計算機的工作模式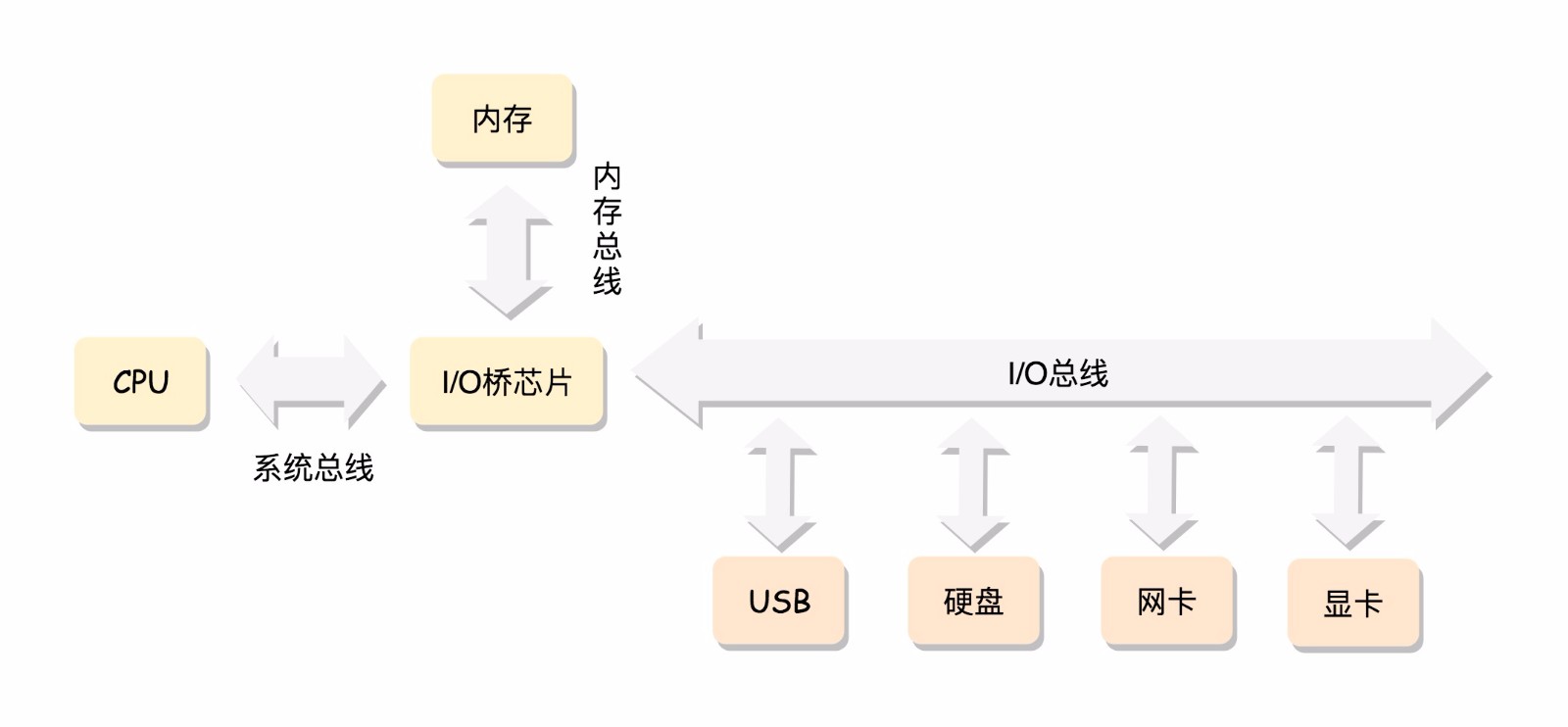
對於計算機來說,CPU(central processing Unit,中央處理器)肯定是最核心的,程序執行全都要依賴於它。
CPU和其他設備連接,要靠一種叫總線(bus)的東西,其實就是主板上密密麻麻的集成電路,這些東西組成了CPU和其他設備的高速通道。
在這些設備中,最重要的是內存(memory),因爲單靠CPU是沒法完成計算任務的,很多複雜的計算任務需要把中間結果保存下來,然後基於中間結果進行進一步計算,CPU本身是沒有辦法保存這些結果的,這就需要依賴內存了。
當然總線上也會有一些其他設備,例如顯卡會連接顯示器,磁盤控制器會連接硬盤,USB控制器會連接鼠標和鍵盤等等。
CPU和內存是完成計算任務的核心組件,CPU其實也不是單獨一塊,它包括三個部分,運算單元 ,數據單元和控制單元。
- 運算單元只管算,例如做加法,做位移等等。但是它不知道應該算哪些數據,運算結果應該放在哪裏。運算單元計算的數據如果每次都要經過總線,到內存中去現拿,這樣就太慢了,
- 所以有了數據單元。數據單元包括CPU內部的緩存和寄存器組,空間很小,但是速度飛快,可以暫時存放數據和運算結果。
