




生存分析是研究生存時間的分佈規律,以及生存時間和相關因素之間關係的一種統計分析方法
其主要應用領域:
-
Cancer studies for patients survival time analyses(臨牀癌症上病人生存分析)
-
Sociology for “event-history analysis”(我也不懂)
-
engineering for “failure-time analysis”(類似於機器使用壽命,故障等研究)
在癌症研究中,其典型研究問題則有:
-
What is the impact of certain clinical characteristics on patient’s survival(某些臨牀特徵對病人的影響有哪些)
-
What is the probability that an individual survives 3 years?(病人個體三年存活率有多少)
-
Are there differences in survival between groups of patients?(兩組病人之間的生存率有什麼差異)
生存分析使用的方法:
- Kaplan-Meier plots to visualize survival curves(根據生存時間分佈,估計生存率以及中位生存時間,以生存曲線方式展示,從而分析生存特徵,一般用Kaplan-Meier法,還有壽命法)
- Log-rank test to compare the survival curves of two or more groups(通過比較兩組或者多組之間的的生存曲線,一般是生存率及其標準誤,從而研究之間的差異,一般用log rank檢驗)
- Cox proportional hazards regression to describe the effect of variables on survival(用Cox風險比例模型來分析變量對生存的影響,可以兩個及兩個以上的因素,很常用)
所以一般做生存分析,可以用KM(Kaplan-Meier)方法估計生存率,做生存曲線,然後可以根據分組檢驗一下多組間生存曲線是否有顯著的差異,最後用Cox風險比例模型來研究下某個因素對生存的影響
基本術語:
- Event(事件):在癌症研究中,事件可以是Relapse,Progression以及Death
- Survival time(生存時間):一般指某個事件的開始到終止這段事件,如癌症研究中的疾病確診到緩解或者死亡,其中有幾個比較重要的腫瘤臨牀試驗終點:
- OS(overall survival):指從開始到任意原因死亡的時間,我們一般見到的5年生存率、10年生存率都是基於OS的
- progression-free survival(PFS,無進展生存期):指從開始到腫瘤發生任意進展或者發生死亡的時間;PFS相比OS包含了惡化這個概念,可用於評估一些治療的臨牀效益
- time to progress(TTP,疾病進展時間):從開始到腫瘤發生任意進展或者進展前死亡的時間;TTP相比PFS只包含了腫瘤的惡化,不包含死亡
- disease-free survival(DFS,無病生存期):指從開始到腫瘤復發或者任何原因死亡的時間;常用於根治性手術治療或放療後的輔助治療,如乳腺癌術後內分泌療法等:
- event free survival(EFS,無事件生存期):指從開始到發生任何事件的時間,這裏的事件包括腫瘤進展,死亡,治療方案的改變,致死副作用等(主要用於病程較長的惡性腫瘤、或該實驗方案危險性高等情況下)
- Censoring(刪失):這經常會在臨牀資料中看到,生存分析中也有其對應的參數,一般指不是由死亡引起的的數據丟失,可能是失訪,可能是非正常原因退出,可能是時間終止而事件未發等等,一般在展示時以‘+’號顯示
- left censored(左刪失):只知道實際生存時間小於觀察到的生存時間
- right censored(右刪失):只知道實際生存時間大於觀察到的生存時間
- interval censored(區間刪失):只知道實際生存時間在某個時間區間範圍內
我們前面瞭解到生存分析需要計算生存率,而生存率(survival rate)則可以看作條件生存概率(conditional probability of survival)的累積,比如三年生存率則是第1-3年每年存活概率的乘積
生存分析的方法一般可以分爲三類:
- 參數法:知道生存時間的分佈模型,然後根據數據來估計模型參數,最後以分佈模型來計算生存率
- 非參數法:不需要生存時間分佈,根據樣本統計量來估計生存率,常見方法Kaplan-Meier法(乘積極限法)、壽命法
- 半參數法:也不需要生存時間的分佈,但最終是通過模型來評估影響生存率的因素,最爲常見的是Cox迴歸模型
而生存曲線(survival curve)則是將每個時間點的生存率連接在一起的曲線,一般隨訪時間爲X軸,生存率爲Y軸;曲線平滑則說明高生存率,反之則低生存率;中位生存率(median survival time)越長,則說明預後較好
簡單看下Kaplan-Meier方法是怎麼計算的:
S(ti)=S(ti−1)(1−di/ni)
- S(ti−1)指在ti−1年還存活的概率
- ni指在在ti年之前還存活的人數
- di指在事件發生的人數
- t0=0,S(0)=1
如果想更加通俗的瞭解生存率/生存曲線/乘積極限法等概念,可以看畫說統計 | 生存分析之Kaplan-Meier曲線都告訴我們什麼,比教科書版的解釋通俗易懂多啦
最後來看下如何用R來做生存分析
先加載必要的兩個包
library("survival")
library("survminer")
使用R包自帶的測試數據
data("lung")
> head(lung)
inst time status age sex ph.ecog ph.karno pat.karno meal.cal wt.loss
1 3 306 2 74 1 1 90 100 1175 NA
2 3 455 2 68 1 0 90 90 1225 15
3 3 1010 1 56 1 0 90 90 NA 15
4 5 210 2 57 1 1 90 60 1150 11
5 1 883 2 60 1 0 100 90 NA 0
6 12 1022 1 74 1 1 50 80 513 0
列名分別是(抄一下了):
* inst: Institution code
* time: Survival time in days
* status: censoring status 1=censored, 2=dead
* age: Age in years
* sex: Male=1 Female=2
* ph.ecog: ECOG performance score (0=good 5=dead)
