




一直找不到關於數據庫的介紹,要麼看上去很複雜,要麼就根本不是想要找的內容。今天運氣好居然在搜狗上搜出來一個,從博客園追到csdn,又追到英文原版,再追到原版論壇下邊一個比較好的中文翻譯。
這篇從比較容易理解的角度介紹數據庫的所有知識,都是經過作者的理解和總結並呈現出來。圖文並茂。
英文原版:http://coding-geek.com/how-databases-work/#Query_optimizer
中文翻譯:https://www.kancloud.cn/devbean/how-databases-work/145502
由於原文比較大,下邊複製的片段,用來討論。第一次從開頭看比較好,直接從討論區域開始有點不清晰。
表的三種連接:循環、hash、歸併

所有現代數據庫都使用**基於成本的優化(Cost Based Optimization,CBO)**來優化查詢。其思路是,爲每一個操作添加一個成本,通過使用成本最低的操作鏈降低查詢成,最終獲得結果。
爲了弄清楚成本優化器是如何工作的,我覺得最好的方法是“感受”這個任務背後的複雜性。在這部分,我將表述連接兩張表的三種通用方法,我們很快就會看到每一個簡單的連接查詢都是一個優化的噩夢。在此之後,我們將看到真正的優化器是如何進行這個工作的。
對於這些連接,我着眼於它們的時間複雜度,但是數據庫優化器會計算其 CPU 成本、磁盤 I/O 成本以及所需內存。時間複雜度和 CPU 成本的區別在於,前者是非常粗略的(對於那些像我一樣懶的人來說)。對於 CPU 成本,我需要計算每一個操作,比如一次加法,一條“if 語句”,一次乘法,一次便利等。另外:
- 每一條高級代碼操作都需要幾條低級 CPU 操作。
- 對於 Intel Core i7、Item Pentium 4 或者 AMD 的 CPU 而言,每一個 CPU 操作的成本都不相同(其術語是 CPU 週期)。換句話說,CPU 操作的成本取決於 CPU 架構。
使用時間複雜度更簡單(至少對於我來說是這樣),使用時間複雜度我們依然能夠獲得 CBO 的概念。有時我也會提到磁盤 I/O,因爲這也是一個重要概念。時刻記住,瓶頸在磁盤 I/O 所消耗的時間,而不是 CPU 消耗的。
索引
在我們介紹 B+ 樹的時候,我們討論過索引。記住,索引已經排好序了。
僅供參考:數據庫還有其它類型的索引,比如位圖索引(bitmap indexes)。它們與 B+ 樹索引消耗的 CPU 週期、磁盤 I/O 和內容都不相同。
另外,如果可以改善執行計劃的成本,很多現代數據庫可以爲當前插件動態創建臨時索引。
訪問路徑
在應用連接運算符之前,首先你需要獲得數據。下面是你能夠如何獲得數據。
注意:由於訪問路徑真正的問題在於磁盤 I/O,因此我不會過多討論時間複雜度。
完整掃描
如果你閱讀過執行計劃,你一定見過完整掃描(full scan,或者就叫 scan)這個詞。完整掃描就是數據庫讀取整張表或索引。考慮到磁盤 I/O,很明顯,對於整張表的完整掃描的成本要遠遠高於對於索引的完整掃描。
範圍掃描
其它類型的掃描有索引範圍掃描(index range scan)。當你使用謂詞,比如“WHERE AGE > 20 AND AGE <40”時,就會使用索引範圍掃描。
當然,爲了使用索引範圍掃描,你需要在 AGE 字段添加索引。
在前面部分,我們已經瞭解到,範圍查詢的時間成本可能會有 log(N) +M,其中,N 是索引數據量,M 是落在這個範圍的行數的估計值。多虧了統計數據,N 和 M 都是已知的(注意,M 就是謂詞 AGE >20 AND AGE<40 的選擇率)。另外,對於範圍掃描,你不需要只讀完整的索引,因此要比完整掃描的磁盤 I/O 成本小得多。
唯一掃描
如果你只需要從索引獲取一個值,可以使用唯一掃描(unique scan)。
通過 row id 訪問
大多數時間,如果數據庫使用索引,它就得找到關聯到索引的那些行。爲了達到這一目的,數據庫會使用 row id 訪問。
例如,如果你的語句如下:
SELECT LASTNAME, FIRSTNAME from PERSON WHERE AGE = 28
如果 age 列有索引,優化器會使用索引找到所有 28 歲的人,然後會請求表中關聯的那些行。這是因爲索引只包含了年齡的信息,但是你卻想要獲取 lastname 和 firstname。
但是,如果你的語句如下:
SELECT TYPE_PERSON.CATEGORY from PERSON, TYPE_PERSON
WHERE PERSON.AGE = TYPE_PERSON.AGE
PERSON 的索引用於連接 TYPE_PERSON,但是 PERSON 表卻不會使用 row id 訪問,因爲你並沒有請求這個表的數據。
對於少量訪問,這是可行的,但這個操作的真正問題在於磁盤 I/O。如果你需要通過 row id 訪問很多數據,數據庫可能會選擇使用完整掃描。
其它路徑
我並沒有闡述所有訪問路徑。如果你想了解更多,可以閱讀 Oracle 文檔。對於其它數據庫,文檔的名字可能會有歧義,但是其背後的原理是相通的。
連接運算符(join)
現在我們知道了如何獲得數據,然後,讓我們將數據連接起來!
