Cox比例風險模型(cox proportional-hazards model),簡稱Cox模型
是由英國統計學家D.R.Cox(1972)年提出的一種半參數迴歸模型。該模型以生存結局和生存時間爲應變量,可同時分析衆多因素對生存期的影響,能分析帶有截尾生存時間的資料,且不要求估計資料的生存分佈類型
Cox模型的基本假設爲:
在任意一個時間點,兩組人羣發生時間的風險比例是恆定的;或者說其危險曲線應該是成比例而且是不能交叉的;也就是如果一個體在某個時間點的死亡風險是另外一個體的兩倍,那麼在其他任意時間點的死亡風險也同樣是2倍
總之,Cox模型的協變量(變量因素)參數必須滿足上述假設,但是有時在研究過程中會遇到延遲反應、假性進展,從而導致生存曲線(如PFS)早期就糾纏在一起,幾個月後才分開,這在免疫療法中會遇到免疫治療困局:COX模型不符合等比例風險假設怎麼辦?,這時Cox模型的假設就不成立了
如果事件的終點不止一個,即存在多個終點並同時競爭風險,那麼Cox模型也是不適用了,一般這時會考慮適用競爭風險模型,而這些終點事件互被稱爲競爭風險事件
Cox模型與Kaplan-Meier法:
- Kaplan-Meier法是非參數法,而Cox模型是半參數法,一般來說在符合一定條件下,後者的檢驗效應要大於前者
- Kaplan-Meier法一般處理單因素對研究生存結局的影響,而Cox模型可以同時處理多個因素對生存結局的影響
Cox模型可以由hazard function表示,h(t);簡單的說就是t時刻死亡的風險,公式如下:
h(t)=h0(t) × exp(b1x1 + b2x2 +…+ bpxp)
- t代表生存時間
- x1-xp代表協變量
- b1-bp代表協變量的迴歸係數
接着如何在R中計算Cox模型
同樣還是用到以下兩個包:
library("survival")
library("survminer")
計算Cox模型主要用到的是coxph()函數,但需要先用Surv()函數產生一個生存對象;另外coxph()函數支持的方法有:exact,breslow以及exact,默認是exact
以lung數據集爲例,看下性別因素對生存結局的影響
data("lung")
res.cox <- coxph(Surv(time, status) ~ sex, data = lung)
> summary(res.cox)
Call:
coxph(formula = Surv(time, status) ~ sex, data = lung)
n= 228, number of events= 165
coef exp(coef) se(coef) z Pr(>|z|)
sex -0.5310 0.5880 0.1672 -3.176 0.00149 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
exp(coef) exp(-coef) lower .95 upper .95
sex 0.588 1.701 0.4237 0.816
Concordance= 0.579 (se = 0.022 )
Rsquare= 0.046 (max possible= 0.999 )
Likelihood ratio test= 10.63 on 1 df, p=0.001
Wald test = 10.09 on 1 df, p=0.001
Score (logrank) test = 10.33 on 1 df, p=0.001
上述summary結果中的coef就是公式中的迴歸係數b(有時也叫做beta值),因此exp(coef)則是Cox模型中最主要的概念風險比(HR-hazard ratio):
- HR = 1: No effect
- HR < 1: Reduction in the hazard
- HR > 1: Increase in Hazard
在癌症研究中:
- hazard ratio > 1 is called bad prognostic factor
- hazard ratio < 1 is called good prognostic factor
z(-3.176)值代表Wald統計量,其值等於迴歸係數coef除以其標準誤se(coef),即z = coef/se(coef);有統計量必有其對應的假設檢驗的顯著性P值(0.00149),其說明bata值是否與0有統計學意義上的顯著差別
coef(-0.5310)值小於0說明HR值小於1,而這裏的Cox模型是group two相對於group one而言的,那麼按照測試數據集來說:male=1,female=1,即女性的死亡風險相比男性要低
exp(coef)等於0.59,即風險比例等於0.59,說明女性(male=2)減少了0.59倍風險,女性與良好預後相關
lower .95 upper .95則是exp(coef)的95%置信區間
Likelihood ratio test,Wald test,Score (logrank) test則是給出了3種可選擇的P值,這三者是asymptotically equivalent;當樣本數目足夠大時(我也不知道多少樣本是足夠大。。),這三者的值是相似的;當樣本數目較少時,這三者是有差別的,但是Likelihood ratio test會比其他兩種在小樣本中表現的更優
