




零 前言
0.1 不同的建模思路
之前討論的迴歸模型,如線性迴歸、Logistic等都是在x的情況下對y的估計,即對p(y|x;θ)進行建模。
爲什麼使用這樣一個條件概率?我們可以從直角座標系出發給出一個感性的理解。若有m個特徵,即xi最大下標爲m,每個特徵對應不同的一個x軸,其與相同的y軸構成了多個y-xi平面,在每個平面都有一個曲線,擬合結果是給定每個xi得到預測yi的總和。所以都是給定x,對y進行預測。y|x的實際意義是已知某個特徵進行建模。
對模型參數的優化,都是對以下似然函數求最大值

那麼之前的方法是直接求單個特徵的p(y|x;θ),然後根據累乘算出似然函數。
現在考慮通過計算p(x|y;θ)來計算似然函數。即對某個y的值,對x值進行建模。同樣也需對p(y)進行建模,然後p(x)的概率可由全概率公式求出。所以根據貝葉斯公式

可求出p(y|x)的概率。這也是這種思路建模的來源。
若對於二分問題,y∈{0,1},那麼我們對於某個特徵x,只關心不同y值p(y|x)的大小比較,將p(y|x)較大的作爲預測值,即求

因爲只與y有關係,那麼上式可寫作:

0.2 判別方法的定義
判別學習算法(discriminative learning algorithm):直接對p(y|x)建模
生成學習算法(generative learning algorithm):對p(x|y)和p(y)建模
一 高斯判別分析(Gaussian Discriminant Analysis GDA)
GDA中,對p(x|y)的假設(或是建模)是多項正態分佈。
1.1 多項正態分佈(Multivariate Normal Distribution)
n維的多項正態分佈的參數爲均值向量μ∈Rn,協方差矩陣Σ∈Rn×n,記作

其中“||”代表行列式符號。
其它資料請自行查閱
1.2 GDA的具體模型
對於二分問題,而且特徵x的取值爲連續值,根據GDA的假設,y與x|y的分佈如下

那麼p(x|y)與p(y)如下

其中參數爲φ,Σ,μ0和μ1,那麼對數似然函數如下(一般假設y=0和1時擁有相同的協方差矩陣)

對這四個參數分別求極值,可以得到
 。
。
其求法就是對要求的某個參數,固定其它參數然後求最大值,這裏給出求φ的方法示意,其他不再展示

對於這些求得的參數,其意義爲
φ是訓練樣本中結果y=1佔有的比例。
μ0是y=0的樣本中特徵均值。
μ1是y=1的樣本中特徵均值。
Σ是樣本特徵方差均值。
得到如下圖所示的分類

其中的圓圈代表等高線,此爲俯視圖,高爲預測值y。
1.3 GDA與logistic迴歸
注意到有

那麼有

其中θ爲φ,Σ,μ0和μ1的某個函數。其和logistic迴歸十分相像。
邏輯迴歸和GDA在訓練相同的數據集的時候我們得到兩種不同的決策邊界,那麼怎麼樣來進行選擇模型呢:
上面提到如果p(x|y)是一個多維的高斯分佈,那麼p(y|x)可以推出一個logistic函數;反之則不正確,p(y|x)是一個logistic函數並不能推出p(x|y)服從高斯分佈.這說明GDA比logistic迴歸做了更強的模型假設.
如果p(x|y)真的服從或者趨近於服從高斯分佈,則GDA比logistic迴歸效率高.
當訓練樣本很大時,嚴格意義上來說並沒有比GDA更好的算法(不管預測的多麼精確).
事實證明即使樣本數量很小,GDA相對logisic都是一個更好的算法.
但是,logistic迴歸做了更弱的假設,相對於不正確的模型假設,具有更好的魯棒性(robust).許多不同的假設能夠推出logistic函數的形式. 比如說,如果

