




MTCNN模型概述
多任務卷積神經網絡(MTCNN)實現人臉檢測與對齊是在一個網絡裏實現了人臉檢測與五點標定的模型,主要是通過CNN模型級聯實現了多任務學習網絡。整個模型分爲三個階段,第一階段通過一個淺層的CNN網絡快速產生一系列的候選窗口;第二階段通過一個能力更強的CNN網絡過濾掉絕大部分非人臉候選窗口;第三階段通過一個能力更加強的網絡找到人臉上面的五個標記點;完整的MTCNN模型級聯如下: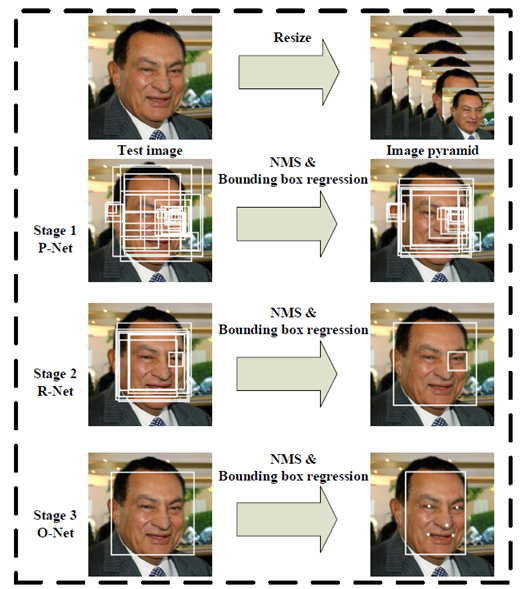
該模型的特徵跟HAAR級聯檢測在某些程度上有一定的相通之處,都是採用了級聯方式,都是在初期就拒絕了絕大多數的圖像區域,有效的降低了後期CNN網絡的計算量與計算時間。MTCNN模型主要貢獻在於:
1.提供一種基於CNN方式的級聯檢測方法,基於輕量級的CNN模型就實現了人 臉檢測與點位標定,而且性能實時。
2.實現了對難樣本挖掘在線訓練提升性能
3.一次可以完成多個任務。階段方法詳解
第一階段
網絡是全卷積神經網絡是一個推薦網絡簡稱 P-Net, 主要功能是獲得臉部區域的窗口與邊界Box迴歸,獲得的臉部區域窗口會通過BB迴歸的結果進行校正,然後使用非最大壓制(NMS)合併重疊窗口。
第二階段
網絡模型稱爲優化網絡R-Net,大量過濾非人臉區域候選窗口,然後繼續校正BB迴歸的結果,使用NMS進行合併。
第三階段
網絡模型稱爲O-Net,輸入第二階段數據進行更進一步的提取,最終輸出人臉標定的5個點位置。
網絡架構與訓練
對CNN網絡架構,論文作者發現影響網絡性能的因素主要原因有兩個:
1.樣本的多樣性缺乏會影響網絡的鑑別能力
2.相比其它的多類別的分類與檢測任務來說,
人臉檢測是一個二分類,每一層不需要太多filters,
