




本文推薦知道的背景知識:
Kubernetes 的基本原理和各大組件的職責;
Serverless 計算的基本概念和它的優勢;
Plus: 對社區 Knative 項目的基本瞭解;
本文根據董一韜和王軻在 KubeCon NA 2019 大會分享整理。
董一韜 螞蟻金服,產品經理,致力於驅動雲計算相關產品,包括雲原生 PaaS 平臺、容器與 Serverless 產品等,與最終顧客緊密合作,幫助客戶在規模化的金融場景下采用與落地雲原生相關解決方案。
王軻 螞蟻金服,軟件工程師,建設基於 Kubernetes/Knative 的企業級 Serverless 產品,Knative 的早期使用者,Kubernetes 社區成員、控制面流控早期維護者,長期致力於用創新的方式優化、落地雲原生技術。
一. 分享概要
Knative 是 Google 主導的基於 Kubernetes 的 Serverless 平臺,在社區上有較高的知名度。然而,身爲社區項目的 Knative 主要關心的是標準、架構。雖有先進的理念,卻離可在生產上使用有不少的差距。
本次 KubeCon 的演講中,來自螞蟻金服 SOFAStack-PaaS 平臺產品技術團隊的隱秀和仲樂與大家分享螞蟻金服金融科技 Knative 的實踐和改造:基於 Knative 構建一個優秀的 Serverless 計算平臺,詳細分析如何用獨特的技術,解決性能、容量、成本三大問題。
從 Serverless 計算的應用場景開始,提煉客戶真正的 Use Case,分公有云、私有云、行業雲等,講述 Serverless 計算的多種用途。之後我們將介紹在 Kubernetes 上運行 Knative 平臺的方案,詳細介紹要使其生產可用,不得不克服的問題。演講最後,將剛剛的這些問題一一攻破,做出一個比社區版本優秀的 Knative 平臺。

二. 解決性能問題:使用 Pod 預熱池
熟悉 Kubernetes 的同學可能知道,Kubernetes 的首要目標並不是性能。
在一個大規模的 Kubernetes 集羣下,要創建一個新的 Pod 並讓它跑起來,是很慢的。這是因爲這整個鏈路很長:先要向 APIServer 發一個 POST 請求,再要等 Scheduler 收到新 Pod 資源被創建的事件,再等 Scheduler 在所有的 Node 上運行一遍篩選、優選算法並把調度結果返回給 API Server,再到被選中 Node 的 Kubelet 收到事件,再到Docker 鏡像拉取、容器運行,再到通過安全檢查並把新的容器註冊到 Service Mesh 上…
任何一個步驟都有可能出現延時、丟事件,或失敗(如調度時資源不足是很常見的)。就算一切都正常工作,在一個大規模的 Kubernetes 集羣裏,整個鏈路延時達到20s,也是很常見的。
這便導致在 Kubernetes 上做 Serverless 的窘境:Serverless 的一大特點是自動擴縮容,尤其是自動從0到1,不使用時不佔任何資源。但如果一個用戶用 Serverless 跑自己的網站/後端,但用戶的首個請求花費20s才成功,這是無法接受的。
爲了解決冷啓性能問題,我們團隊提出了一個創造性的解決方案:使用 Pod 預熱池(Pod Pool)。
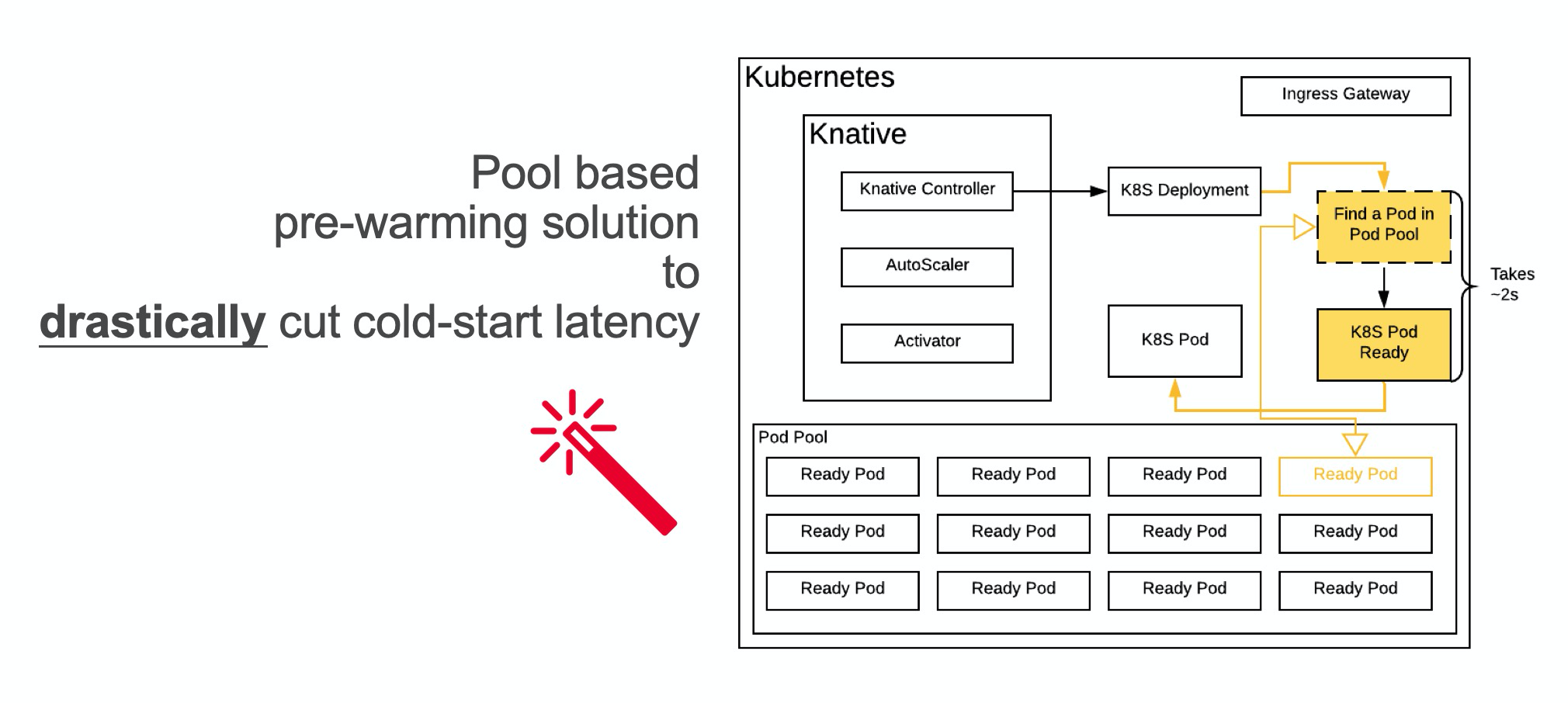
我們的產品會預先創建許多個 Pod 並讓它們運行起來,當 Kubernetes 的控制器希望創建一個新的 Pod 的時候,我們不再是從零開始新建一個 Pod,而是找到一個處於待命狀態的符合條件的 Pod,並把代碼注入這個 Pod,直接使用。
在演講中,我們分享了一定技術實現的細節,例如如何創建 CRD 並 fork Kubernetes 的 ControllerManager,來以較小的成本實現新 Workload;如何自動根據歷史的使用數據來自動伸縮 Pod 池的水位;如何做代碼注入等。我們提了3種方式,分別是給容器發指令讓容器中的進程下載並執行代碼包、使用 Ephemeral Container、魔改 Kubelet允許替換 Container。
實際的實現比這個還要複雜,要考慮的問題更多,例如如何響應 Pod 中不同的資源 request、limit。我們實際上也實現了一個調度器。當某個預熱好的 Pod 不能滿足,會看那個 Pod 所在 Node 上的資源餘量,如果餘量夠則動態改 Kubernetes 控制面數據和 cgroups,實現“垂直擴容”。
