




論文:Spatial Transformer Networks,是Google旗下 DeepMind 公司的研究成果。
這篇論文的試驗做的特別好。
1 簡介
1.2 問題提出
CNN在圖像分類中取得了顯著的成效,主要是得益於 CNN 的深層結構具有 空間不變性(spatially invariance)(平移不變性,旋轉不變性),所以圖像上的目標物體就算是做了平移或者旋轉,CNN仍然能夠準確的識別出來,這對於CNN的泛化能力是有益的。
- 空間不變性主要是由於 Pooling 層 和 步長不爲1的卷積層 的存在帶來的。實際上主要是池化層的作用,因爲大部分的卷積層的步長都是大於1而又小於卷積核大小的,也就是滑動時是有重疊的,而池化層一般不是重疊的。也就是說這些層越多,越深,池化核或卷積核越大,空間不變性也越強;但是隨之而來的問題是局部信息丟失,所以這些層越多準確率肯定是下降的,所以主流的CNN分類網絡一般都很深,但是池化核都比較小,比如2×2。
- 比如ResNet,GoogLeNet,VGG,FCN,這些網絡的總降採樣比例一般是 16或32,基本沒有見過 64倍,128倍或者更高倍數的降採樣(會損失局部信息降低準確率),也很少見到 2倍或者4倍的降採樣比例(空間不變性太弱,泛化能力不好)。不過這個是跟數據集中的圖像大小有關的,上述主流圖像分類網絡基本都是針對於 ImageNet數據集做分類的,ImageNet中的圖片都比較大,一般在 256×256 左右。如果數據集中的圖像本來就很小,那麼降採樣比例就也會小,比如 MNIST數據集,圖像只有28×28,所以LeNet中的降採樣比例是4。總之,降採樣比例要根據數據集調整,找到合適的降採樣比例,才能保證準確率的情況下,有較強的空間不變性。
那麼如何在保證準確率的情況下,即不損失局部信息的前提下,增強網絡的空間不變性呢?這篇文章就是爲了解決這個問題。
1.2 解決方法
對於CNN 來說,即便通過選擇合適的降採樣比例來保證準確率和空間不變性,但是 池化層 帶來的空間不變性是不夠的,它受限於預先選定的固定尺寸的池化核(感受野是固定的,局部的)。因爲物體的變形包括旋轉,平移,扭曲,縮放,混淆噪聲等,所以後面feature map中像素點的感受野不一定剛好包含物體或者反映物體的形變。
文章提出了一種 Spatial Transformer Networks,簡稱 STN,引進了一種可學習的採樣模塊 Spatial Transformer ,姑且稱爲空間變換器,Spatial Transformer的學習不需要引入額外的數據標籤,它可以在網絡中對數據(feature map)進行空間變換操作。這個模塊是可微的(後向傳播必須),並且可以插入到現有的CNN模型中,使得 feature map具有空間變換能力,也就是說 感受野是動態變化的,feature map的空間變換方向 與 原圖片上的目標的空間變換方向(一般認爲是數據噪聲)是相反的,所以使得整個網絡的空間不變性增強。試驗結果展示這種方法確實增強了空間不變性,在一些標誌性的數據集(benchmark)上取得了先進的水平。
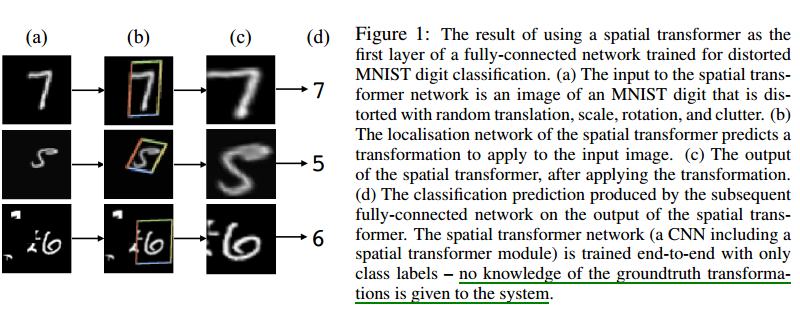
圖1 在輸入層使用 Spatial Transformer
空說無憑,先看一個簡單效果,如圖1:
- (a) :輸入圖片