也就是說每層網絡的feature maps個數不需要太多根據上述兩個因素,作者設計網絡每層的filter個數有限,但是它增加了整個網絡的深度,這樣做的好處是可以顯著減少計算量,提升整個網絡性能,同時全部改用3x3的filter更進一步降低計算量,在卷積層與全連接層使用PReLU作爲非線性激活函數(輸出層除外)整個網絡架構如下: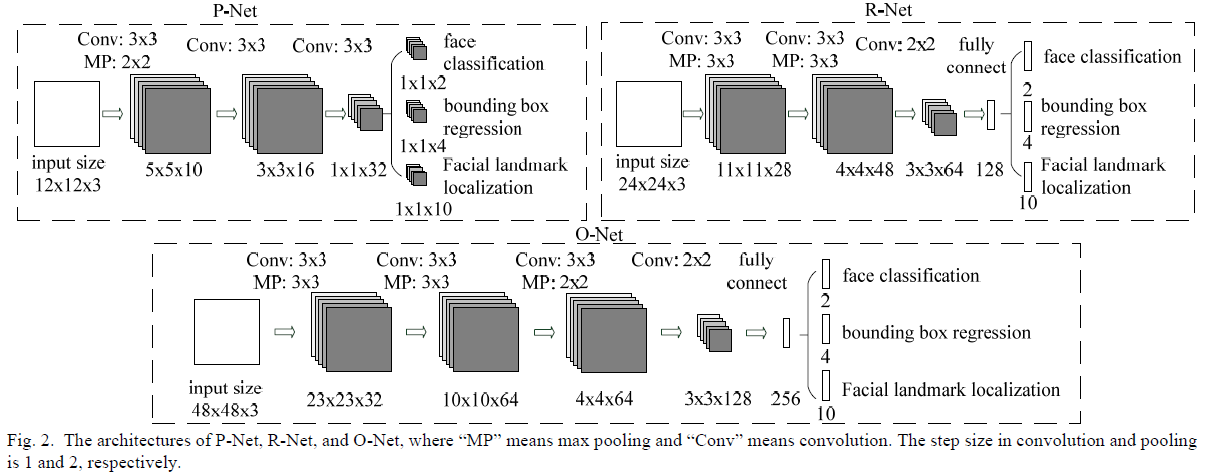
訓練這個網絡需要如下三任務得到收斂
1.人臉二元分類
2.BB迴歸(bounding box regression)
3.標記定位(Landmark localization)訓練時候對於人臉採用交叉熵損失: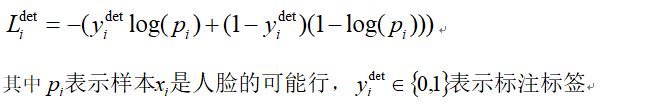
BB迴歸損失:
對每個候選窗口,計算它與標註框之間的offset,目標是進行位置迴歸,計算其平方差損失如下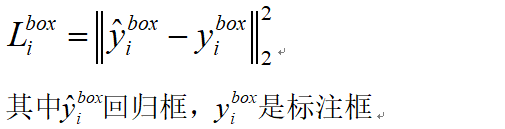
臉部landmark位置損失:
總計有五個點位座標分別爲左眼、右眼、鼻子、左嘴角、右嘴角
因爲每個CNN網絡完成不同的訓練任務,所以在網絡學習/訓練階段需要不同類型的訓練數據。所以在計算損失的時候需要區別對待,對待背景區域,在R-Net與O-Net中的訓練損失爲0,因爲它沒有包含人臉區域,通過參數beta=0來表示這種類型。總的訓練損失可以表示如下: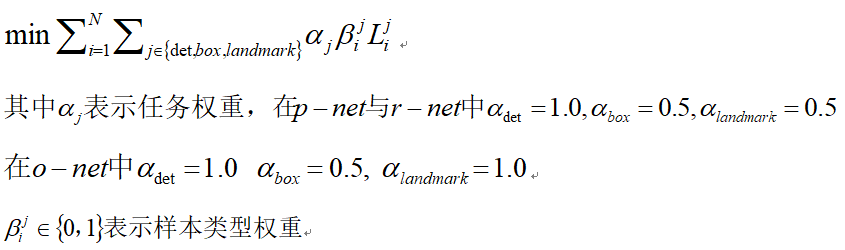
