




轉載:http://blog.fens.me/r-probability/
R語言作爲統計學一門語言,一直在小衆領域閃耀着光芒。直到大數據的爆發,R語言變成了一門炙手可熱的數據分析的利器。隨着越來越多的工程背景的人的加入,R語言的社區在迅速擴大成長。現在已不僅僅是統計領域,教育,銀行,電商,互聯網….都在使用R語言。
要成爲有理想的極客,我們不能停留在語法上,要掌握牢固的數學,概率,統計知識,同時還要有創新精神,把R語言發揮到各個領域。讓我們一起動起來吧,開始R的極客理想。

前方
R語言是統計語言,概率又是統計的基礎,所以可以想到,R語言必然要從底層API上提供完整、方便、易用的概率計算的函數。讓R語言幫我們學好概率的基礎課。
目錄
- 隨機變量
- 隨機變量的數字特徵
- 極限定理
1. 隨機變量
- 什麼是隨機變量?
- 離散型隨機變量
- 連續型隨機變量
1). 什麼是隨機變量?
隨機變量(random variable)表示隨機現象各種結果的實值函數。隨機變量是定義在樣本空間S上,取值在實數載上的函數,由於它的自變量是隨機試驗的結果,而隨機實驗結果的出現具有隨機性,因此,隨機變量的取值具有一定的隨機性。
R程序:生成一個在(0,1,2,3,4,5)的隨機變量
> S<-1:5
> sample(S,1)
[1] 2
> sample(S,1)
[1] 3
> sample(S,1)
[1] 5
2). 離散型隨機變量
如果隨機變量X的全部可能的取值只有有限多個或可列無窮多個,則稱X爲離散型隨機變量。
R程序:生成樣本空間爲(1,2,3)的隨機變量X,X的取值是有限的
> S<-1:3
> X<-sample(S,1);X
[1] 2
3). 連續型隨機變量
隨機變量X,取值可以在某個區間內取任一實數,即變量的取值可以是連續的,這隨機變量就稱爲連續型隨機變量
R程序:生成樣本在空間(0,1)的連續隨機函數,取10個值
> runif(10,0,1)
[1] 0.3819569 0.7609549 0.6692581 0.6314708 0.5552201 0.8225527 0.7633086 0.4667188 0.1883553
[10] 0.3741653
2. 隨機變量的數字特徵
- 數學期望
- 方差
- 標準差
- 各種分步的期望和方差
- 常用統計量(最大,最小,中位數,四分位數)
- 協方差
- 相關係數
- 矩(原點矩,中心矩,偏度,峯度)
- 協方差矩陣
1). 數學期望(mathematical expectation)
離散型隨機變量:的一切可能的取值xi與對應的概率Pi(=xi)之積的和稱爲該離散型隨機變量的數學期望,記爲E(x)。數學期望是最基本的數學特徵之一。它反映隨機變量平均取值的大小。
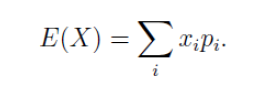
R程序:計算樣本(1,2,3,7,21)的數學期望
> S<-c(1,2,3,7,21)
> mean(S)
[1] 6.8
連續型隨機變量:若隨機變量X的分佈函數F(x)可表示成一個非負可積函數f(x)的積分,則稱X爲連續性隨機變量,f(x)稱爲X的概率密度函數,積分值爲X的數學期望,記爲E(X)。
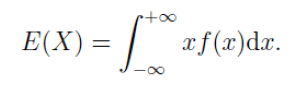
2). 方差(Variance)
方差是各個數據與平均數之差的平方的平均數。在概率論和數理統計中,方差用來度量隨機變量和其數學期望(即均值)之間的偏離程度。
設X爲隨機變量,如果E{[X-E(X)]^2}存在,則稱E{[X-E(X)]^2}爲X的方差,記爲Var(X)。
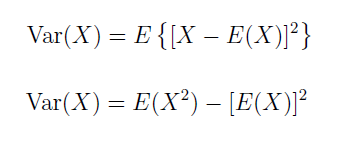
R程序:計算樣本(1,2,3,7,21)的方差
> S<-c(1,2,3,7,21)
> var(S)
[1] 68.2
3). 標準差(Standard Deviation)
標準差是方差的算術平方根sqrt(var(X))。標準差能反映一個數據集的離散程度。平均數相同的,標準差未必相同。
R程序:計算樣本(1,2,3,7,21)標準差
> S<-c(1,2,3,7,21)
> sd(S)
[1] 8.258329
4). 各種分步的期望和方差
- 離散型分佈:兩點分佈,二項分佈,泊松分佈等
- 連續型分佈:均勻分佈,指數分佈,正態分佈,伽馬分佈等
對於某一特定場景,其所符合的分佈規律一般先驗給出
請參考文章:http://blog.fens.me/r-density/
5). 常用統計量
衆數(Mode): 一組數據中出現次數最多的數值,叫衆數,有時衆數在一組數中有好幾個。
R程序:計算樣本(1,2,3,3,3,7,7,7,7,9,10,21)的衆數
> S<-c(1,2,3,3,3,7,7,7,7,9,10,21)
> names(which.max(table(S)))
[1] "7"
最小值(minimum): 在給定情形下可以達到的最小數量或最小數值
R程序:計算樣本(2,3,3,3,7,7,7,7,9,10,21)的最小值
> S<-c(2,3,3,3,7,7,7,7,9,10,21)
#最小值
> min(S)
[1] 2
#最小值的索引
> which.min(S)
[1] 1
最大值(maximum): 在給定情形下可以達到的最大數量或最大數值
R程序:計算樣本(2,3,3,3,7,7,7,7,9,10,21)的最大值
> S<-c(2,3,3,3,7,7,7,7,9,10,21)
#最大值
> max(S)
[1] 21
#最大值的索引
> which.max(S)
[1] 11
中位數(Medians): 是指將統計總體當中的各個變量值按大小順序排列起來,形成一個數列,處於變量數列中間位置的變量值就稱爲中位數。
R程序:計算樣本(1,2,3,4,5)的中位數
> S<-c(1,2,3,4,5)
> median(S)
[1] 3
四分位數(Quartile): 用於描述任何類型的數據,尤其是偏態數據的離散程度,即將全部數據從小到大排列,正好排列在上1/4位置叫上四分位數,下1/4位置上的數就叫做下四分位數.
R程序:計算樣本(1,2,3,4,5,6,7,8,9)的四分位數
> S<-c(1,2,3,4,5,6,7,8,9)
> quantile(S)
0% 25% 50% 75% 100%
1 3 5 7 9
> fivenum(S)
[1] 1 3 5 7 9
通用的計算統計函數:
R程序:計算樣本(1,2,3,4,5,6,7,8,9)的統計函數
> S<-c(1,2,3,4,5,6,7,8,9)
> summary(S)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1 3 5 5 7 9
6). 協方差(Covariance)
協方差用於衡量兩個變量的總體誤差。而方差是協方差的一種特殊情況,即當兩個變量是相同的情況。設X,Y爲兩個隨機變量,稱E{[X-E(X)][Y-E(Y)]}爲X和Y的協方差,記錄Cov(X,Y)。
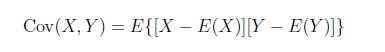
R程序:計算X(1,2,3,4)和Y(5,6,7,8)的協方差
> X<-c(1,2,3,4)
> Y<-c(5,6,7,8)
> cov(X,Y)
[1] 1.666667
7). 相關係數(Correlation coefficient)
相關係數是用以反映變量之間相關關係密切程度的統計指標。相關係數是按積差方法計算,同樣以兩變量與各自平均值的離差爲基礎,通過兩個離差相乘來反映兩變量之間相關程度。當Var(X)>0, Var(Y)>0時,稱Cov(X,Y)/sqrt(Var(X)*Var(Y))爲X與Y的相關係統。
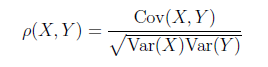
R程序:計算X(1,2,3,4)和Y(5,7,8,9)的相關係數
> X<-c(1,2,3,4)
> Y<-c(5,7,8,9)
> cor(X,Y)
[1] 0.9827076
8). 矩
原點矩(moment about origin): 對於正整數k,如果E|X^k|存在,稱V^k=E(X^k)爲隨機變量X的k階原點矩。X的數學期望是X的一階原點矩,即E(x)=v1.
