




路人甲:薑汁哥,聽說你專欄賣得很火?
還行吧,感謝大家的認可。
路人甲:你這賺了點小錢,就跑路了?上次見你發文章,轉眼已是n年。
沒跑路,沒跑路,我現在夜以繼日的在爲《網工2.0晉級攻略 - 零基礎入門Ansible/Python》趕稿子呢。
路人甲:真會裝。。。。
琢磨了半天,才想出來這麼個用2B鉛筆寫的,廣告成分極大開場白,最近一忙專欄,就沒空更新博客,對不住我的朋友們了。
今天我想和大家聊一個關乎於多年江湖恩怨的話題。
SNMP已死!
喔喔喔,等下,先別急着扔斧頭,大哥,這話不是我說的,是別人說的。

我知道你對SNMP情誼很深,你的網絡全都是靠SNMP罩着呢。
這貨要罷工了,估計老闆馬上就去你家了,估計你新婚之夜也得扛筆記本去機房了。
但是,就像美帝亡我之心不似,很多人早已對SNMP起了歹心,一心想把它幹掉。
我今天來的目的,就是想給大家說說說,別人對SNMP都怎麼看的,他們如何計劃把SNMP幹掉的。
畢竟,有些事情一個巴掌拍不響,肯定事出有因。
我們先別急着反對,看看他們說有沒有道理。
沒道理了,再飛斧頭。
第一:數據不精確
SNMP是基於查詢的模式,網管系統通過定期發送snmp 查詢消息,挨個兒問網絡設備,或者服務器設備?
喂,你好麼?
你哪裏啥情況啊,接口流量是多少,CPU是多少,內佔用率等?
就像大學時候的查房老太太,過一會兒就過來騷擾你一下。
但是這個查詢,畢竟有個時間間隔,一般情況下我們都是配置5分鐘,即300秒。
你要是以一天,或者數小時來看,5分鐘的確很短。
所以一切都很好,很完美。
但是,偶爾就會出問題,我們以基於類似Cacti這種流量監控平臺爲例。
例如,客戶抱怨在某個時間段網速很卡,有丟包現象。
然後工程師查看監控平臺,沒問題啊,我們監控平臺上接口流量非常穩定。
沒見着擁塞。
你說,這個時候,你是說客戶刁蠻,還是說工程師說假話?
其實他們兩個說的都沒錯。
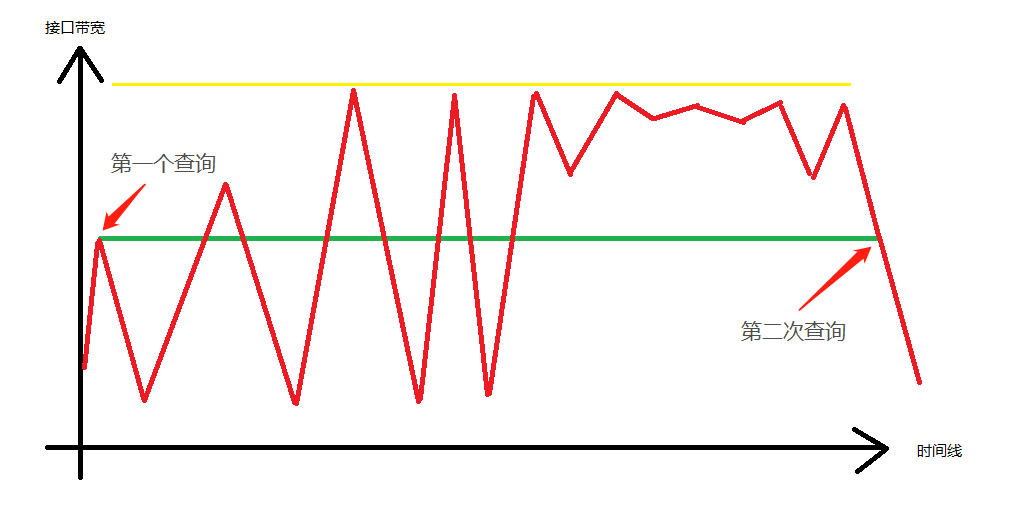
讓我們看下圖:
(薑汁啊,嗯?你這個windows畫圖功底有待加強啊,不是一般的醜啊。)
上圖中,綠色線條爲監控系統認爲的帶寬,而頂上的黃 色 線 條代表接口帶寬,上下波動的代表實時流量。
我猜,不用仔細說,你估計都知道大概了。
沒錯,當5分鐘前SNMP第一次查詢時,得到了第一個值,而第二次查詢後,很碰巧,得到的值和第一次一樣。
所以從SNMP的角度來看,貌似這5分鐘之內,所佔用的接口帶寬沒變化。
但是,真正的用戶數據正如滔滔大浪,風雲變幻。
你不知道在某一個時刻就會有突發數據,而突發兩個字,正說明了他不是持續性的,是臨時突然出現。
可是這突發流量仍然會造成網絡接口丟包。
例如圖中幾個凸出。
可是在監控系統裏面,卻是風平浪靜,歲月靜好啊。
上面的例子可能稍微極端點,因爲完全平直的監控平臺流量線,不太可能。
但是很平滑,而不是突突突的突發流量,倒是實實在在發生的。
例如,下面又是另外一個反例:
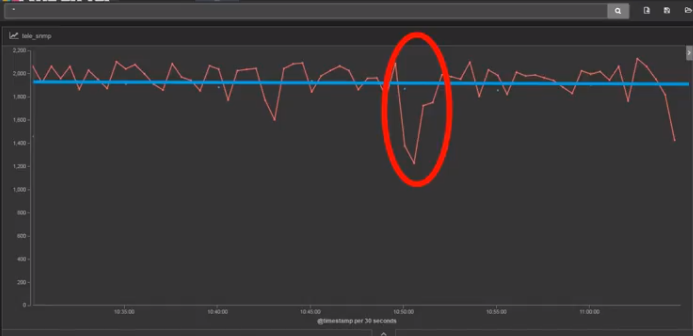
下圖中, 藍色線條,很不幸,仍然是SNMP查詢。
而紅色線條,是某個監控協議吐出來的數據。
這裏看出,紅色線條非常貼近於真實流量了。
而粗紅色線條圈起來的部分,則是某個故障導致流量暴跌。
可是,SNMP的定期查詢,是看不到這些細節的。
在他的眼裏,永遠是絲般順滑的直線。
第二:出力不討好
上面說了,SNMP因爲定期查詢的原因,導致n多細節漏掉了。
有些小夥伴嘴角上揚,露出壞壞的笑容。
你這還不好解決,把SNMP查詢時間調短一點不就行了麼。
例如,1分鐘,想爽一點30秒也成。
這叫當領導的動嘴,幹活的動腿啊。
相信很多運維朋友肯定體會過,網絡設備CPU定期飆高。
特別有規律,幾分鐘來一把。
而且趕巧的時,網管系統的服務器也特別心有靈犀,兩者一起共振。
你高,我也高。
查來查去,就一個進程搞的事:SNMP。
這不用說,要麼就是監控系統太多,這個系統負責查詢一部分,那個系統負責查詢另外一部分。
這網絡設備吃不消啊。
要麼是一個監控系統,但是查詢內容太多。例如每查詢一次,基本上把網絡設備翻了個底朝天。
因爲這些查詢相應都是基於網絡設備的路由引擎來處理,CPU能不高麼?
所以,修改查詢頻率過高也不行。
第三:不靠譜
上面說完了snmp 查詢,snmp的trap消息也是存在問題。
一般情況下我們都是用UDP來承載SNMP消息,那UDP的德行你們也懂的。
沒問題還好,有啥問題了,直接當場把數據包丟了,關鍵是還不告訴你數據包被它丟了,這個品行值得懷疑。
一般協議還行,但是SNMP trap就這麼一個啊。
你要是一個接口down掉了,網絡設備就發一次,僅此一次trap消息這個獨苗苗。
UDP照丟不誤。
丟了以後,網絡設備拍拍屁股說,反正我發出去了。
網管系統說,我沒看見,不知道。
最後誰倒黴?
搞運維的工程師麼,還用說。
網絡世界,其實也有國企。
另外一個問題,我自己就遇到過,例如當一臺監控平臺設備同時管控上千臺設備的時候。
這些不同時間段的snmp trap消息就像洪水一樣涌入監控平臺設備,可是當這些trap在進入監控平臺內部snmp進程的時候,因爲開源軟件的某些bug,併發數不夠了,導致trap在設備內部軟件隊列排着隊,進場。
然後滑稽的一幕出現了,2個小時前一臺網絡設備掛了,網管中心監控人員開心的吃着火鍋唱着歌。直到有人衝到辦公室說,我們網斷了,什麼情況?
沒有啊,你看監控平臺,全是綠油油的燈,多美。
兩小時以後,有人大呼,設備down了。
那回到問題本身,假設現在有一個重要接口down掉了,靠SNMP你怎麼解決?
A. 咱把查詢時間調節到每秒查詢吧?
B. 等着SNMP trap消息吧?
你說上面兩個,你選擇哪個?
第四:不完全兼容
你是否遇到如下場景:
一早上,什麼事情沒幹,光百度了。
百度什麼?
關鍵字:某某設備的MIB庫?
或者,關鍵字:某某設備SNMP 查詢某個數值。
這些事情,真心煩心。
到最後怎麼解決的?