- (b) :框起來的是用於後面網絡進行進一步識別分類的部分,這一部分是就是Spatial Transformer的結果
- (c) :輸出層的可視化
- (d) :預測結果
整體上來看是一種視覺 attention 機制,也更像一種弱的目標檢測機制,就是把圖片中物體所在區域送到網絡後面的層中,使得後面的分類任務更簡單。
CNN是盡力讓網絡適應物體的形變,而STN是直接通過 Spatial Transformer 將形變的物體給變回到正常的姿態(比如把字擺正),然後再給網絡識別。
文章給的 Spatial Transformer 的使用場景:
- image classification :如果數據集中的圖像上的目標形變很大,噪聲很大,位於圖片中心較遠,那麼 Spatial Transformer 可以將物體部分 “剪裁” 出來,並做一定的旋轉,縮放變換,使之成爲大小統一的圖片,便於後續網絡識別,並且獲得比CNN更好的結果。
- co-localisation :給定輸入圖片,不確定是否有物體,如果有,可以使用Spatial Transformer做出定位。
- spatial attention :對於使用attention機制的視覺任務,可以很輕鬆的使用 Spatial Transformer 完成。
看完這篇論文之後,個人覺得目標檢測(object detection)也是可以用的,果不其然,真有人將類似的方法用在了 目標檢測上,這篇論文就是 Deformable Convolutional Networks ,後面再講。
2 Spatial Transformer結構
文章最重要的一個結構就是 Spatial Transformers ,這個結構的示意圖如下:
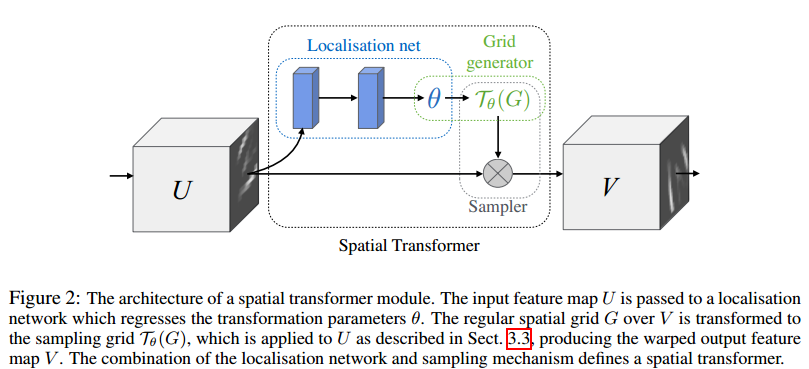
圖2 Spatial Transformers 結構圖
這樣一個結構相當於 CNN中的一個 卷積層或者池化層:
這個結構又被分爲三部分:localisation network ,grid generator和sampler
一些符號意義:
- U∈RH×W×CU∈RH×W×C 爲輸入 feature map
- V∈RH′×W′×C′V∈RH′×W′×C′ 爲輸出 feature map
- θ=floc(U)θ=floc(U) 是一個迴歸子網絡
- TθTθ 表示以參數 θθ 爲變換矩陣的某種變換,可以是2維仿射變換(2D affine transformation ),平面投影變換(plane projective transformation ),薄板樣條變換(thin plate spline )
- Gi=(xti,yti)Gi=(xit,yit) 代表V中的像素點 G={Gi}G={Gi} 是V中像素點的整體。
- Tθ(G)Tθ(G) 代表下面圖3中,輸入U上的綠色區域的座標。
這個圖與圖1做個對應,U 相當於 圖1 中的 (a) , V相當於 圖1 中的(c),中間那一部分相當於圖1 中的(b), 作用就是爲了找到那個物體所在的框,或者叫做弱目標檢測。
2.1 Localisation network
這一部分很簡單,可以使用全連接層或者全卷積層,只要保證最後一層是一個迴歸層即可,最後輸出的一個向量是 θθ 。 θθ 的維度下面再說。
2.2 Grid generator
前面提到中間那一部分是爲了找到那個物體所在的框,並把它給 變換回 “直立的狀態”。很自然就能想到使用仿射變換就可以完成,如下圖:

圖3 (a)恆等變換與採樣; (b)仿射變換與採樣
我們期望的是輸出 V 是 將U中某一部分(比如綠色點覆蓋的部分)做了旋轉,放縮,平移之後的feature map。
看一下Grid generator是如何進行仿射變換的。
先簡單的看一下仿射變換:
仿射變換用於表示旋轉,縮放和平移,表示的是兩副圖之間的關係,
以下 A 爲旋轉矩陣,B 爲平移矩陣,M稱爲仿射變換矩陣。
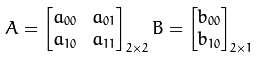
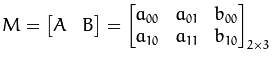
假設要對二維向量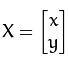
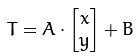
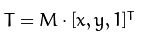
輸出的結果是:
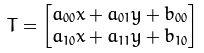
對於仿射變換來說,一般的用法有兩種:
- 已知 M 和 X,求T; 這個很簡單,直接矩陣相乘。
- 已知 X 和 T , 求M; 可以選取三對點,帶入上面的式子中,列方程,6個方程6個未知數;
這裏使用的是第一種用法。其中 圖3 (b) U 中的被綠點覆蓋的那一部分相當於這裏的 T,V相當於這裏的 X,那不是應該 M也是已知的嗎?M哪去了?還記得上面提到的 θθ ? θθ 就相當於這裏的M。因爲 M的大小是 2×3 ,所以 θθ 的維度爲6。如果使用了別的變換方法,那就根據變換矩陣的大小相應調整。也就是說這裏的變換矩陣是學習出來的。
對應於圖3的變換公式如下:
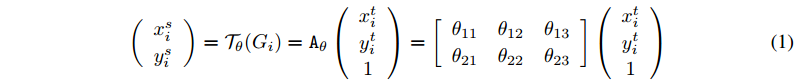
- (xti,yti)(xit,yit) are the target coordinates of the regular grid in the output feature map ,代表的是圖3輸出V中的像素點,即目標像素座標;
- (xsi,ysi)(xis,yis) are the source coordinates in the input feature map that define the sample points ,代表的是圖3輸入U中被綠色點覆蓋的像素點,即源像素座標;
- AθAθ is the affine transformation matrix ,代表的是仿射變換矩陣。其中的成員 θijθij 由 localisation network 迴歸生成。圖3或圖2中的 TθTθ 這時指的仿射變換 AθAθ。
注意他這個仿射變換是 從後向前變換的,就是說這個模塊的輸出是仿射變換的輸入,這個模塊的輸入的其中一部分(圖3(b) 綠點覆蓋部分)是仿射變換的輸出。
按照一般的做法,應該是從前往後變換,即從 source coordinates 得到 target coordinates 。但是這樣做的問題是,如何確定變換的輸入?如果是從前往後做變換,U 中綠色部分相當於 X,那怎麼確定這一部分是多大,什麼形狀,位置在哪?
