




此文凝聚筆者不少心血請尊重筆者勞動,轉載請註明出處。http://freeze.blog.51cto.com/
隨着Internet技術的迅猛發展,網絡技術、性能的不斷提高,高可伸縮性、高可用性、可管理性、價格有效性的網絡服務技術將成爲網絡服務技術的主導。各種平臺下的技術方案應運而生。本文試圖以一篇完整的理論+實踐性的文字來介紹如何在優秀的開源操作系統Linux下創建低成本、高性能、高可用的服務集羣系統(也叫集羣系統),希望通過筆者努力,讓您對集羣有一定的瞭解。

- 高可擴展性:如上所述。
- 高可用性:集羣中的一個節點失效,它的任務可以傳遞給其他節點。可以有效防止單點失效。
- 高性能:負載平衡集羣允許系統同時接入更多的用戶。
- 高性價比:可以採用廉價的符合工業標準的硬件構造高性能的系統。
集羣類型 : 最常見的三種集羣類型包括: 負載均衡集羣: LB: load balancing 高可用性集羣: HA:High Availability 高性能也叫科學集羣:HP : High Performance 負載均衡集羣 (LB:load balancing) 負載均衡集羣爲企業需求提供了更實用的系統。如名稱所暗示的,該系統使負載可以在計算機集羣中儘可能平均地分攤處理。該負載可能是需要均衡的應用程序處理負載或網絡流量負載。這樣的系統非常適合於運行同一組應用程序的大量用戶。每個節點都可以處理一部分負載,並且可以在節點之間動態分配負載,以實現平衡。對於網絡流量也是如此。通常,網絡服務器應用程序接受了太多入網流量,以致無法迅速處理,這就需要將流量發送給在其它節點上運行的網絡服務器應用。還可以根據每個節點上不同的可用資源或網絡的特殊環境來進行優化。 高可用性集羣 (HA:High Availability) 高可用性集羣的出現是爲了使集羣的整體服務儘可能可用,以便考慮計算硬件和軟件的易錯性。如果高可用性集羣中的主節點發生了故障,那麼這段時間內將由次節點代替它。次節點通常是主節點的鏡像,所以當它代替主節點時,它可以完全接管其身份,並且因此使系統環境對於用戶是一致的。 在集羣的這三種基本類型之間,經常會發生混合與交雜。於是,可以發現高可用性集羣也可以在其節點之間均衡用戶負載,同時仍試圖維持高可用性程度。同樣,可以從要編入應用程序的集羣中找到一個並行集羣,它可以在節點之間執行負載均衡。儘管集羣系統本身獨立於它在使用的軟件或硬件,但要有效運行系統時,硬件連接將起關鍵作用。 高性能集羣 (HP :High Performance ) 通常,第一種涉及爲集羣開發並行編程應用程序,以解決複雜的科學問題。這是並行計算的基礎,儘管它不使用專門的並行超級計算機,這種超級計算機內部由十至上萬個獨立處理器組成。但它卻使用商業系統,如通過高速連接來鏈接的一組單處理器或雙處理器 PC,並且在公共消息傳遞層上進行通信以運行並行應用程序。因此,您會常常聽說又有一種便宜的 Linux 超級計算機問世了。但它實際是一個計算機集羣,其處理能力與真的超級計算機相等,通常一套象樣的集羣配置開銷要超過 $100,000。這對一般人來說似乎是太貴了,但與價值上百萬美元的專用超級計算機相比還算是便宜的。 |
下面筆者着重介紹前兩種集羣方式,也是企業中最常用的。(不是做科學研究,模擬原子彈爆炸,宇宙曲線計算等的大型項目高性能集羣一般用不到)
一、負載均衡集羣 (LB:load balancing)
|
負載均衡技術主要應用 1、DNS負載均衡 最早的負載均衡技術是通過DNS來實現的,在DNS中爲多個地址配置同一個名字,因而查詢這個名字的客戶機將得到其中一個地址,從而使得不同的客戶訪問不同的服務器,達到負載均衡的目的。DNS負載均衡是一種簡單而有效的方法,因此,對於同一個名字,不同的客戶端會得到不同的地址,他們也就連結不同地址上的Web服務器,從而達到負載平衡的目的。例如 : 當客戶端連結 www.51cto.com這名稱時,DNS
有能力依序將名稱解析到 202.1.1.1 、 202.1.1.2 、202.1.1.3和 202.1.1.4等不同的網絡地址,而這些是提供相同服務的主機,讓客戶端不自覺有不同 . |
筆者用一幅圖爲例,簡單介紹下負載均衡原理:
用戶通過互聯網訪問到某個網站時,,前端的Load Balancer(類似負載均衡器)根據不同的算法或某種特定的方式,將請求轉發到後端真正的服務器(節點),後臺多臺服務器共同分擔整個網站的壓力。後臺的某個節點如果有宕機,其他節點也可以提供服務,從而維持整個網站的正常運行.

