




redis對外公開的有5種數據結構,分別是String,List,Hash,Set,ZSet。這幾種底層分別用了不同的數據結構來實現。
redis介紹:
redis是一個開源的使用C語言編寫的一個kv存儲系統,是一個速度非常快的非關係內存數據庫。它支持包括String、List、Set、Zset、hash五種數據結構。
與關係型數據庫相比,redis的命令請求不需要經過查詢分析器或查詢優化器進行處理,也避免了更新數據時引起的隨機讀\寫,這些慢操作。它直接讀寫內存中的數據,並且數據是按照一定的數據結構存儲的。所以它的速度非常快。
Redis採用redisObjec結構來統一五種不同的數據類型,這樣所有的數據類型就都可以以相同的形式在函數間傳遞而不用使用特定的類型結構。
typedef struct redisObject {
unsigned type:4; //保存信息的類型(String,List,Set,Zset,Hash)
unsigned encoding:4;//保存信息的編碼方式(底層數據結構)
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;//引用次數
void *ptr;//保存的指針
} robj;
/* Object types */
#define OBJ_STRING 0
#define OBJ_LIST 1
#define OBJ_SET 2
#define OBJ_ZSET 3
#define OBJ_HASH 4
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
String:
由於redis是C語言寫的,C語言並沒有實現好的字符串類型,是用指針或則char數組實現的,C語言字符串結尾是以'\0'來標識。redis自定義了一種自定義結構,SDS(動態字符串)。
struct sdshdr{
//記錄buf數組中已使用字節的數量
//等於 SDS 保存字符串的長度
int len;
//記錄 buf 數組中未使用字節的數量
int free;
//字節數組,用於保存字符串
char buf[];
}

SDS的性質:
1.C 語言的字符串不會記錄自己的長度,而是需要進行遍歷獲得,時間複雜度爲 O(n) ,而 SDS 已經封裝了 len 屬性,直接讀取 len 的值就可以獲得長度,不需要遍歷,時間複雜度 O(1) 。
2.二進制安全的(C語言是以\0來表示字符串結束的),如果二進制中有 \0 會結束字符串。所以redis是可以存儲圖片和視頻的。
3. 如果修改後的 SDS 長度 len 小於 1MB,那麼程序分配和 len 屬性相等的未使用空間,此時 free 和 len 的值相同。所以此時數組的實際長度爲 free + len + 1byte(額外的空字符 1 個字節)。
4. 如果修改後的 SDS 長度大於 1MB,那麼程序分配 1MB 的未使用空間。實際長度爲 len + 1MB + 1byte。
在擴展 SDS 之前,會檢查未使用空間是否夠用,如果足夠,就不用內存重分配,直接使用剩餘空間即可。
5.惰性刪除機制,字符串縮減後的空間不釋放,作爲預分配空間保留。
在redis中,key都是用sds這種來表示的,key最大是512M,value也是512M。

EMBSTR和RAM的區別:這兩個的編碼方式是一樣的,不同之處是在於embstr是通過調用一次內存分配函數來分配一塊內存空間,這一塊內存空間包含了redisObject和sds兩個結構;而raw是調用兩次內存分配函數,分別來創建redisObject和sds。
採用一次內存分配的好處?
1.創建embstr字符串只需調用一次內存分配函數,釋放的時候也只需調用一次。更快。
embstr的缺點:embstr是隻讀的,是不能修改的,一旦修改,會自動轉raw格式。
當我們對於int編碼的字符串對象修改,將其修改爲一個不再是整數值,而是一個字符串值時,redis就會將該字符串對象的編碼從int轉爲raw
當我們對於embstr編碼的字符串對象執行修改時,由於embstr編碼字符串對象是隻讀的,redis也會將其轉爲raw編碼的字符串對象後再執行修改命令
List:

在3.2之前的版本,List底層是由ziplist和linkedlist實現,而在3.2之後,List都是由quicklist實現的。
ziplist(壓縮列表):

| 域 | 長度/類型 | 域的值 |
|---|---|---|
zlbytes |
uint32_t |
整個 ziplist 佔用的內存字節數,對 ziplist 進行內存重分配,或者計算末端時使用。 |
zltail |
uint32_t |
到達 ziplist 表尾節點的偏移量。 通過這個偏移量,可以在不遍歷整個 ziplist 的前提下,彈出表尾節點。 |
zllen |
uint16_t |
ziplist 中節點的數量。 當這個值小於 UINT16_MAX (65535)時,這個值就是 ziplist 中節點的數量; 當這個值等於 UINT16_MAX 時,節點的數量需要遍歷整個 ziplist 才能計算得出。 |
entryX |
? |
ziplist 所保存的節點,各個節點的長度根據內容而定。 |
zlend |
uint8_t |
255 的二進制值 1111 1111 (UINT8_MAX) ,用於標記 ziplist 的末端。 |
| 域 | |
|---|---|
| pre_entry_length |
記錄了前一個節點的長度,通過這個值,可以進行指針計算,從而跳轉到上一個節點。
根據編碼方式的不同,
|
| encoding和length |
1、一字節、二字節或者五字節,值的最高位爲00,01或者10的字節編碼,這樣的編碼表示content保存的是字節數組,數組的長度保存在剩餘的其他位。 2、一字節長,值的最位爲11,表示整數編碼,具體的整數類型對應如下: 11000000-int16_t,11010000-int32_t,11100000-int64_t,11110000-24位有符號整數 11111110-8位有符號整數,1111xxxx——xxxx用於保存0-12的整數。 |
| content | content記錄保存節點的值,節點值可以是一個字節數組或者整數。 |
ziplist是一個經過特殊編碼的雙向鏈表,它的設計目標就是爲了提高存儲效率。ziplist可以用於存儲字符串或整數,其中整數是按真正的二進制表示進行編碼的,而不是編碼成字符串序列。它能以O(1)的時間複雜度在表的兩端提供push和pop操作。
實際上,ziplist充分體現了Redis對於存儲效率的追求。一個普通的雙向鏈表,鏈表中每一項都佔用獨立的一塊內存,各項之間用地址指針(或引用)連接起來。這種方式會帶來大量的內存碎片(頻繁的插入刪除),而且地址指針也會佔用額外的內存。而ziplist卻是將表中每一項存放在前後連續的地址空間內,一個ziplist整體佔用一大塊內存。它是一個表(list),但其實不是一個鏈表(linked list)。
另外,ziplist爲了在細節上節省內存,對於值的存儲採用了變長的編碼方式,大概意思是說,對於大的整數,就多用一些字節來存儲,而對於小的整數,就少用一些字節來存儲。