我會介紹三種通用連接運算符:歸併連接、哈希連接和嵌套循環連接。但在此之前,我需要介紹一個新的術語:內關係(inner relation)和外關係(outer relation)。一個關係可以是
- 一個表
- 一個索引
- 來自上一步操作的中間結果(例如上一個連接的結果)
當你連接兩個關係時,連接算法會分別管理兩個關係。在本文剩下的部分,我會假設:
- 外關係是左數據集
- 內連接是右數據集
例如,A JOIN B 是 A 和 B 的連接,其中,A 是外連接,B 是內連接。
大多數情況下,A JOIN B 的成本與 B JOIN A 並不相同。
在這一部分,我同樣假設外連接有 N 個元素,內連接有 M 個元素。時刻記住,真正的優化器可以通過統計知道 N 和 M 的值。
注意,N 和 M 是聯繫的基數。
嵌套循環連接(nested loop join)
嵌套循環連接是最簡單的一個。
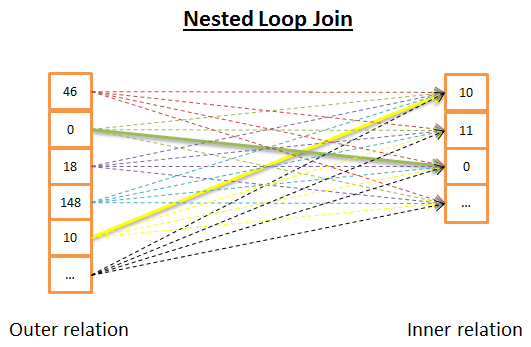
其思路是:
- 對於外關係的每一行
- 檢查內關係中的所有行,看是不是有行能夠匹配
僞代碼如下:
nested_loop_join(array outer, array inner)
for each row a in outer
for each row b in inner
if (match_join_condition(a, b))
write_result_in_output(a, b)
end if
end for
end for
因爲這裏有兩層循環,所以時間複雜度是 O(N*M)。
從磁盤 I/O 方面,對於外關係 N 行的每一行,內層循環都需要從內關係讀取 M 行。這個算法需要從磁盤讀取 N + N * M 行。但是,如果內關係足夠小,那麼就可以把所有關係放在內存,這樣就只需要 M +N 次讀取。根據這樣的修改,內關係必須是最小的一個,因爲只有這樣纔有更多機會放入內存。
從時間複雜度方面,這樣並沒有什麼不同,但是從磁盤 I/O 方面,這種方式只需要讀取兩種關係一次。
當然,內關係可以替換爲索引,這樣對磁盤 I/O 更有利。
由於這個算法非常簡單,對於那些不能完全讀入內存的內關係而言,還有一個對磁盤 I/O 更友好的版本。其思路是這樣的:
- 不是一行一行讀取關係
- 按照批次讀取關係,在內存中始終保存兩個批次的行(每個關係都保留 2 個批次)
- 在兩個批次內部比較行,保留匹配的行
- 然後,從磁盤加載新的批次,再進行比較
- 如此進行下去,知道沒有批次可供加載
下面是算法僞代碼:
// 改進版本,減少磁盤 I/O。
nested_loop_join_v2(file outer, file inner)
for each bunch ba in outer
// 現在 ba 在內存中
for each bunch bb in inner
// 現在 bb 在內存中
for each row a in ba
for each row b in bb
if (match_join_condition(a,b))
write_result_in_output(a,b)
end if
end for
end for
end for
end for
使用這個版本,時間複雜度相同,但是磁盤訪問次數有所減少:
- 之前的版本,算法需要 N + N * M 次磁盤訪問(每次訪問讀取一行)