負載均衡可以針對不同的網路層次
鏈路聚合技術(第二層負載均衡)是將多條物理鏈路當作一條單一的聚合邏輯鏈路使用,網絡數據流量由聚合邏輯鏈路中所有物理鏈路共同承擔,由此在邏輯上增大了鏈路的容量,使其能滿足帶寬增加的需求.
現在經常使用的是4至7層的負載均衡。
第四層負載均衡將一個Internet上合法註冊的IP地址映射爲多個內部服務器的IP地址,對每次TCP連接請求動態使用其中一個內部IP地址,達到負載均衡的目的。在第四層交換機中,此種均衡技術得到廣泛的應用,一個目標地址是服務器羣VIP(虛擬IP,Virtual IP address)連接請求的數據包流經交換機,交換機根據源端和目的IP地址、TCP或UDP端口號和一定的負載均衡策略,在服務器IP和VIP間進行映射,選取服務器羣中最好的服務器來處理連接請求。
第七層負載均衡控制應用層服務的內容,提供了一種對訪問流量的高層控制方式,適合對HTTP服務器羣的應用。第七層負載均衡技術通過檢查流經的HTTP報頭,根據報頭內的信息來執行負載均衡任務。
第七層負載均衡優點表現在如下幾個方面:
1。通過對HTTP報頭的檢查,可以檢測出HTTP400、500和600系列的錯誤信息,因而能透明地將連接請求重新定向到另一臺服務器,避免應用層故障。
2。可根據流經的數據類型(如判斷數據包是圖像文件、壓縮文件或多媒體文件格式等),把數據流量引向相應內容的服務器來處理,增加系統性能。
3。能根據連接請求的類型,如是普通文本、圖象等靜態文檔請求,還是asp、cgi等的動態文檔請求,把相應的請求引向相應的服務器來處理,提高系統的性能及安全性。
缺點: 第七層負載均衡受到其所支持的協議限制(一般只有HTTP),這樣就限制了它應用的廣泛性,並且檢查HTTP報頭會佔用大量的系統資源,勢必會影響到系統的性能,在大量連接請求的情況下,負載均衡設備自身容易成爲網絡整體性能的瓶頸。
實現負載均衡有兩種方式:
1、硬件:
如果我們搜一搜"負載均衡",會發現大量的關於F5等負載均衡設備的內容,基於硬件的方式,能夠直接通過智能交換機實現,處理能力更強,而且與系統無關,這就是其存在的理由.但其缺點也很明顯:
首先是貴,這個貴不僅是體現在一臺設備上,而且體現在冗餘配置上.很難想象後面服務器做一個集羣,但最關鍵的負載均衡設備卻是單點配置,一旦出了問題就全趴了.
第二是對服務器及應用狀態的掌握:硬件負載均衡,一般都不管實際系統與應用的狀態,而只是從網絡層來判斷,所以有時候系統處理能力已經不行了,但網絡可能還來得及反應(這種情況非常典型,比如應用服務器後面內存已經佔用很多,但還沒有徹底不行,如果網絡傳輸量不大就未必在網絡層能反映出來)。
所以硬件方式更適用於一大堆設備、大訪問量、簡單應用。
一般而言,硬件負載均衡在功能、性能上優於軟件方式,不過成本昂貴。
在網站上搜索了一些硬件負載均衡設備的報價.是不是很嚇人.動則幾十萬,貴則上百萬.

