




在九月初BosonNLP全面開放了分詞和詞性標註引擎以後,很多尤其是從事數據處理和自然語言研究的朋友在試用後很好奇,玻森如何能夠做到目前的高準確率?希望這篇文章能夠幫助大家理解玻森分詞背後的實現原理。
衆所周知,中文並不像英文那樣詞與詞之間用空格隔開,因此,在一般情況下,中文分詞與詞性標註往往是中文自然語言處理的第一步。一個好的分詞系統是有效進行中文相關數據分析和產品開發的重要保證。
玻森採用的結構化預測模型是傳統線性條件隨機場(Linear-chain CRF)的一個變種。在過去及幾年的分詞研究中,雖然以字符爲單位進行編碼,從而預測分詞與詞性標註的文獻佔到了主流。這類模型雖然實現較容易,但比較難捕捉到高階預測變量之間的關係。比如傳統進行詞性標註問題上使用Tri-gram特徵能夠得到較高準確率的結果,但一階甚至高階的字符CRF都難以建立這樣的關聯。所以玻森在字符編碼以外加入了詞語的信息,使這種高階作用同樣能被捕捉。
分詞與詞性標註中,新詞識別與組合切分歧義是兩個核心挑戰。玻森在這方面做了不少的優化,包括對特殊字符的處理,對比較有規律的構詞方式的特徵捕捉等。例如,近些年比較流行採用半監督的方式,通過使用在大規模無標註數據上的統計數據來改善有監督學習中的標註結果,也在我們的分詞實現上有所應用。比如通過使用accressory variety作爲特徵,能夠比較有效發現不同領域的新詞,提升泛化能力。
我們都知道上下文信息是解決組合切分歧義的重要手段。而作爲一個面向實際商用環境的算法,除了在準確率上的要求之外,還需要注意模型算法的時間複雜度需要足夠高效。例如,相比於普通的Linear-chain CRF,Skip-chain CRF因爲加入了更多的上下文信息,能夠在準確率上達到更好的效果,但因爲其它在訓練和解碼過程,不論是精確算法還是近似算法,都難以達到我們對速度的要求,所以並沒有在我們最終實現中採用。一個比較有趣的分詞改進是我們捕捉了中文中常見的固定搭配詞對信息。譬如,如 “得出某個結論”、 “回答某個提問”等。如果前面出現 “得出” ,後面出現 “結論” ,那麼“得出”和“結論”作爲一個詞語出現的可能性就會很大,與這種相沖突的分詞方案的可能性就會很小。這類固定搭配也可以被建模,用於解決部分分詞錯誤的問題。
怎樣確定兩個詞是否是固定的搭配呢?我們通過計算兩個詞間的歸一化逐點互信息(NPMI)來確定兩個詞的搭配關係。逐點互信息(PMI),經常用在自然語言處理中,用於衡量兩個事件的緊密程度。歸一化逐點互信息(NPMI)是逐點互信息的歸一化形式,將逐點互信息的值歸一化到-1到1之間。如果兩個詞在一定距離範圍內共同出現,則認爲這兩個詞共現。篩選出NPMI高的兩個詞作爲固定搭配,然後將這組固定搭配作爲一個組合特徵添加到分詞程序中。如“回答”和“問題”是一組固定的搭配,如果在標註“回答”的時候,就會找後面一段距離範圍內是否有“問題”,如果存在那麼該特徵被激活。


歸一化逐點互信息(npmi)的計算公式
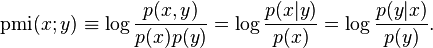
逐點互信息(pmi)的計算公式
可以看出,如果我們提取固定搭配不限制距離,會使後面偶然出現某個詞的概率增大,降低該統計的穩定性。在具體實現中,我們限定了成爲固定搭配的詞對在原文中的距離必須小於一個常數。具體來看,可以採用倒排索引,通過詞找到其所在的位置,進而判斷其位置是否在可接受的區間。這個簡單的實現有個比較大的問題,即在特定構造的文本中,判斷兩個詞是否爲固定搭配有可能需要遍歷位置數組,每次查詢就有O(n)的時間複雜度了,並且可以使用二分查找進一步降低複雜度爲O(logn)。
其實這個詞對檢索問題有一個更高效的算法實現。我們採用滑動窗口的方法進行統計:在枚舉詞的同時維護一張詞表,保存在當前位置前後一段距離中出現的可能成詞的字符序列;當枚舉詞的位置向後移動時,窗口也隨之移動。這樣在遍歷到 “回答” 的時候,就可以通過查表確定後面是否有 “問題” 了,同樣在遇到後面的 “問題” 也可以通過查表確定前面是否有 “回答”。當枚舉下一個詞的時候,詞表也相應地進行調整。採用哈希表的方式查詢詞表,這樣計算一個固定搭配型時間複雜度就可以是O(1)了。

通過引入上述的上下文的信息,分詞與詞性標註的準確率有近1%的提升,而對算法的時間複雜度沒有改變。我們也在不斷迭代升級以保證引擎能夠越來越準確,改善其通用性和易用性。今後我們也會在BosonNLP微信賬戶更多享我們在自然語言處理方面的經驗,歡迎關注!
該文章轉自OSChina