實際上從後往前變換也就是爲了解決這個問題,就是要根據輸出V的座標得到輸入U中目標所在的區域的座標(綠色的區域)。
仿射變換變換的是座標,既是座標,那麼變換的輸入和輸出的座標的參考系應該是一樣的,就是說 V 中像素的座標 和 U 中像素的座標應該是同一個參考系。這裏使用的是針對 寬和高 進行的歸一化座標(height and width normalised coordinates),把在U和V中的像素座標歸一化到 [-1,1] 之間。U的 尺寸是上一層決定的,V的尺寸是人爲固定的,輸出 H′,W′H′,W′ 可以分別比 輸入H,WH,W 大或者小,或者相等。
可以給仿射變換的變換矩陣添加更多的約束:
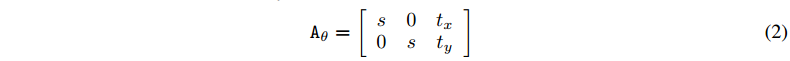
這時候,綠色區域已經確定了,相當於V中對應座標(xti,yti)(xit,yit) 的像素都將從U中這塊綠色區域中獲取。 H′,W′H′,W′ 與H,WH,W 不一定相等;即便是相等,由於變換後的源座標 (xsi,ysi)(xis,yis) 很有可能不是整數 ,對應U中不是整數像素點,所以沒有像素值,沒辦法直接拷貝。所以V中 (xti,yti)(xit,yit) 座標的像素值如何確定就成了問題。這時就涉及到採樣和插值。
2.3 Sampler
實際上 CNN中的卷積核 或者 池化核起到的就是採樣的作用。
(xsi,ysi)(xis,yis) 是U中綠色區域的座標,來看看更加具有一般性的採樣問題如何描述:
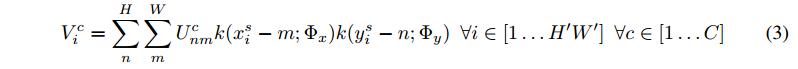
- UcnmUnmc 是輸入feature map上第 cc 個通道上座標爲 (n,m)(n,m) 的像素值;
- VciVic 是輸出 feature map上第 cc 個通道上座標爲 (xti,yti)(xit,yit) 的像素值;
- k()k() 表示插值核函數;
- Φx,ΦyΦx,Φy 代表 x 和 y 方向的插值核函數的參數;
- H,WH,W 輸入U的尺寸;
- H′,W′H′,W′ 輸出 V 的尺寸;
注意上式只是針對一個通道的像素進行採樣,實際上每個通道的採樣都是一樣的,這樣可以保留 空間一致性。
卷積的操作也是符合上式的,比如一維卷積:
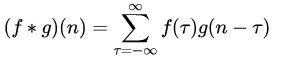
- f(τ)f(τ) 相當於 UcnmUnmc ;
- g(n−τ)g(n−τ) 相當於 k(xsi−m;Φx)k(xis−m;Φx) 或 (ysi−m;Φy)(yis−m;Φy) 因爲這裏的卷積是 一維的。
理論來說 任意 對 xsi,ysixis,yis 可導或局部可導的採樣核函數都是可以使用的.
比如最近鄰插值核函數:
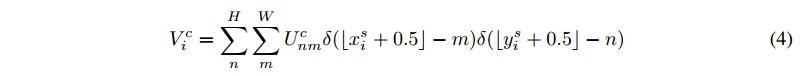
- 其中
- ⌊x+0.5⌋⌊x+0.5⌋ 向下取整
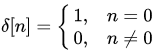
這個插值核函數做的就是把U中 離 當前源座標 (xsi,ysi)(xis,yis) (小數座標) 最近的 整數座標 (n,m)(n,m) 處的像素值拷貝到V中的 (xti,yti)(xit,yit) 座標處;
不過這篇文章使用的是雙線性插值,雙線性插值 參考 維基百科 和 圖像處理之插值運算,這裏放一張示意圖吧:

圖4 雙線性插值(來源於[參考資料 6])
這裏的公式如下:
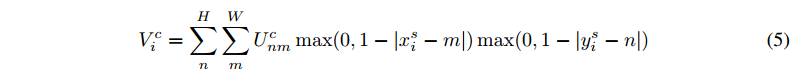
這個插值核函數做的是利用 U中 離 當前源座標 (xsi,ysi)(xis,yis) (小數座標) 最近的 4個整數座標 (n,m)(n,m) 處的像素值做雙線性插值然後拷貝到V中的 (xti,yti)(xit,yit)座標處;
我在想他那個通過仿射變換確定綠色區域之後,綠色區域相當於ROI,那採樣能不能使用ROI 池化的方式?
2.4 前向傳播
結合前面的分析,總結一下前向傳播的過程,如下圖:
- 實際上首先進行的是 localisation network 的迴歸,產生 變換矩陣的參數 θθ ,進而resize爲 變換矩陣 TθTθ ;
- 根據 V中的 目標座標 (xti,yti)(xit,yit) 做逆向仿射變換變換到源座標 (xsi,ysi)(xis,yis) : Source=Tθ⋅TargetSource=Tθ⋅Target , 源座標 (xsi,ysi)(xis,yis) 位於U上;對應圖中 1,2步;
- 在U中找到 源座標 (xsi,ysi)(xis,yis) (小數座標)附近的四個整數座標,做雙線性插值,插值後的值作爲 目標座標 (xti,yti)(xit,yit) 處的像素值;對應圖中 3,4步;
![]()

圖5 前向傳播流程(來源於[參考資料 6])
2.5 梯度流動與反向傳播
這個函數雖不是 完全可導 但也是局部可導的,求導如下,對 ysiyis 的導數也是類似的:
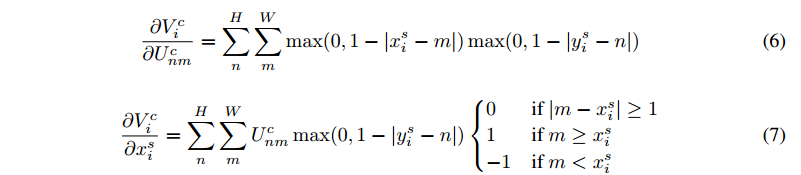
根據公式(1)很容易求得: ∂xsi∂θ∂xis∂θ 和 ∂ysi∂θ∂yis∂θ 。
所以反向傳播過程,誤差可以傳播到輸入 feature map(公式6),可以傳播到 採樣格點座標(sampling grid coordinates )(公式7),還可以傳播到變換參數 θθ .
下圖是梯度流動的示意圖:

圖6 反向傳播流程(來源於[參考資料 6])
其中localisation network中的 ∂xsi∂θ∂xis∂θ 和 ∂ysi∂θ∂yis∂θ 也就是這一股誤差流 {∂Vci∂xSi→∂xSi∂θ ∂Vci∂ySi→∂ySi∂θ{∂Vic∂xiS→∂xiS∂θ ∂Vic∂yiS→∂yiS∂θ ,在定位網絡處就斷了。
定位網絡是一個迴歸模型,相當於一個子網絡,一旦更新完參數,流就斷了,獨立於主網絡。
3 試驗
3.1 Distorted MNIST
這個試驗的數據集 是 MNIST,不過與原版的MNIST 不同,這個數據集對圖片上的數字做了各種形變操作,比如平移,扭曲,放縮,旋轉等。
如下,不同形變操作的簡寫表示:
- 旋轉:rotation (R),
- 旋轉+縮放+平移:rotation, scale and translation (RTS),
- 投影變換:projective transformation (P),
- 彈性變形:elastic warping (E) – note that elastic warping is destructive and can not be inverted in some cases.