ziplist的數據結構定義,我們介紹完了,現在我們看一個具體的例子。
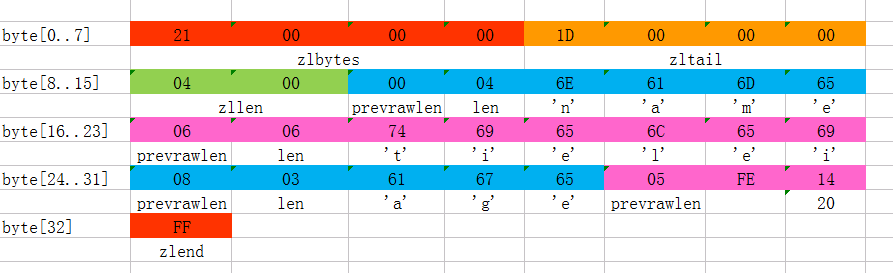
上圖是一份真實的ziplist數據。我們逐項解讀一下:
- 這個ziplist一共包含33個字節。字節編號從byte[0]到byte[32]。圖中每個字節的值使用16進製表示。
- 頭4個字節(0x21000000)是按小端(little endian)模式存儲的
<zlbytes>字段。什麼是小端呢?就是指數據的低字節保存在內存的低地址中(參見維基百科詞條Endianness)。因此,這裏<zlbytes>的值應該解析成0x00000021,用十進制表示正好就是33。 - 接下來4個字節(byte[4..7])是
<zltail>,用小端存儲模式來解釋,它的值是0x0000001D(值爲29),表示最後一個數據項在byte[29]的位置(那個數據項爲0x05FE14)。 - 再接下來2個字節(byte[8..9]),值爲0x0004,表示這個ziplist裏一共存有4項數據。
- 接下來6個字節(byte[10..15])是第1個數據項。其中,prevrawlen=0,因爲它前面沒有數據項;len=4,相當於前面定義的9種情況中的第1種,表示後面4個字節按字符串存儲數據,數據的值爲”name”。
- 接下來8個字節(byte[16..23])是第2個數據項,與前面數據項存儲格式類似,存儲1個字符串”tielei”。
- 接下來5個字節(byte[24..28])是第3個數據項,與前面數據項存儲格式類似,存儲1個字符串”age”。
- 接下來3個字節(byte[29..31])是最後一個數據項,它的格式與前面的數據項存儲格式不太一樣。其中,第1個字節prevrawlen=5,表示前一個數據項佔用5個字節;第2個字節=FE,相當於前面定義的9種情況中的第8種,所以後面還有1個字節用來表示真正的數據,並且以整數表示。它的值是20(0x14)。
- 最後1個字節(byte[32])表示
<zlend>,是固定的值255(0xFF)。
總結一下,這個ziplist裏存了4個數據項,分別爲:
- 字符串: “name”
- 字符串: “tielei”
- 字符串: “age”
- 整數: 20
LinkedList:雙向鏈表,額外的信息多,佔用內存,頻繁的創建節點和刪除節點,容易造成內存碎片。
quickList:相當於鏈表和ziplist的結合體。ziplist在我們程序裏面來看將會是一塊連續的內存塊。它使用內存偏移來保存next從而節約了next指針。這樣造成了我們每一次的刪除插入操作都會進行remalloc,從而分配一塊新的內存塊。當我們的ziplist特別大的時候。沒有這麼大空閒的內存塊給我們的時候。操作系統其實會抽象出一塊連續的內存塊給我。在底層來說他其實是一個鏈表鏈接成爲的內存。不過在我們程序使用來說。他還是一塊連續的內存。這樣的話會造成內存碎片,並且在操作的時候因爲內存不連續等原因造成效率問題。或者因爲轉移到大內存塊等進行數據遷移。從而損失性能。

