




生產級負載均衡算法詳解
負載均衡介紹
負載均衡,英文名稱爲Load Balance,指由多臺服務器以對稱的方式組成一個服務器集合,每臺服務器都具有等價的地位,都可以單獨對外提供服務而無須其他服務器的輔助。
通過某種負載分擔技術,將外部發送來的請求均勻分配到對稱結構中的某一臺服務器上,而接收到請求的服務器獨立地迴應客戶的請求。
負載均衡能夠平均分配客戶請求到服務器陣列,藉此提供快速獲取重要數據,解決大量併發訪問服務問題,這種集羣技術可以用最少的投資獲得接近於大型主機的性能。
負載均衡方式
負載均衡分爲軟件負載均衡和硬件負載均衡
建議沒有相關軟件使用經驗的朋友們不要太糾結他們的不同之處,可繼續往下看I
軟件負載均衡
常見的負載均衡軟件有Nginx、LVS、HAProxy。
關於這幾個軟件的特點比較不是本文重點,本文就不多做闡述。
硬件負載均衡
常見的負載均衡硬件有Array、F5。
負載均衡算法
常見的負載均衡算法有:隨機算法、加權輪詢、一致性hash、最小活躍數算法。
千萬別以爲這幾個算法看上去都特別簡單,但其實真正在生產上用到時會遠比你想的複雜
算法前提條件
定義一個服務器列表,每個負載均衡的算法會從中挑出一個服務器作爲算法的結果。
public class ServerIps {
private static final List<String> LIST = Arrays.asList(
"192.168.0.1",
"192.168.0.2",
"192.168.0.3",
"192.168.0.4",
"192.168.0.5",
"192.168.0.6",
"192.168.0.7",
"192.168.0.8",
"192.168.0.9",
"192.168.0.10"
);
}隨機算法-RandomLoadBalance
先來個最簡單的實現。
public class Random {
public static String getServer() {
// 生成一個隨機數作爲list的下標值
java.util.Random random = new java.util.Random();
int randomPos = random.nextInt(ServerIps.LIST.size());
return ServerIps.LIST.get(randomPos);
}
public static void main(String[] args) {
// 連續調用10次
for (int i=0; i<10; i++) {
System.out.println(getServer());
}
}
}運行結果: 192.168.0.3 192.168.0.4 192.168.0.7 192.168.0.1 192.168.0.2 192.168.0.7 192.168.0.3 192.168.0.9 192.168.0.1 192.168.0.1
當調用次數比較少時,Random 產生的隨機數可能會比較集中,此時多數請求會落到同一臺服務器上,只有在經過多次請求後,才能使調用請求進行“均勻”分配。調用量少這一點並沒有什麼關係,負載均衡機制不正是爲了應對請求量多的情況嗎,所以隨機算法也是用得比較多的一種算法。
但是,上面的隨機算法適用於每天機器的性能差不多的時候,實際上,生產中可能某些機器的性能更高一點,它可以處理更多的請求,所以,我們可以對每臺服務器設置一個權重。
在ServerIps類中增加服務器權重對應關係MAP,權重之和爲50:
public static final Map<String, Integer> WEIGHT_LIST = new HashMap<String, Integer>();
static {
// 權重之和爲50
WEIGHT_LIST.put("192.168.0.1", 1);
WEIGHT_LIST.put("192.168.0.2", 8);
WEIGHT_LIST.put("192.168.0.3", 3);
WEIGHT_LIST.put("192.168.0.4", 6);
WEIGHT_LIST.put("192.168.0.5", 5);
WEIGHT_LIST.put("192.168.0.6", 5);
WEIGHT_LIST.put("192.168.0.7", 4);
WEIGHT_LIST.put("192.168.0.8", 7);
WEIGHT_LIST.put("192.168.0.9", 2);
WEIGHT_LIST.put("192.168.0.10", 9);
}那麼現在的隨機算法應該要改成權重隨機算法,當調用量比較多的時候,服務器使用的分佈應該近似對應權重的分佈。
權重隨機算法
