 ;http://www.lire-project.net/
2、Lucene概述
Lucene是最高效的開源搜素引擎框架。但是使用起來較爲複雜,Elasticsearch作爲一個應用程序使用 Lucene 作爲內部引擎進行以下工作:
1)分佈式的實時文件存儲,每個字段都被索引並可被搜索
2)分佈式的實時分析搜索引擎
3)可以擴展到上百臺服務器,處理PB級結構化或非結構化數據
Lucene:索引鏈,沒有前端界面,不獲取文檔
構件查詢,讀取結果,運行查詢
ElaticSearch:搜索引擎的前端,核心是Lucene
索引,文檔分析,構件文檔等
Lucene: 提供了完整的查詢引擎和索引引擎,部分文本分析引擎;Lucene中,使用這種“倒排索引”的技術,來實現相關映射。
文檔:Document
包含了一個或多個域的容器;
field:value //鍵值對,真正搜索搜索的是value
域:field
有很多選項
索引選項、存儲選項、向量使用選項;//可單獨或組合使用
索引選項:用於通過倒排索引來控制文本是否可被搜索。
//只有成爲索引中的項纔可以被搜索。
Index:ANYLIZED //分析(切詞)並單獨作爲索引項
Index.Not_ANYLIZED //不分析(不切詞),把整個內容當一個索引項
Index.ANYLIZED_NORMS //類似於Index:ANYLIZED,但不存儲token的Norms[加權基準]
Index.Not_ANYLIZED_NORMS //類似於Index:Not_ANYLIZED,但不存儲值的Norms(加權基準)
Index.No:不對此域的值進行索引,因此不被搜索。
存儲選項:是否需要存儲域的真實值
title:this is a Notebook //根據存儲法則,存儲N爲小寫,那展示的時候,展示的是大寫?小寫?
store.YES:存儲真實值
store.NO:不存儲真實值
域向量選項用於在搜索期間控制該文檔所有的唯一項動能完全從文檔中檢索時使用;搜索:
- 查詢Lucene索引時,返回的是一個有序的scoreDOC對象
- 查詢時,Lucene會爲每個文檔計算其score
- lucence:java語言研發
API:
- IndexSearcher:索引搜索入口
- Query及其子類:
- QueryParser:查詢分析器
- TopDocs:lucene每一次返回的對象scoreDoc放在TopDocs數組中;TopDocs:保存查詢結果ScoreDocs中分值較高的前10個
- ScoreDOC:搜索返回的對象
Luence的多樣化查詢
- IndexSearcher中的search方法;
TermQuery:對索引中的特定項進行搜索,Term是索引中的最小索引片段,每個Term包含了一個域名和一個文本值
title: This is a Desk.
owner: Tom Blair
description: this is a desk, it's belong to Tom.
title: This is a table.
`owner:Clinton
description: this is a desk,it's belong to Clinton.
This: 1 2
Desk: 1
table: 2
TermQuery可以指定搜索域爲title中,title中包含Desk
TermRangQuery:可以指定多個域進行搜索,例如在title和descrition中包含Desk
NumericRangQuery:數值範圍搜索,判定其數值大小
PrefixQuery:用於搜索以指定字符串開頭的項,
BooleanQuery:布爾型搜索,用於實現組合搜索,組合邏輯有三種:AND,OR,NOT
PhraseQuery:定義距離範圍,來進行搜索。
WillcardQuery:通配查詢,?,*
FuzzyQuery:模糊查詢,根據模糊程度:Levenshtein距離算法 //距離真實查詢內容有多遠3、相關概念
正排索引:正排索引是指文檔ID爲key(可以理解爲主鍵),表中記錄每個關鍵詞出現的次數,查找時掃描表中的每個文檔中字的信息,直到找到所有包含查詢關鍵字的文檔。
倒排索引:以word作爲關鍵索引表中關鍵字所對應的記錄表項記錄了出現這個字或詞的所有文檔,一個表項就是一個字表段,它記錄該文檔的ID和字符在該文檔中出現的位置情況。
分詞:
不同語言的切詞方式時不同的; 還有同義詞,語法錯誤:,大小寫分析,錯別字等:分析引擎,進行語法分析
倒排索引原理
兩篇文章:
文章1.Tom lives in Guangzhou,I live in Guangzhou too.
文章2.He once lived in Shanghai.
分詞後:
文章1關鍵字爲:[tom][live][guangzhou][i][live][guangzhou]
文章2關鍵字爲:[he][live][shanghai]
加上 出現頻率 和”出現位置“信息後,我們的索引結構爲:
關鍵字 文章號碼[出現頻率] 出現位置
guangzhou 1[2] 3,6
he 2[1] 1
i 1[1] 4
live 1[2],2[1] 2,5,2
shanghai 2[1] 3
tom 1[1] 1
Lucene中,就是使用這種“倒排索引”的技術,來實現相關映射。
基本組件:
- 索引(index):文檔的容器,索引是具有類似特性的文檔的集合。類似於表;索引名必須使用小寫字母;
一個索引(index)就像是傳統關係數據庫中的數據庫,它是相關文檔存儲的地方,index的複數是indices 或indexe- 類型(type):類型是索引內部的邏輯分區,其意義取決於用戶需求,一個索引內部可以定義一個或多個類型。
一般來說:類型就是擁有相同的域的文檔的預定義
//建議在一個索引中存儲一個type的數據。- 文檔(document):文檔是lucene索引和搜索的的原子單位,它包含了一個或多個域,是域的容器,基於JSON格式表示。
每個域的組成部分:一個名字,一個或多個值,擁有多個域的值,通常稱爲多值域
Elasticsearch是面向文檔(document oriented)的,這意味着它可以存儲整個對象或文檔(document)。然而它不僅僅是存儲,還會索引(index)每個文檔的內容使之可以被搜索。
在Elasticsearch中,你可以對文檔(而非成行成列的數據)進行索引、搜索、排序、過濾
- 映射(mapping):原始內容存儲爲文檔之前,需要事先進行分析,例如切詞、過濾某些詞;映射用於定義此分析機制該如何實現
除此之外,ES還爲映射提供了諸如將域中的內容排序等功能。
例如This is a boy //is 和a要不要過濾掉,boy是關鍵字等Relational DB -> Databases -> Tables -> Rows行 -> Columns列 Elasticsearch -> Indices -> Types -> Documents -> Fields
4、ELK概述
ELK stacks:ELK(ElasticSearch, Logstash, Kibana)
Elasticsearch是個開源分佈式搜索引擎,它的特點有:分佈式,零配置,自動發現,索引自動分片,索引副本機制,restful風格接口,多數據源,自動搜索負載等。
Logstash是一個完全開源的工具,他可以對你的日誌進行收集、過濾,並將其存儲供以後使用(如,搜索)。
Kibana 也是一個開源和免費的工具,它Kibana可以爲 Logstash 和 ElasticSearch 提供的日誌分析友好的 Web 界面;可以幫助您彙總、分析和搜索重要數據日誌。
ELasticsearch對lucence拓展:把一個索引,分片,分別存儲到多個節點上
- 對分片進行HA:例如把分片1和分片1的副本,分別存儲在A和C兩個節點上。A就是片1的主節點,c就是片1的從節點片2在B和C上一份,B爲片2的主節點,C爲片2的分節點
- 主從結構:主節點可寫,從節點更新//
- 查詢:每一個節點都知道所有分片所在node,可以幫忙做遞歸
- 寫入:請求對2的寫,API會轉發到2上
5、ES組件
- Cluster:ES的集羣標識爲集羣名稱;默認爲"elasticsearch"。節點基於該名字決定加入到哪個集羣中,一個節點只能屬於一個集羣。
- Node:運行了單個ES實例的主機即爲節點,集羣的成員,用於存儲數據、參與集羣索引、搜索操作。節點的標識靠節點名。
默認會生成隨機子串作爲主機名- Shard:分片,將索引切割成爲的物理存儲組件,但每一個shard都是一個獨立且完整的索引。
創建索引時,ES默認可爲其分割爲5個shard,可以按需定義,創建完成之後不可修改。- Shard有兩種類型:primary shard和replica。用戶可自定義每個primary replica的個數
Replica用於數據冗餘及查詢時的負載均衡,每個主shard的副本數量可以自定義。
主shard的副本數量可以動態修改,但是index的切割shard個數不能動態修改
ES Cluster工作過程:- 啓動時:通過多播(默認)或單播方式,在9300/tcp查找同一個集羣中的其它節點。並與之建立通信。
集羣中的所有節點會選舉出一個主節點負責管理整個集羣狀態,以及在集羣範圍內決定各shards的分佈方式。
站在用戶角度而言,每個均可接受並響應用戶的各類請求。
集羣狀態:green,red,yellow //yellow:修復過程。green正常,red不可用
yellow狀態:各副本shard都不可用,只能使用主shard。讀請求將無法進行LB
主node會檢測所有shard,主shard是否正常,副shard數量是否滿足。假如主shard不在,就修改某個副shard爲主,副本shard不夠,則添加
主節點會週期檢查各個從節點是否可用:
任意一個節點不可用:進入修復模式,重新均衡。 //Mogilefs不會自動進行rebalance,但是 elasticsearch可以自動進行
ES選舉過程:
- 1、集羣已經選舉完畢,新節點會加入然後接受之前的master
- 2、整個master集羣剛開始初始啓動的時候
Bully選舉算法
Leader選舉的基本算法之一。它假定所有節點都有一個惟一的ID,該ID對節點進行排序。 任何時候的當前Leader都是參與集羣的最高id節點
只有一個Leader將當前版本的全局集羣狀態推送到每個節點。 ZenDiscovery(默認)過程就是這樣的:- 1、每個節點計算最低的已知節點ID,並向該節點發送領導投票
- 2、如果一個節點收到足夠多的票數,並且該節點也爲自己投票,那麼它將扮演領導者的角色,開始發佈集羣狀態。
- 3、所有節點都會參數選舉,並參與投票,但是,只有有資格成爲 master 的節點的投票纔有效.
圖1: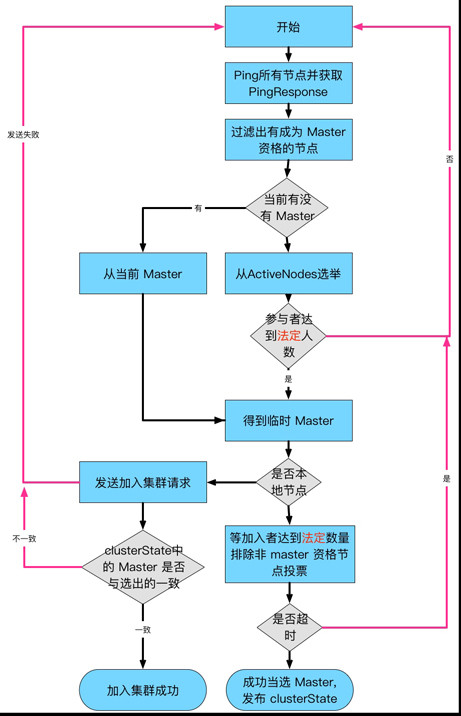
三、安裝
1、環境配置
node1 192.168.192.222
node2 192.168.192.223
node3 192.168.192.224配置java環境變量,不再重複。請自行百度。版本使用新版本
elasticsearch:是用jruby研發 //json java python因此需要先安裝jdk
ruby有cruby和jruby
JDK區分:Oracle JDK和OpenJDK
2、修改ES配置文件
node1配置: elasticsearch.yml
- cluster.name: my-cluster
- node.name: node1
- network.host: 192.168.192.222
- http.port: 9200
- discovery.zen.ping.unicast.hosts: ["node1", "node2", "node3"]
node2配置:
- cluster.name: my-cluster
- node.name: node2
- network.host: 192.168.192.223
- http.port: 9200
- discovery.zen.ping.unicast.hosts: ["node1", "node2", "node3"]
node3配置:
- cluster.name: my-cluster
- node.name: node3
- network.host: 192.168.192.224
- http.port: 9200
- discovery.zen.ping.unicast.hosts: ["node1", "node2", "node3"]
3、啓動
bin/elasticsearch -d 以daemon方式運行
> * ERROR: [2] bootstrap checks failed
> * [1]: max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
> * [2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
針對上面2個報錯
不能用root啓動,否則會報錯
vim /etc/security/limits.conf
ulimit -Hn 查看當前nofile hard limit
ulimit -n 調整
echo $((65530*10)) > /proc/sys/vm/max_map_count 四、API簡介
訪問elasticsearch使用Restful API:
四類API:
- 1.檢查集羣、節點、索引等健康與否,以及獲取其相應狀態
- 2.管理集羣、節點、索引及元數據
- 3.執行CRUD操作:增刪查改
- 4.執行高級操作,例如paging,filtering
ES訪問接口:tcp/9200
curl -X [VERB] PROTOCOL://Host:PORT/path/?Query_STRING -d 'BODY'
VERB:get,put,delete等
PROTOCOL:http,https
QUERY_STRING:查詢參數,例如?pretty表示易讀的JSON格式輸出;
curl -X GET 'http://192.168.192.222:9200/?pretty'
curl -X GET 'http://192.168.192.222:9200/_cluster/health?pretty'
curl -X GET 'http://192.168.192.222:9200/_cat/' //查看cat API的用法
curl -X GET 'http://192.168.192.222:9200/_cat/nodes' //查看node信息
curl -X GET 'http://192.168.192.222:9200/_cat/nodes?v' //verbose顯示
curl -X GET 'http://192.168.192.222:9200/_cat/nodes?help' //幫助
curl -X GET 'http://192.168.192.222:9200/_cat/nodes?h=name,ip,port,uptime,heap,current' //h:head頭部內容
curl -X GET '192.168.192.222:9200/_cluster/stats?pretty=true' //查看集羣性能信息
curl -X GET 'http://192.168.192.222:9200/_cluster/pending_tasks?pretty=true' //查看等待中的任務1、集羣類API
Cluster API:
curl -XGET 'http://192.168.192.222:9200/_cluster/health?level=shards'
curl -XGET 'http://192.168.192.222:9200/_cluster/health?level=indicies&pretty' //並且
curl -X GET 'http://192.168.192.222:9200/_cluster/state/nodes?pretty' //顯示所有狀態node id
1.cluster Health //node健康狀態
2.Cluster State //狀態
curl -X GET 'http://192.168.192.222:9200/_cluster/state/?pretty'
3.Cluster Stats //統計數據
curl -X GET 'http://192.168.192.222:9200/_cluster/stats?pretty'
4.Cluster Reroute //重新路由,對某個查詢重新路由到另外一個節點
5.Cluster Update Settings //更新集羣中的某些事務
6.Nodes Stats
curl -X GET 'http://192.168.192.222:9200/_nodes/stats?pretty' //默認顯示所有node,可以指定顯示的那個node
...
curl -X GET 'http://192.168.192.222:9200/_cluster/health?pretty'
{
"cluster_name" : "my-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}status:
- green:集羣百分百可用
- yellow:所有的主分片已經分片了,但至少還有一個副本是缺失的。不會有數據丟失,所以搜索結果依然是完整的。
- red:至少一個主分片(以及它的全部副本)都在缺失中。數據丟失:搜索只能返回部分數據,而分配到這個分片上的寫入請求會返回一個異常。
number_of_nodes 和 number_of_data_nodes 這個命名完全是自描述的。
active_primary_shards 指出你集羣中的主分片數量。這是涵蓋了所有索引的彙總值。
active_shards 是涵蓋了所有索引的_所有_分片的彙總值,即包括副本分片。
elocating_shards 顯示當前正在從一個節點遷往其他節點的分片的數量。通常來說應該是 0,不過在 Elasticsearch 發現集羣不太均衡時,該值會上漲。比如說:添加了一個新節點,或者下線了一個節點。
initializing_shards 是剛剛創建的分片的個數。比如,當你剛創建第一個索引,分片都會短暫的處於 initializing 狀態。這通常會是一個臨時事件,分片不應該長期停留在 initializing 狀態。你還可能在節點剛重啓的時候看到 initializing 分片:當分片從磁盤上加載後,它們會從 initializing 狀態開始。
unassigned_shards 是已經在集羣狀態中存在的分片,但是實際在集羣裏又找不着。通常未分配分片的來源是未分配的副本。比如,一個有 5 分片和 1 副本的索引,在單節點集羣上,就會有 5 個未分配副本分片。如果你的集羣是 red 狀態,也會長期保有未分配分片(因爲缺少主分片)。
curl -s '192.168.192.222:9200/_cluster/health?level=shards;pretty=true' //查看索引中每個分片的狀態和位置。可以定位是哪些索引異常
Relational DB -> Databases -> Tables -> Rows行 -> Columns列
Elasticsearch -> Indices -> Types -> Documents -> Fields
各種版本API用法:
https://www.elastic.co/guide/en/elasticsearch/reference/index.html
https://www.elastic.co/guide/en/elasticsearch/reference/6.6/index.html2、CRUD之類的API
增加
爲部門(partment)下的銷售部(xiaoshou)建立員工索引,編號爲1
[root@node2 ~]# curl -H "Content-Type: application/json" -X POST '192.168.192.223:9200/partment/xiaoshou/1?pretty' -d '
{
"first_name":"zhong",
"seconde_name":"guo",
"gender":"Male",
"age":26,
"interests": [ "sports", "music" ]
}'索引名:partment
類型名:xiaoshou
文檔:1
注意:如果不添加Content-Type: application/json 可能會報錯406
[root@node2 ~]# curl -H "Content-Type: application/json" -X POST '192.168.192.223:9200/partment/xiaoshou/2?pretty' -d '
{
"first_name":"Rong",
"last_name":"Huang",
"gender":"Female",
"age":23,
"courses":"Luoying Shenjian"
}'查看文檔
[root@node3 ~]# curl -XGET '192.168.192.222:9200/partment/xiaoshou/2?pretty' //查看更新文檔
PUT方法會覆蓋原有文檔
如果只更新部分內容:使用_update API
[root@node3 ~]# curl -H "Content-Type: application/json" -XPOST '192.168.192.222:9200/partment/xiaoshou/2/_update?pretty' -d '
{
"doc":{ "age":28 }
}'
[root@node3 ~]# curl -XGET '192.168.192.222:9200/partment/xiaoshou/2?pretty' //再次查看刪除文檔
curl -XDELETE '192.168.192.222:9200/partment/xiaoshou/2'刪除索引
curl -XGET '192.168.192.222:9200/_cat/indices?v' //查看索引
curl -XDELETE '192.168.192.222:9200/students' //刪除索引五、配置文件詳解
elasticsearch.yml 主配置文件
jvm.options jvm參數配置文件
log4j2.properties 日誌配置文件
elasticsearch.keystore SSL相關
配置文件參考:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules.html
API方式修改配置:https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-update-settings.html
1、elasticsearch.yml參數分類
Cluster-level routing and shard allocation //設置shard如何分配
Discovery //node之間的發現規則
Gateway //集羣內有多少個node存活纔可以恢復
HTTP //設置http restful接口
Indices //全局索引相關配置
Network //默認網絡配置
Node client //node作爲非data node或者作爲master node加入集羣
Painless //用於ElasticSearch的內置腳本語言,旨在儘可能安全。
Plugins //插件
Scripting //自定義腳本在Lucene表達式、Ad groovy中可用。您也可以用內置的腳本語言編寫腳本,非常簡單。
Snapshot/Restore //使用快照/還原備份數據
Thread pools //線程池設置
Transport //內部node之間的傳輸層配置
Tribe nodes //一個節點在多個es集羣中伴有角色
Remote clusters //遠程集羣用於在傳輸層上跨集羣連接的功能中。
Cross-cluster search //跨集羣搜索允許跨多個集羣執行搜索請求,而無需加入它們,並在它們之間充當聯合客戶機。 2、示例說明
cluster.name: es6.2 //集羣名稱
node.name: node-1 //node名稱
node.master: true //允許一個節點是否可以成爲一個master節點,es是默認集羣中的第一臺機器爲master,如果這臺機器停止就會重新選舉master. 任何主節點的節點(默認情況下所有節點)都可以被主選舉過程選爲主節點。
node.data: true //允許該節點存儲數據(默認開啓)
注意:主節點必須有權訪問該data/目錄(就像data節點一樣 ),因爲這是集羣狀態在節點重新啓動之間持續存在的位置。
node.ingest:true //
search.remote.connect:true //開啓跨羣集搜索(默認啓用)
# 配置文件中給出了三種配置高性能集羣拓撲結構的模式,如下:
# 1. 如果你想讓節點從不選舉爲主節點,只用來存儲數據,可作爲數據節點
# node.master: false
# node.data: true
# node.ingest: true
# 2. 如果想讓節點成爲主節點,且不存儲任何數據,並保有空閒資源,可作爲協調器
# node.master:true
# node.data:false
# node.ingest:false
# 3. 如果想讓節點既不稱爲主節點,又不成爲數據節點,那麼可將他作爲攝取節點,從節點中獲取數據,生成搜索結果等
# node.master: false
# node.data: false
# node.ingest: true
# 4. 僅作爲協調器
# node.master: false
# node.data: false
# node.ingest: false
path.data: /var/data/elasticsearch //數據目錄
path.logs: /var/log/elasticsearch //日誌文件的路徑
network.host: 127.0.0.1 //節點將綁定到此主機名或IP地址
