




原創作品,允許轉載,轉載時請務必以超鏈接形式標明文章 原始出處 、作者信息和本聲明。否則將追究法律責任。http://jimmyli.blog.51cto.com/3190309/1183766
搜索引擎蜘蛛給網站帶來的危害,有效指引爬蟲對應的措施(最準確搜索引擎蜘蛛名稱)
簡要:
1.搜索引擎爬蟲的危害,蜘蛛對網站的負面影響。
2.有效指引搜索引擎對應的措施,及解決方法。
3.收集最新最準確各大搜索引擎蜘蛛名稱。
一、搜索引擎的蜘蛛,是不是爬得越多越好?
當然不是!不論什麼搜索引擎的爬蟲,來抓取你網站的頁面的時候,肯定在消耗你的網站資源,例如網站的連接數、網絡帶寬資源(空間流量)、服務器的負載。
另外,搜索引擎的爬蟲來抓取你的頁面數據後,它也不一定收用數據。只代表它“到此一遊”留下痕跡而已。因此你的網站爲它“服務過、接待過”。
對於一個原創內容豐富,URL結構合理易於爬取的網站來說,簡直就是各種爬蟲的盤中大餐,很多網站的訪問流量構成當中,爬蟲帶來的流量要遠遠超過真實用戶訪問流量,甚至爬蟲流量要高出真實流量一個數量級。像提高網站有效利用率雖然設置了相當嚴格的反爬蟲策略,但是網站處理的動態請求數量仍然是真實用戶訪問流量的2倍。可以肯定的說,當今互聯網的網絡流量至少有2/3的流量爬蟲帶來的。因此反爬蟲是一個值得網站長期探索和解決的問題。![]()
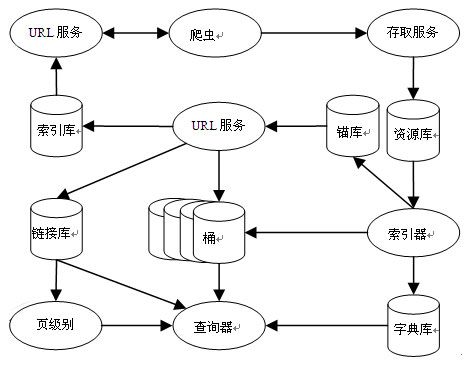
搜索引擎的主要工作流程(圖)
搜索引擎爬蟲對網站的負面影響。
1.網站有限的帶寬資源,而爬蟲的量過多,導致正常用戶訪問緩慢。
例如,原本虛擬主機主機的連接數受限,帶寬資源也是有限。這種情況搜索引擎爬蟲受影響呈現更明顯。
2.搜索引擎爬蟲過頻密,抓取掃描很多無效頁面。甚至抓頁面抓到服務器報502、500 、504 等服務器內部錯誤了,蜘蛛爬蟲還在不停使勁抓取。
不論是實際生產監控,還是網友反映,部分搜索引擎爬蟲可用幾個詞來形容“壞蜘蛛”“惡爬蟲”。很多討論搜索引擎相關的文章,已經將它們列過排行榜。有興趣的可更多瞭解它。
不論是實際生產監控,還是網友反映,部分搜索引擎爬蟲可用幾個詞來形容“壞蜘蛛”“惡爬蟲”。很多討論搜索引擎相關的文章,已經將它們列過排行榜。有興趣的可更多瞭解它。
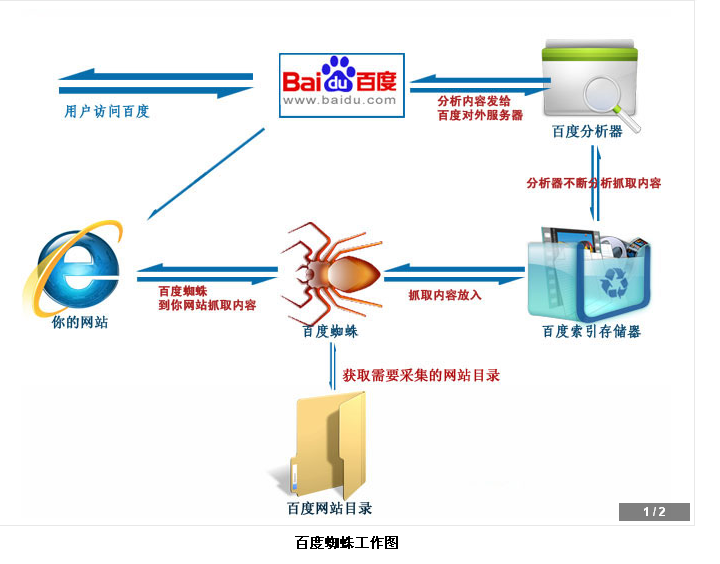
百度蜘蛛工作圖
3.與網站主題不相關的搜索引擎爬蟲消耗資源。