|
硬件load balance廠商和產品列表: 公司名稱: Alteon Websystems(Nortel): 產品 ACEDirector, AceSwitch 180等 http://products.nortel.com/go/product_content.jsp?segId=0&parId=0&prod_id=37160&locale=en-US ------------------------------------------------------------------------------------------------------------------------------------------公司名稱: F5 networks:
產品: BIG-IP http://www.f5networks.co.jp/product/bigip/ltm/index.html http://www.f5.com/products/bigip/ ------------------------------------------------------------------------------------------------------------------------------------------ 公司名稱: Arrow Point(Cisco): 產品: CS-100 http://www.ecrunch.com/listingview.php?listingID=59&PHPSESSID=3c21a8f95a6459132a120d4335dcf506 ------------------------------------------------------------------------------------------------------------------------------------------ 公司名稱: Cisco 產品: Local Director 400 series http://www.cisco.com/en/US/products/hw/contnetw/ps1894/index.html ------------------------------------------------------------------------------------------------------------------------------------------ 公司名稱: RADWARE 產品: APP Director (Web server director) http://www.radware.com/content/products/appdirector/default.asp ------------------------------------------------------------------------------------------------------------------------------------------ 公司名稱: Abocom(友旺) 產品: MH系列多路負載均衡器 http://www.abocom.com.cn/product.asp?xlflid=12 臺灣公司,生產家用和企業用負載均衡器, 看上去比較 業餘 ------------------------------------------------------------------------------------------------------------------------------------------ 公司名稱: Intel 產品: NetStructure(網擎) 7170 traffic director http://www.intel.com/support/netstructure/sb/cs-009599.htm ------------------------------------------------------------------------------------------------------------------------------------------ 公司名稱: Coyote Point 專門做硬件load balance的公司好稱性價比超過F5的公司 ------------------------------------------------------------------------------------------------------------------------------------------ 公司名稱: Foundry Networks 產品: ServerIron http://www.foundrynet.com/products/webswitches/serveriron/index.html ------------------------------------------------------------------------------------------------------------------------------------------ 公司名稱: HydraWeb 產品: HydraWeb Dispatcher |