http.port: 9200 //綁定到傳入HTTP請求的端口,可以接受單個值或者範圍
transport.tcp.port: 9300 //端口綁定節點之間的通信。接受單個值或範圍。如果指定了範圍,則節點將綁定到範圍中的第一個可用端口。默認爲9300-9400
transport.publish_port: 9300 //與此節點通信時,羣集中其他節點應使用的端口。當羣集節點位於代理或防火牆之後並且transport.tcp.port不能從外部直接尋址時很有用。默認爲通過分配的實際端口 transport.tcp.port
transport.bind_host: 127.0.0.1 //將傳輸服務綁定到的主機地址。默認爲transport.host(如果設置)或network.bind_host
transport.publish_host: 127.0.0.1 //發佈集羣中要連接到的節點的主機地址。默認爲transport.host(如果設置)或network.publish_host
transport.host: 127.0.0.1 //用於設置transport.bind_host和transport.publish_host默認爲transport.host或network.host
transport.tcp.connect_timeout: 30s //套接字連接超時設置(以時間設置格式)。默認爲30s
transport.tcp.compress: false //設置是否壓縮tcp傳輸時的數據,默認爲false,不壓縮。
transport.ping_schedule: 5s //安排常規ping消息以確保連接保持活動狀態。默認爲5s在傳輸客戶端和-1(禁用)
network.bind_host: 127.0.0.1 //綁定到哪個網絡接口以偵聽傳入請求
network.publish_host: 127.0.0.1 //發佈主機是節點通告集羣中其他節點的單個接口,以便這些節點可以連接到它。目前,Elasticsearch節點可能會綁定到多個地址,但只發佈一個。如果未指定,則默認爲“最佳”地址network.host,按IPv4 / IPv6堆棧首選項排序,然後按可訪問性排序。如果您將其設置爲 network.host多個綁定地址,但依賴於特定地址進行節點間通信,則應該明確設置 network.publish_host。transport.tcp.port
network.tcp.no_delay: true //啓用或禁用TCP無延遲 設置。默認爲true。
network.tcp.keep_alive: true //啓用或禁用TCP保持活動狀態。默認爲true。
network.tcp.reuse_address: true //地址是否應該重複使用。默認爲true在非Windows機器上。
network.tcp.send_buffer_size //TCP發送緩衝區的大小(以大小單位指定)。默認情況下不明確設置。
network.tcp.receive_buffer_size //TCP接收緩衝區的大小(以大小單位指定)。默認情況下不明確設置。
bootstrap.memory_lock: true //設置爲true來鎖住內存。因爲內存交換到磁盤對服務器性能來說是致命的,當jvm開始swapping時es的效率會降低,所以要保證它不swap
使用head等插件監控集羣信息,需要打開以下配置項 ###########
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-credentials: true
################################### Gateway ###################################
# 以下靜態設置(必須在每個主節點上設置)控制剛剛選擇的主服務器在嘗試恢復羣集狀態和羣集數據之前應等待的時間,修改後需要重啓生效
gateway.expected_nodes: 0 //預計在集羣中的(數據或主節點)數量。只要預期的節點數加入羣集,恢復本地碎片就會開始。默認爲0
gateway.expected_master_nodes: 0 //預計將在羣集中的主節點的數量。一旦預期的主節點數加入羣集,就會立即開始恢復本地碎片。默認爲0
gateway.expected_data_nodes: 0 //預計將在羣集中的數據節點的數量。只要預期數量的節點加入羣集,就會開始恢復本地碎片。默認爲0
gateway.recover_after_time: 5m //設置初始化恢復過程的超時時間,超時時間從上一個配置中配置的N個節點啓動後算起。默認爲5m
################################## Discovery ##################################
#### 該配置十分重要,沒有正確配置,可能無法構成集羣
# 這是一個集羣中的主節點的初始列表,當節點(主節點或者數據節點)啓動時使用這個列表進行探測
# discovery.zen.ping.unicast.hosts: ["host1:port", "host2:port", "host3:port"]
# 默認爲["127.0.0.1", "[::1]"]
discovery.zen.ping.unicast.hosts.resolve_timeout: 5s //在每輪ping中等待DNS查找的時間量。指定爲 時間單位。默認爲5秒
