




在數據庫應用開發中,我們經常需要面對複雜的SQL式計算,多級關聯就是其中一種。SQL的join語句比較抽象,只適合表達簡單的關聯關係,一旦關聯的層級較多,相應的代碼就會變得非常複雜。而SPL則可以利用對象引用來表達關聯關係,從而使代碼更加直觀,下面就用一個例子來加以說明。
表channel存儲着某網站所有的頻道及其上級頻道的對應關係,分別用ID和PARENT字段來表示,最多四級,其中root代表網站本身(即根節點)。表中部分數據如下:
| ID | PARENT | NAME |
| p1 | root | news |
| p2 | root | health |
| p3 | root | manage |
| c11 | p1 | Scenic Introduction |
| c12 | p1 | Places of Interest |
| c13 | p1 | Local culture |
| c21 | p2 | Scenic Service |
| c22 | p2 | E-commerce |
| c31 | p3 | Travel Tips |
| d111 | c11 | Investment Projects |
| d112 | c11 | Virtual tour |
| d113 | c11 | Places of Interest |
| d114 | c11 | Historical legends |
| d115 | c11 | Resort weather |
| d121 | c12 | Ticket booking |
現在想要根據參數輸入的ID,分層列出該頻道所有下級的名稱,同一層的下級之間用逗號分隔。假設參數arg1的值是p1,我們期望的結果如下圖所示:

SPL代碼如下:
| A | B | |
| 1 | =db.query("select * from channel") | >A1.switch(PARENT,A1:ID) |
| 2 | =create(ID,LEVEL,SUB) | |
| 3 | =A1.select(PARENT.ID==arg1) | >A2.insert(0,arg1,1,A3.(NAME).string()) |
| 4 | =A1.select(PARENT.PARENT.ID==arg1) | >A2.insert(0,arg1,2,A4.(NAME).string()) |
| 5 | =A1.select(PARENT.PARENT.PARENT.ID==arg1) | >A2.insert(0,arg1,3,A5.(NAME).string()) |
| 6 | >file("channel.xlsx").xlsexport@t(A2) |
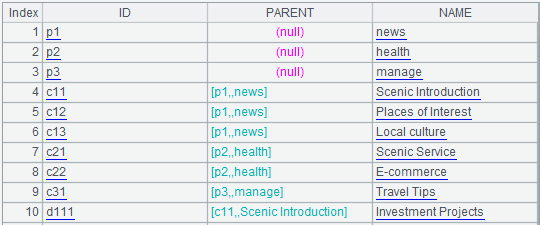
A1:查詢表channel,部分結果如下圖所示:

B1:>A1.switch(PARENT,A1:ID),使用函數switch將表中PARENT字段替換成對應的記錄引用,如下圖所示:
切換後,可以直接用PARENT.ID來表示上級(父)頻道,而PARENT. PARENT. PARENT.ID則可以直接表示上三級(曾祖父)頻道。雖然在SQL中也可以用join來表示這種自連接,但層級多了後顯然容易產生混亂。
A2:=create(ID,LEVEL,SUB),建立一個空序表,用來存儲最終的計算結果。
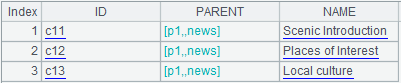
A3:=A1.select(PARENT.ID==arg1),從表中查詢出上級(父)頻道等於參數arg1的記錄,即:arg1的下一級(子)頻道。計算結果如下:
B3:>A2.insert(0,arg1,1,A3.(NAME).string()),在A2中追加一條記錄,第一個字段值是arg1;第二個字段值爲1,表示第一級子頻道;第三個字段爲表達式A3.(NAME).string(),表示取出A3中的列NAME,拼成逗號分隔的字符串。計算結果如下:

A4:=A1.select(PARENT.PARENT.ID==arg1),這句代碼和A3類似,表示從表中查詢出arg1的下兩級(孫子)頻道。結果如下:
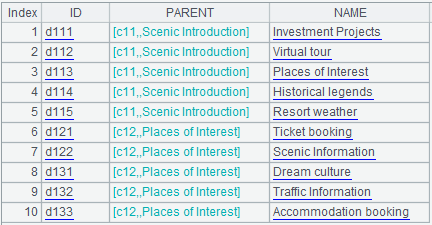
A5和A4類似,表示取出arg1的下三級(曾孫)頻道。用類似的辦法可以輕鬆取出下N級的頻道。
B4、B5和B3類似,都是向A2中追加新記錄,只是level字段改爲2和3。執行完B5後,A2就是本次運算的最終結果:

剛纔參數arg1的值爲p1,如果輸入c12,則計算結果如下:

有時我們希望看到更清晰的數據,比如將某個頻道的所有下級頻道一條條列出,並標出層級關係。如下圖所示:

要想實現這種算法,可以使用下面的代碼:
| A | B | |
| 1 | =db.query("select * from channel") | >A1.switch(PARENT,A1:ID) |
| 2 | =create(ID,LEVEL,SUB) | |
| 3 | =A1.select(PARENT.ID==arg1) | =A2.insert(0,arg1,1,A3) |
| 4 | =A1.select(PARENT.PARENT.ID==arg1) | =A2.insert(0,arg1,2,A4) |
| 5 | =A1.select(PARENT.PARENT.PARENT.ID==arg1) | =A2.insert(0,arg1,3,A5) |
| 6 | =A2.(~.SUB.new(A2.ID,A2.LEVEL,ID:SUBID,NAME)) | |
| 7 | =A6.union() |
紅色字體爲變動後的代碼,其中B3中的代碼是=A2.insert(0,arg1,1,A3),這表示直接將A3的記錄存儲在A2中,假設參數arg1的值爲p1,則計算結果如下:

點開SUB字段,可以看到詳細的記錄:

可以看到,SPL的字段值是泛型的,可以存儲記錄組,或者單條記錄。而函數switch的本質就是將外鍵切換爲主表中對應的記錄。
執行完B5後,A2中的結果如下:

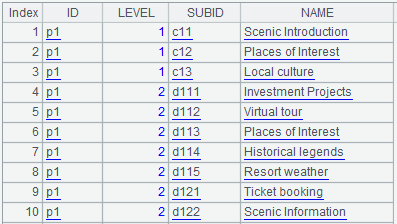
A6:=A2.(~.SUB.new(A2.ID,A2.LEVEL,ID:SUBID,NAME)),用來將A2中ID和LEVEL拼到SUB字段裏的每條記錄中。其中A2.()表示對A2進行計算,計算中可以使用“~”來表示A2中的每條記錄,~.SUB則表示每條記錄的SUB字段(記錄組)。函數new用來生成新的序表,即:A2中的ID字段、LEVEL字段,SUB中的ID字段、NAME字段。計算完成後,A6的值如下:

A7=A6.union(),這句代碼用來將A7的各組記錄拼在一起,形成最終計算結果:
有時我們需要直接列出每個頻道的所有下級頻道。要想實現這種算法,可以使用SPL的for語句,代碼如下:
| A | B | C | |
| 1 | =db.query("select * from channel") | >A1.switch(PARENT,A1:ID) | |
| 2 | =create(ID,LEVEL,SUB) | ||
| 3 | for A1.(ID) | =A1.select(PARENT.ID==A3) | =A2.insert(0,A3,1,B3) |
| 4 | =A1.select(PARENT.PARENT.ID==A3) | =A2.insert(0,A3,2,B4) | |
| 5 | =A1.select(PARENT.PARENT.PARENT.ID==A3) | =A2.insert(0,A3,3,B5) | |
| 6 | =A2.(~.SUB.new(A2.ID,A2.LEVEL,ID:SUBID,NAME)) | ||
| 7 | =A6.union() |
A3中的代碼for A1.(ID)表示循環A1的ID字段,每次取出一條,可以用循環語句所在的單元格A3來表示循環變量。循環的作用範圍可以用縮進來表示,例子中的循環範圍就是B 3:C5。最終的計算結果在A7中,部分數據如下:

從這些例子可以看出,使用SPL簡化多級關聯問題時,思路直觀明瞭,代碼簡潔易懂,層級關係清晰可見。與SQL相比,這樣的SPL代碼可以大幅度降低開發成本,並極大地簡化後期優化和維護工作。