- 有了放數據的地方,也有了算的地方,還需要有個指揮到底做什麼運算的地方,這就是控制單元。控制單元是一個統一的指揮中心,它可以獲得下一條指令,然後執行這條指令,這個指令會指定運算單元取出數據單元的某幾個數據,計算出結果,然後放在數據單元的某個地方。
![X86架構模式]() ‘’
‘’
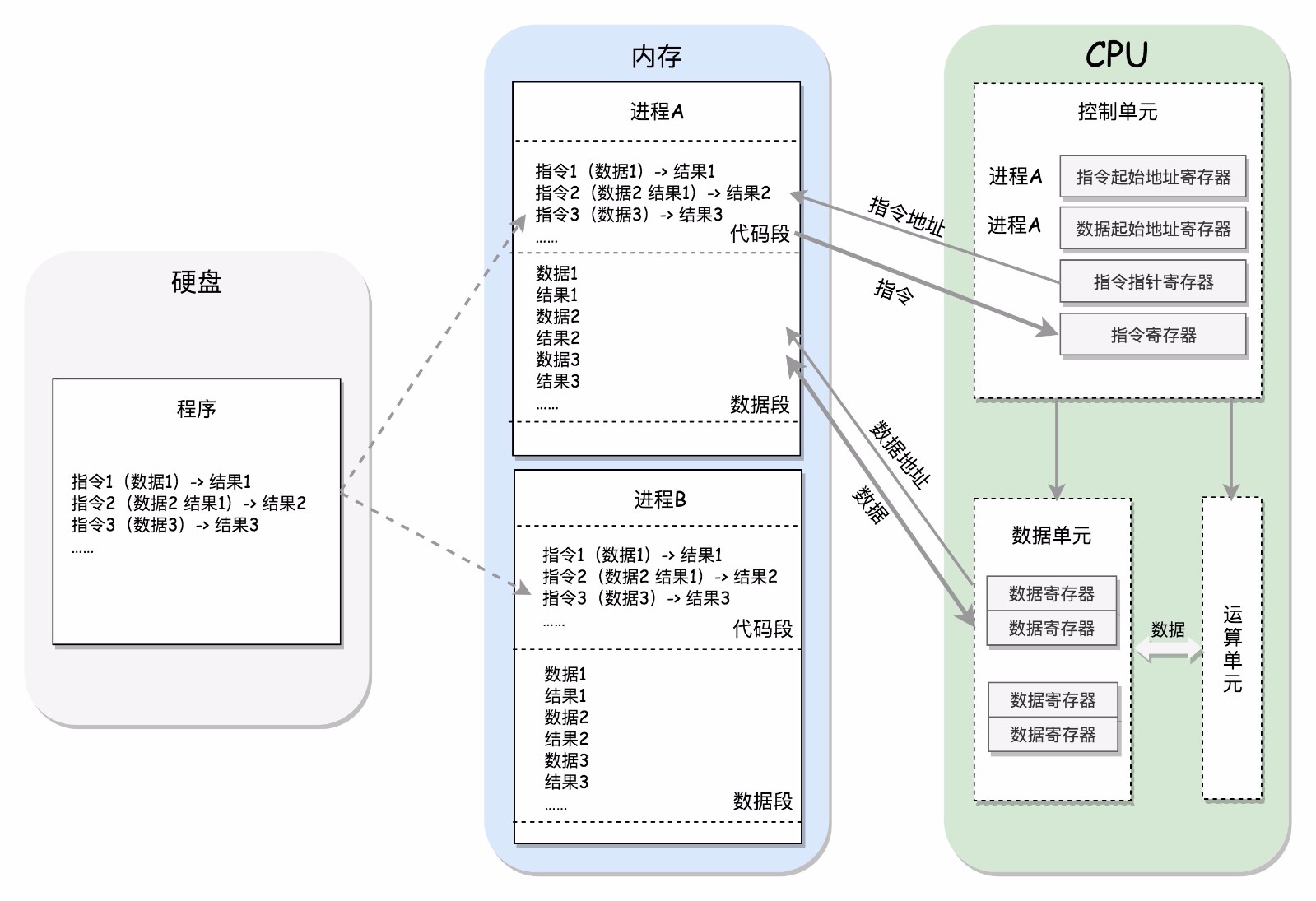 ‘’
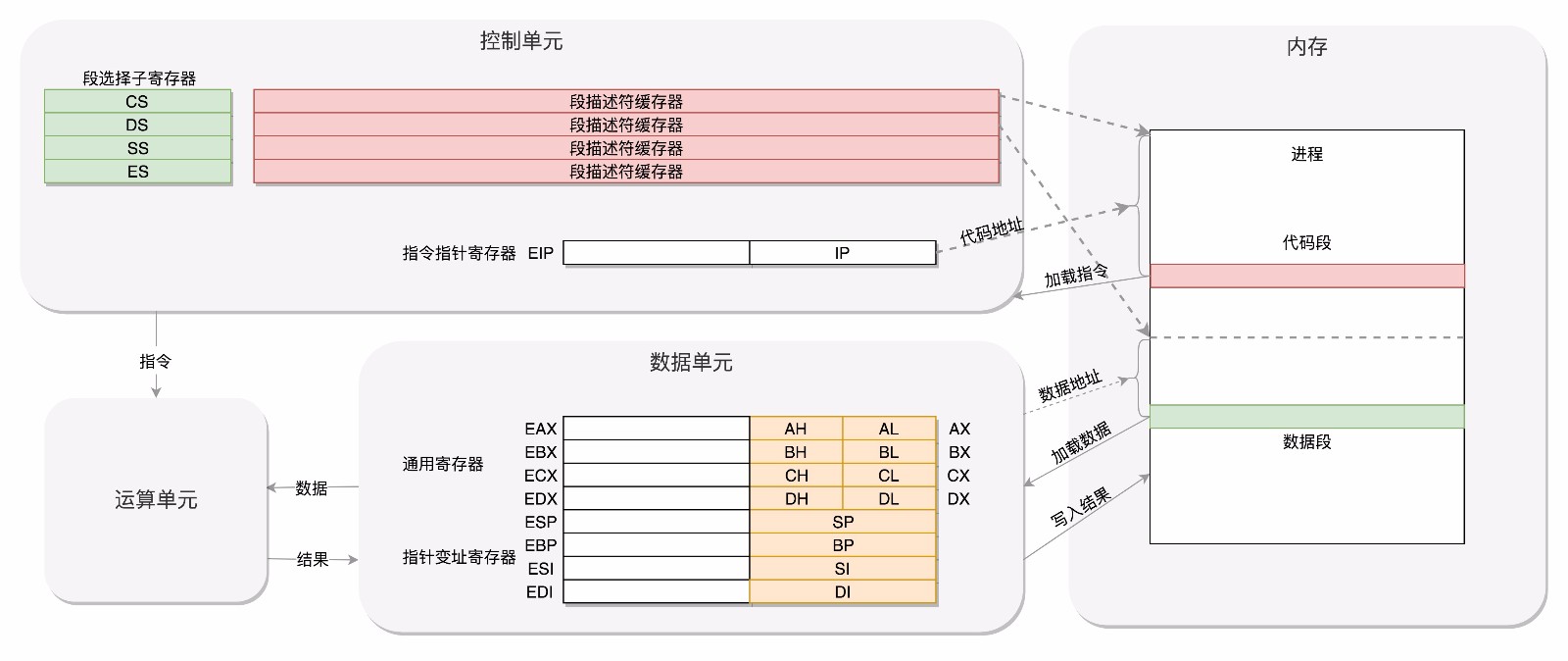
‘’CPU的控制單元中,有一個指令指針寄存器,執行的是下一條指令執行的地址,控制單元會不停的將代碼段的指令拿出來,先放進指令寄存器,當前的指令分爲倆部分,一部分是做什麼操作,是加法還是位移;一部分是操作哪些數據,要執行這些指令,就需要把就需要把第一部分交給運算單元,第二部分交給數據單元,數據單元根據數據的地址,從數據段裏讀到數據寄存器裏,就可以參與運算了。運算單元做完運算,產生的結果會暫存在數據單元的數據寄存器裏,最終會有指令將數據寫回內存中的數據段。CPU有倆個寄存器,專門保存當前處理進程的代碼段的起始地址,以及數據段的起始地址,這裏面寫的都是進程A,那當前執行的就是進程A的指令,等切換成進程B,就會執行B的指令了,這個過程叫做進程切換(process switch)。這是一個多任務系統的必備操作。