Hash:

ZipList是如何實現hash結構的?
ziplist是一個列表的結構,它分別存了key和value,查找的過程:
1.首先調用ziplistFind函數,在壓縮列表中查找指定鍵對應的節點。
2.然後調用ziplistNext函數,將指針移動到鍵節點旁邊的值節點,最後返回值節點。
爲什麼要從ziplist轉dict結構?
ziplist每次插入或修改引發的realloc操作會有更大的概率造成內存拷貝,從而降低性能。
一旦發生內存拷貝,內存拷貝的成本也相應增加,因爲要拷貝更大的一塊數據。
當ziplist數據項過多的時候,在它上面查找指定的數據項就會性能變得很低,因爲ziplist上的查找需要進行遍歷。(ziplist屬於用時間換空間)
在數據量小的時候,ziplist和dict結構操作時間是相差不大的,可以接受的。但數據量增大,dict的查找,插入,刪除,都接近O(1),相對於ziplist是有非常大的優勢的。
Set:

intset:會根據插入的數據來進行編碼升級。比如:在intset裏都是int16,接下來要插入的是一個int32的數,那麼intset裏所有的數都會升級int32;
dict:key保存元素,value爲null。
Zset:

ziplist:entry第一個節點保存元素成員,緊接着保存的是分值。
skiplist:
typedef struct zskiplistNode {
// member 對象
robj *obj;
// 分值
double score;
// 後退指針
struct zskiplistNode *backward;
// 層
struct zskiplistLevel {
// 前進指針
struct zskiplistNode *forward;
// 節點在該層和前向節點的距離
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
// 頭節點,尾節點
struct zskiplistNode *header, *tail;
// 節點數量
unsigned long length;
// 目前表內節點的最大層數
int level;
} zskiplist;
頭結點默認層數是爲32的,但描述符中指示跳躍表層數初始化爲1。
層
跳躍表節點的 level 數組可以包含多個元素, 每個元素都包含一個指向其他節點的指針, 程序可以通過這些層來加快訪問其他節點的速度, 一般來說, 層的數量越多, 訪問其他節點的速度就越快。
每次創建一個新跳躍表節點的時候, 隨機生成一個介於 1 和 32 之間的值作爲 level 數組的大小(redis最高是32層)。
圖 5-2 分別展示了三個高度爲 1 層、 3 層和 5 層的節點, 因爲 C 語言的數組索引總是從 0 開始的, 所以節點的第一層是 level[0] , 而第二層是 level[1] , 以此類推。

跨度
層的跨度(level[i].span 屬性)用於記錄兩個節點之間的距離:
兩個節點之間的跨度越大, 它們相距得就越遠。
指向 NULL 的所有前進指針的跨度都爲 0 , 因爲它們沒有連向任何節點。
初看上去, 很容易以爲跨度和遍歷操作有關, 但實際上並不是這樣 —— 遍歷操作只使用前進指針就可以完成了, 跨度實際上是用來計算排位(rank)的: 在查找某個節點的過程中, 將沿途訪問過的所有層的跨度累計起來, 得到的結果就是目標節點在跳躍表中的排位。
舉個例子, 圖 5-4 用虛線標記了在跳躍表中查找分值爲 3.0 、 成員對象爲 o3 的節點時, 沿途經歷的層: 查找的過程只經過了一個層, 並且層的跨度爲 3 , 所以目標節點在跳躍表中的排位爲 3 。

後退指針
節點的後退指針(backward 屬性)用於從表尾向表頭方向訪問節點: 跟可以一次跳過多個節點的前進指針不同, 因爲每個節點只有一個後退指針, 所以每次只能後退至前一個節點。
圖 5-6 用虛線展示瞭如果從表尾向表頭遍歷跳躍表中的所有節點: 程序首先通過跳躍表的 tail 指針訪問表尾節點, 然後通過後退指針訪問倒數第二個節點, 之後再沿着後退指針訪問倒數第三個節點, 再之後遇到指向 NULL 的後退指針, 於是訪問結束。

分值和成員
節點的分值(score 屬性)是一個 double 類型的浮點數, 跳躍表中的所有節點都按分值從小到大來排序。
節點的成員對象(obj 屬性)是一個指針, 它指向一個字符串對象, 而字符串對象則保存着一個 SDS 值。
在同一個跳躍表中, 各個節點保存的成員對象必須是唯一的, 但是多個節點保存的分值卻可以是相同的: 分值相同的節點將按照成員對象在字典序中的大小來進行排序, 成員對象較小的節點會排在前面(靠近表頭的方向), 而成員對象較大的節點則會排在後面(靠近表尾的方向)。
舉個例子, 在圖 5-7 所示的跳躍表中, 三個跳躍表節點都保存了相同的分值 10086.0 , 但保存成員對象 o1 的節點卻排在保存成員對象 o2 和 o3 的節點之前, 而保存成員對象 o2 的節點又排在保存成員對象 o3 的節點之前, 由此可見, o1 、 o2 、 o3 三個成員對象在字典中的排序爲 o1 <= o2 <= o3 。
跳錶還可以快速的訪問頭尾節點。