可以看出,硬件設備的昂貴程度不是每個企業都可以用起的,而且實際上如果幾臺服務器,用F5之類的絕對是殺雞用牛刀(而且得用兩把牛刀),而用軟件就要合算得多,因爲服務器同時還可以跑應用,呵呵,下面來看看可以在linux平臺實現負載均衡的軟件。
2、軟件:
軟件負載均衡解決方案是指在一臺或多臺服務器相應的操作系統上安裝一個或多個附加軟件來實現負載均衡,它的優點是基於特定環境,配置簡單,使用靈活,成本低廉,可以滿足一般的負載均衡需求。
著名項目:開源軟件 最著名的是LVS.
LVS提供了兩大類負載均衡技術及其配套集羣管理軟件
★★★LVS系統結構與特點
1. Linux Virtual Server:簡稱LVS。是由中國一個Linux程序員章文嵩博士發起和領導的,基於Linux系統的服務器集羣解決方案,其實現目標是創建一個具有良好的擴展性、高可靠性、高性能和高可用性的體系。許多商業的集羣產品,比如RedHat的Piranha、 Turbo Linux公司的Turbo Cluster等,都是基於LVS的核心代碼的。
2. 體系結構:使用LVS架設的服務器集羣系統從體系結構上看是透明的,最終用戶只感覺到一個虛擬服務器。物理服務器之間可以通過高速的 LAN或分佈在各地的WAN相連。最前端是負載均衡器,它負責將各種服務請求分發給後面的物理服務器,讓整個集羣表現得像一個服務於同一IP地址的虛擬服務器。
3. LVS的三種模式工作原理和優缺點: Linux Virtual Server主要是在負載均衡器上實現的,負載均衡器是一臺加了 LVS Patch的2.2.x版內核的Linux系統。LVS Patch可以通過重新編譯內核的方法加入內核,也可以當作一個動態的模塊插入現在的內核中。
功能
有實現三種IP負載均衡技術和八種連接調度算法的IPVS軟件。在IPVS內部實現上,採用了高效的Hash函數和垃圾回收機制,能正確處理所調度報文相關的ICMP消息(有些商品化的系統反而不能)。虛擬服務的設置數目沒有限制,每個虛擬服務有自己的服務器集。它支持持久的虛擬服務(如HTTP Cookie和HTTPS等需要該功能的支持),並提供詳盡的統計數據,如連接的處理速率和報文的流量等。針對大規模拒絕服務(Deny of Service)攻擊,實現了三種防衛策略。
負載均衡器可以運行在以下三種模式下:
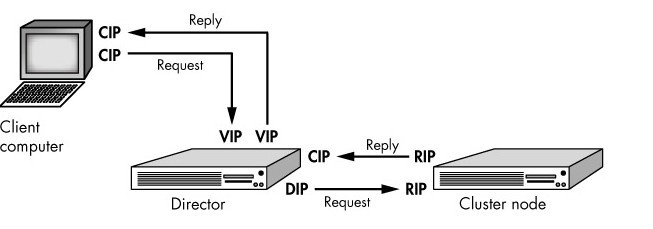
簡單說明下圖簡稱:以下CIP爲客戶端IP,VIP爲服務器向外提供服務的IP,DIP爲Director與內部服務器節點通信的IP,RIP爲內部真實服務器的IP。
(1)Virtual Server via NAT(VS-NAT):用地址翻譯實現虛擬服務器。地址轉換器有能被外界訪問到的合法IP地址,它修改來自專有網絡的流出包的地址。外界看起來包是來自地址轉換器本身,當外界包送到轉換器時,它能判斷出應該將包送到內部網的哪個節點。優點是節省IP 地址,能對內部進行僞裝;缺點是效率低,因爲返回給請求方的流量經過轉換器。
整個過程如圖所示:CIP爲客戶Client的IP,VIP爲服務器對外的IP,RIP爲內部真實服務器的IP
(2)Virtual Server via Direct Routing(VS-DR):用直接路由技術實現虛擬服務器。當參與集羣的計算機和作爲控制管理的計算機在同一個網段時可以用此法,控制管理的計算機接收到請求包時直接送到參與集羣的節點。直接路由模式比較特別,很難說和什麼方面相似,前2種模式基本上都是工作在網絡層上(三層),而直接路由模式則應該是工作在數據鏈路層上(二層)。其原理 爲,DR和REAL SERVER都使用同一個IP對外服務。但只有DR對ARP請求進行響應,所有REAL SERVER對本身這個IP的ARP請求保持靜默。也就是說,網關會把對這個服務IP的請求全部定向給DR,而DR收到數據包後根據調度算法,找出對應的 REAL SERVER,把目的MAC地址改爲REAL SERVER的MAC併發給這臺REAL SERVER。這時REAL SERVER收到這個數據包,則等於直接從客戶端收到這個數據包無異,處理後直接返回給客戶端。由於DR要對二層包頭進行改換,所以DR和REAL SERVER之間必須在一個廣播域,也可以簡單的理解爲在同一臺交換機上。
DR模式:DR模式是這樣工作的,當CIP訪問VIP後,VIP把數據包通過DIP轉交給RIP,RIP在收到數據包後通過網卡別名欺騙(節點的網卡配置別名,IP爲VIP),直接用別名的VIP相應客戶端,從而加快了迴應速度,也避免了Director成爲地址轉換的單點故障.目前主要應用的爲DR模式的負載均衡.

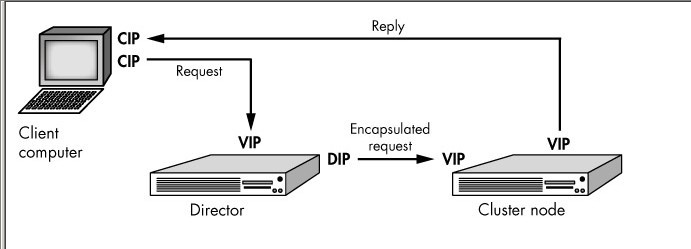
(3)Virtual Server via IP Tunneling (VS-TUN):用IP隧道技術實現虛擬服務器。這種方式是在集羣的節點不在同一個網段時可用的轉發機制,是將IP包封裝在其他網絡流量中的方法。爲了安全的考慮,應該使用隧道技術中的VPN,也可使用租用專線。 集羣所能提供的服務是基於TCP/IP的Web服務、Mail服務、News服務、DNS服務、Proxy服務器等等.
