




三分/彩/代碼出/售 Q1157880099 源碼地址:haozbbs.com 中的數據遷移到MaxCompute中經常需要先卸載到S3中,再到阿里雲對象存儲OSS中,大數據計算服務MaxCompute然後再通過外部表的方式直接讀取OSS中的數據。
如下示意圖:
前提條件
本文以SQL Workbench/J工具來連接Reshift進行案例演示,其中用了Reshift官方的Query editor發現經常報一些奇怪的錯誤。建議使用SQL Workbench/J。
下載Amazon Redshift JDBC驅動程序,推薦4.2 https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.16.1027/RedshiftJDBC42-1.2.16.1027.jar
在SQL Workbench/J中新建Drivers,選擇下載的驅動程序jar,並填寫Classname爲 com.amazon.redshift.jdbc42.Driver。
配置新連接,選擇新建的Driver,並複製JDBC url地址、數據庫用戶名和密碼並勾選Autocommit。
如果在配置過程中發現一隻connection time out,需要在ecs的vpc安全組中配置安全策略。具體詳見:https://docs.aws.amazon.com/zh_cn/redshift/latest/gsg/rs-gsg-authorize-cluster-access.html
Amazon Redshift數據預覽
方式一:在AWS指定的query editor中進行數據預覽,如下所示:
方式二:使用Workbench/J進行數據預覽,如下圖所示:
具體Workbench/J的下載和配置詳見:https://docs.aws.amazon.com/zh_cn/redshift/latest/mgmt/connecting-using-workbench.html
(下圖爲JDBC驅動下載和JDBC URL查看頁面)
卸載數據到Amazon S3
在卸載數據到S3之前一定要確保IAM權足夠,否則如果您在運行 COPY、UNLOAD 或 CREATE LIBRARY 命令時收到錯誤消息 S3ServiceException: Access Denied,則您的集羣對於 Amazon S3 沒有適當的訪問權限。如下:
創建 IAM 角色以允許 Amazon Redshift 集羣訪問 S3服務
step1:進入https://console.aws.amazon.com/iam/home#/roles,創建role。
step2:選擇Redshift服務,並選擇Redshift-Customizable
step3:搜索策略S3,找到AmazonS3FullAccess,點擊下一步。
step4:命名角色爲redshiftunload。
step5:打開剛定義的role並複製角色ARN。(unload命令會用到)
step6:進入Redshift集羣,打開管理IAM角色