CPU和內存傳輸數據都是依靠總線,總線上主要有倆類數據,一個是地址數據,也就是我想拿內存中哪個位置的數據,這類總線叫做地址總線(Address bus);另一類是真正的數據,這類總線叫數據總線(data bus).總線有點像連接CPU和內存的高速公路,說總線到底有多少位,就類似說高速公路有幾個車道,地址總線的位數,決定了能訪問的地址範圍到底有多廣,例如只有倆位,那CPU就只能認00,01,10,11四個位置,超過這四個位置,就區分不出來了,位數越多,能夠訪問的位置就越多,能管理的內存範圍就越廣。而數據總線的位數,決定了一次能拿多少數據進來,例如只有倆位,那CPU一次只能從內存拿倆位數,要想拿八位就需要拿四次,位數越多,一次拿的數據就越多,訪問速度也就越快。
英特爾技術成爲行業的開放事實標準,這個系列開端於8086,因此稱爲X86架構,後來英特爾的數據總線和位置總線越來越寬,處理能力越來越強,但是一直不能忘記三點,一個是標準,二是開放,三是兼容。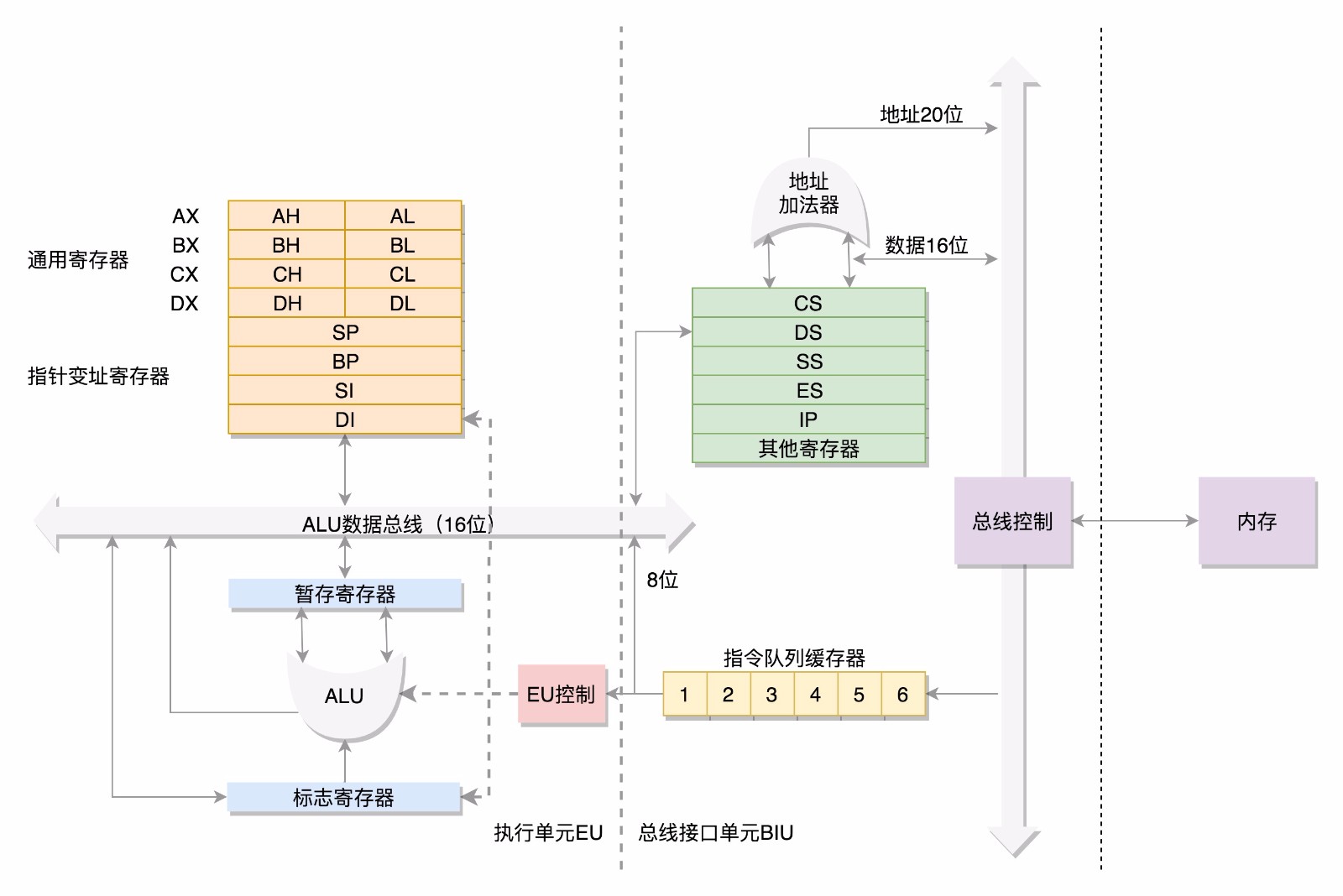
- 先來看數據單元,爲了暫存數據,8086處理器內部有8個16位的通用寄存器,也就是剛纔說的CPU內部的單元數據,分別是AX,BX,CX,DX,SP,BP,SI,DI,這些寄存器主要用於在計算過程中暫存數據。這些寄存器比較靈活,其中AX,BX,CX,DX可以分爲倆個8位的寄存器來使用,分別是AH,AL,BH,BL,CH,CL,DH,DL其中H就是High(高位),L是LOW(低位),這樣,比較長的數據也可以暫存。