二 樸素貝葉斯(Naive Bayes)
現在考慮x的取值是是離散的情況。
我們沿用對垃圾郵件進行分類的例子,我們要區分郵件是不是垃圾郵件。分類郵件是文本分類的一種應用
將一封郵件作爲輸入特徵向量,與現有的字典進行比較,如果在字典中第i個詞在郵件中出現,則xi =1,否則xi =0,所以現在我們假設輸入特徵向量如下:
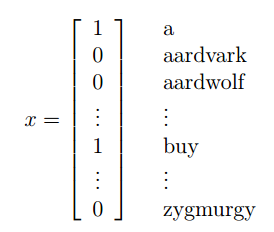
選定特徵向量後,現在要對p(x|y)進行建模:
假設字典中有50000個詞,x ∈ {0, 1}^50000 如果採用多項式建模, 將會有2^50000種結果,2^50000-1維的參數向量,這樣明顯參數過多。所以爲了對p(x|y)建模,需要做一個強假設,假設x的特徵是條件獨立的,這個假設稱爲樸素貝葉斯假設(Naive Bayes (NB) assumption),這個算法就稱爲樸素貝葉斯分類(Naive Bayes classifier).
解釋:
如果有一封垃圾郵件(y=1),在郵件中出現buy這個詞在2087這個位置它對39831這個位置是否出現price這個詞都沒有影響,也就是,我們可以這樣表達p(x_2087|y) = p(x_2087|y, x_39831),這個和x_2087 and x_39831 相互獨立不同,如果相互獨立,則可以寫爲p(x_2087) = p(x_2087|x_39831),我們這裏假設的是在給定y的情況下,x_2087 and x_39831 獨立。
那麼可以得到

解釋
第一個等號用到的是概率的性質 鏈式法則
第二個等式用到的是樸素貝葉斯假設
樸素貝葉斯假設是約束性很強的假設,一般情況下 buy和price是有關係的,這裏我們假設的是條件獨立 ,獨立和條件獨立不相同
模型參數:
φi|y=1 = p(xi= 1|y = 1)
φi|y=0 = p(xi = 1|y = 0)
φy = p(y = 1)
對於訓練集{(x(i) , y(i)); i =1, . . . , m},根據生成學習模型規則,聯合似然函數(joint likelihood)爲:
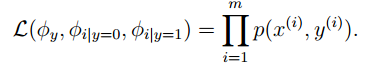
得到最大似然估計值:
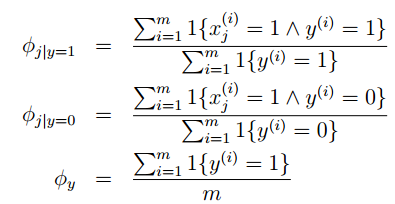
最後一個式子是表示y=1的樣本數佔全部樣本數的比例,前兩個表示在y=1或0的樣本中,特徵Xj=1的比例。
擬合好所有的參數後,如果我們現在要對一個新的樣本進行預測,特徵爲x,則有:
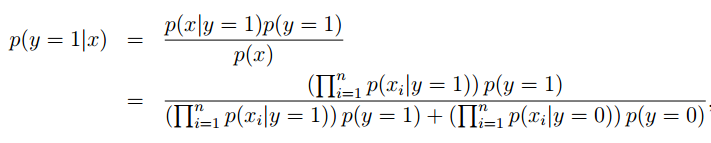
實際上只要比較分子就行了,分母對於y = 0和y = 1是一樣的,這時只要比較p(y = 0|x)與p(y = 1|x)哪個大就可以確定郵件是否是垃圾郵件
三 拉普拉斯平滑(Laplace smoothing)
樸素貝葉斯模型可以在大部分情況下工作良好。但是該模型有一個缺點:對數據稀疏問題敏感。
比如在郵件分類中,對於低年級的研究生,NIPS顯得太過於高大上,郵件中可能沒有出現過,現在新來了一個郵件"NIPS call for papers",假設NIPS這個詞在詞典中的位置爲35000,然而NIPS這個詞從來沒有在訓練數據中出現過,這是第一次出現NIPS,於是算概率時:
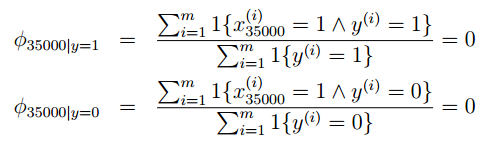
由於NIPS從未在垃圾郵件和正常郵件中出現過,所以結果只能是0了。於是最後的後驗概率:
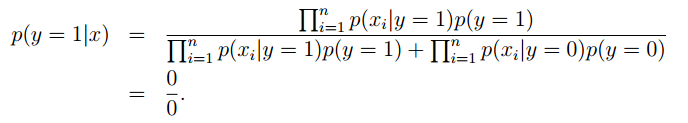
對於這樣的情況,我們可以採用拉普拉斯平滑,對於未出現的特徵,我們賦予一個小的值而不是0。具體平滑方法爲:
假設離散隨機變量取值爲{1,2,···,k},原來的估計公式爲:
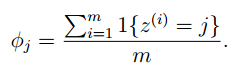
使用拉普拉斯平滑後,新的估計公式爲:
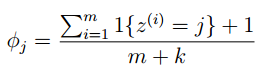
即每個k值出現次數加1,分母總的加k,類似於NLP中的平滑,具體參考宗成慶老師的《統計自然語言處理》一書。
對於上述的樸素貝葉斯模型,參數計算公式改爲:
