




先是在微博上看到了個微博和雲風的評論,然後我回了“樓主對C的內存管理不瞭解”。
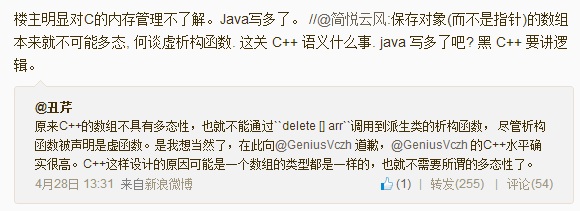
後來引發了很多人的討論,大量的人又藉機來黑C++,比如:
//@Baidu-ThursdayWang:這不就c++弱爆了的地方嗎,需要記憶太多東西
//@編程浪子張發財:這個跟C關係真不大。不過我得驗證一下,感覺真的不應該是這樣的。如果基類的析構這種情況不能 調用,就太弱了。
//@程序元:現在看來,當初由於毅力不夠而沒有深入糾纏c++語言特性的各種犄角旮旯的坑爹細枝末節,實是幸事。爲現在還沉浸於這些詭異特性並樂此不疲的同志們感到憂傷。
然後,也出現了一些亂七八糟的理解:
//@BA5BO: 數組是基於拷貝的,而多態是基於指針的,派生類賦值給基類數組只是拷貝複製了一個基類新對象,當然不需要派生類析構函數
//@編程浪子張發財:我突然理解是怎麼回事了,這種情況下數組中各元素都是等長結構體,類型必須一致,的確沒法多態。這跟C#和java不同。後兩者對於引用類型存放的是對象指針。
等等,看來我必需要寫一篇博客以正視聽了。
因爲沒有看到上下文,我就猜測討論的可能會是下面這兩種情況之一:
1) 一個Base*[]的指針數組中,存放了一堆派生類的指針,這樣,你delete [] pBase; 只是把指針數組給刪除了,並沒有刪除指針所指向的對象。這個是最基礎的C的問題。你先得for這個指針數組,把數據裏的對象都delete掉,然後再刪除數組。很明顯,這和C++沒有什麼關係。
2)第二種可能是:Base *pBase = new Derived[n] 這樣的情況。這種情況下,delete[] pBase 明顯不會調用虛析構函數(當然,這並不一定,我後面會說) ,這就是上面雲風回的微博。對此,我覺得如果是這個樣子,這個程序員完全沒有搞懂C語言中的指針和數組是怎麼一回事,也沒有搞清楚, 什麼是對象,什麼是對象的指針和引用,這完全就是C語言沒有學好。
後來,在看到了 @GeniusVczh 的原文 《如何設計一門語言(一)——什麼是坑(a)》最後時,才知道了說的是第二種情況。也就是下面的這個示例(我加了虛的析構函數這樣方便編譯):
class Base
{
public:
virtual ~B(){ cout <<"B::~B()"<<endl; }
};
class Derived : public Base
{
public:
virtual ~D() { cout <<"D::D~()"<<endl; }
};
Base* pBase = new Derived[10];
delete[] pBase;C語言補課
我先不說這段C++的程序在什麼情況下能正確調用派生類的析構函數,我還是先來說說C語言,這樣我在後面說這段代碼時你就明白了。
對於上面的:
Base* pBase = new Derived[10];這個語言和下面的有什麼不同嗎?
Derived d[10];
Base* pBase = d;一個是堆內存動態分配,一個是棧內存靜態分配。只是內存的位置和類型不一樣,在語法和使用上沒有什麼不一樣的。(如果你把Base 和 Derived想成struct,把new想成malloc() ,你還覺得這和C++有什麼關係嗎?)
那麼,你覺得pBase這個指針是指向對象的,是對象的引用,還是指向一個數組的,是數組的引用?
於是乎,你可以想像一下下面的場景:
int *pInt; char* pChar;
pInt = (int*)malloc(10*sizeof(int));
pChar = (char*)pInt;對上面的pInt和pChar指針來說,pInt[3]和pChar[3]所指向的內容是否一樣呢?當然不一樣,因爲int是4個字節,char是1個字節,步長不一樣,所以當然不一樣。
那麼再回到那個把Derived[]數組的指針轉成Base類型的指針pBase,那麼pBase[3]是否會指向正確的Derrived[3]呢?