文章將 Spatial Transformer 模塊嵌入到 兩種主流的分類網絡,FCN和CNN中(ST-FCN 和 ST-CNN )。Spatial Transformer 模塊嵌入位置在圖片輸入層與後續分類層之間。
試驗也測試了不同的變換函數對結果的影響:
- 仿射變換:affine transformation (Aff),
- 投影變換:projective transformation (Proj),
- 薄板樣條變換:16-point thin plate spline transformation (TPS)
其中CNN的模型與 LeNet是一樣的,包含兩個池化層。爲了公平,所有的網絡變種都只包含 3 個可學習參數的層,總體網絡參數基本一致,訓練策略也相同。
試驗結果

- 左側:不同的形變策略以及不同的 Spatial Transformer網絡變種與 baseline的對比;
- 右側:一些CNN分錯,但是ST-CNN分對的樣本
- (a):輸入
- (b):Spatial Transformer層 的 源座標(Tθ(G)Tθ(G) )可視化結果
- (c):Spatial Transformer層輸出
- 很明顯:ST-CNN優於CNN, ST-FCN優於FCN,說明Spatial Transformer確實增加了 空間不變性
- FCN中由於沒有 池化層,所以FCN的空間不變性不如CNN,所以FCN效果不如CNN
- ST-FCN效果可以達到CNN程度,說明Spatial Transformer確實增加了 空間不變性
- ST-CNN效果優於ST-FCN,說明 池化層 確實對 增加 空間不變性很重要
- 在 Spatial Transformer 中使用 plate spline transformation (TPS) 變換效果是最好的
- Spatial Transformer 可以將歪的數字扭正
- Spatial Transformer 在輸入圖片上確定的attention區域很明顯利於後續分類層分類,可以更加有效地減少分類損失
作者也做了噪聲環境下的試驗:將數字 放置在 60×60的圖片上,並添加斑點噪聲(圖1第三行)錯誤率分別爲:
FCN ,13.2% error; CNN , 3.5% error; ST-FCN ,2.0% error; ST-CNN ,1.7% error.
3.2 Street View House Numbers
Street View House Numbers是一個真實的 街景門牌號 數據集,共200k張圖片,每張圖片包含1-5個數字 ,數字都有形變。
- baseline character sequence CNN model :11層,5個softmax層輸出對應位置的預測序列
- STCNN Single :在輸入層添加一個Spatial Transformer
- ST-CNN Multi :前四層,每一層都添加一個Spatial Transformer 見下面 tabel 2 右側
- localisation networks 子網絡:兩層32維的全連接層
- 使用仿射變換和雙線性插值
結果:

3.3 Fine-Grained Classification
數據集:CUB-200-2011 birds dataset, 6k training images and 5.8k test images, covering 200 species of birds.
- baseline CNN model : an Inception architecture with batch normalisation pre-trained on ImageNet and fine-tuned on CUB – which by itself achieves the state-of-the-art accuracy of 82.3% (previous best result is 81.0% [30]).
- ST-CNN, which contains 2 or 4 parallel spatial transformers, parameterised for attention and acting on the input image.
這裏使用了並行的Spatial Transformer , 效果是可以將圖片的不同 部分(part)輸入到不同的 Spatial Transformer 層,會產生不同的 part representations 然後經過 inception ,最後再合併起來,經過一個單獨的softmax層做分類。
結果:

- ST-CNN效果最好
- 右側上邊使用了 2 路 Spatial Transformer並行,可以看到其中一個 spatial transformer(紅色) 檢測的是鳥的頭部, 而另外一個 (綠色) 檢測的鳥的身體.
- 右側下邊使用了 4 路 Spatial Transformer並行,有相似的效果.