例如,典型的例子搜索引擎“一淘網蜘蛛(EtaoSpider)爲一淘網抓取工具。”被各大電子商務購物網站屏蔽。拒絕一淘網抓取其商品信息及用戶產生的點評內容。被禁止的原因首先應該是它們之間沒有合作互利的關係,還有就是EtaoSpider爬蟲是一個抓取最瘋狂的蜘蛛。統計發現EtaoSpider爬蟲的一天爬行量比“百度蜘蛛:Baiduspider”“360蜘蛛:360Spider”“SOSO蜘蛛:Sosospider”等主流蜘蛛爬蟲多幾倍,並且是遠遠的多。重點是EtaoSpider被抓取只會消耗你的網站資源,它不會給你帶來訪問量,或者其它對你有利用的。中文成語詞典可用一個詞來形容,這個詞留給大家想吧。
例如,典型的例子搜索引擎“一淘網蜘蛛(EtaoSpider)爲一淘網抓取工具。”被各大電子商務購物網站屏蔽。拒絕一淘網抓取其商品信息及用戶產生的點評內容。被禁止的原因首先應該是它們之間沒有合作互利的關係,還有就是EtaoSpider爬蟲是一個抓取最瘋狂的蜘蛛。統計發現EtaoSpider爬蟲的一天爬行量比“百度蜘蛛:Baiduspider”“360蜘蛛:360Spider”“SOSO蜘蛛:Sosospider”等主流蜘蛛爬蟲多幾倍,並且是遠遠的多。重點是EtaoSpider被抓取只會消耗你的網站資源,它不會給你帶來訪問量,或者其它對你有利用的。中文成語詞典可用一個詞來形容,這個詞留給大家想吧。
4.一些搜索引擎開發程序員,它們寫的爬蟲程序在測試爬行。你懂的...
5.robots.txt文件不是萬能!
肯定有很多人認爲,在robots.txt設置屏蔽搜索引擎爬蟲即可,或者允許某些特定的搜索引擎爬蟲,能達到你預想效果。
不錯正規的搜索引擎會遵守規則,且不會及時生效。實際中某些蜘蛛往往不是這樣的,先掃描抓取你的頁面,無視你的robots.txt。也可能它抓取後不一定留用;或者它只是統計信息,收集互聯網行業趨勢分析統計。
肯定有很多人認爲,在robots.txt設置屏蔽搜索引擎爬蟲即可,或者允許某些特定的搜索引擎爬蟲,能達到你預想效果。
不錯正規的搜索引擎會遵守規則,且不會及時生效。實際中某些蜘蛛往往不是這樣的,先掃描抓取你的頁面,無視你的robots.txt。也可能它抓取後不一定留用;或者它只是統計信息,收集互聯網行業趨勢分析統計。
6.還有一種它們不是蜘蛛,但其有蜘蛛的特性。例如採集軟件,採集程序,網絡掃描e-mail地址的工具,各式各樣的SEO分析統計工具,千奇百怪的網站漏洞掃描工具,等等,只有你想不到的工具,沒有它做不到的...