TUN模式:採用NAT技術時,由於請求和響應報文都必須經過調度器地址重寫,當客戶請求越來越多時,調度器的處理能力將成爲瓶頸。爲了解決這個問題,調度器把請求報文通過IP隧道轉發至真實服務器,而真實服務器將響應直接返回給客戶,所以調度器只處理請求報文。由於一般網絡服務應答比請求報文大許多,採用 VS/TUN技術後,集羣系統的最大吞吐量可以提高10倍。(通過重寫ip來實現,真實服務器直接回復客戶端。tun原理請參閱VPN原理!),與上圖比較,注意節點的VIP和RIP的區別.
介紹完上面3種負載均衡模式,下面來看看負載均衡調度算法.
IPVS調度器實現瞭如下八種負載調度算法
|
·1.輪叫(Round Robin) 調度器通過"輪叫"調度算法將外部請求按順序輪流分配到集羣中的真實服務器上,它均等地對待每一臺服務器,而不管服務器上實際的連接數和系統負載。 ·2.加權輪叫(Weighted Round Robin) 調度器通過"加權輪叫"調度算法根據真實服務器的不同處理能力來調度訪問請求。這樣可以保證處理能力強的服務器處理更多的訪問流量。調度器可以自動問詢真實服務器的負載情況,並動態地調整其權值。 ·3.最少鏈接(Least Connections) 調度器通過"最少連接"調度算法動態地將網絡請求調度到已建立的鏈接數最少的服務器上。如果集羣系統的真實服務器具有相近的系統性能,採用"最小連接"調度算法可以較好地均衡負載。 ·4.加權最少鏈接(Weighted Least Connections) 在集羣系統中的服務器性能差異較大的情況下,調度器採用"加權最少鏈接"調度算法優化負載均衡性能,具有較高權值的服務器將承受較大比例的活動連接負載。調度器可以自動問詢真實服務器的負載情況,並動態地調整其權值。 ·5.基於局部性的最少鏈接(Locality-Based Least Connections) "基於局部性的最少鏈接" 調度算法是針對目標IP地址的負載均衡,目前主要用於Cache集羣系統。該算法根據請求的目標IP地址找出該目標IP地址最近使用的服務器,若該服務器是可用的且沒有超載,將請求發送到該服務器;若服務器不存在,或者該服務器超載且有服務器處於一半的工作負載,則用"最少鏈接"的原則選出一個可用的服務器,將請求發送到該服務器。 ·6.帶複製的基於局部性最少鏈接(Locality-Based Least Connections with Replication) "帶複製的基於局部性最少鏈接"調度算法也是針對目標IP地址的負載均衡,目前主要用於Cache集羣系統。它與LBLC算法的不同之處是它要維護從一個目標IP地址到一組服務器的映射,而LBLC算法維護從一個目標IP地址到一臺服務器的映射。該算法根據請求的目標IP地址找出該目標IP地址對應的服務器組,按"最小連接"原則從服務器組中選出一臺服務器,若服務器沒有超載,將請求發送到該服務器,若服務器超載;則按"最小連接"原則從這個集羣中選出一臺服務器,將該服務器加入到服務器組中,將請求發送到該服務器。同時,當該服務器組有一段時間沒有被修改,將最忙的服務器從服務器組中刪除,以降低複製的程度。 ·7.目標地址散列(Destination Hashing) "目標地址散列"調度算法根據請求的目標IP地址,作爲散列鍵(Hash Key)從靜態分配的散列表找出對應的服務器,若該服務器是可用的且未超載,將請求發送到該服務器,否則返回空。 ·8.源地址散列(Source Hashing) "源地址散列"調度算法根據請求的源IP地址,作爲散列鍵(Hash Key)從靜態分配的散列表找出對應的服務器,若該服務器是可用的且未超載,將請求發送到該服務器,否則返回空。 |
IPVS的缺點
在基於IP負載調度技術中不會區分內容!所以就要求後端服務器提供相同的服務。而事實呢很多web應用總後端服務器都擔任不同的角色,比如專門存放html的、專門存放圖片的、專門存放CGI的
★★★內核Layer-7交換機KTCPVS(基於內容轉發可以提高單臺服務器cache的命中率)
KTCPVS工作流程
在基於IP負載調度技術中,當一個TCP連接的初始SYN報文到達時,調度器就選擇一臺服務器,將報文轉發給它。此後通過查發報文的IP和TCP報文頭地址,保證此連接的後繼報文被轉發到該服務器。這樣,IPVS無法檢查到請求的內容再選擇服務器,這就要求後端服務器組提供相同的服務,不管請求被髮送到哪一臺服務器,返回結果都是一樣的。但是,在有些應用中後端服務器功能不一,有的提供HTML文檔,有的提供圖片,有的提供CGI,這就需要基於內容的調度 (Content-Based Scheduling)。
由於用戶空間TCP Gateway的開銷太大
他們提出在操作系統的內核中實現Layer-7交換方法,來避免用戶空間與核心空間的切換和內存複製的開銷。在Linux操作系統的內核中,我們實現了Layer-7交換,稱之爲KTCPVS(Kernel TCP Virtual Server)。目前,KTCPVS已經能對HTTP請求進行基於內容的調度,但它還不很成熟,在其調度算法和各種協議的功能支持等方面,有大量的工作需要做。
雖然應用層交換處理複雜,它的伸縮性有限,但應用層交換帶來以下好處:
相同頁面的請求被髮送到同一服務器,可以提高單臺服務器的Cache命中率。
一些研究[5]表明WEB訪問流中存在局部性。Layer-7交換可以充分利用訪問的局部性,將相同類型的請求發送到同一臺服務器,使得每臺服務器收到的請求具有更好的相似性,可進一步提高單臺服務器的Cache命中率。
後端服務器可運行不同類型的服務,如文檔服務,圖片服務,CGI服務和數據庫服務等。
----------------------------------------------------------------------------------------------------------------------------------------------------
二、 高可用性集羣 (HA:High Availability)
高可用集羣,英文原文爲High Availability Cluster,簡稱HA Cluster,是指以減少服務中斷(如因服務器宕機等引起的服務中斷)時間爲目的的服務器集羣技術。簡單的說,集羣(cluster)就是一組計算機,它們作爲一個整體向用戶提供一組網絡資源。這些單個的計算機系統就是集羣的節點(node)。
高可用集羣的出現是爲了使集羣的整體服務儘可能可用,從而減少由計算機硬件和軟件易錯性所帶來的損失。它通過保護用戶的業務程序對外不間斷提供的服務,把因軟件/硬件/人爲造成的故障對業務的影響降低到最小程度。如果某個節點失效,它的備援節點將在幾秒鐘的時間內接管它的職責。因此,對於用戶而言,集羣永遠不會停機。高可用集羣軟件的主要作用就是實現故障檢查和業務切換的自動化。
只有兩個節點的高可用集羣又稱爲雙機熱備,即使用兩臺服務器互相備份。當一臺服務器出現故障時,可由另一臺服務器承擔服務任務,從而在不需要人工干預的情況下,自動保證系統能持續對外提供服務。雙機熱備只是高可用集羣的一種,高可用集羣系統更可以支持兩個以上的節點,提供比雙機熱備更多、更高級的功能,更能滿足用戶不斷出現的需求變化。
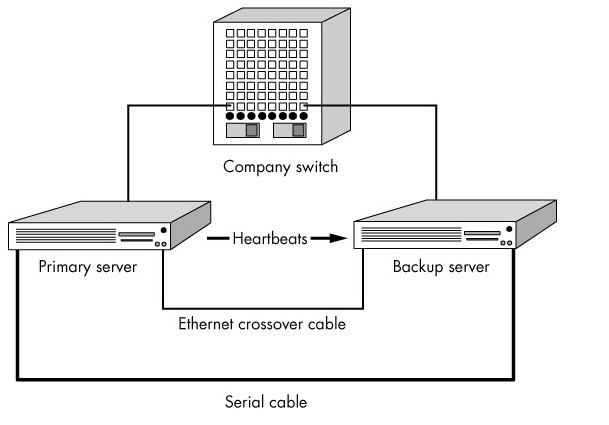
2、爲什麼要使用高可用集羣?
