




下面,我們結合Kaggle賽題:Avazu:Click-Through Rate Prediction,練習數據挖掘技術在CTR預估中的應用。
本文內容包括賽題任務簡析,以及基於LR(邏輯斯蒂迴歸)的初步實現。

本文的源碼託管於我的Github:PnYuan - Kaggle_CTR,歡迎查看交流。
1.任務概述
CTR(Click Through Rate,點擊率),是“推薦系統/計算廣告”等領域的重要指標,對其進行預估是支持進一步地“商品推送/廣告投放”等決策的基礎。Avazu:Click-Through Rate Prediction是Kaggle2015舉行的一場CTR預估比賽。賽事主辦方提供了規約化的歷史數據(train.csv)與待預測數據(test.csv),下述條目給出了該賽事任務的一些基本信息:
任務輸入:數據集文件:train.csv 和 test.csv。
任務輸出:給出預測集id所對應的CTR預估值,形如:
id, click xx01, 0.118.. xx02, 0.159.. xx03, 0.162..評價方法:log-loss,二分類任務的交叉熵損失函數;
原始數據規模(百萬級樣本數):
訓練集樣本數:≈40.4M 測試集樣本數:≈4.58M原始特徵(20+),有關特徵的官方解釋見賽題主頁-Data,下面示意性列舉了部分特徵:
id: int或string型,用戶ID號,可作爲樣本索引; click:bool或int型,只存在於訓練集中,樣本的標籤(是否點擊:0-否,1-是); hour:int型,時間變量形如YYMMDDHH; C1:int型,匿名特徵; banner_pos:int型,網頁上的廣告位置,離散特徵0,1,2,3... app_id:string型,用戶APP的ID; ...
據上所述,可以爲該任務貼上一些初識標籤,如:有監督學習、二分類概率預測、較大規模數據等等。
2.特徵工程
本文擬給出一個基於LR的任務初步實現樣例,主要目的是體驗CTR預估的任務進行過程。在訓練LR模型之前,首先要根據原始數據特點以及模型輸入要求,對原始特徵數據進行預處理以使更好的用於模型的訓練與上線。
賽題主頁-Data頁對原始數據及其特徵進行了簡要說明。這裏爲簡化計算過程,只選用部分原始特徵進行實驗,如下表所示:
| 特徵名 | 數值類型 | 數值樣例 | 特徵內涵 |
|---|---|---|---|
| C1 | int | 1001,1004 | 未知 |
| banner_pos | int | 0,1,2… | 廣告條目位置 |
| site_domain | str | f3845767,1b32ed33… | Site領域 |
| site_id | str | 1fbe01fe,fe8cc448… | Site ID |
| site_category | str | 28905ebd,0569f928… | Site類型 |
| app_id | str | ecad2386,98fed791… | App ID |
| app_category | str | 07d7df22,cef3e649… | APP類型 |
| device_type | int | 0,1,2… | Device類型 |
| device_conn_type | int | 0,1,2… | Device接入類型 |
| C14 | int | 20366,19251… | 未知 |
| C15 | int | 320,120… | 未知 |
| C16 | int | 50,250… | 未知 |
原始特徵絕大多數爲離散類別型(categorical)(包括上表所選特徵在內)。當採用此類特徵進行LR訓練時,常進行獨熱編碼(One-Hot Encoding)以使其數據更加利於模型學習。這裏由於部分特徵的類別取值數量巨大,全部採用One-Hot編碼易產生高維度稀疏矩陣,影響學習效率,考慮到特徵類別取值呈現長尾分佈,如下圖所示,故而先將稀有類別取值統一設置爲“Other”,然後再進行One-Hot編碼處理,從而在保留主體特徵信息的同時,控制新特徵維度,提高訓練效率。
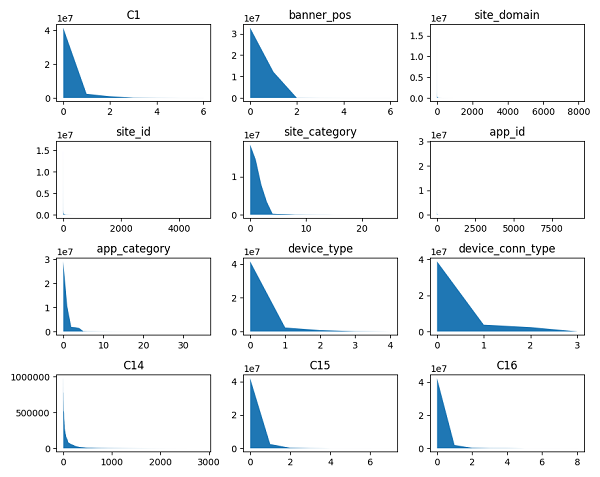
考慮到數據規模較大,這裏採用dummyPy工具包來分塊實現數據的One-Hot轉換。
3.LR實驗
LR(邏輯迴歸/對率迴歸)模型是一個非常簡單實用的有監督學習模型,這裏我們將其運用到對CTR預估的初步嘗試中。考慮到數據量較大,這裏我們採用sklearn.linear_model.SGDClassifier庫函數來實現LR的增量式學習。通過設置默認的SGDClassifier超參數,採用分塊式訓練,得出訓練過程損失(log-loss)曲線如下圖所示。
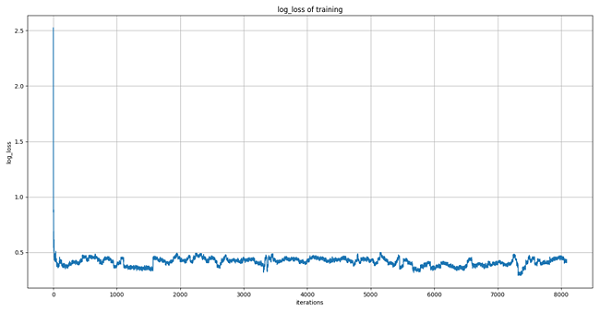
初步分析曲線收斂狀況可知,訓練過程損失指標始終處於log-loss=0.4左右微振盪。猜測LR模型已大致完成對當前數據的擬合,但效果欠佳。採用經此訓練的模型進行預測,得出結果提交至Kaggle評分爲:
- private:0.4172740 (rank 75%)
- public: 0.4155279 (rank 74%)
之後,我們嘗試引入更多的原始特徵進行LR實驗,獲得了一定的結果提升,如:
- private:0.4097192 (rank 72%)
- public: 0.4118247 (rank 72%)
4.小結
本文圍繞Avazu-CTR預估任務,以LR-based爲基本方案,相繼完成了:
- 任務和數據的解析;
- 原始特徵抽取及其One-Hot編碼預處理;
- LR訓練及預測;
三部分的內容,取得了初步的評分結果。之後還可以在模型的選擇與改進、特徵工程的細緻深入、訓練調優策略的積極嘗試等方面入手,進一步研究提高CTR預估效果。
5.參考資料
- 賽題主頁:Click-Through Rate Prediction
- 數據處理技巧:Pandas: Filter dataframe for values that are too frequent or too rare
- 數據處理技巧:How to One Hot Encode Categorical Variables of a Large Dataset in Python?
轉自:https://pnyuan.github.io/blog/ml_practice/Kaggle%E6%BB%91%E6%B0%B4%20-%20CTR%E9%A2%84%E4%BC%B0%EF%BC%88LR%EF%BC%89/