在P-Net中對人臉進行二元分類時候就可以在線進行難樣本挖掘,在網絡前向傳播時候對每個樣本計算得到的損失進行排序(從高到低)然後選擇70%進行反向傳播,原因在於好的樣本對網絡的性能提升有限,只有那些難樣本才能更加有效訓練,進行反向傳播之後纔會更好的提升整個網絡的人臉檢測準確率。作者的對比實驗數據表明這樣做可以有效提升準確率。在訓練階段數據被分爲四種類型:
負樣本:並交比小於0.3
正樣本:並交比大於0.65
部分臉:並交比在0.4~0.65之間
Landmark臉:能夠找到五個landmark位置的其中在負樣本與部分臉之間並沒有明顯的差異鴻溝,作者選擇0.3與0.4作爲區間。
正負樣本被用來實現人臉分類任務訓練
正樣本與部分臉樣本訓練BB迴歸
Landmark臉用來訓練人臉五個點位置定位
整個訓練數的比例如下:
負樣本:正樣本:部分臉:landmark臉=3:1:1:2
測試代碼
加載網絡
print('Creating networks and loading parameters')
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_memory_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
pnet, rnet, onet = align.detect_face.create_mtcnn(sess, None)人臉檢測
def detection(image):
minsize = 20 # minimum size of face
threshold = [0.6, 0.7, 0.7] # three steps's threshold
factor = 0.709 # scale factor
# detect with RGB image
h, w = image.shape[:2]
bounding_boxes, _ = align.detect_face.detect_face(image, minsize, pnet, rnet, onet, threshold, factor)
if len(bounding_boxes) < 1:
print("can't detect face in the frame")
return None
print("num %d faces detected"% len(bounding_boxes))
bgr = cv.cvtColor(image, cv.COLOR_RGB2BGR)
for i in range(len(bounding_boxes)):
det = np.squeeze(bounding_boxes[i, 0:4])
bb = np.zeros(4, dtype=np.int32)
# x1, y1, x2, y2
bb[0] = np.maximum(det[0] - margin / 2, 0)
bb[1] = np.maximum(det[1] - margin / 2, 0)
bb[2] = np.minimum(det[2] + margin / 2, w)
bb[3] = np.minimum(det[3] + margin / 2, h)
cv.rectangle(bgr, (bb[0], bb[1]), (bb[2], bb[3]), (0, 0, 255), 2, 8, 0)
cv.imshow("detected faces", bgr)
return bgr實時攝像頭檢測
capture = cv.VideoCapture(0)
height = capture.get(cv.CAP_PROP_FRAME_HEIGHT)
width = capture.get(cv.CAP_PROP_FRAME_WIDTH)
out = cv.VideoWriter("D:/mtcnn_demo.mp4", cv.VideoWriter_fourcc('D', 'I', 'V', 'X'), 15,
(np.int(width), np.int(height)), True)
while True:
ret, frame = capture.read()
if ret is True:
frame = cv.flip(frame, 1)
cv.imshow("frame", frame)
rgb = cv.cvtColor(frame, cv.COLOR_BGR2RGB)
result = detection(rgb)
out.write(result)
c = cv.waitKey(10)
if c == 27:
break
else:
break
cv.destroyAllWindows()運行演示:
本來想上傳視頻的發現上傳不了了,所以就把視頻寫成多張連續的圖像,截屏顯示各種效果,其實視頻十分流暢,效果也非常的好。
有遮擋、部分臉檢測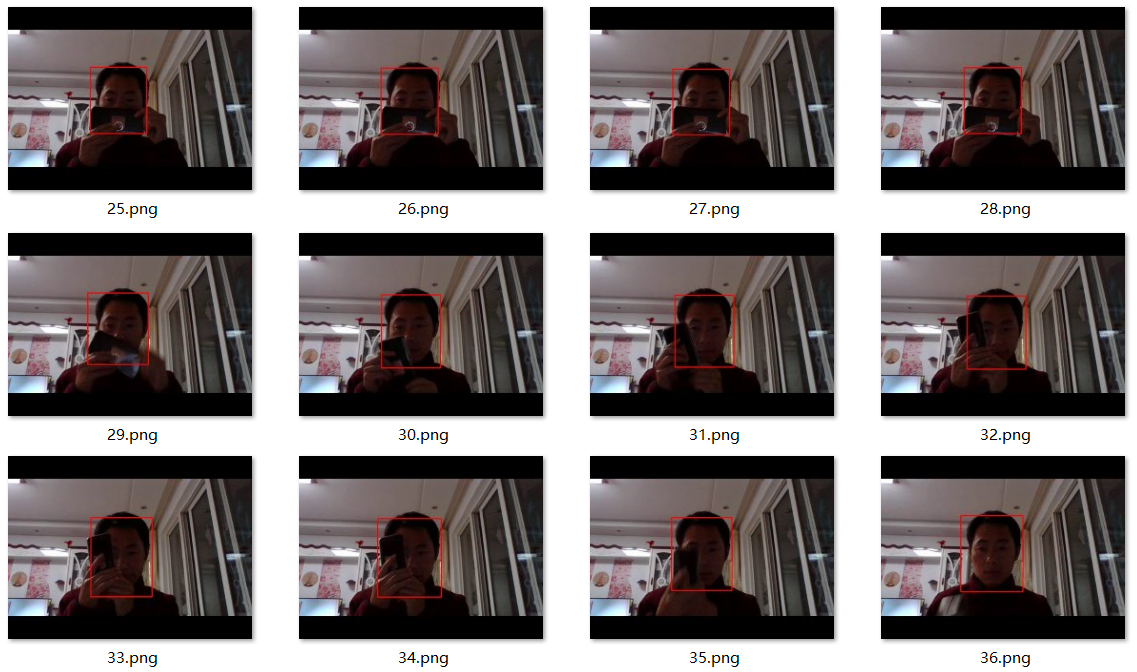
側臉檢測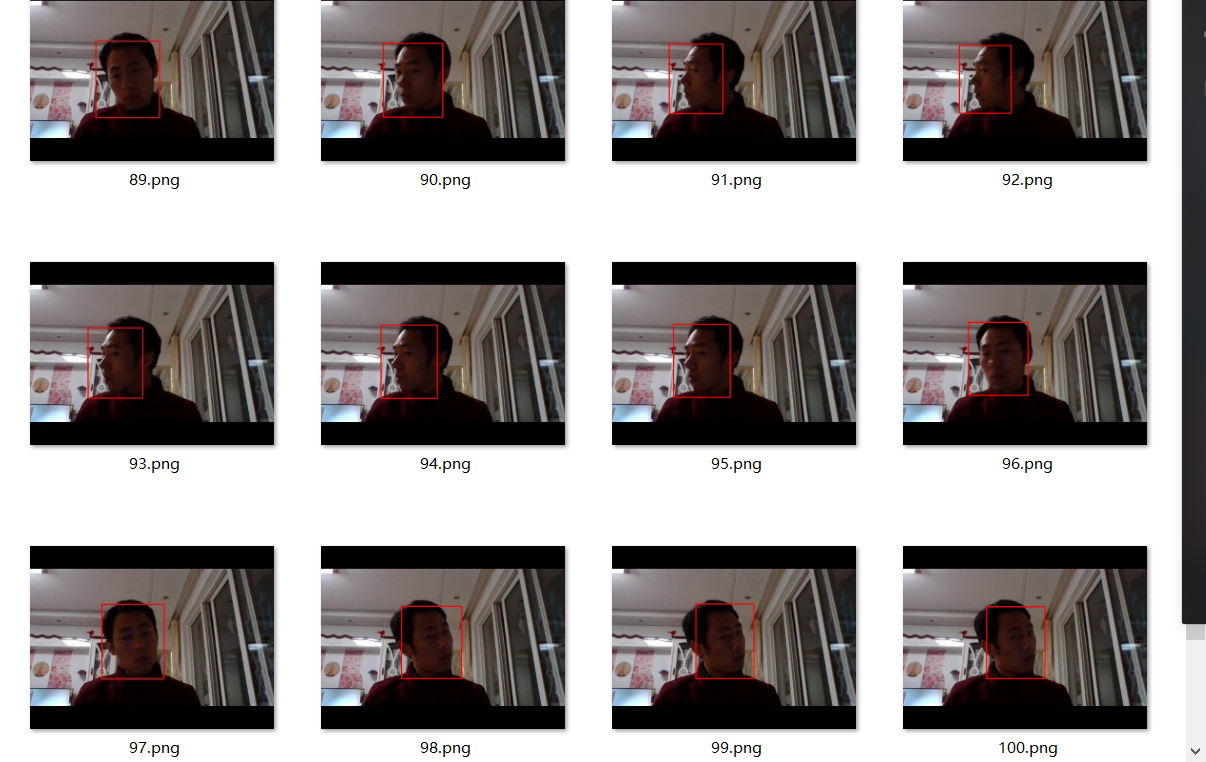
角度俯仰臉檢測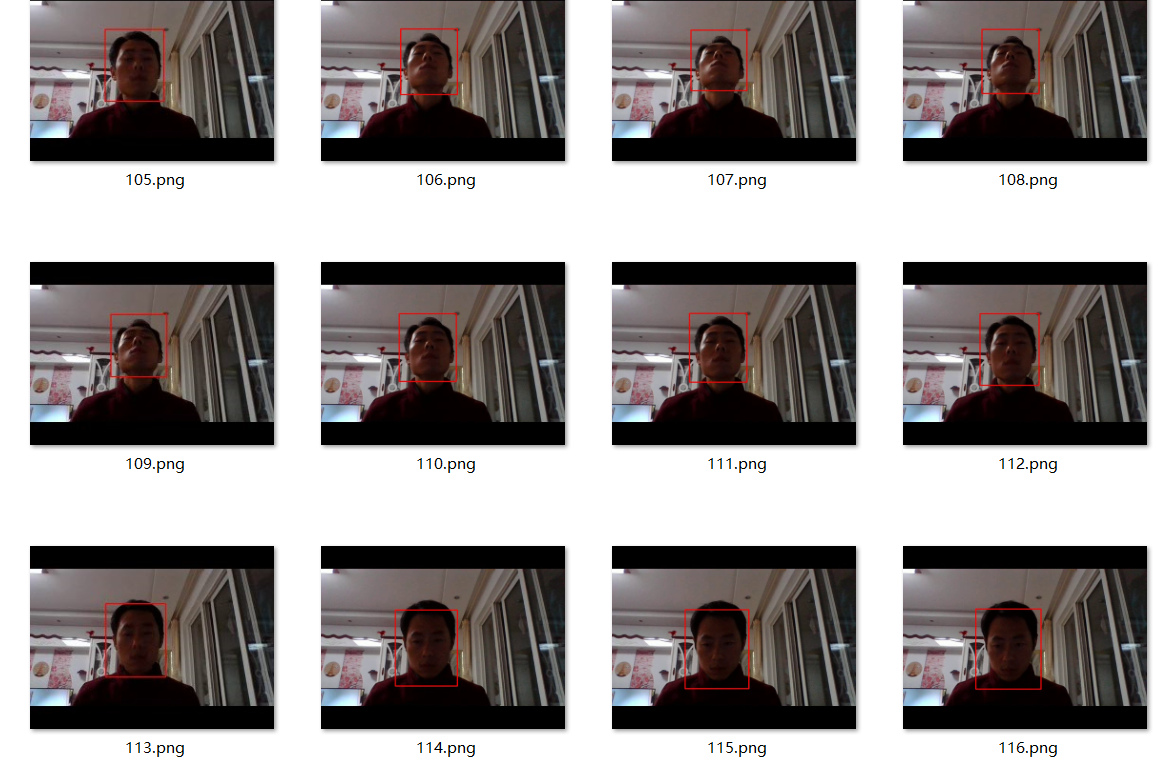
總結一下
整個模型的運行速度極快,即使在CPU上也可以完全達到實時性能,關鍵是其檢測準確率與穩定性跟HAAR/LBP的方式相比,你就會感覺HAAR/LBP的方式就是渣,完全涼啦!