先來看一組數據說明:
|
可用比例
(Percent Availability) |
年停機時間
(downtime/year) |
可用性分類
|
|
99.5
|
3.7天
|
常規系統(Conventional)
|
|
99.9
|
8.8小時
|
可用系統(Available)
|
|
99.99
|
52.6分鐘
|
高可用系統(Highly Available)
|
|
99.999
|
5.3分鐘
|
Fault Resilient
|
|
99.9999
|
32秒
|
Fault Tolerant
|
|
應用系統
|
每分鐘損失(美元)
|
|
呼叫中心(Call Center)
|
27000
|
|
企業資源計劃(ERP)系統
|
13000
|
|
供應鏈管理(SCM)系統
|
11000
|
|
電子商務(eCommerce)系統
|
10000
|
|
客戶服務(Customer Service Center)系統
|
27000
|
隨着企業越來越依賴於信息技術,由於系統停機而帶來的損失也越拉越大。
高可用集羣主要是在linux平臺搭建的,在linux上實現高可用的解決方案有哪些:
| Linux平臺常見的高可用集羣 有這些:
1. 開放源代碼的 HA 項目 (http://www.linux-ha.org/)
|
筆者以最常用的heartbeat爲例介紹高可用集羣:
下圖是一個Heartbeat集羣的一般拓撲圖。在實際應用中,由於節點的數目、網絡結構和磁盤類型配置的不同,拓撲結構可能會有不同。
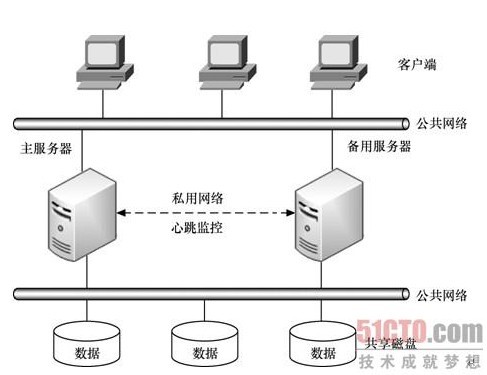
Heartbeat的組成:
Heartbeat提供了高可用集羣最基本的功能,例如,節點間的內部通信方式、集羣合作管理機制、監控工具和失效切換功能等。目前的最新版本是Heartbeat 2.x,這裏的講述也是以Heartbeat 2.x爲主。下面介紹Heartbeat 2.0的內部組成,主要分爲以下幾大部分。

heartbeat:節點間通信檢測模塊。
ha-logd:集羣事件日誌服務。
CCM(Consensus Cluster Membership):集羣成員一致性管理模塊。
LRM(Local Resource Manager):本地資源管理模塊。
Stonith Daemon:使出現問題的節點從集羣環境中脫離。
CRM(Cluster Resource Management):集羣資源管理模塊。
Cluster policy engine:集羣策略引擎。
Cluster transition engine:集羣轉移引擎。
| 從上圖中可以看出,Heartbeat內部結構由三大部分組成。
(1)集羣成員一致性管理模塊(CCM) CCM用於管理集羣節點成員,同時管理成員之間的關係和節點間資源的分配。Heartbeat模塊負責檢測主次節點的運行狀態,以決定節點是否失效。ha-logd模塊用於記錄集羣中所有模塊和服務的運行信息。 (2)本地資源管理器(LRM) LRM負責本地資源的啓動、停止和監控,一般由LRM守護進程lrmd和節點監控進程Stonith Daemon組成。lrmd守護進程負責節點間的通信;Stonith Daemon通常是一個Fence設備,主要用於監控節點狀態,當一個節點出現問題時處於正常狀態的節點會通過Fence設備將其重啓或關機以釋放IP、磁盤等資源,始終保持資源被一個節點擁有,防止資源爭用的發生。 (3)集羣資源管理模塊(CRM) CRM用於處理節點和資源之間的依賴關係,同時,管理節點對資源的使用,一般由CRM守護進程crmd、集羣策略引擎和集羣轉移引擎3個部分組成。