- 接下來我們來看控制單元,IP寄存器就是指令指針寄存器(instruction Pointer register),指向代碼段中下一條指令的位置,CPU會根據它來不斷的將指令從內存的代碼中,加載到CPU的指令隊列中,然後交給運算單元去執行。每個進程都分代碼段和數據段,爲了指向不同進程的地址空間,有四個16位的段寄存器,分別是CS,DS,SS,ES。其中CS是代碼段寄存器(Code segment register),通過它可以找到代碼在內存中的位置。DS是數據段的寄存器,通過它可以找到數據在內存中的位置。SS是棧寄存器(Stack register)。棧是程序運行中的一個特殊的數據結構,數據的存取只能從一端進行,秉承後進先出原則,push就是入棧,pop就是出棧。凡是與函數調用相關的操作,都與棧緊密相關
如果運算中需要加載內存中的數據,需垚通過DS找到內存中的數據,加載到通用寄存器中,對於一個段,有一個起始的地址,而段內的具體位置,我們稱爲偏移量(Offset),在CS和DS中都存着一個段的起始地址。代碼段的偏移量在IP寄存器中,數據段的偏移量會放到通用寄存器中。CS和DS都是16位的,起始地址都是16位的,IP寄存器和通用寄存器也都是16位的,偏移量也是16位的,但是8086的地址總線地址是20位,方法就是起始地址16+偏移量,也就是把CS和DS中的值左移4位,變成20位,加上16位的偏移量,這樣就可以得到20位的數據地址。