實際操作證明,這個冷啓優化的效果非常好,當 Pod 大小固定、代碼包緩存存在時,啓動一個最簡單的 HTTP 服務器類型應用的耗時從近20秒優化到了2秒,而且由於不需要當場調度 Pod,從0到1的穩定性也提升了很多。
這個優化主要是跳過了若干次 API Server 的交互、Pod Schedule 的過程和 Service Mesh 註冊的過程,用戶程序從零到一的體驗得到極大的提升,又不會招致過多的額外成本。一般來講多預留10-20個 Pod 就可以應付絕大多數情況,對於少見的短時間大量應用流量激增,最壞情況也只是 fallback 到原先的新創建 Pod 的鏈路。
Pod 預熱池不光可以用來做冷啓優化,還有很多其他的應用場景。演講中我呼籲將這種技術標準化,來解決 Kubernetes 數據面性能的問題。會後有觀衆提出 cncf/wg-serverless 可能有興趣做這件事情。
三. 降低成本:共享控制面組件
在成本方面,我們和大家分享了多租戶改造和其他的降低成本的方式。
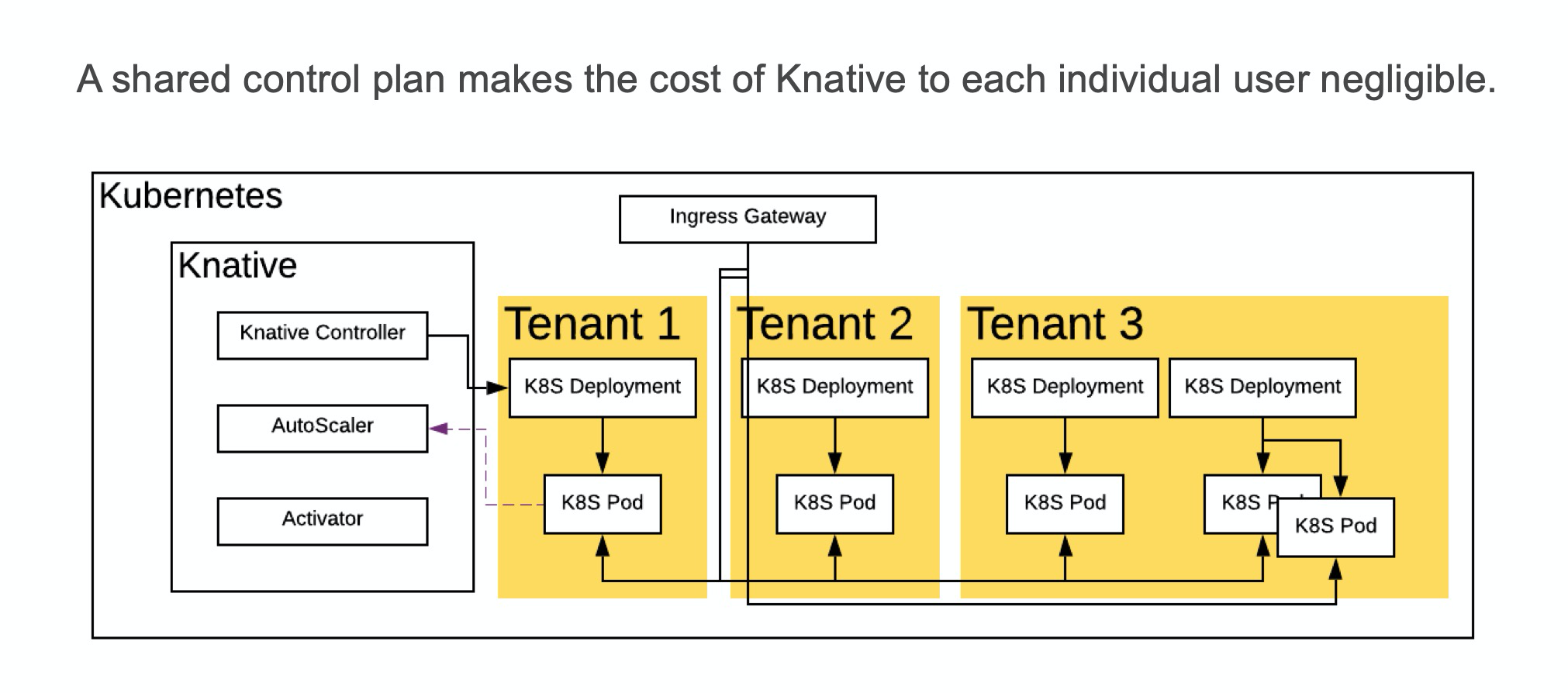
如果以單租戶的方式運行社區版的 Knative,成本是昂貴的:需要部署 Kubernetes 控制面和 Service Mesh 控制面,因爲這些都是 Knative 的依賴,Knative 本身的控制面也很佔資源。十幾C幾十G 的機器就這樣被使用了,不產生任何業務價值。因此,共享這些控制面的組件是非常必要的。
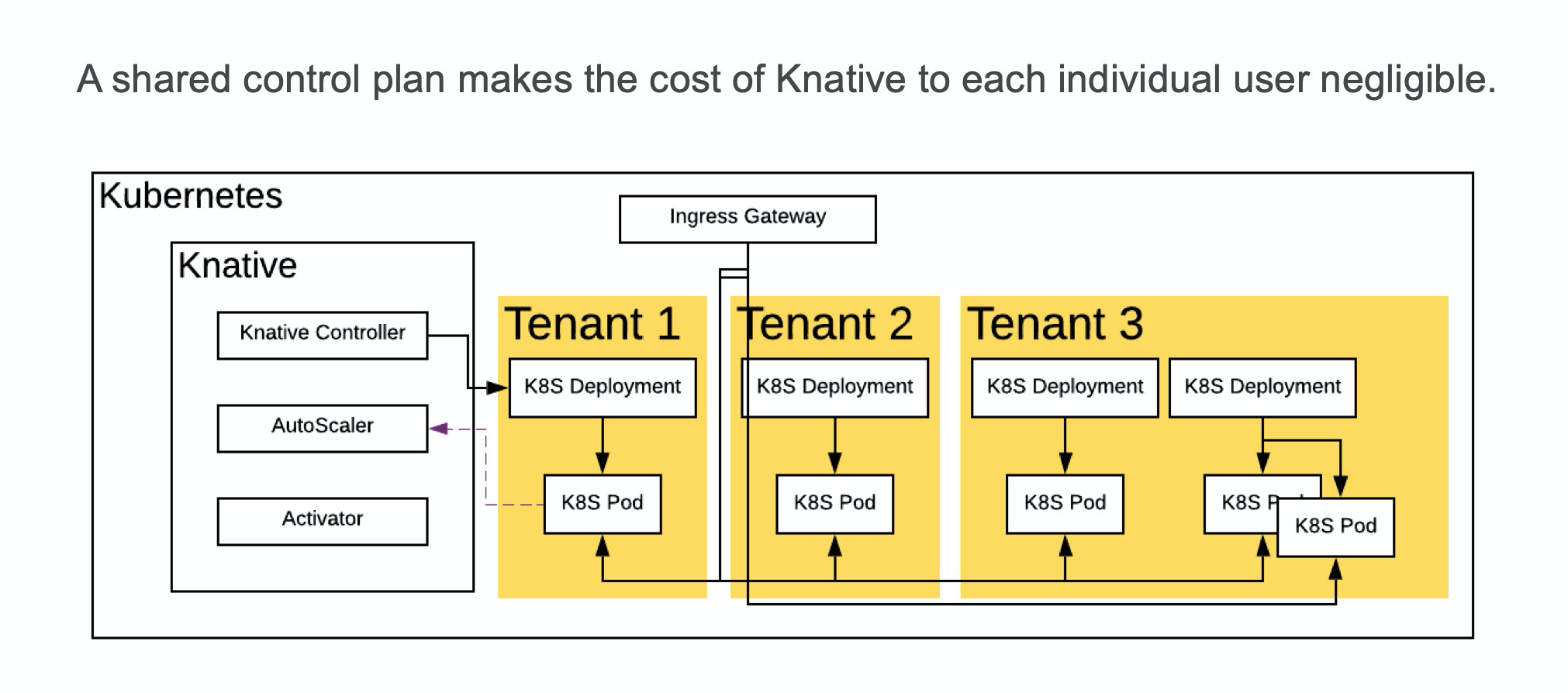
通過共享,用戶不必再單獨爲基礎設施買單。控制面的成本也只和每個租戶創建的應用的數量之和有關,而不會再和租戶多少產生關聯。
我們推薦兩種共享的方式,一種是 Namespace 隔離+ RBAC 權限控制,這種控制面共享的方法是最簡單、Kubernetes 原生支持,也廣爲使用的一種方法。另一種方法是螞蟻金服金融科技自研 Kubernetes 實現的多租戶方案,通過在 etcd 中多加一級目錄並把每個用戶的數據存在他們自己的目錄中,實現真正全方位多租戶的
Kubernetes。
演講中還提到了其他的一些降低成本的方法,如通過 Virtual Kubelet 對接阿里雲的 ECI(按需的容器服務)、通過 Cluster AutoScaler 來自動釋放使用率低的 Kubernetes 節點或從阿里雲購置 ECS 來增加新的節點以水平擴容等。還簡單提了一下多個租戶的容器共享同一個宿主機可能面臨的安全問題,如 Docker 逃逸。一種可能的解決方法是使用 Kata Container(虛擬機)以避免共享 Linux 內核。
四. 解決容量問題:每個層級都做好對分片的支持
容量方面的挑戰在於當 Workload 數量增多後,無論是 Knative 各控制器/數據面組件還是 Kubernetes 控制面本身還是 Service Mesh,都會面臨更大的壓力。要解決這個問題並不難,只要在從上到下每個層級都做好對分片的支持。
上游系統給每個 APP 創建一個分片 ID,下游就可以部署多組控制面組件,讓每一組組件處理一個分片 ID。
要完整支持分片,我們需要改造控制面各控制器、數據面的 Knative Activator,和 Service Mesh。
控制器的改造非常容易,只需要在 Informer 中添加 LabelSelector,其值爲分片 ID,控制器就只能看到那個分片 ID下的所有資源,自動無視其他資源了。每組控制器都設置不重疊的 LabelSelector,我們就可以同時運行多組互不干擾的控制器。因爲控制器調和是無狀態且冪等的,對於每一個分片 ID,我們仍然可以以主主的方式部署多個副本以實現高可用。
接下來是數據面 Activator 的改造,其主要挑戰是如何找到每個應用對應的 AutoScaler(因爲 AutoScaler 也被分片,部署了多份)。這裏可以通過域名的方式來做尋址,把分片 ID 作爲域名的一部分,然後搭配 DNS 記錄或 Service Mesh,將 Activator 的報文路由到某個分片的 AutoScaler 裏。
