




當觸發一個RDD的action後,以count爲例,調用關係如下:
- org.apache.spark.rdd.RDD#count
- org.apache.spark.SparkContext#runJob
- org.apache.spark.scheduler.DAGScheduler#runJob
- org.apache.spark.scheduler.DAGScheduler#submitJob
- org.apache.spark.scheduler.DAGSchedulerEventProcessActor#receive(JobSubmitted)
- org.apache.spark.scheduler.DAGScheduler#handleJobSubmitted
其中步驟五的DAGSchedulerEventProcessActor是DAGScheduler 的與外部交互的接口代理,DAGScheduler在創建時會創建名字爲eventProcessActor的actor。這個actor的作用看它的實現就一目瞭然了:
- /**
- * The main event loop of the DAG scheduler.
- */
- def receive = {
- case JobSubmitted(jobId, rdd, func, partitions, allowLocal, callSite, listener, properties) =>
- dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, allowLocal, callSite,
- listener, properties) // 提交job,來自與RDD->SparkContext->DAGScheduler的消息。之所以在這需要在這裏中轉一下,是爲了模塊功能的一致性。
- case StageCancelled(stageId) => // 消息源org.apache.spark.ui.jobs.JobProgressTab,在GUI上顯示一個SparkContext的Job的執行狀態。
- // 用戶可以cancel一個Stage,會通過SparkContext->DAGScheduler 傳遞到這裏。
- dagScheduler.handleStageCancellation(stageId)
- case JobCancelled(jobId) => // 來自於org.apache.spark.scheduler.JobWaiter的消息。取消一個Job
- dagScheduler.handleJobCancellation(jobId)
- case JobGroupCancelled(groupId) => // 取消整個Job Group
- dagScheduler.handleJobGroupCancelled(groupId)
- case AllJobsCancelled => //取消所有Job
- dagScheduler.doCancelAllJobs()
- case ExecutorAdded(execId, host) => // TaskScheduler得到一個Executor被添加的消息。具體來自org.apache.spark.scheduler.TaskSchedulerImpl.resourceOffers
- dagScheduler.handleExecutorAdded(execId, host)
- case ExecutorLost(execId) => //來自TaskScheduler
- dagScheduler.handleExecutorLost(execId)
- case BeginEvent(task, taskInfo) => // 來自TaskScheduler
- dagScheduler.handleBeginEvent(task, taskInfo)
- case GettingResultEvent(taskInfo) => //處理獲得TaskResult信息的消息
- dagScheduler.handleGetTaskResult(taskInfo)
- case completion @ CompletionEvent(task, reason, _, _, taskInfo, taskMetrics) => //來自TaskScheduler,報告task是完成或者失敗
- dagScheduler.handleTaskCompletion(completion)
- case TaskSetFailed(taskSet, reason) => //來自TaskScheduler,要麼TaskSet失敗次數超過閾值或者由於Job Cancel。
- dagScheduler.handleTaskSetFailed(taskSet, reason)
- case ResubmitFailedStages => //當一個Stage處理失敗時,重試。來自org.apache.spark.scheduler.DAGScheduler.handleTaskCompletion
- dagScheduler.resubmitFailedStages()
- }
總結一下org.apache.spark.scheduler.DAGSchedulerEventProcessActor的作用:可以把他理解成DAGScheduler的對外的功能接口。它對外隱藏了自己內部實現的細節,也更易於理解其邏輯;也降低了維護成本,將DAGScheduler的比較複雜功能接口化。
handleJobSubmitted
org.apache.spark.scheduler.DAGScheduler#handleJobSubmitted首先會根據RDD創建finalStage。finalStage,顧名思義,就是最後的那個Stage。然後創建job,最後提交。提交的job如果滿足一下條件,那麼它將以本地模式運行:
1)spark.localExecution.enabled設置爲true 並且 2)用戶程序顯式指定可以本地運行 並且 3)finalStage的沒有父Stage 並且 4)僅有一個partition
3)和 4)的話主要爲了任務可以快速執行;如果有多個stage或者多個partition的話,本地運行可能會因爲本機的計算資源的問題而影響任務的計算速度。
要理解什麼是Stage,首先要搞明白什麼是Task。Task是在集羣上運行的基本單位。一個Task負責處理RDD的一個partition。RDD的多個patition會分別由不同的Task去處理。當然了這些Task的處理邏輯完全是一致的。這一組Task就組成了一個Stage。有兩種Task:
- org.apache.spark.scheduler.ShuffleMapTask
- org.apache.spark.scheduler.ResultTask
ShuffleMapTask根據Task的partitioner將計算結果放到不同的bucket中。而ResultTask將計算結果發送回Driver Application。一個Job包含了多個Stage,而Stage是由一組完全相同的Task組成的。最後的Stage包含了一組ResultTask。
在用戶觸發了一個action後,比如count,collect,SparkContext會通過runJob的函數開始進行任務提交。最後會通過DAG的event processor 傳遞到DAGScheduler本身的handleJobSubmitted,它首先會劃分Stage,提交Stage,提交Task。至此,Task就開始在運行在集羣上了。
一個Stage的開始就是從外部存儲或者shuffle結果中讀取數據;一個Stage的結束就是由於發生shuffle或者生成結果時。
創建finalStage
handleJobSubmitted 通過調用newStage來創建finalStage:
- finalStage = newStage(finalRDD, partitions.size, None, jobId, callSite)
創建一個result stage,或者說finalStage,是通過調用org.apache.spark.scheduler.DAGScheduler#newStage完成的;而創建一個shuffle stage,需要通過調用org.apache.spark.scheduler.DAGScheduler#newOrUsedStage。
- private def newStage(
- rdd: RDD[_],
- numTasks: Int,
- shuffleDep: Option[ShuffleDependency[_, _, _]],
- jobId: Int,
- callSite: CallSite)
- : Stage =
- {
- val id = nextStageId.getAndIncrement()
- val stage =
- new Stage(id, rdd, numTasks, shuffleDep, getParentStages(rdd, jobId), jobId, callSite)
- stageIdToStage(id) = stage
- updateJobIdStageIdMaps(jobId, stage)
- stage
- }
對於result 的final stage來說,傳入的shuffleDep是None。
我們知道,RDD通過org.apache.spark.rdd.RDD#getDependencies可以獲得它依賴的parent RDD。而Stage也可能會有parent Stage。看一個RDD論文的Stage劃分吧:

一個stage的邊界,輸入是外部的存儲或者一個stage shuffle的結果;輸入則是Job的結果(result task對應的stage)或者shuffle的結果。
上圖的話stage3的輸入則是RDD A和RDD F shuffle的結果。而A和F由於到B和G需要shuffle,因此需要劃分到不同的stage。
從源碼實現的角度來看,通過觸發action也就是最後一個RDD創建final stage(上圖的stage 3),我們注意到new Stage的第五個參數就是該Stage的parent Stage:通過rdd和job id獲取:
- // 生成rdd的parent Stage。沒遇到一個ShuffleDependency,就會生成一個Stage
- private def getParentStages(rdd: RDD[_], jobId: Int): List[Stage] = {
- val parents = new HashSet[Stage] //存儲parent stage
- val visited = new HashSet[RDD[_]] //存儲已經被訪問到得RDD
- // We are manually maintaining a stack here to prevent StackOverflowError
- // caused by recursively visiting // 存儲需要被處理的RDD。Stack中得RDD都需要被處理。
- val waitingForVisit = new Stack[RDD[_]]
- def visit(r: RDD[_]) {
- if (!visited(r)) {
- visited += r
- // Kind of ugly: need to register RDDs with the cache here since
- // we can't do it in its constructor because # of partitions is unknown
- for (dep <- r.dependencies) {
- dep match {
- case shufDep: ShuffleDependency[_, _, _] => // 在ShuffleDependency時需要生成新的stage
- parents += getShuffleMapStage(shufDep, jobId)
- case _ =>
- waitingForVisit.push(dep.rdd) //不是ShuffleDependency,那麼就屬於同一個Stage
- }
- }
- }
- }
- waitingForVisit.push(rdd) // 輸入的rdd作爲第一個需要處理的RDD。然後從該rdd開始,順序訪問其parent rdd
- while (!waitingForVisit.isEmpty) { //只要stack不爲空,則一直處理。
- visit(waitingForVisit.pop()) //每次visit如果遇到了ShuffleDependency,那麼就會形成一個Stage,否則這些RDD屬於同一個Stage
- }
- parents.toList
- }
生成了finalStage後,就需要提交Stage了。
- // 提交Stage,如果有parent Stage沒有提交,那麼遞歸提交它。
- private def submitStage(stage: Stage) {
- val jobId = activeJobForStage(stage)
- if (jobId.isDefined) {
- logDebug("submitStage(" + stage + ")")
- // 如果當前stage不在等待其parent stage的返回,並且 不在運行的狀態, 並且 沒有已經失敗(失敗會有重試機制,不會通過這裏再次提交)
- if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
- val missing = getMissingParentStages(stage).sortBy(_.id)
- logDebug("missing: " + missing)
- if (missing == Nil) { // 如果所有的parent stage都已經完成,那麼提交該stage所包含的task
- logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
- submitMissingTasks(stage, jobId.get)
- } else {
- for (parent <- missing) { // 有parent stage爲完成,則遞歸提交它
- submitStage(parent)
- }
- waitingStages += stage
- }
- }
- } else {
- abortStage(stage, "No active job for stage " + stage.id)
- }
- }
DAGScheduler將Stage劃分完成後,提交實際上是通過把Stage轉換爲TaskSet,然後通過TaskScheduler將計算任務最終提交到集羣。其所在的位置如下圖所示。
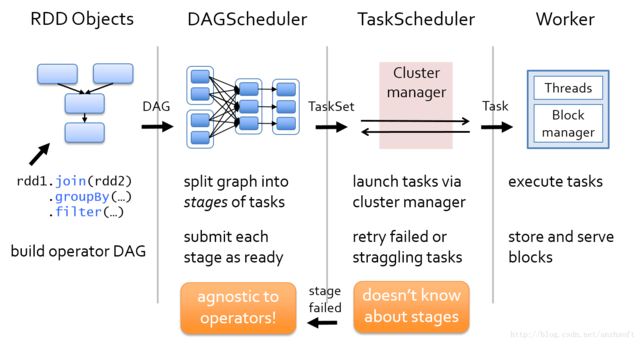
接下來,將分析Stage是如何轉換爲TaskSet,並最終提交到Executor去運行的。
BTW,最近工作太忙了,基本上到家洗漱完都要7點多。也再沒有精力去進行源碼解析了。