discovery.zen.ping_timeout: 3s //確定節點將多久決定開始選舉或加入現有的羣集之前等待,默認3s
discovery.zen.join_timeout: //一旦一個節點決定加入一個現有的已形成的集羣,它將發送一個加入請求給主設備,默認值是ping超時的20倍。
discovery.zen.minimum_master_nodes: 2
爲防止數據丟失,配置discovery.zen.minimum_master_nodes設置(默認設置1)至關重要, 以便每個符合主節點的節點都知道 爲了形成羣集而必須可見的主節點的最小數量。
爲了解釋,假設您有一個由兩個主節點組成的集羣。網絡故障會中斷這兩個節點之間的通信。每個節點都會看到一個主節點的節點......本身。隨着minimum_master_nodes設置爲默認1,這是足以形成一個集羣。每個節點將自己選爲新的主人(認爲另一個主人資格的節點已經死亡),結果是兩個集羣,或者是一個分裂的大腦。直到一個節點重新啓動後,這兩個節點纔會重新加入。任何已寫入重新啓動節點的數據都將丟失。
現在想象一下,您有一個具有三個主節點資格的節點的集羣,並 minimum_master_nodes設置爲2。如果網絡拆分將一個節點與其他兩個節點分開,則具有一個節點的一側不能看到足夠的主節點,並且會意識到它不能將自己選爲主節點。具有兩個節點的一側將選擇一個新的主控(如果需要)並繼續正常工作。一旦網絡拆分解決,單個節點將重新加入羣集並再次開始提供服務請求。
該設置應該設置爲符合主數據節點的法定數量:
(master_eligible_nodes / 2)+ 1六、插件
plugins:插件
插件擴展ES的功能:
添加自定義的映射類型、自定義分析器、本地腳本、自定義發現方式
安裝:
1.直接將插件放置在plugins目錄中
/usr/share/elasticsearch/plugins
2.使用plugin腳本進行安裝
/usr/share/elasticsearch/bin/plugin
/usr/share/elasticsearch/bin/plugin -h
//在一個節點上安裝,在其他節點上可以查看
插件:
_plugin/plugin_name 訪問
systemctl restart elasticsearch.service
http://192.168.192.222:9200/_plugin/marval/
http://192.168.192.222:9200/_plugin/bigdesk/
http://192.168.192.222:9200/_plugin/headhead插件:是一個Elasticsearch的集羣管理工具,它是完全由HTML5編寫的獨立網頁程序,
以查看集羣幾乎所有信息,還能進行簡單的搜索查詢,觀察自動恢復的情況等等。
kopf插件:Kopf是一個ElasticSearch的管理工具,它也提供了對ES集羣操作的API。
bigdesk插件:集羣監控插件,通過該插件可以查看整個集羣的資源消耗情況,cpu、內存、http鏈接等等。
analysis-ik插件:爲了提高搜索的效率,es使用倒排索引來做全文搜索。
通過analyzer(分詞器)先把需要分析的文本,表徵化爲適合的term(詞),然後標準化這些term,使他們容易被搜索到。
(比如說模糊大小寫,空格等等),analysis-ik是專門用於中文的分詞器。
bigdesk插件安裝方式:
./plugin install mobz/elasticsearch-head
./plugin install lmenezes/elasticsearch-kopf
bigdesk:
https://github.com/lukas-vlcek/bigdesk/tree/master 下載zip壓縮包
cd /usr/share/elasticsearch/plugins/
mkdir bigdesk-master/_site -pv
將解壓後的bigdesk-master文件夾下的所有文件拷貝到_site目錄下
cd /usr/share/elasticsearch/plugins/bigdesk-master
vim plugin-descriptor.properties
description=bigdesk
version=bigdesk
name=bigdesk
site=true
vim bigdesk-master/_site/js/store/BigdeskStore.js
major >= 1 marvel安裝:https://www.elastic.co/guide/en/marvel/current/getting-started.html
推薦網址:
https://es.xiaoleilu.com/
https://elasticsearch.cn/
https://www.elastic.co/guide/cn/kibana/current/index.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
https://github.com/JThink/SkyEye
https://www.elastic.co/downloads/past-releases
https://blog.csdn.net/qq_34021712/article/details/79342668