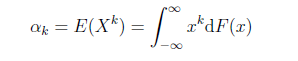
R程序:計算S(1,2,3,4,5)的一階原點矩(均值)
> S<-c(1,2,3,4,5)
> mean(S)
[1] 3
中心矩(moment about centre): 對於正整數k,如果EX存在,且E(|X - EX|^k)也存在,則稱E[X-EX]^k爲隨機變量X的k階中心矩。如X的方差是X的二階中心矩,即D(X)=E{[X-E(X)]^2}
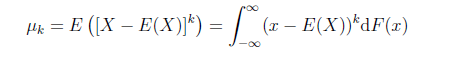
R程序:計算S(1,2,3,4,5)的二階中心矩(方差)
> S<-c(1,2,3,4,5)
> var(S)
[1] 2.5
距是廣泛應用的一類數學特徵,均值和方差分別就是一階原點矩和二階中心矩。
偏度(skewness): 是統計數據分佈偏斜方向和程度的度量,是統計數據分佈非對稱程度的數字特徵。設分佈函數F(x)有中心矩u2=E(X −E(X))^2, u3 = E(X −E(X))^3,則Cs=u3/u2^(3/2)爲偏度係數。
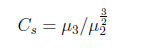
當Cs>0時,概率分佈偏向均值右則,Cs<0時,概率分佈偏向均值左則。
R語言:計算10000個正態分佈的樣本的偏度
> library(PerformanceAnalytics)
> S<-rnorm(10000)
> skewness(S)
[1] -0.00178084
> hist(S,breaks=100)
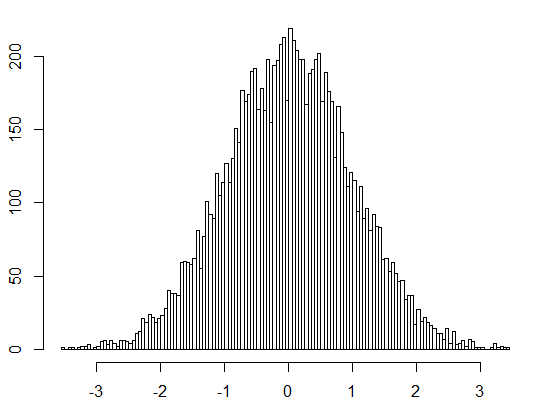
峯度(kurtosis): 又稱峯態係數。表徵概率密度分佈曲線在平均值處峯值高低的特徵數。峯度刻劃不同類型的分佈的集中和分散程序。設分佈函數F(x)有中心矩u2=E(X −E(X))^2, u4=E(X −E(X))^4,則Ck=u4/(u2^2-3)爲峯度係數。
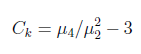
R語言:計算10000個正態分佈的樣本的峯度,(同偏度的樣本數據)
> library(PerformanceAnalytics)
> kurtosis(S)
[1] -0.02443549
> hist(S,breaks=100)
8). 協方差矩陣(covariance matrix)
協方差矩陣是一個矩陣,其每個元素是各個向量元素之間的協方差。是從標量隨機變量到高維度隨機向量的自然推廣。設X = (X1,X2, ... ,Xn), Y = (Y1, Y2, ..., Ym) 爲兩個隨機變量,則Cov(X,Y)爲X,Y的協方差矩陣.
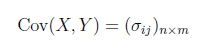
R語言:計算協方差矩陣
> x=as.data.frame(matrix(rnorm(10),ncol=2))
> x
V1 V2
1 -2.11315384 -2.55189840
2 -0.96631271 -1.36148355
3 -0.02835058 -0.82328774
4 -1.86669567 -0.07201353
5 0.27324957 -2.23835218
> var(x)
V1 V2
V1 1.13470650 -0.09292042
V2 -0.09292042 1.03172261
> cov(x)
V1 V2
V1 1.13470650 -0.09292042
V2 -0.09292042 1.03172261
3. 極限定理
- 大數定律
- 中心極限定理
1). 大數定律
大數定律(law of large numbers),又稱大數定理,是判斷隨機變量的算術平均值是否向常數收斂的定律,是概率論和數理統計學的基本定律之一。
設X1,X2,...,Xk, 是隨機變量序列且E(Xk)存在(k=1,2,3...), Yn = 1/n * (X1 +X2+ ... + Xk),對於任意給定的ε > 0, 有
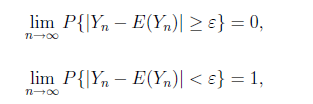
則稱隨機變量序列{Xk}服從大數定律。
三個重要定律
- Bernoulli大數定律
- Chebyshev(切比雪夫)大數定律
- Khintchin(辛欽)大數定律
Bernoulli(貝努力)大數定律
設Na是n次獨立重複試驗中A發生的次數,p是事件A在每次試驗中發生的概率,則對任意的正數ε > 0,有
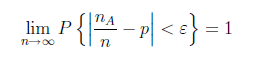
Bernoulli大數定律揭示了“頻率穩定於概率”說法的實質。
Chebyshev(切比雪夫)大數定律
設隨機變量X1,X2,...Xk相互獨立,且具有相同的期望與方差:E(Xk)=μ, Var(Xk) = σ^2, (k = 1, 2, ...), 則對於任意的正數ε > 0, 有
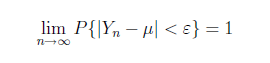
Khintchin(辛欽)大數定律
設隨機變量X1,X2...Xk相互獨立,服從相同的分佈,且其期望E(Xk) = μ , (k = 1, 2,...), 則對於任意的正數ε > 0, 有
若對隨機變量序列X1, X2, ...Xk存在常數a, 使得對於任意的正數ε > 0, 有
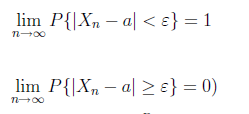
成立,則稱Xk依概率收斂於a,則Chebyshev大數定律和Khintchin大數定律有
大數定律定理
設隨機變量X具有期望E(X)=μ,方差Var(X) = σ2, 則對於任意ε > 0, 有
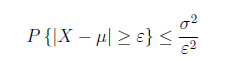
R語言:假設投硬幣,正面概率是0.5,投4次時,計算得到2次正面的概率?根據大數定律,如果投是10000次,計算5000次正面的概率?