簡單的實現思路是,把每個服務器按它所對應的服務器進行復制,具體看代碼更加容易理解
public class WeightRandom {
public static String getServer() {
// 生成一個隨機數作爲list的下標值
List<String> ips = new ArrayList<String>();
for (String ip : ServerIps.WEIGHT_LIST.keySet()) {
Integer weight = ServerIps.WEIGHT_LIST.get(ip);
// 按權重進行復制
for (int i=0; i<weight; i++) {
ips.add(ip);
}
}
java.util.Random random = new java.util.Random();
int randomPos = random.nextInt(ips.size());
return ips.get(randomPos);
}
public static void main(String[] args) {
// 連續調用10次
for (int i=0; i<10; i++) {
System.out.println(getServer());
}
}
}運行結果: 192.168.0.8 192.168.0.2 192.168.0.7 192.168.0.10 192.168.0.8 192.168.0.8 192.168.0.4 192.168.0.7 192.168.0.6 192.168.0.8
這種實現方法在遇到權重之和特別大的時候就會比較消耗內存,因爲需要對ip地址進行復制,權重之和越大那麼上文中的ips就需要越多的內存,下面介紹另外一種實現思路。
假設我們有一組服務器 servers = [A, B, C],他們對應的權重爲 weights = [5, 3, 2],權重總和爲10。現在把這些權重值平鋪在一維座標值上,[0, 5) 區間屬於服務器 A,[5, 8) 區間屬於服務器 B,[8, 10) 區間屬於服務器 C。接下來通過隨機數生成器生成一個範圍在 [0, 10) 之間的隨機數,然後計算這個隨機數會落到哪個區間上。比如數字3會落到服務器 A 對應的區間上,此時返回服務器 A 即可。權重越大的機器,在座標軸上對應的區間範圍就越大,因此隨機數生成器生成的數字就會有更大的概率落到此區間內。只要隨機數生成器產生的隨機數分佈性很好,在經過多次選擇後,每個服務器被選中的次數比例接近其權重比例。比如,經過一萬次選擇後,服務器 A 被選中的次數大約爲5000次,服務器 B 被選中的次數約爲3000次,服務器 C 被選中的次數約爲2000次。
假設現在隨機數offset=7:
offset<5 is false,所以不在[0, 5)區間,將offset = offset - 5(offset=2)
offset<3 is true,所以處於[5, 8)區間,所以應該選用B服務器
實現如下
public class WeightRandomV2 {
public static String getServer() {
int totalWeight = 0;
boolean sameWeight = true; // 如果所有權重都相等,那麼隨機一個ip就好了
Object[] weights = ServerIps.WEIGHT_LIST.values().toArray();
for (int i = 0; i < weights.length; i++) {
Integer weight = (Integer) weights[i];
totalWeight += weight;
if (sameWeight && i > 0 && !weight.equals(weights[i - 1])) {
sameWeight = false;
}
}
java.util.Random random = new java.util.Random();
int randomPos = random.nextInt(totalWeight);
if (!sameWeight) {
for (String ip : ServerIps.WEIGHT_LIST.keySet()) {
Integer value = ServerIps.WEIGHT_LIST.get(ip);
if (randomPos < value) {
return ip;
}
randomPos = randomPos - value;
}
}
return (String) ServerIps.WEIGHT_LIST.keySet().toArray()[new java.util.Random().nextInt(ServerIps.WEIGHT_LIST.size())];