Cox模型在於其可以對多因素進行Cox迴歸分析,如我們想同時考慮年齡、性別以及ECOG performance score(ph.ecog)對生存結局的影響
res.cox <- coxph(Surv(time, status) ~ age + sex + ph.ecog, data = lung)
> summary(res.cox)
Call:
coxph(formula = Surv(time, status) ~ age + sex + ph.ecog, data = lung)
n= 227, number of events= 164
(1 observation deleted due to missingness)
coef exp(coef) se(coef) z Pr(>|z|)
age 0.011067 1.011128 0.009267 1.194 0.232416
sex -0.552612 0.575445 0.167739 -3.294 0.000986 ***
ph.ecog 0.463728 1.589991 0.113577 4.083 4.45e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
exp(coef) exp(-coef) lower .95 upper .95
age 1.0111 0.9890 0.9929 1.0297
sex 0.5754 1.7378 0.4142 0.7994
ph.ecog 1.5900 0.6289 1.2727 1.9864
Concordance= 0.637 (se = 0.026 )
Rsquare= 0.126 (max possible= 0.999 )
Likelihood ratio test= 30.5 on 3 df, p=1e-06
Wald test = 29.93 on 3 df, p=1e-06
Score (logrank) test = 30.5 on 3 df, p=1e-06
這裏的結果形式大致上跟單因素的一樣,我們主要需要看的是以下幾點:
Likelihood ratio test/Wald test/Score (logrank) test三種假設檢驗方法給出的P值說明Cox模型對三個因素均進行了beta值是否爲0的假設檢驗,並且拒絕了omnibus null hypothesis(beta=0的零假設)
該模型結果給出了三個因素各自在其他因素保持不變下的HR以及P值;比如年齡因素的HR=1.01以及P=0.23,說明年齡因素在調整了性別和ph.ecog因素的影響後,其對HR的變化貢獻較小(只有1%)
而看性別因素,HR=0.58,以及P=0.000986,說明在保持其他因素不變的情況下,年齡和死亡風險有很強的關係,女性能將死亡風險降低0.58倍,再次說明了女性與良好預後相關
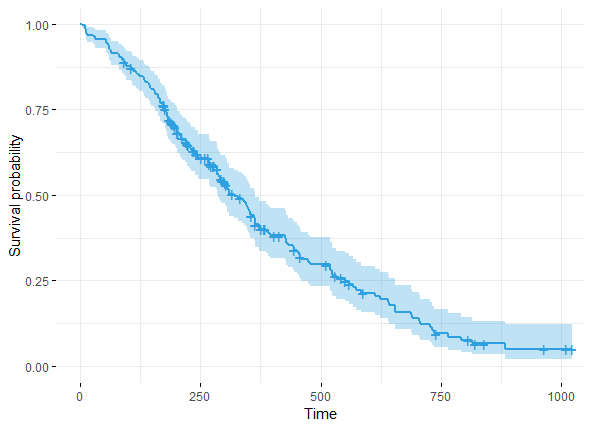
最後看下生存曲線
根據數據擬合的Cox模型,我們可以將其在各個時間的預測的生存比例進行可視化展示。使用survfit()函數評估生存比例,默認是依據所有因素(協變量)的平均值
ggsurvplot(survfit(res.cox), data = lung, palette = "#2E9FDF",
ggtheme = theme_minimal(), legend = "none")
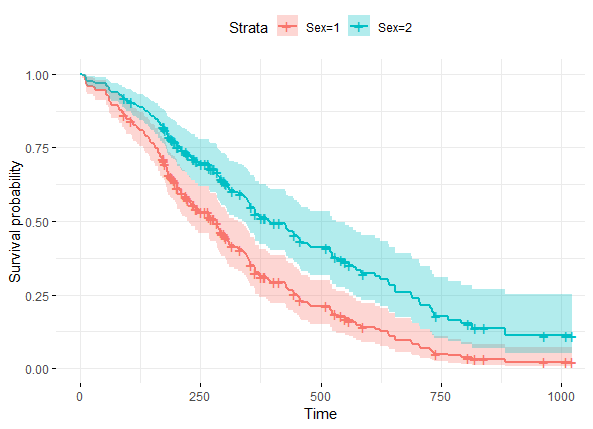
如果想單獨看一下上面這個Cox模型中某個因素(協變量)的預測可視化圖,教程中則是將其他兩個因素(協變量)做些處理:
In this case, we construct a new data frame with two rows, one for each value of sex; the other covariates are fixed to their average values (if they are continuous variables) or to their lowest level (if they are discrete variables). For a dummy covariate, the average value is the proportion coded 1 in the data set
代碼照搬下:
# Create the new data
sex_df <- with(lung,
data.frame(sex = c(1, 2),
age = rep(mean(age, na.rm = TRUE), 2),
ph.ecog = c(1, 1)
)
)
fit <- survfit(res.cox, newdata = sex_df)
ggsurvplot(fit, data = sex_df, conf.int = TRUE,
legend.labs=c("Sex=1", "Sex=2"),
ggtheme = theme_minimal())