二、有效指引搜索引擎對應的措施,及解決方法:
1.依據空間流量實際情況,就保留幾個常用的屏蔽掉其它蜘蛛以節省流量。以暫時空間流量還足夠使用,先保證正常瀏覽器優先。
2.從服務器防火牆iptable直接屏蔽蜘蛛IP段、詳細的IP。這是最直接、有效的屏蔽方法。
3.WWW服務器層面做限制。例如Nginx,Squid,Lighttpd,直接通過“http_user_agent”屏蔽搜索引擎爬蟲。
4.最後robots.txt文件做限制。搜索引擎國際規則還是要遵循規則的,讓robots.txt明示公佈於衆。
後續文章會詳細介紹該方法,包括如果發現蜘蛛,從網站的日誌裏統計蜘蛛,發現未知的蜘蛛。針對不同的蜘蛛,屏蔽蜘蛛、禁止爬蟲怎麼樣更高效,更快捷。並且通過實例來介紹。
象形圖示蜘蛛,爬蟲機器人(圖)
三、收集最新最準確各大搜索引擎蜘蛛名稱
信息來源線上:最新最準確
根據線上空間的訪問日誌來整理常見的蜘蛛名稱,不求最全,但力求爬蟲信息資料最新最準確。以下搜索引擎蜘蛛名稱都是根據線上空間日誌親手提取。
各種搜索引擎的蜘蛛爬蟲會不斷地訪問抓取我們站點的內容,也會消耗站點的一定流量,有時候就需要屏蔽某些蜘蛛訪問我們的站點。
其實有效常用的搜索引擎就那麼幾個,只要在robots.txt文件裏把常用的幾個搜索引擎蜘蛛允許放行就好了,其它的爬蟲統統通過通配符(*)禁止掉,屏蔽某些蜘蛛。
現況:
從網上獲取的搜索引擎蜘蛛名稱,幾乎都是原文複製粘貼的轉載又轉載的文章,而且很多的資料都是過期的了,這些舊資料根本就沒修正和更新(實際用處不大),並且關於蜘蛛名稱、大小寫衆說不一,根本就獲取不到一個準確無誤的資料信息。
最新最準確各大搜索引擎蜘蛛名稱:
1、百度蜘蛛:Baiduspider
網上的資料百度蜘蛛名稱有BaiduSpider、baiduspider等,都洗洗睡吧,那是舊黃曆了。百度蜘蛛最新名稱爲Baiduspider。日誌中還發現了Baiduspider-p_w_picpath這個百度旗下蜘蛛,查了下資料(其實直接看名字就可以了……),是抓取圖片的蜘蛛。
常見百度旗下同類型蜘蛛還有下面這些:Baiduspider-mobile(抓取wap)、Baiduspider-p_w_picpath(抓取圖片)、Baiduspider-video(抓取視頻)、Baiduspider-news(抓取新聞)。
注:以上百度蜘蛛目前常見的是Baiduspider和Baiduspider-p_w_picpath兩種。
1、百度蜘蛛:Baiduspider
網上的資料百度蜘蛛名稱有BaiduSpider、baiduspider等,都洗洗睡吧,那是舊黃曆了。百度蜘蛛最新名稱爲Baiduspider。日誌中還發現了Baiduspider-p_w_picpath這個百度旗下蜘蛛,查了下資料(其實直接看名字就可以了……),是抓取圖片的蜘蛛。
常見百度旗下同類型蜘蛛還有下面這些:Baiduspider-mobile(抓取wap)、Baiduspider-p_w_picpath(抓取圖片)、Baiduspider-video(抓取視頻)、Baiduspider-news(抓取新聞)。
注:以上百度蜘蛛目前常見的是Baiduspider和Baiduspider-p_w_picpath兩種。
2、谷歌蜘蛛:Googlebot
這個爭議較少,但也有說是GoogleBot的。谷歌蜘蛛最新名稱爲“compatible; Googlebot/2.1;”。還發現了Googlebot-Mobile,看名字是抓取wap內容的。
這個爭議較少,但也有說是GoogleBot的。谷歌蜘蛛最新名稱爲“compatible; Googlebot/2.1;”。還發現了Googlebot-Mobile,看名字是抓取wap內容的。
3、360蜘蛛:360Spider,它是一個很“勤奮抓爬”的蜘蛛。
4、SOSO蜘蛛:Sosospider,也可爲它頒一個“勤奮抓爬”獎的蜘蛛。
5、雅虎蜘蛛:“Yahoo! Slurp China”或者Yahoo!