}
public static void main(String[] args) {
// 連續調用10次
for (int i = 0; i < 10; i++) {
System.out.println(getServer());
}
}
}這就是另外一種權重隨機算法。
輪詢算法-RoundRobinLoadBalance
簡單的輪詢算法很簡單
public class RoundRobin {
// 當前循環的位置
private static Integer pos = 0;
public static String getServer() {
String ip = null;
// pos同步
synchronized (pos) {
if (pos >= ServerIps.LIST.size()) {
pos = 0;
}
ip = ServerIps.LIST.get(pos);
pos++;
}
return ip;
}
public static void main(String[] args) {
// 連續調用10次
for (int i = 0; i < 11; i++) {
System.out.println(getServer());
}
}
}運行結果: 192.168.0.1 192.168.0.2 192.168.0.3 192.168.0.4 192.168.0.5 192.168.0.6 192.168.0.7 192.168.0.8 192.168.0.9 192.168.0.10 192.168.0.1
這種算法很簡單,也很公平,每臺服務輪流來進行服務,但是有的機器性能好,所以能者多勞,和隨機算法一下,加上權重這個維度之後,其中一種實現方法就是複製法,這裏就不演示了,這種複製算法的缺點和隨機算法的是一樣的,比較消耗內存,那麼自然就有其他實現方法。我下面來介紹一種算法:
這種算法需要加入一個概念:調用編號,比如第1次調用爲1, 第2次調用爲2, 第100次調用爲100,調用編號是遞增的,所以我們可以根據這個調用編號推算出服務器。
假設我們有三臺服務器 servers = [A, B, C],對應的權重爲 weights = [ 2, 5, 1], 總權重爲8,我們可以理解爲有8臺“服務器”,這是8臺“不具有併發功能”,其中有2臺爲A,5臺爲B,1臺爲C,一次調用過來的時候,需要按順序訪問,比如有10次調用,那麼服務器調用順序爲AABBBBBCAA,調用編號會越來越大,而服務器是固定的,所以需要把調用編號“縮小”,這裏對調用編號進行取餘,除數爲總權重和,比如:
1號調用,1%8=1;
2號調用,2%8=2;
3號調用,3%8=3;
8號調用,8%8=0;
9號調用,9%8=1;
100號調用,100%8=4;
我們發現調用編號可以被縮小爲0-7之間的8個數字,問題是怎麼根據這個8個數字找到對應的服務器呢?和我們隨機算法類似,這裏也可以把權重想象爲一個座標軸“0-----2-----7-----8”1號調用,1%8=1,offset = 1, offset <= 2 is true,取A;
2號調用,2%8=2;offset = 2,offset <= 2 is true, 取A;
3號調用,3%8=3;offset = 3, offset <= 2 is false, offset = offset - 2, offset = 1, offset <= 5,取B
8號調用,8%8=0;offset = 0, 特殊情況,offset = 8,offset <= 2 is false, offset = offset - 2, offset = 6, offset <= 5 is false, offset = offset - 5, offset = 1, offset <= 1 is true, 取C;
9號調用,9%8=1;// …
100號調用,100%8=4; //…
實現:
模擬調用編號獲取工具:
public class Sequence {
public static Integer num = 0;
public static Integer getAndIncrement() {
return ++num;
}
}public class WeightRoundRobin {
private static Integer pos = 0;
public static String getServer() {
int totalWeight = 0;
boolean sameWeight = true; // 如果所有權重都相等,那麼隨機一個ip就好了
Object[] weights = ServerIps.WEIGHT_LIST.values().toArray();
for (int i = 0; i < weights.length; i++) {
Integer weight = (Integer) weights[i];
totalWeight += weight;
if (sameWeight && i > 0 && !weight.equals(weights[i - 1])) {
sameWeight = false;
}
}
Integer sequenceNum = Sequence.getAndIncrement();
Integer offset = sequenceNum % totalWeight;
offset = offset == 0 ? totalWeight : offset;
if (!sameWeight) {
for (String ip : ServerIps.WEIGHT_LIST.keySet()) {
Integer weight = ServerIps.WEIGHT_LIST.get(ip);
if (offset <= weight) {
return ip;
}
offset = offset - weight;
}
}
String ip = null;
synchronized (pos) {
if (pos >= ServerIps.LIST.size()) {
pos = 0;
}
ip = ServerIps.LIST.get(pos);
pos++;
}
return ip;
}
public static void main(String[] args) {
// 連續調用11次
for (int i = 0; i < 11; i++) {
System.out.println(getServer());
}
}
}運行結果: 192.168.0.1 192.168.0.2 192.168.0.2 192.168.0.2 192.168.0.2 192.168.0.2 192.168.0.2 192.168.0.2 192.168.0.2 192.168.0.3 192.168.0.3
但是這種算法有一個缺點:一臺服務器的權重特別大的時候,他需要連續的的處理請求,但是實際上我們想達到的效果是,對於100次請求,只要有100*8/50=16次就夠了,這16次不一定要連續的訪問,比如假設我們有三臺服務器 servers = [A, B, C],對應的權重爲 weights = [5, 1, 1] , 總權重爲7,那麼上述這個算法的結果是:AAAAABC,那麼如果能夠是這麼一個結果呢:AABACAA,把B和C平均插入到5個A中間,這樣是比較均衡的了。
我們這裏可以改成平滑加權輪詢。
平滑加權輪詢
思路:每個服務器對應兩個權重,分別爲 weight 和 currentWeight。其中 weight 是固定的,currentWeight 會動態調整,初始值爲0。當有新的請求進來時,遍歷服務器列表,讓它的 currentWeight 加上自身權重。遍歷完成後,找到最大的 currentWeight,並將其減去權重總和,然後返回相應的服務器即可。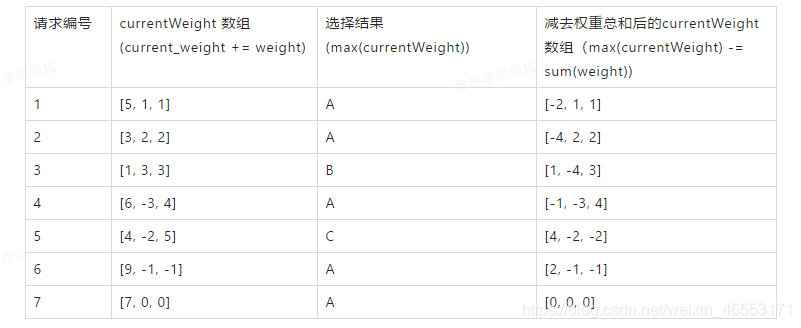
如上,經過平滑性處理後,得到的服務器序列爲 [A, A, B, A, C, A, A],相比之前的序列 [A, A, A, A, A, B, C],分佈性要好一些。初始情況下 currentWeight = [0, 0, 0],第7個請求處理完後,currentWeight 再次變爲 [0, 0, 0]。
實現:
// 增加一個Weight類,用來保存ip, weight(固定不變的原始權重), currentweight(當前會變化的權重)
public class Weight {
private String ip;
private Integer weight;
private Integer currentWeight;
public Weight(String ip, Integer weight, Integer currentWeight) {
this.ip = ip;
this.weight = weight;
this.currentWeight = currentWeight;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public Integer getWeight() {
return weight;
}
public void setWeight(Integer weight) {
this.weight = weight;