從這個計算方式可以算出,無論真正的內存多麼大,對於只有20位地址總現的8086來講,能夠分出的地址也就2^20=1M,超過這個空間就訪問不到了。如果你想訪問1M+X的地方,這個位置已經超出20位了,由於地址總線只有20位,在總線上超過20位的部分是發不出去的,所以發出去的還是X,最後還是會訪問1M內的X的位置。那麼一個段最大是多大,因爲偏移量只能是16位的,所以一個段最大的大小爲2^16=64K。對於8086CPU,最多隻能訪問1M的內存空間,還要分成多個段,每個段最多64k,不過在當時已經足夠使用了。
- 32位處理器
在32位處理器中有32根地址總線,可以訪問2^32=4G的內存。既然是開放的就需要保持兼容,首先,通用寄存器有擴展,可以將8個16位的擴展到8個32位的,但是依然可以保留16位的和8位的使用方式,其中指向下一條指令的指令指針寄存器IP,就會擴展成32位的,同樣也兼容16位的。
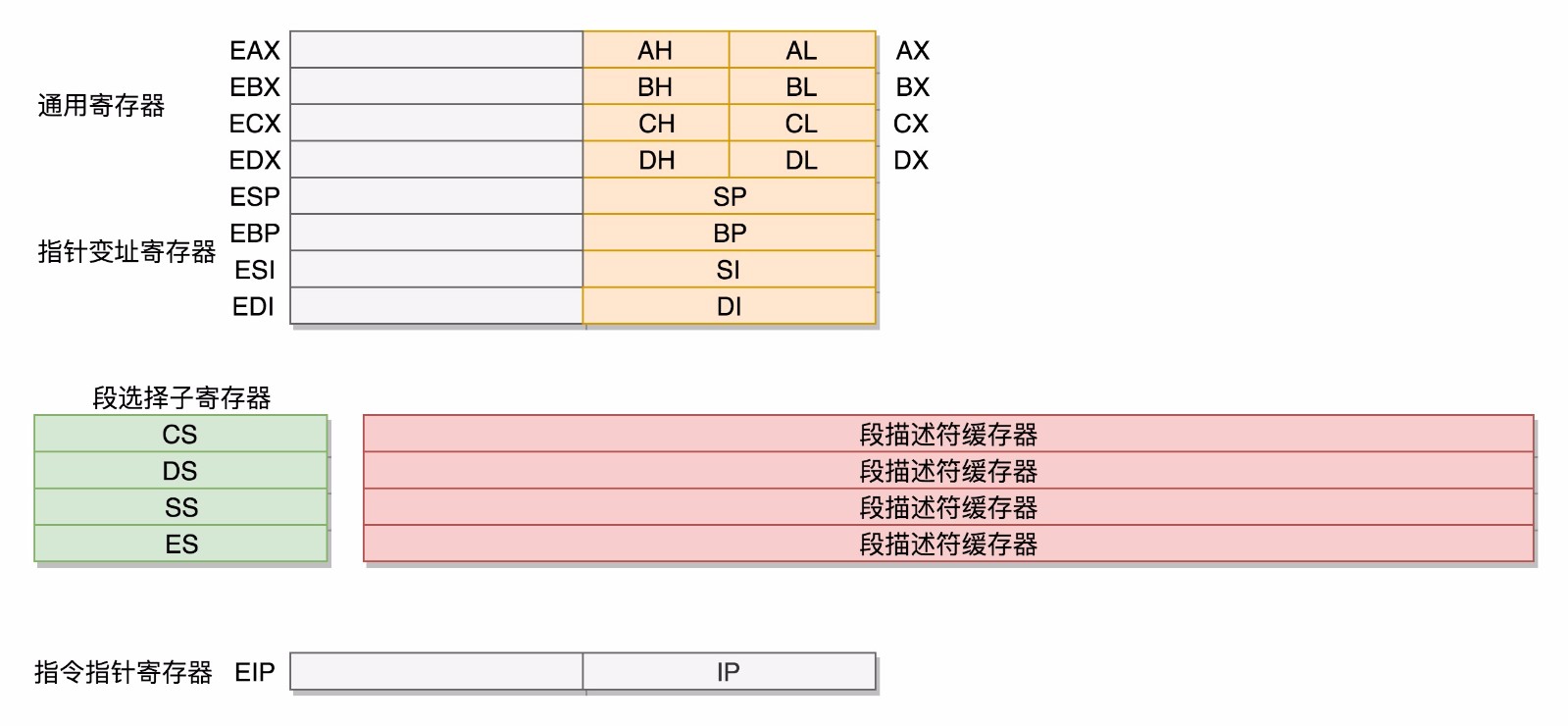
而改動比較大,有點不兼容的就是段寄存器(segment register),因爲原來的模式其實有一點不倫不類,因爲他沒有把16位當成一個段的起始位置,也沒有按8位或者16位擴展的形式,而是根據當時的硬件,弄了一個不上不下的20位的地址,這樣每次都要左移4位,也就意味着段的起始位置不能是任何一個地方,只是能整除16的地方。那麼我們索性重新定義,CS,SS,DS,ES仍然是16位的,但是不再是段的起始地址,段的起始地址放在內存的某個地方,這個地方是一個表格,表格的一項一項是段描述符(segment descriptor),這裏面纔是段的真正起始地址,而段寄存器保存的是在這個表格的哪一項,稱爲選擇子(selector),這樣,將一個段寄存器直接拿到的段起始地址,就變成了先間接地從段寄存器找到表格中的一項,再從表格的一項中拿到段起始地址。這樣段起始地址就會很靈活,爲了快速拿到段起始地址,段寄存器會從內存中拿到CPU的描述符高速緩存器中。這樣就會不兼容,好在後面這種模式靈活度非常高,可以保持將來一直兼容下去,前面的模式出現的時候,沒想到自己能夠成爲一個標準,所以設計就沒有這麼靈活,因而到了32位的系統架構下,我們將前一種模式稱爲實模式(Real Pattern),後一種模式稱爲保護模式(Protected Pattern).當系統剛啓動的時候,CPU是處於實模式的,這個時候和原來的模式是兼容的,當需要更多內存的時候,你可以遵循一定的規則,進行一系列的操作,然後切換到保護模式,就能用到32位CPU更強大的能力。也就是說,不能無縫兼容,但是通過切換模式兼容,也是可以接受的。