唉,還能怎麼解決,敲命令行收集唄。
要是會編程,就寫個程序來敲命令收集唄。
要是當領導了,就找個會寫代碼的工程師,寫個程序來敲命令收集唄。
第五:毫無人性的OID值
問你個問題,你知道這是什麼?
.1.3.6.1.2.1.2.1.8
答:SNMP OID值。
再問?
什麼OID值?
如果你說:這指代IF-MIB的接口狀態,ifOperStatus
恭喜你,你可以進入非正常人類研究中心參觀了。
我相信你也玩過snmpwalk,你walk一把出來的全是一堆非人類語言,密密麻麻的數字。
你說上班的心情怎麼能好?
SNMP 小結
不敢再說多了,說多了都是在拉仇恨,畢竟包括我在內很多人都還在依靠着SNMP,不伺候好了,小心給你罷工。
綜上所述,SNMP在現如今的網絡環境下,的確遇到了瓶頸。
尤其是網絡規模日益擴大的今天。
所以,應了那句話:
有些SNMP還活着,但是其實它已經死了。。
怎麼辦?
從拉(Pull) 到推(Push)的變化。
我們能不能換個角度,把傳統的從監控系統到網絡設備”拉“數據的方法,變爲網絡設備主動向監控系統”推“數據的方法?
例如,以SNMP 爲例的設備狀態獲取方法是拉的方法,即所謂的查詢。
這就導致了網絡設備被動響應,因爲你不知道什麼時候SNMP查詢會飛過來,等它來了,網絡設備不得不分配資源處理。
但是,換個角度,如果採用主動上報的方式,這個問題就解決了。
因爲主動上報,網絡設備握有主動權,開發人員可以根據實際運行情況調整設備資源利用率和負載。
爲了方便閱讀,下面是兩者的一個簡單對比:

不用說,一番PK下來,除了靈活性敗給被動查詢,其他方面主動上報”推“的方式優勢巨大。
未來趨勢:Streaming Telemetry 流遙測技術
這個名字很吊,流遙測技術。
其實,簡單來講。它就是實現了上述“推”數據的方法。
那如何高效的完成“推”的這個動作呢?
Streaming Telemetry有如下特點:
1. 基於數據層面的數據上報
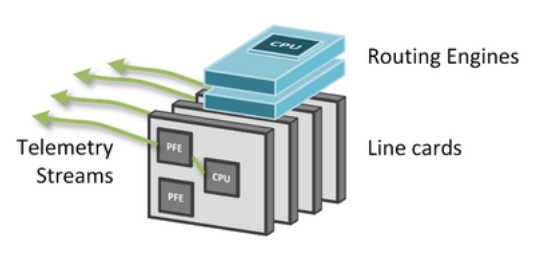
傳統的SNMP,不管是查詢還是Trap,都是路由引擎,控制層面來處理。
但是Streaming Telemetry則可以藉助於廠商支持,在硬件板卡ASIC層面植入代碼,直接從板卡導出實時數據。
而板卡導出的數據是按照線速發送,從而使得上層的路由引擎專注於處理協議和路由計算等。
如下圖所示:
2.高擴展性
基於第一條數據層面的原因,Stream Telemetry的擴展性大大增強。
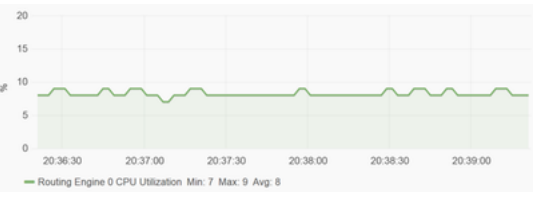
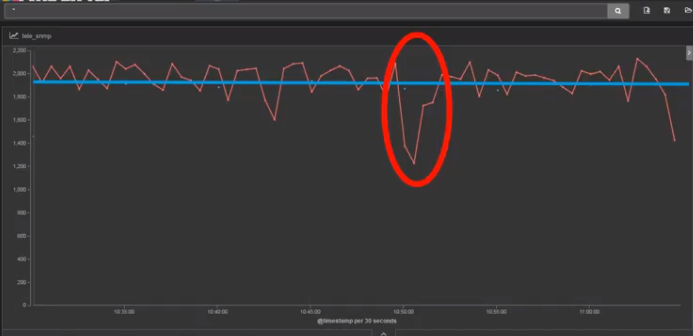
例如下面這張圖是一張CPU的利用率圖。(設備型號未知)
大致看來,CPU利用率徘徊在8%左右。
但是,這臺設備配置了Stream Telemetry主動上報。
你猜,它都上報了多少內容?