- 新的版本,磁盤訪問數變爲 number_of_bunches_for(outer) + number_of_ bunches_for(outer) * number_of_ bunches_for(inner)
- 增加每一批次的大小,就能降低磁盤訪問次數
注意:雖然每一次磁盤訪問都可以加載比上述算法更多的數據,但是由於數據是順序訪問的(機械硬盤真正的問題是獲得第一組數據所需時間),因此影響並不會很大。
哈希連接
哈希連接要比嵌套循環連接複雜得多,但是在很多情形下,它的性能要比後者好得多。
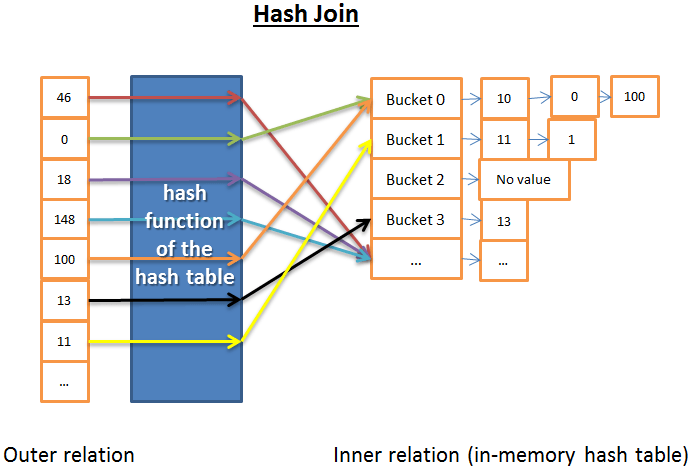
哈希連接的思路是:
- 從內關係獲取所有元素
- 構建內存中的哈希表
- 依次獲取外關係中的所有元素
- 計算每一個元素的哈希值(使用哈希表的哈希函數),找到與內關係關聯的桶
- 檢查桶中元素和外表中的元素是不是匹配
關於時間複雜度,我需要作一些假定以簡化問題:
- 內關係分爲 X 個桶
- 對於兩個關係,哈希函數都可以均勻地散列哈希值。換句話說,這些桶的大小相同
- 外關係中的一個元素與桶中所有元素的匹配過程消耗只與桶中的元素數目有關
其時間複雜度是 (M/X) * N + cost_to_create_hash_table(M) + cost_of_hash_function*N
如果哈希函數創建足夠小的桶,那麼,時間複雜度就是 O(M+N)。
下面的哈希連接的版本對內存更友好,但是不利於磁盤 I/O。這一次:
- 同時計算內關係和外關係的哈希表
- 將計算出的哈希值存入磁盤
- 然後按照桶依次比較兩個關係(現將一個加載到內存,然後依次讀取另外一個)
歸併連接
歸併連接是唯一獲得排序結果的連接。
注意:在這個簡化的歸併連接中,不存在內表或外表;它們的角色是一致的。但是,實際實現是有區別的,例如,當處理複製時。
歸併連接可以分爲兩步:
- (可選的)排序連接操作:兩個輸入都按照連接鍵進行排序
- 歸併連接操作:將排好序的輸入合併在一起
排序
我們已經討論了歸併排序,在這個情形下,歸併排序是一個不錯的算法(但是如果內存不是問題的話,這並不是最好的算法)。
但是,有時數據集已經排好序了,例如:
- 表自然地排序了,例如在連接條件上使用索引組織的表
- 如果在連接條件上,這個關係是一個索引
- 如果這個連接應用在一箇中間結果上,而這個中間結果已經在查詢處理階段排好序了
歸併連接
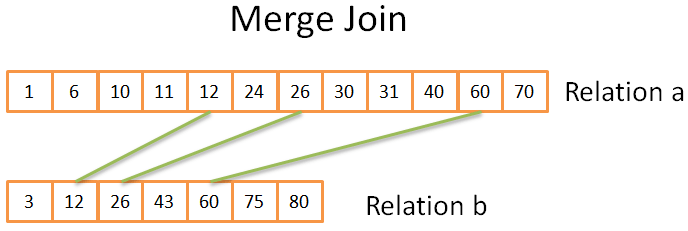
這一步非常像我們之前見過的歸併排序的歸併操作。但是這一次我們並不是從每個關係中取出每一個元素,而是從每個關係中取出相同元素。其思想是:
- 比較兩個關係中的當前元素(第一次時,當前元素就是第一個元素)
- 如果相同,將兩個元素放進結果集,然後獲取兩個關係中的下一個元素
- 如果不相同,從較小元素所在關係中取出下一個元素(因爲下一個元素可能會相同)
- 重複以上 3 步,直到其中一個關係到達最後一個元素
因爲兩個關係都是排好序的,因此這種操作是可行的。你不需要在這些關係中“後退”。
這個算法是一個簡化版本,因爲它沒有處理兩個數組中相同數據出現多次的情況(也就是多次匹配)。真實的版本會更復雜一些,但也不會複雜太多,因此我選擇了一個相對簡單的版本。
如果兩個關係都已經排好序,那麼時間複雜度就是 O(N+M)。
如果兩個關係都需要排序,那麼時間複雜度就是兩個關係排序的消耗:O(N * Log(N) + M * Log(M))。
對於計算機專業技術人員,下面是一個能夠處理多次匹配的可行算法(雖然我也不是 100% 確保算法正確性):
mergeJoin(relation a, relation b)
relation output
integer a_key:=0;
integer b_key:=0;
while (a[a_key]!=null or b[b_key]!=null)
if (a[a_key] < b[b_key])
a_key++;
else if (a[a_key] > b[b_key])
b_key++;
else //Join predicate satisfied
//i.e. a[a_key] == b[b_key]
//count the number of duplicates in relation a
integer nb_dup_in_a = 1:
while (a[a_key]==a[a_key+nb_dup_in_a])
nb_dup_in_a++;
//count the number of duplicates in relation b
integer dup_in_b = 1:
while (b[b_key]==b[b_key+nb_dup_in_b])
nb_dup_in_b++;
//write the duplicates in output
for (int i = 0 ; i< nb_dup_in_a ; i++)
for (int j = 0 ; i< nb_dup_in_b ; i++)
write_result_in_output(a[a_key+i],b[b_key+j])
a_key=a_key + nb_dup_in_a-1;
b_key=b_key + nb_dup_in_b-1;
end if
end while
哪個最好?
如果有最好的連接方式,就不會有這麼多種了。這個問題很難回答,因爲有很多因素在裏面:
- 可用內存總數:沒有足夠了內存,就基本可以跟強大的哈希連接說拜拜了(至少對完全內存中的哈希連接)
- 兩個數據集的大小:例如,如果你有一張大表和一個很小的表,那麼,嵌套循環連接要比哈希連接快一些,因爲哈希連接需要計算哈希值。如果你的兩張表都很大,那麼,嵌套循環連接會消耗非常多的 CPU。
- 是不是有索引:對於歸併連接,兩個 B+ 樹索引絕對是一個好主意。
- 如果結果需要排序:即使你的數據集沒有排序,你還是可能想使用代價昂貴的歸併連接(使用排序),因爲最終結果是排好序的,你可以將這個結果交給另外的歸併連接(或者是由於查詢語句使用 ORDER BY/GROUP BY/DISTINCT 等隱式或顯式要求了結果排序)。
- 如果關係已經排好序:這種情況下,歸併連接是最好的選擇。
- 你正在使用的連接類型:是不是** equijoin** (例如 tableA.col1 = tableB.col2)?是不是 inner join、outer join、cartesian product 或者 self-join?某些連接不適用與特定情形。
- 數據的分佈:如果連接條件中的數據是不均衡的(skewed),例如,你需要使用人名中的姓氏連接,但是很多人都有相同的姓,使用哈希連接就是一場災難,因爲哈希函數計算出來的桶是非常不均衡的。
- 如果你需要在多線程或多進程情形下進行連接。
更多信息,可以閱讀 DB2、ORACLE 或 [SQL Server](https://technet.microsoft.com/en-us/library/ms191426(v=sql.105).aspx) 的文檔。