}
public Integer getCurrentWeight() {
return currentWeight;
}
public void setCurrentWeight(Integer currentWeight) {
this.currentWeight = currentWeight;
}
}public class WeightRoundRobinV2 {
private static Map<String, Weight> weightMap = new HashMap<String, Weight>();
public static String getServer() {
// java8
int totalWeight = ServerIps.WEIGHT_LIST.values().stream().reduce(0, (w1, w2) -> w1+w2);
// 初始化weightMap,初始時將currentWeight賦值爲weight
if (weightMap.isEmpty()) {
ServerIps.WEIGHT_LIST.forEach((key, value) -> {
weightMap.put(key, new Weight(key, value, value));
});
}
// 找出currentWeight最大值
Weight maxCurrentWeight = null;
for (Weight weight : weightMap.values()) {
if (maxCurrentWeight == null || weight.getCurrentWeight() > maxCurrentWeight.getCurrentWeight()) {
maxCurrentWeight = weight;
}
}
// 將maxCurrentWeight減去總權重和
maxCurrentWeight.setCurrentWeight(maxCurrentWeight.getCurrentWeight() - totalWeight);
// 所有的ip的currentWeight統一加上原始權重
for (Weight weight : weightMap.values()) {
weight.setCurrentWeight(weight.getCurrentWeight() + weight.getWeight());
}
// 返回maxCurrentWeight所對應的ip
return maxCurrentWeight.getIp();
}
public static void main(String[] args) {
// 連續調用10次
for (int i = 0; i < 10; i++) {
System.out.println(getServer());
}
}
}講ServerIps裏的數據簡化爲:
WEIGHT_LIST.put("A", 5);
WEIGHT_LIST.put("B", 1);
WEIGHT_LIST.put("C", 1);
```運行結果: A A B A C A A A A B
這就是輪詢算法,一個循環很簡單,但是真正在實際運用的過程中需要思考更多。
一致性哈希算法-ConsistentHashLoadBalance
服務器集羣接收到一次請求調用時,可以根據根據請求的信息,比如客戶端的ip地址,或請求路徑與請求參數等信息進行哈希,可以得出一個哈希值,特點是對於相同的ip地址,或請求路徑和請求參數哈希出來的值是一樣的,只要能再增加一個算法,能夠把這個哈希值映射成一個服務端ip地址,就可以使相同的請求(相同的ip地址,或請求路徑和請求參數)落到同一服務器上。
因爲客戶端發起的請求情況是無窮無盡的(客戶端地址不同,請求參數不同等等),所以對於的哈希值也是無窮大的,所以我們不可能把所有的哈希值都進行映射到服務端ip上,所以這裏需要用到哈希環。如下圖: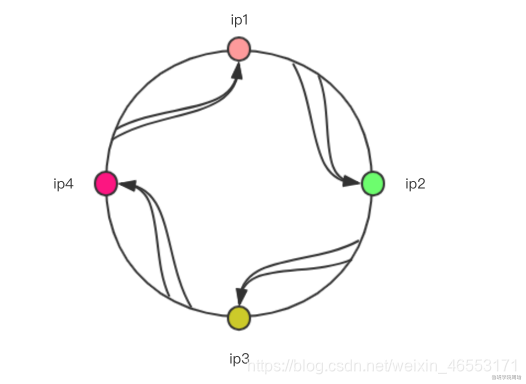
• 哈希值如果需要ip1和ip2之間的,則應該選擇ip2作爲結果;
• 哈希值如果需要ip2和ip3之間的,則應該選擇ip3作爲結果;
• 哈希值如果需要ip3和ip4之間的,則應該選擇ip4作爲結果;
• 哈希值如果需要ip4和ip1之間的,則應該選擇ip1作爲結果;
上面這情況是比較均勻情況,如果出現ip4服務器不存在,那就是這樣了:
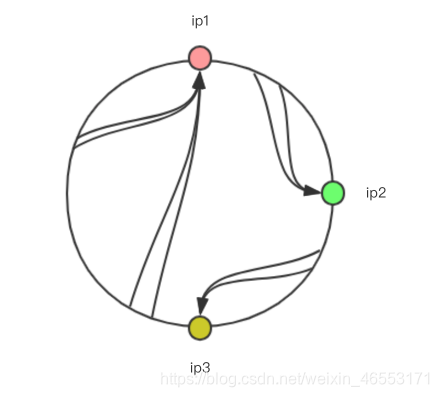
會發現,ip3和ip1直接的範圍是比較大的,會有更多的請求落在ip1上,這是不“公平的”,解決這個問題需要加入虛擬節點,比如:
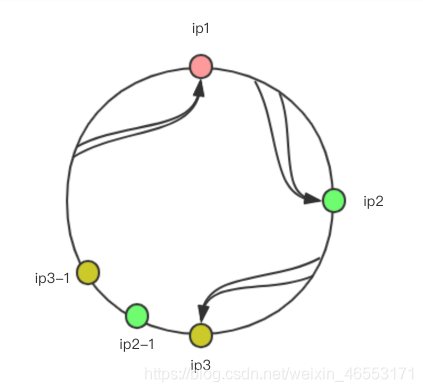
其中ip2-1, ip3-1就是虛擬結點,並不能處理節點,而是等同於對應的ip2和ip3服務器。
實際上,這只是處理這種不均衡性的一種思路,實際上就算哈希環本身是均衡的,你也可以增加更多的虛擬節點來使這個環更加平滑,比如:
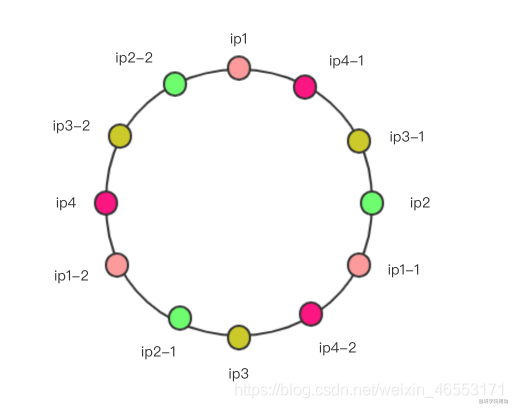
這個彩環也是“公平的”,並且只有ip1,2,3,4是實際的服務器ip,其他的都是虛擬ip。
那麼我們怎麼來實現呢?
對於我們的服務端ip地址,我們肯定知道總共有多少個,需要多少個虛擬節點也有我們自己控制,虛擬節點越多則流量越均衡,另外哈希算法也是很關鍵的,哈希算法越散列流量也將越均衡。
實現:
public class ConsistentHash {
private static SortedMap<Integer, String> virtualNodes = new TreeMap<>();
private static final int VIRTUAL_NODES = 160;
static {
// 對每個真實節點添加虛擬節點,虛擬節點會根據哈希算法進行散列
for (String ip : ServerIps.LIST) {
for (int i = 0; i < VIRTUAL_NODES; i++) {
int hash = getHash(ip+"VN"+i);
virtualNodes.put(hash, ip);
}
}
}
private static String getServer(String client) {
int hash = getHash(client);
// 得到大於該Hash值的排好序的Map
SortedMap<Integer, String> subMap = virtualNodes.tailMap(hash);
// 大於該hash值的第一個元素的位置
Integer nodeIndex = subMap.firstKey();
// 如果不存在大於該hash值的元素,則返回根節點
if (nodeIndex == null) {
nodeIndex = virtualNodes.firstKey();
}
// 返回對應的虛擬節點名稱
return subMap.get(nodeIndex);
}
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出來的值爲負數則取其絕對值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
public static void main(String[] args) {
// 連續調用10次,隨機10個client
for (int i = 0; i < 10; i++) {
System.out.println(getServer("client" + i));
}
}
}最小活躍數算法-LeastActiveLoadBalance
前面幾種方法主要目標是使服務端分配到的調用次數儘量均衡,但是實際情況是這樣嗎?調用次數相同,服務器的負載就均衡嗎?當然不是,這裏還要考慮每次調用的時間,而最小活躍數算法則是解決這種問題的。
活躍調用數越小,表明該服務提供者效率越高,單位時間內可處理更多的請求。此時應優先將請求分配給該服務提供者。在具體實現中,每個服務提供者對應一個活躍數。初始情況下,所有服務提供者活躍數均爲0。每收到一個請求,活躍數加1,完成請求後則將活躍數減1。在服務運行一段時間後,性能好的服務提供者處理請求的速度更快,因此活躍數下降的也越快,此時這樣的服務提供者能夠優先獲取到新的服務請求、這就是最小活躍數負載均衡算法的基本思想。除了最小活躍數,最小活躍數算法在實現上還引入了權重值。所以準確的來說,最小活躍數算法是基於加權最小活躍數算法實現的。舉個例子說明一下,在一個服務提供者集羣中,有兩個性能優異的服務提供者。某一時刻它們的活躍數相同,則會根據它們的權重去分配請求,權重越大,獲取到新請求的概率就越大。如果兩個服務提供者權重相同,此時隨機選擇一個即可。
實現:
因爲活躍數是需要服務器請求處理相關邏輯配合的,一次調用開始時活躍數+1,結束是活躍數-1,所以這裏就不對這部分邏輯進行模擬了,直接使用一個map來進行模擬。
// 服務器當前的活躍數
public static final Map<String, Integer> ACTIVITY_LIST = new LinkedHashMap<String, Integer>();
static {
ACTIVITY_LIST.put("192.168.0.1", 2);
ACTIVITY_LIST.put("192.168.0.2", 0);