下面是數據:
- 每15秒上報一次
- 超過60種指標上報
- 包含500多個上報類型
- 176個萬兆接口的輸入,輸出統計,error數,Qos隊列數統計。
- 每一個接口都包含IPv4和IPv6兩種數據類型。
- 最後以及200個MPLS LSP的字節數和數據包數。
太恐怖了,SNMP與之相比,瞬間弱爆了。
這一張圖片紅色線條,在上面提到過是某協議吐出的數據。
不用說,你都知道了。
這就是Streaming Telemetry吐出的數據。
3. 自動支持 Devops運維自動化
Streaming Telemetry因爲兩大優勢,自動對接了當前流行的技術,例如運維自動化技術。
一方面,Streaming Telemetry監控平臺收集到的數據接近於即時信息,所以Devops運維自動化工程師可以有很多不同的玩法,例如根據當前流量數據,結合SDN來自動調整數據轉發路徑。
另外一方面,Streaming Telemetry採用的數據格式都是當今很流行的標準格式和模型。例如JSON,NETCONF,以及YANG模型。
所以,簡單來說,這是一個順應時代的工具和技術。
4. 多選擇
目前Streaming Telemetry技術,有兩個選擇。
一個是Sflow
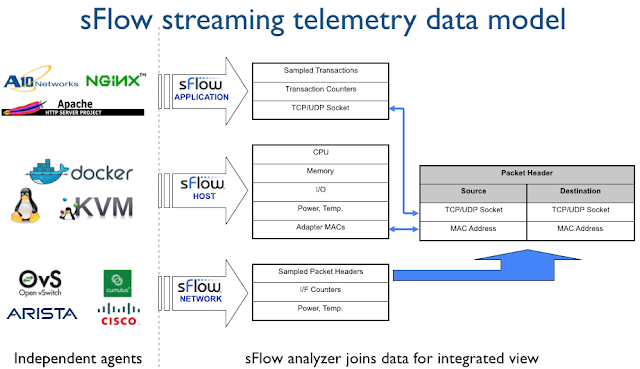
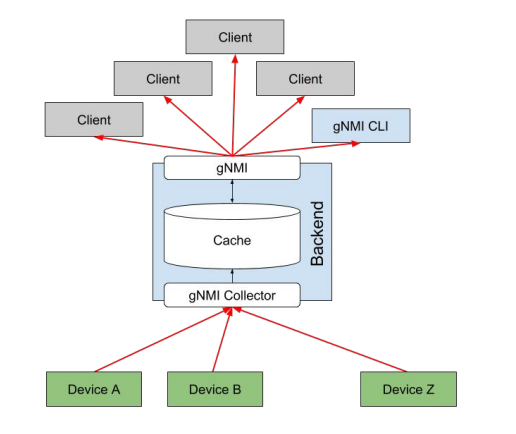
而另外一個是OpenConfig Telemetry
(已經在Google部署,30%的廠商設備已經開啓Streaming Telemetry,每秒百萬級別的更新量。)

上面兩家已經有很多廠商跟進了。
例如思科和Juniper針對上面兩種都可以做相應的配置。
感興趣朋友可以去看看官方配置文檔。
此篇文章先打個頭哨。
如果你對於sflow,或者Openconfig乾的事兒很感興趣。
請留言,我下篇文章針對性的一起聊細節。
最後
說了這麼多,最後聊聊情懷。
也就是最近5-6年的時光,計算機網絡這個行業,已經算是翻天覆地的變化了。
各種新技術層出不窮,百花齊放,百家爭鳴。
而當我不斷觸碰到這些新技術時,心裏不光被觸動,更重要的是一種時刻存在的危機感。
所以,我希望自己能夠憑藉有限的時間和精力,構築一個小小的信息橋樑,不管你是因爲英語這個鴻溝,還是其他原因也好,我們一起爲未來的到來,一起努力。
順便做個小小的推廣:
如果你不知道上面說的JSON,NETCONF,YANG模型是什麼意思?
如果你想學習自動化?
或者,你就是想找一羣志同道合的好xxx(原文是 基 友,和諧版本爲×××),暢談網絡技術。而不是一次一次的加入一個死寂一般的羣。
那麼,我想我的專欄 《網工2.0晉級攻略 - 零基礎入門Ansible/Python》會滿足你上面所有需求。
加入我們,迎接未來。
末了,就以崔健《不是我不明白 這世界變化快》的歌詞結尾,國慶快樂。
不是我不明白
- 崔健
放眼看那座座高樓如同那稻麥
看眼前是人的海洋和交通的堵塞
我左看右看前看後看還是看不過來
這個這個那個那個越看越奇怪
過去我不知什麼是寬闊胸懷
過去我不知世界有很多奇怪
過去我幻想的未來可不是現在
現在才似乎清楚什麼是未來
噢……
不是我不明白,這世界變化快