step7:選擇剛定義的redshiftunload角色並應用更改。
執行unload命令卸載數據
以管道分隔符導出數據
以默認管道符號(|)的方式將數據卸載到對應的S3存儲桶中,並以venue_爲前綴進行存儲,如下:
unload ('select * from venue')
to 's3://aws2oss/venue_'
iam_role '<新建的redshiftunload角色對應的ARN>';
--parallel off; --連續卸載,UNLOAD 將一次寫入一個文件,每個文件的大小最多爲 6.2 GB
執行效果圖如下:
進入Amazon S3對應的存儲桶中可以查看到有兩份文件,且以venue_爲前綴的,可以打開文件查看下數據。
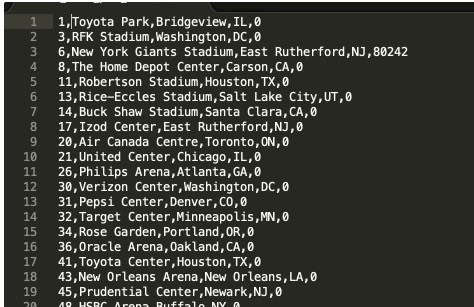
數據如下,以管道字符(|)分隔:
以指標符導出數據
要將相同的結果集卸載到製表符分隔的文件中,請發出下面的命令:
unload ('select * from venue')
to 's3://aws2oss/venue_'
iam_role '<新建的redshiftunload角色對應的ARN>'
delimiter as '\t';
打開文件可以預覽到數據文件如下:
----爲了MaxCompute更方便的讀取數據,我們採用以逗號(,)分隔--`sql
unload ('select * from venue')
to 's3://aws2oss/venue_'
iam_role '<新建的redshiftunload角色對應的ARN>'
delimiter as ','
NULL AS '0';
更多關於unload的命令說明詳見:https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/r_UNLOAD.html
<a name="dbfe35f7"></a>
Amazon S3無縫切換到OSS
在線遷移工具只支持同一個國家的數據源,針對不同國家數據源遷移建議用戶採用OSS遷移工具,自己部署遷移服務並且購買專線來完成,詳見:https://help.aliyun.com/document_detail/56990.html
OSS提供了S3 API的兼容性,可以讓您的數據從AWS S3無縫遷移到阿里雲OSS上。從AWS S3遷移到OSS後,您仍然可以使用S3 API訪問OSS。更多可以詳見S3遷移教程。
<a name="66a56ac6"></a>
背景信息
① 執行在線遷移任務過程中,讀取Amazon S3數據會產生公網流出流量費,該費用由Amazon方收取。<br />② 在線遷移默認不支持跨境遷移數據,若有跨境數據遷移需求需要提交工單來申請配置任務的權限。
<a name="88210852"></a>
準備工作
<a name="ed3070e2"></a>
Amazon S3前提工作
接下來以RAM子賬號來演示Amazon S3數據遷移到Aliyun OSS上。
- 預估遷移數據,進入管控臺中確認S3中有的存儲量與文件數量。
- 創建遷移密鑰,進入AWS IAM頁面中創建用戶並賦予AmazonS3ReadOnlyAccess權限。
- 添加用戶-->訪問類型(編程訪問,AK信息)-->賦予AmazonS3ReadOnlyAccess權限-->記錄AK信息。
step1:進入IAM,選擇添加用戶。<br />![image.png]
step2:新增用戶並勾選創建AK。<br />
step3:選擇直接附加現有策略,並賦予AmazonS3ReadOnlyAccess權限。<br />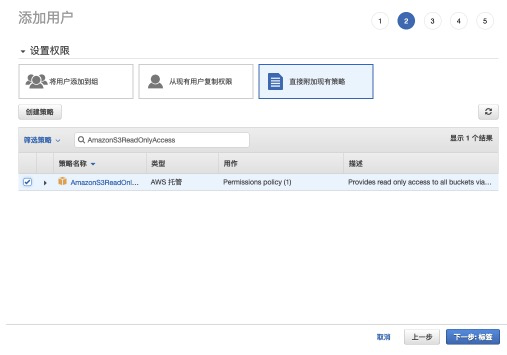
step4:記錄AK信息,在數據遷移中會用到。<br />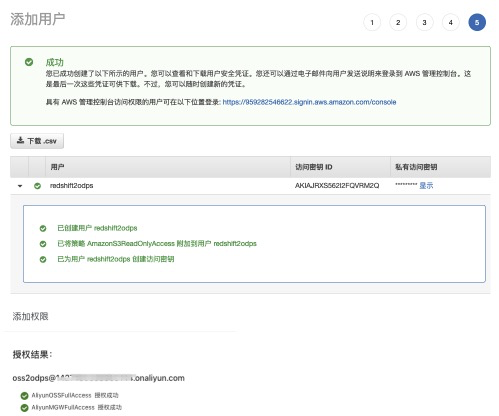
<a name="75e5510f"></a>
Aliyun OSS前提工作
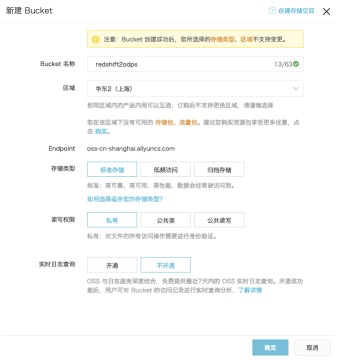
- 阿里雲OSS相關操作,新創建bucket:
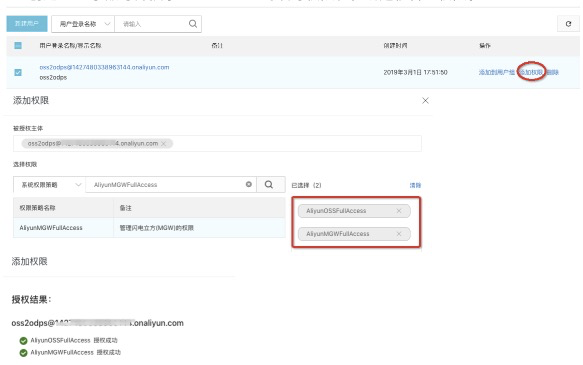
- 創建RAM子賬號並授予OSS bucket的讀寫權限和在線遷移管理權限。
<a name="582bdcd8"></a>
遷移實施
遷移會佔用源端和目的端的網絡資源;遷移需要檢查源端和目的端文件,如果存在文件名相同且源端的最後更新時間少於目的端,會進行覆蓋。
- 進入阿里雲數據在線遷移控制檯:https://mgw.console.aliyun.com/?spm=a2c4g.11186623.2.11.10fe1e02iYSAhv#/job?_k=6w2hbo,並以《Aliyun OSS前提工作》中新建的子賬號登錄。
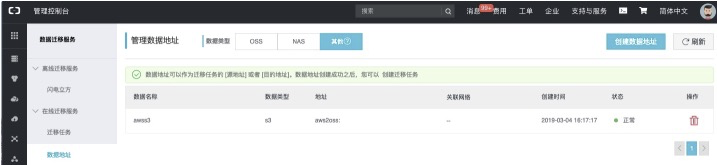
- 進入數據遷移服務-數據地址-數據類型(其他),如下:
【創建源地址:】<br />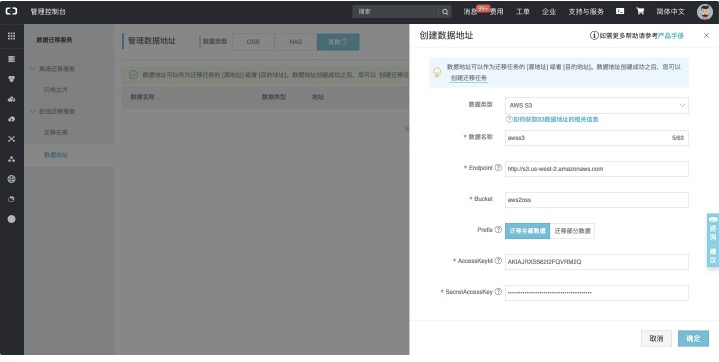
具體配置項說明詳見:https://help.aliyun.com/document_detail/95159.html<br />【創建目標地址:】<br />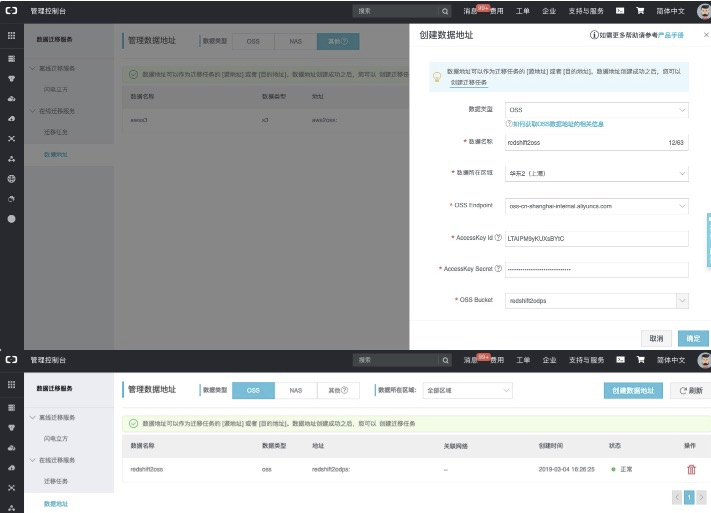
具體配置項說明詳見:https://help.aliyun.com/document_detail/95159.html
<a name="b4361e56"></a>
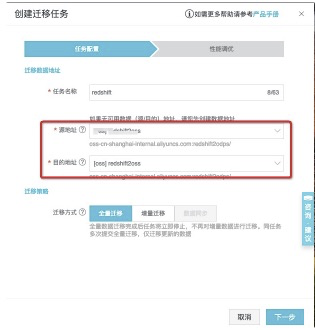
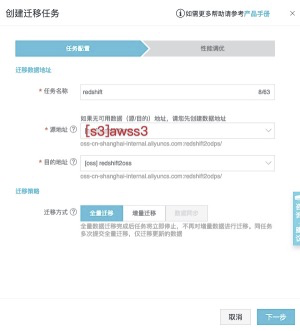
創建遷移任務
從左側tab頁面中找到遷移任務,並進入頁面,點擊創建遷移任務。<br />![image.png]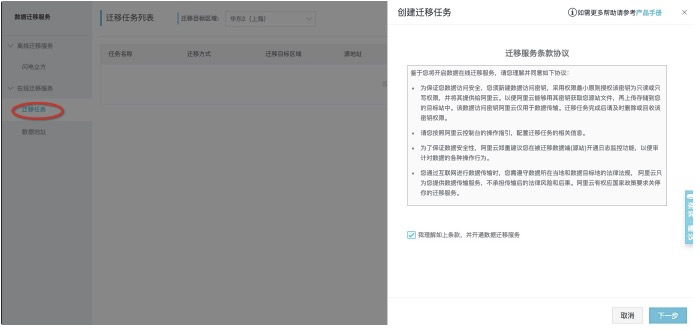
---->OSS中的數據如下:<br />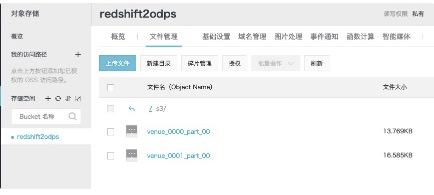