集羣策略引擎(Cluster policy engine)具體實施這些管理和依賴;集羣轉移引擎(Cluster transition engine)監控CRM模塊的狀態,當一個節點出現故障時,負責協調另一個節點上的進程進行合理的資源接管。 在Heartbeat集羣中,最核心的是Heartbeat模塊的心跳監測部分和集羣資源管理模塊的資源接管部分。心跳監測一般由串行接口通過串口線來實現,兩個節點之間通過串口線相互發送報文來告訴對方自己當前的狀態。如果在指定的時間內未受到對方發送的報文,就認爲對方失效,這時資源接管模塊將啓動,用來接管運行在對方主機上的資源或者服務 |
---------------------------------------------------------------------------------------------------------------------------------------------------- 三.高性能集羣 (HP :High Performance )
這種集羣一般企業或者個人很少應用到, 高性能計算羣集HPC。它可以解決世界上最爲複雜和艱鉅的計算難題,並且能夠輕鬆處理。在氣象建模、模擬撞車試驗、人體基因繪圖以及核爆炸模擬等多種與人類生命相關的重要領域都要用到HPC。隨着其性能突飛猛進的提高和成本的急劇下降,HPC迅速走出科學研究實驗室,步入主流商業領域。通過將集羣和大型SMP系統的性能進行完美結合,HPC正在步入網格計算時代,它將使任何人都能隨時隨地、經濟高效地進行計算,在商業上得到更好的應用。衆多企業都被其幾乎不可抗拒特性和優勢所打動,並爭相進行部署。除政府、教育和國家實驗室等公共部門之外,HPC在製造、金融、能源、生命科學和數字媒體等行業都廣受青睞。(此類集羣應用有一定侷限性,筆者接觸不多,不做過多介紹。)
下面是一張某公司的高性能集羣組成圖:
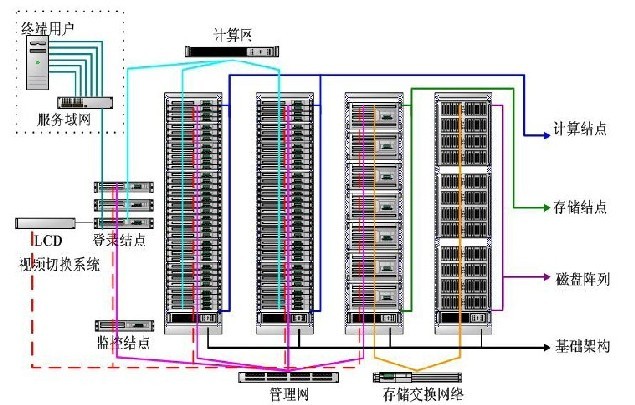
基礎架構:聚合結點、網絡以及存儲等硬件子系統的基礎設施,提供整個集羣系統的供電、散熱、佈線等功能<登錄結點:用戶登錄到集羣的工作場所,用戶通過它來完成程序的編譯調試等工作
計算結點:用於執行用戶程序的結點服務器。
存儲結點:是掛接存儲設備、向系統中的其它結點提供存儲服務的服務器。
監控結點:用來監控系統各部分的運行狀態、進行遠程電源管理和事件告警服務等工作。
存儲交換網絡:用來連接存儲結點和磁盤陣列。
計算網:計算結點在運行程序時的通信設施。由高速的通信網絡構成,如Infiniband網絡。
管理網:用於集羣系統管理的網絡,一般採用千兆以太網。
視頻切換系統:通過它可以將選定結點機的keyboard、video和mouse重定向到監控臺上,從而可以在監控臺上對結點進行各種終端的操作
集羣軟件系統結構圖:
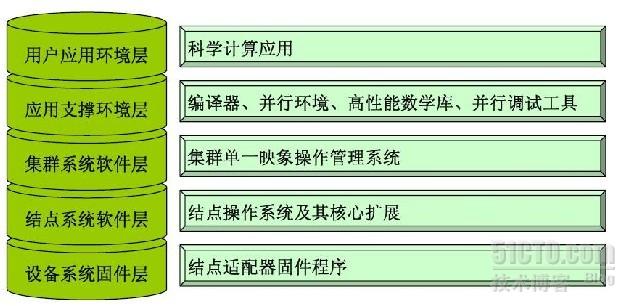
設備系統固件層:通信軟件和外部設備在適配器上的固件程序
結點系統軟件層:結點操作系統及其核心擴展,如操作系統、設備驅動程序、文件系統擴展等
集羣系統軟件層:集羣單一映象的操作管理軟件。包括集羣管理系統、集羣監控系統、作業調度系統等
應用支撐環境層:科學計算應用的支撐平臺。如並行環境、數學庫、多核線程調試工具等
應用程序層:科學工程計算類的實際應用。
高性能集羣筆者接觸不多就不過多介紹了,筆者上傳一個惠普公司的一個高性能集羣案例,在附件裏,要想深入瞭解的話可以看下。