ACTIVITY_LIST.put("192.168.0.3", 1);
ACTIVITY_LIST.put("192.168.0.4", 3);
ACTIVITY_LIST.put("192.168.0.5", 0);
ACTIVITY_LIST.put("192.168.0.6", 1);
ACTIVITY_LIST.put("192.168.0.7", 4);
ACTIVITY_LIST.put("192.168.0.8", 2);
ACTIVITY_LIST.put("192.168.0.9", 7);
ACTIVITY_LIST.put("192.168.0.10", 3);
}public class LeastActive {
private static String getServer() {
// 找出當前活躍數最小的服務器
Optional<Integer> minValue = ServerIps.ACTIVITY_LIST.values().stream().min(Comparator.naturalOrder());
if (minValue.isPresent()) {
List<String> minActivityIps = new ArrayList<>();
ServerIps.ACTIVITY_LIST.forEach((ip, activity) -> {
if (activity.equals(minValue.get())) {
minActivityIps.add(ip);
}
});
// 最小活躍數的ip有多個,則根據權重來選,權重大的優先
if (minActivityIps.size() > 1) {
// 過濾出對應的ip和權重
Map<String, Integer> weightList = new LinkedHashMap<String, Integer>();
ServerIps.WEIGHT_LIST.forEach((ip, weight) -> {
if (minActivityIps.contains(ip)) {
weightList.put(ip, ServerIps.WEIGHT_LIST.get(ip));
}
});
int totalWeight = 0;
boolean sameWeight = true; // 如果所有權重都相等,那麼隨機一個ip就好了
Object[] weights = weightList.values().toArray();
for (int i = 0; i < weights.length; i++) {
Integer weight = (Integer) weights[i];
totalWeight += weight;
if (sameWeight && i > 0 && !weight.equals(weights[i - 1])) {
sameWeight = false;
}
}
java.util.Random random = new java.util.Random();
int randomPos = random.nextInt(totalWeight);
if (!sameWeight) {
for (String ip : weightList.keySet()) {
Integer value = weightList.get(ip);
if (randomPos < value) {
return ip;
}
randomPos = randomPos - value;
}
}
return (String) weightList.keySet().toArray()[new java.util.Random().nextInt(weightList.size())];
} else {
return minActivityIps.get(0);
}
} else {
return (String) ServerIps.WEIGHT_LIST.keySet().toArray()[new java.util.Random().nextInt(ServerIps.WEIGHT_LIST.size())];
}
}
public static void main(String[] args) {
// 連續調用10次,隨機10個client
for (int i = 0; i < 10; i++) {
System.out.println(getServer());
}
}
}這裏因爲不會對活躍數進行操作,所以結果是固定的(擔任在隨機權重的時候會隨機,具體看源碼實現,以及運行結果即可理解)。
如果有疑問歡迎在評論區留言, 一起學習交流