名稱中帶“Slurp”和空格,名稱有空格robots里名稱可以使用“Slurp”或者“Yahoo”單詞描述,不知道有效無效。
名稱中帶“Slurp”和空格,名稱有空格robots里名稱可以使用“Slurp”或者“Yahoo”單詞描述,不知道有效無效。
6、有道蜘蛛:YoudaoBot,YodaoBot(兩個名字都有,中文拼音少了個U字母讀音差別很大嘎,這都會少?)
7、搜狗蜘蛛:Sogou News Spider
搜狗蜘蛛還包括如下這些:Sogou web spider、Sogou inst spider、Sogou spider2、Sogou blog、Sogou News Spider、Sogou Orion spider,
(參考一些網站的robots文件,搜狗蜘蛛名稱可以用Sogou概括,無法驗證不知道有沒有效)
搜狗蜘蛛還包括如下這些:Sogou web spider、Sogou inst spider、Sogou spider2、Sogou blog、Sogou News Spider、Sogou Orion spider,
(參考一些網站的robots文件,搜狗蜘蛛名稱可以用Sogou概括,無法驗證不知道有沒有效)
看看最權威的百度的robots.txt ,http://www.baidu.com/robots.txt 就爲Sogou搜狗蜘蛛費了不少字節,佔了一大塊領地。
“Sogou web spider;Sogou inst spider;Sogou spider2;Sogou blog;Sogou News Spider;Sogou Orion spider”目前6個,名稱都帶空格。
“Sogou web spider;Sogou inst spider;Sogou spider2;Sogou blog;Sogou News Spider;Sogou Orion spider”目前6個,名稱都帶空格。
線上常見"Sogou web spider/4.0" ;"Sogou News Spider/4.0" ;"Sogou inst spider/4.0" 可以爲它頒個“佔名爲王”獎。
8、MSN蜘蛛:msnbot,msnbot-media(只見到msnbot-media在狂爬……)
9、必應蜘蛛:bingbot
線上(compatible; bingbot/2.0;)
線上(compatible; bingbot/2.0;)
10、一搜蜘蛛:YisouSpider
11、Alexa蜘蛛:ia_archiver
12、宜搜蜘蛛:EasouSpider
13、即刻蜘蛛:JikeSpider
14、一淘網蜘蛛:EtaoSpider
"Mozilla/5.0 (compatible; EtaoSpider/1.0; http://省略/EtaoSpider)"
"Mozilla/5.0 (compatible; EtaoSpider/1.0; http://省略/EtaoSpider)"
根據上述蜘蛛中選擇幾個常用的允許抓取,其餘的都可以通過robots屏蔽抓取。如果你暫時空間流量還足夠使用,等流量緊張了就保留幾個常用的屏蔽掉其它蜘蛛以節省流量。至於那些蜘蛛抓取對網站能帶來有利用的價值,網站的管理者眼睛是雪亮的。
另外還發現瞭如 YandexBot、AhrefsBot和ezooms.bot這些蜘蛛,據說這些蜘蛛國外噶,對中文網站用處很小。那不如就節省下資源。
小結:
這次分析了對搜索引擎爬蟲的危害,蜘蛛對網站的負面影響;如何有效指引搜索引擎對應的措施,及解決方法;收集來源線上最新最準確各大搜索引擎蜘蛛名稱。
這次分析了對搜索引擎爬蟲的危害,蜘蛛對網站的負面影響;如何有效指引搜索引擎對應的措施,及解決方法;收集來源線上最新最準確各大搜索引擎蜘蛛名稱。