我們來看個純C語言的例程,下面有兩個結構體,就像繼承一樣,我還別有用心地加了一個void *vptr,好像虛函數表一樣:
struct A {
void *vptr;
int i;
};
struct B{
void *vptr;
int i;
char c;
int j;
}b[2] ={
{(void*)0x01, 100, 'a', -1},
{(void*)0x02, 200, 'A', -2}
};
注意:我用的是G++編譯的,在64bits平臺上編譯的,其中的sizeof(void*)的值是8。
我們看一下棧上內存分配:
struct A *pa1 = (struct A*)(b);
用gdb我們可以看到下面的情況:(pa1[1]的成員的值完全亂掉了)
(gdb) p b
$7 = {{vptr = 0x1, i = 100, c = 97 'a', j = -1}, {vptr = 0x2, i = 200, c = 65 'A', j = -2}}
(gdb) p pa1[0]
$8 = {vptr = 0x1, i = 100}
(gdb) p pa1[1]
$9 = {vptr = 0x7fffffffffff, i = 2}
我們再來看一下堆上的情況:(我們動態了struct B [2],然後轉成struct A *,然後對其成員操作)
struct A *pa = (struct A*)malloc(2*sizeof(struct B));
struct B *pb = (struct B*)pa;
pa[0].vptr = (void*) 0x01;
pa[1].vptr = (void*) 0x02;
pa[0].i = 100;
pa[1].i = 200;
用gdb來查看一下變量,我們可以看到下面的情況:(pa沒問題,但是pb[1]的內存亂掉了)
(gdb) p pa[0]
$1 = {vptr = 0x1, i = 100}
(gdb) p pa[1]
$2 = {vptr = 0x2, i = 200}
(gdb) p pb[0]
$3 = {vptr = 0x1, i = 100, c = 0 '\000', j = 2}
(gdb) p pb[1]
$4 = {vptr = 0xc8, i = 0, c = 0 '\000', j = 0}
可見,這完全就是C語言裏亂轉型造成了內存的混亂,這和C++一點關係都沒有。而且,C++的任何一本書都說過,父類對象和子類對象的轉型會帶來嚴重的內存問題。
但是,如果在64bits平臺下,如果把我們的structB改一下,改成如下(把struct B中的int j給註釋掉):
struct A {
void *vptr;
int i;
};
struct B{
void *vptr;
int i;
char c;
//int j; <---註釋掉int j
}b[2] ={
{(void*)0x01, 100, 'a'},
{(void*)0x02, 200, 'A'}
};
你就會發現,上面的內存混亂的問題都沒有了,因爲struct A和struct B的size是一樣的:
(gdb) p sizeof(struct A) $6 = 16 (gdb) p sizeof(struct B) $7 = 16
注:如果不註釋int j,那麼sizeof(struct B)的值是24。
這就是C語言中的內存對齊,內存對齊的原因就是爲了更快的存取內存(詳見《深入理解C語言》)
如果內存對齊了,而且struct A中的成員的順序在struct B中是一樣的而且在最前面話,那麼就沒有問題。
再來看C++的程序
如果你看過我5年前寫的《C++虛函數表解析》以及《C++內存對象佈局 上篇、下篇》,你就知道C++的標準會把虛函數表的指針放在類實例的最前面,你也就知道爲什麼我別有用心地在struct A和struct B前加了一個 void *vptr。C++之所以要加在最前面就是爲了轉型後,不會找不到虛表了。
好了,到這裏,我們再來看C++,看下面的代碼:
#include
using namespace std;
class B
{
int b;
public:
virtual ~B(){ cout <<"B::~B()"<<endl; }
};
class D: public B
{
int i;
public:
virtual ~D() { cout <<"D::~D()"<<endl; }
};
int main(void)
{
cout << "sizeB:" << sizeof(B) << " sizeD:"<< sizeof(D) <<endl;
B *pb = new D[2];
delete [] pb;
return 0;
}
上面的代碼可以正確執行,包括調用子類的虛函數!因爲內存對齊了。在我的64bits的CentOS上——sizeof(B):16 ,sizeof(D):16
但是,如果你在class D中再加一個int成員的問題,這個程序就Segmentation fault了。因爲—— sizeof(B):16 ,sizeof(D):24。pb[1]的虛表找到了一個錯誤的內存上,內存亂掉了。
再注:我在Visual Studio 2010上做了一下測試,對於 struct 來說,其表現和gcc的是一樣的,但對於class的代碼來說,其可以“正確調用到虛函數”無論父類和子類有沒有一樣的size。
然而,在C++的標準中,下面這樣的用法是undefined! 你可以看看StackOverflow上的相關問題討論:《Why is it undefined behavior to delete[] an array of derived objects via a base pointer?》(同樣,你也可以看看《More Effective C++》中的條款三)
Base* pBase = new Derived[10];
delete[] pBase;所以,微軟C++編程譯器define這個事讓我非常不解,對微軟的C++編譯器再度失望,看似默默地把其編譯對了很漂亮,實則誤導了好多人把這種undefined的東西當成defined來用,還讚揚做得好,真是令人無語。(就像微博上的這個貼一樣,說VC多麼牛,還說這是OO的特性。我勒個去!)
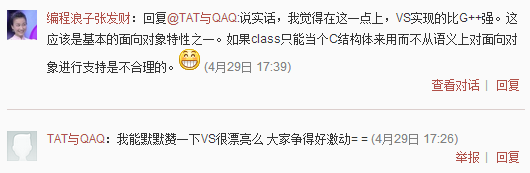
現在,你終於知道Base* pBase = new Derived[10];這個問題是C語言的轉型的問題,你也應該知道用於數組的指針是怎麼回事了吧?這是一個很奇葩的代碼!請你不要像那些人一樣在微博上和這裏的評論裏高呼並和我理論到:“微軟的C++編譯器支持這個事!”。
最後,我越來越發現,很多說C++難用的人,其實是不懂C語言。