- 此處的Spatial Transformer有點像目標檢測的味道
3.4 MNIST Addition
這個試驗是將任意兩張MNIST中的數字獨立的進行一系列變形,然後疊加到一塊,給網絡識別,標籤是二者之和。
同樣的測試 FCN, CNN, ST-CNN,2×ST-CNN。
2×ST-CNN在輸入層使用了兩個並行的Spatial Transformer,結構見下面table 4右側。

- 由於數據比較複雜,FCN的效果很差,添加了 Spatial Transformer之後,錯誤率顯著下降
- CNN有池化層存在所以效果比FCN好
- 2×ST-CNN效果最好
- 從右邊可視化的圖中可以看到雖然每個輸入channel都輸入到了兩個Spatial Transformer中,但是每個Spatial Transformer都是對其中一個channel作用強,而且這兩個Spatial Transformer是互補的,所以最後連接起來之後 4個通道的feature map中有兩個是完整的數字,所以識別較爲有效。
3.5 Co-localisation
這個試驗將 Spatial Transformer用在了半監督的任務Co-localisation 。
Co-localisation :給一些圖片,假設這些圖片包含一些目標(也可能不包含),在不使用目標類別標籤和目標位置標籤的情況下,定位出常見的目標。
數據集還是 MNIST ,將 28×28大小的 數字圖像 隨機的放在 84×84 大小的含有噪聲的背景上,對每個數字產生100個不同的變形。數據有定位標籤,但是在訓練時不用,測試時用。
模型還是使用 LeNet CNN模型,在輸入層嵌入Spatial Transformer。
文章使用了半監督的方式,監督的學習過程是這樣的:
對於一個 包含 N 張圖片的 數據集 I={In}I={In} ,比如table 5 右側的圖。
- 最下面一行代表在同類別的樣本中挑選一張 InIn 做一個隨機裁剪,裁剪出的這一塊 IrandnInrand ,認爲是目標位置
- 中間這一行代表將同樣的樣本 InIn輸入 Spatial Transformer,輸出 ITnInT
- 上面這行代表另選一個樣本 ImIm 輸入Spatial Transformer,輸出 ITmImT
- 以上三個輸出分別經過一個映射函數 e()e() ,這個函數由 LeNet CNN模型提供,以便於將上述三個feature map映射成向量,映射成向量後可以計算兩兩之間的距離
- 計算 L1=||e(ITm)−e(ITn)|2L1=||e(ImT)−e(InT)|2 , L2=||e(ITn)−e(Irandn)||2L2=||e(InT)−e(Inrand)||2 , 訓練過程中就是要保證 L1 < L2,L2是一個隨機裁剪與經過Spatial Transformer的輸出之間的距離,理應大於L1.

經過上面的分析,可以提出如下損失函數: hinge loss (triplet loss)
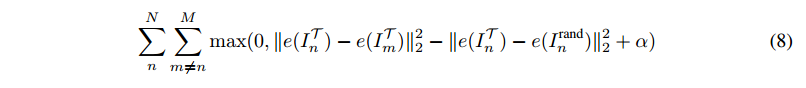
αα is a margin ,可以稱爲 裕度,相當於淨賺多少。
半監督是因爲這裏的標籤相當於 L2,而L2是人爲構造出來的距離指標。
測試時認爲檢測出的box與ground truth bounding box的IOU 大於0.5爲正確,table5 左側爲測試結果。
在沒有噪聲時,可以達到100%的準確率,有噪聲時在75-93%之間。
下圖是優化過程的動態可視化結果,可見隨着迭代次數越來越多,模型對目標的定位越來越準確

這個試驗使用了一種簡單的損失函數,在不使用數據定位標籤的情況下,構建了一種距離標籤,實現了對目標的檢測。這個可以推廣到目標檢測或追蹤問題中去。
作者把前面一些檢測的動態效果做成了視頻,看起來很清晰明瞭,看這裏:https://goo.gl/qdEhUu
4 總結
這篇文章提出的 Spatial Transformer 結構能夠很方便的嵌入到現有的CNN模型中去,並且實現端到端(end-to-end)的訓練,通過對數據進行反向空間變換來消除圖片上目標的變形,從而使得分類網絡的識別更加簡單高效。現在的CNN的已經非常強大了,但是 Spatial Transformer 仍然能過通過增強空間不變性來提高性能表現。Spatial Transformer實際上是一種attention機制,可以用於目標檢測,目標追蹤等問題,還可以構建半監督模。
下一篇介紹 Deformable Convolutional Networks ,跟本篇的TSN思路很像,但是又比這個模型簡單。