<a name="ebdc286b"></a>
MaxCompute直接加載OSS數據
<a name="98a315c0"></a>
授權
在查詢OSS上數據之前,需要對將OSS的數據相關權限賦給MaxCompute的訪問賬號,授權詳見授權文檔。<br />MaxCompute需要直接訪問OSS的數據,前提需要將OSS的數據相關權限賦給MaxCompute的訪問賬號,您可通過以下方式授予權限:
- 當MaxCompute和OSS的owner是同一個賬號時,可以直接登錄阿里雲賬號後,點擊此處完成一鍵授權。
- 若MaxCompute和OSS不是同一個賬號,此處需由OSS賬號登錄進行授權,詳見文檔。
<a name="a6dbe7f5"></a>
創建外部表
在DataWorks中創建外部表,如下圖所示:<br />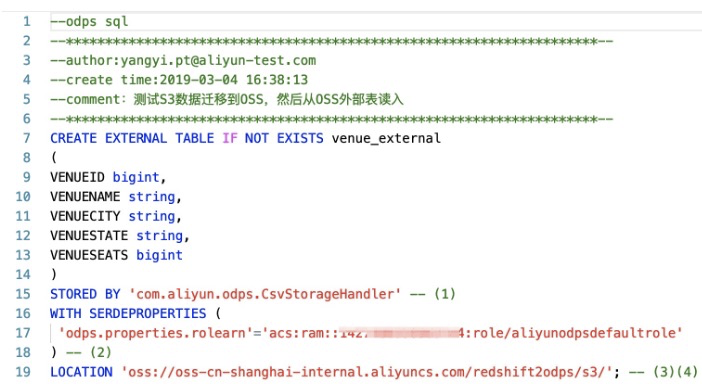
創建MaxCompute外部表DDL語句:
CREATE EXTERNAL TABLE IF NOT EXISTS venue_external
(
VENUEID bigint,
VENUENAME string,
VENUECITY string,
VENUESTATE string,
VENUESEATS bigint
)
STORED BY 'com.aliyun.odps.CsvStorageHandler' -- (1)
WITH SERDEPROPERTIES (
'odps.properties.rolearn'='acs:ram::*:role/aliyunodpsdefaultrole'
) -- (2)
LOCATION 'oss://oss-cn-shanghai-internal.aliyuncs.com/redshift2odps/s3/'; -- (3)(4)
- com.aliyun.odps.CsvStorageHandler是內置的處理CSV格式文件的StorageHandler,它定義瞭如何讀寫CSV文件。您只需指明這個名字,相關邏輯已經由系統實現。如果用戶在數據卸載到S3時候自定義了其他分隔符那麼,MaxCompute也支持自定義分隔符的Handler,詳見:https://help.aliyun.com/document_detail/45389.html
可以直接查詢返回結果:<br />select * from venue_external limit 10;
DataWorks上執行的結果如下圖所示:<br />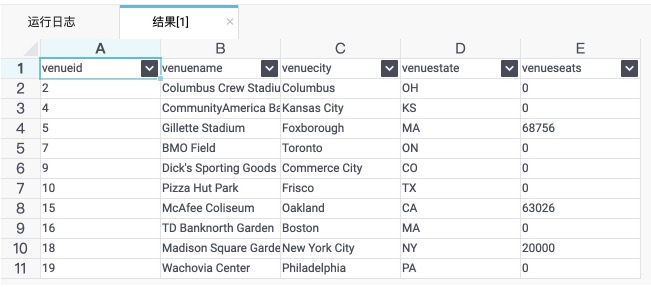
<a name="189c0f78"></a>
創建內部表固化數據
如果後續還需要做複雜的查詢且數據量特別大的情況下,建議將外部錶轉換爲內部表,具體示意如下:<br />create table if not exists venue as select * from venue_external;<br />
原文鏈接