最後是 Service Mesh 的改造,默認情況下每個 Service Mesh 中的 Sidecar 都包含別的 Pod 的信息,所以一個含有 n 個 Pod 的 Mesh 的數據量是 O(n2)。通過 ServiceGroup,我們可以將一個 Service Mesh 分割成多個子 Service Mesh,並設爲僅每個子 Service Mesh 中的 Sidecar 相互可見,來解決數據量在規模增長下激增的問題。自然的,每個子 Service Mesh 需要單獨設置一個 Ingress,但這也有好處:每個 Ingress 的壓力不會過高。如果要跨子 Service Mesh 訪問,那可以走公網 IP 等,訪問另一個子 Service Mesh 的 Ingress。改造完以上所有東西后,在單個 Kubernetes 集羣裏,就可以無限水平擴容了。
但當 Workload 多到一定程度,Kubernetes 控制面本身也可能成爲瓶頸。這個時候,我們可以再部署一個Kubernetes,並把某些分片放到那個新的 Kubernetes 集羣裏,這算是更高級別的分片。巧的是,本屆 KubeCon一大火熱話題也是多 Cluster:把你的全套應用打包帶走,一鍵建立新 Kubernetes 集羣並全量發佈,統一運維和升級…
五. 結束語

本次分享不到40分鐘,現場觀衆約150人,關注653人,YouTube 觀看目前近200人。KubeCon 的確是很不錯的技術會議,有很多專業人士。更加棒的是那種包容、自由、分享的氛圍,讓人覺得自己是一個很大 Community 的一份子,一同進步與革新,一同做一些了不起的事情。
本次 KubeCon,我們將螞蟻金服內部的一些技術成果帶了出去和大家分享,也從這個 Community,見識了大家在搞的新技術、新產品,有很多非常棒,很值得借鑑。
在雲原生 Serverless 平臺模式下,我們需要處理的場景和待解決的問題還非常多,數據規模也在不斷的增長,歡迎致力於雲原生領域的小夥伴們加入我們,我們一起探索和創新!
分享演講視頻回顧:
https://www.youtube.com/watch?v=PA1UoLPf4nE
P.S. 團隊長期招人、歡迎轉崗。產品、研發、測試,base支付寶上海S空間!
技術崗 → 凌真([email protected])、仲樂([email protected])
產品崗 → 隱秀([email protected])