#計算2次正面的的概率
> choose(4,2)/2^4 #choose組合數的計算:從4中選擇2個
[1] 0.375
#計算5000次正面的的概率
> pbinom(5000, 10000, 0.5) #pbinom二向分佈,5000爲分位數,產生10000個隨機數,每個概率0.5
[1] 0.5039893
2). 中心極限定理(central limit theorem)
中心極限定理是判斷隨機變量序列部分和的分佈是否漸近於正態分佈的一類定理。在自然界及生產科學實踐中,一些現象受到許多相互獨立的隨機因素的影響,如果每個因素的影響都很小,那麼部的影響可以看作是服從正太分佈。中心極限定理正是從數學上論證了這一現象。
設從均值爲μ、方差爲σ^2;(有限)的任意一個總體中抽取樣本量爲n的樣本,當n充分大時,樣本均值的抽樣分佈近似服從均值爲μ、方差爲σ^2/n的正態分佈。
兩個最著名的中心極限宣
- 列維定理(Lindburg-Levy)
- 拉普拉斯定理(de Movire - Laplace)
列維定理(Lindburg-Levy)
即獨立同分布隨機變量序列的中心極限定理。它表明,獨立同分布、且數學期望和方差有限的隨機變量序列的標準化和以標準正態分佈爲極限。
設隨機變量X1,X2,......Xn,......相互獨立,服從同一分佈,且具有數學期望和方差:E(Xk)=μ,D(Xk)=σ^2>0(k=1,2....),則隨機變量之和的標準化變量的分佈函數Fn(x)對於任意x滿足limFn(x)=Φ(x),n→∞ 其中Φ(x)是標準正態分佈的分佈函數。
拉普拉斯定理(de Movire - Laplace)
即服從二項分佈的隨機變量序列的中心極限定理。它指出,參數爲n, p的二項分佈以np爲均值、np(1-p)爲方差的正態分佈爲極限。
R語言:中心極限定理模擬,從指數分佈到正態分佈
if (!require(animation)) install.packages("animation")
library(animation)
ani.options(interval = 0.1, nmax = 100)
par(mar = c(4, 4, 1, 0.5))
clt.ani()
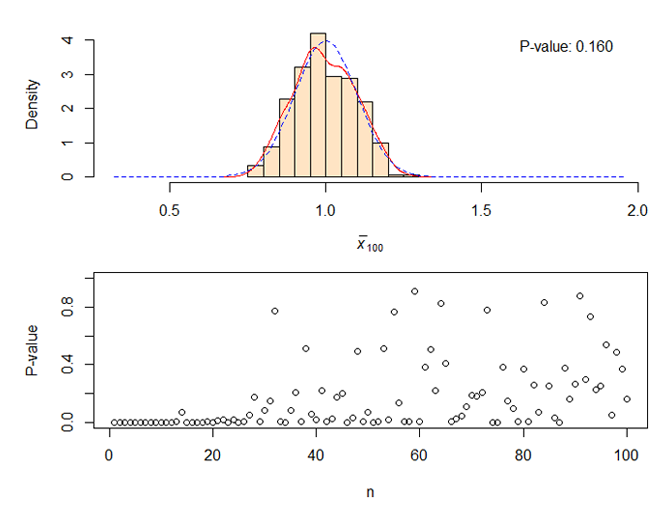
掌握R語言,就可以快速的把概率的知識,用R語言進行現實,非常有利於幫助我們解決生活中遇到的問題。
參考資料:
- 圖書:統計建模與R軟件
- 百度百科
- 從中心極限定理的模擬到正態分佈