* ph.karno: Karnofsky performance score (bad=0-good=100) rated by physician
* pat.karno: Karnofsky performance score as rated by patient
* meal.cal: Calories consumed at meals
* wt.loss: Weight loss in last six months
接着用Surv()函數創建生存數據對象(主要輸入生存時間和狀態邏輯值),再用survfit()函數對生存數據對象擬合生存函數,創建KM(Kaplan-Meier)生存曲線
fit <- survfit(Surv(time, status) ~ sex, data = lung)
> print(fit)
Call: survfit(formula = Surv(time, status) ~ sex, data = lung)
n events median 0.95LCL 0.95UCL
sex=1 138 112 270 212 310
sex=2 90 53 426 348 550
如果想看整體的fit結果,可以summary(fit) or summary(fit)$table,但是想看每個時間點的更好的方式則是:
res.sum <- surv_summary(fit)
> head(res.sum)
time n.risk n.event n.censor surv std.err upper lower strata sex
1 11 138 3 0 0.9782609 0.01268978 1.0000000 0.9542301 sex=1 1
2 12 135 1 0 0.9710145 0.01470747 0.9994124 0.9434235 sex=1 1
3 13 134 2 0 0.9565217 0.01814885 0.9911586 0.9230952 sex=1 1
4 15 132 1 0 0.9492754 0.01967768 0.9866017 0.9133612 sex=1 1
5 26 131 1 0 0.9420290 0.02111708 0.9818365 0.9038355 sex=1 1
6 30 130 1 0 0.9347826 0.02248469 0.9768989 0.8944820 sex=1 1
具體每個列的含義如下(再抄一下):
* time: the time points on the curve.
* n.risk: the number of subjects at risk at time t
* n.event: the number of events that occurred at time t.
* n.censor: the number of censored subjects, who exit the risk set, without an event, at time t.
* surv: estimate of survival probability.
* std.err: standard error of survival.
* upper: upper end of confidence interval
* lower: lower end of confidence interval
* strata: indicates stratification of curve estimation. If strata is not NULL, there are multiple curves in the result. The levels of strata (a factor) are the labels for the curves.
根據上述fit結果,我們可以將KM生存數據進行可視化,主要使用Survminer包的ggsurvplot()函數,如下(這裏我們在survfit()函數時用性別因子進行了分組,所以生存曲線有兩組,即兩條曲線;如果不想分組,將sex換成1即可):
ggsurvplot(fit,
pval = TRUE, conf.int = TRUE,
risk.table = TRUE, # Add risk table
risk.table.col = "strata", # Change risk table color by groups
linetype = "strata", # Change line type by groups
surv.median.line = "hv", # Specify median survival
ggtheme = theme_bw(), # Change ggplot2 theme
palette = c("#E7B800", "#2E9FDF")
)

如果想對上圖再進行自定義修改,看下ggsurvplot函數說明即可
如果在參數里加上fun = "event"則可繪製cumulative events圖(fun除了even外,還有log:log transformation和cumhaz:cumulative hazard)
ggsurvplot(fit,
conf.int = TRUE,
risk.table.col = "strata", # Change risk table color by groups
ggtheme = theme_bw(), # Change ggplot2 theme
palette = c("#E7B800", "#2E9FDF"),
fun = "event")
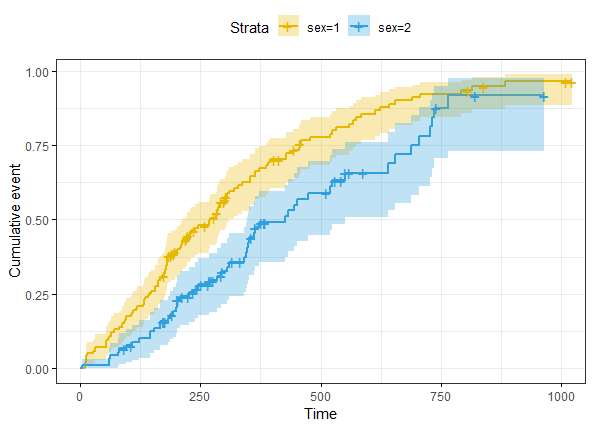
最後如果想對不同組的生存率進行假設檢驗(Log-Rank test)的話,可以用survdiff()函數,Log-Rank test是無參數檢驗,近似於卡方檢驗,零假設是組間沒有差異
surv_diff <- survdiff(Surv(time, status) ~ sex, data = lung)
> surv_diff
Call:
survdiff(formula = Surv(time, status) ~ sex, data = lung)
N Observed Expected (O-E)^2/E (O-E)^2/V
sex=1 138 112 91.6 4.55 10.3
sex=2 90 53 73.4 5.68 10.3
Chisq= 10.3 on 1 degrees of freedom, p= 0.001
不僅從圖中可看出性別組間生存曲線是有差異的,也從Log-Rank test的P值0.001也可得出性別組有顯著差異