




ZooKeeper 是什麼?
ZooKeeper 顧名思義 動物園管理員,他是拿來管大象(Hadoop) 、 蜜蜂(Hive) 、 小豬(Pig) 的管理員, Apache Hbase和 Apache Solr 以及LinkedIn sensei 等項目中都採用到了 Zookeeper。ZooKeeper是一個分佈式的,開放源碼的分佈式應用程序協調服務,ZooKeeper是以Fast Paxos算法爲基礎,實現同步服務,配置維護和命名服務等分佈式應用。
ZooKeeper 如何工作?
ZooKeeper是作爲分佈式應用建立更高層次的同步(synchronization)、配置管理 (configuration maintenance)、羣組(groups)以及名稱服務(naming)。在編程上,ZooKeeper設計很簡單,所使用的數據模型風格很像文件系統的目錄樹結構,簡單來說,有點類似windows中註冊表的結構,有名稱,有樹節點,有Key(鍵)/Value(值)對的關係,可以看做一個樹形結構的數據庫,分佈在不同的機器上做名稱管理。
Zookeeper分爲2個部分:服務器端和客戶端,客戶端只連接到整個ZooKeeper服務的某個服務器上。客戶端使用並維護一個TCP連接,通過這個連接發送請求、接受響應、獲取觀察的事件以及發送心跳。如果這個TCP連接中斷,客戶端將嘗試連接到另外的ZooKeeper服務器。客戶端第一次連接到ZooKeeper服務時,接受這個連接的 ZooKeeper服務器會爲這個客戶端建立一個會話。當這個客戶端連接到另外的服務器時,這個會話會被新的服務器重新建立。
啓動Zookeeper服務器集羣環境後,多個Zookeeper服務器在工作前會選舉出一個Leader,在接下來的工作中這個被選舉出來的Leader死了,而剩下的Zookeeper服務器會知道這個Leader死掉了,在活着的Zookeeper集羣中會繼續選出一個Leader,選舉出leader的目的是爲了可以在分佈式的環境中保證數據的一致性。如圖所示:
另外,ZooKeeper 支持watch(觀察)的概念。客戶端可以在每個znode結點上設置一個觀察。如果被觀察服務端的znode結點有變更,那麼watch就會被觸發,這個watch所屬的客戶端將接收到一個通知包被告知結點已經發生變化。若客戶端和所連接的ZooKeeper服務器斷開連接時,其他客戶端也會收到一個通知,也就說一個Zookeeper服務器端可以對於多個客戶端,當然也可以多個Zookeeper服務器端可以對於多個客戶端,如圖所示:
你還可以通過命令查看出,當前那個Zookeeper服務端的節點是Leader,哪個是Follower,如圖所示:

記得大約在2006年的時候Google出了Chubby來解決分佈一致性的問題(distributed consensus problem),所有集羣中的服務器通過Chubby最終選出一個Master Server ,最後這個Master Server來協調工作。簡單來說其原理就是:在一個分佈式系統中,有一組服務器在運行同樣的程序,它們需要確定一個Value,以那個服務器提供的信息爲主/爲準,當這個服務器經過n/2+1的方式被選出來後,所有的機器上的Process都會被通知到這個服務器就是主服務器 Master服務器,大家以他提供的信息爲準。很想知道Google Chubby中的奧妙,可惜人家Google不開源,自家用。
但是在2009年3年以後沉默已久的Yahoo在Apache上推出了類似的產品ZooKeeper,並且在Google原有Chubby的設計思想上做了一些改進,因爲ZooKeeper並不是完全遵循Paxos協議,而是基於自身設計並優化的一個2 phase commit的協議,如圖所示:
ZooKeeper跟Chubby一樣用來存放一些相互協作的信息(Coordination),這些信息比較小一般不會超過1M,在zookeeper中是以一種hierarchical tree的形式來存放,這些具體的Key/Value信息就store在tree node中,如圖所示:
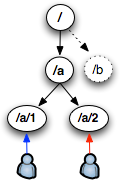
當有事件導致node數據,例如:變更,增加,刪除時,Zookeeper就會調用 triggerWatch方法,判斷當前的path來是否有對應的監聽者(watcher),如果有watcher,會觸發其process方法,執行process方法中的業務邏輯,如圖所示:

應用實例
ZooKeeper有了上述的這些用途,讓我們設想一下,在一個分佈式系統中有這這樣的一個應用:
2個任務工廠(Task Factory)一主一從,如果從的發現主的死了以後,從的就開始工作,他的工作就是向下面很多臺代理(Agent)發送指令,讓每臺代理(Agent)獲得不同的賬戶進行分佈式並行計算,而每臺代理(Agent)中將分配很多帳號,如果其中一臺代理(Agent)死掉了,那麼這臺死掉的代理上的賬戶就不會繼續工作了。
上述,出現了3個最主要的問題:
1.Task Factory 主/從一致性的問題
2.Task Factory 主/從心跳如何用簡單+穩定 或者2者折中的方式實現。
3.一臺代理(Agent)死掉了以後,一部分的賬戶就無法繼續工作,需要通知所有在線的代理(Agent)重新分配一次帳號。
怕文字闡述的不夠清楚,畫了系統中的Task Factory和Agent的大概系統關係,如圖所示:
OK,讓我們想想ZooKeeper是不是能幫助我們去解決目前遇到的這3個最主要的問題呢?
解決思路
1. 任務工廠Task Factory都連接到ZooKeeper上,創建節點,設置對這個節點進行監控,監控方法例如:
event= new WatchedEvent(EventType.NodeDeleted, KeeperState.SyncConnected, "/TaskFactory");
這個方法的意思就是隻要Task Factory與zookeeper斷開連接後,這個節點就會被自動刪除。
2.原來主的任務工廠斷開了TCP連接,這個被創建的/TaskFactory節點就不存在了,而且另外一個連接在上面的Task Factory可以立刻收到這個事件(Event),知道這個節點不存在了,也就是說主TaskFactory死了。
3.接下來另外一個活着的TaskFactory會再次創建/TaskFactory節點,並且寫入自己的ip到znode裏面,作爲新的標記。
4.此時Agents也會知道主的TaskFactory不工作了,爲了防止系統中大量的拋出異常,他們將會先把自己手上的事情做完,然後掛起,等待收到Zookeeper上重新創建一個/TaskFactory節點,收到 EventType.NodeCreated 類型的事件將會繼續工作。
5.原來從的TaskFactory 將自己變成一個主TaskFactory,當系統管理員啓動原來死掉的主的TaskFactory,世界又恢復平靜了。
6.如果一臺代理死掉,其他代理他們將會先把自己手上的事情做完,然後掛起,向TaskFactory發送請求,TaskFactory會重新分配(sharding)帳戶到每個Agent上了,繼續工作。

