




CCA典型相關分析
(canonical correlation analysis)利用綜合變量對之間的相關關係來反映兩組指標之間的整體相關性的多元統計分析方法。它的基本原理是:爲了從總體上把握兩組指標之間的相關關係,分別在兩組變量中提取有代表性的兩個綜合變量U1和V1(分別爲兩個變量組中各變量的線性組合),利用這兩個綜合變量之間的相關關係來反映兩組指標之間的整體相關性。
Canonical Correlation Analysis典範相關分析/Canonical Correspondence Analysis典範對應分析
簡單相關係數描述兩組變量的相關關係的缺點:只是孤立考慮單個X與單個Y間的相關,沒有考慮X、Y變量組內部各變量間的相關。兩組間有許多簡單相關係數,使問題顯得複雜,難以從整體描述。典型相關是簡單相關、多重相關的推廣。典型相關是研究兩組變量之間相關性的一種統計分析方法。也是一種降維技術。
1936年,Hotelling提出典型相關分析。考慮兩組變量的線性組合, 並研究它們之間的相關係數p(u,v).在所有的線性組合中, 找一對相關係數最大的線性組合, 用這個組合的單相關係數來表示兩組變量的相關性, 叫做兩組變量的典型相關係數, 而這兩個線性組合叫做一對典型變量。在兩組多變量的情形下, 需要用若干對典型變量才能完全反映出它們之間的相關性。下一步, 再在兩組變量的與u1,v1不相關的線性組合中, 找一對相關係數最大的線性組合, 它就是第二對典型變量, 而且p(u2,v2)就是第二個典型相關係數。這樣下去, 可以得到若干對典型變量, 從而提取出兩組變量間的全部信息。
典型相關分析的實質就是在兩組隨機變量中選取若干個有代表性的綜合指標(變量的線性組合), 用這些指標的相關關係來表示原來的兩組變量的相關關係。這在兩組變量的相關性分析中, 可以起到合理的簡化變量的作用; 當典型相關係數足夠大時, 可以像迴歸分析那樣, 由- 組變量的數值預測另一組變量的線性組合的數值。
典型關聯分析(Canonical Correlation Analysis)
在線性迴歸中,我們使用直線來擬合樣本點,尋找n維特徵向量X和輸出結果(或者叫做label)Y之間的線性關係。其中,

當然我們仍然可以使用迴歸的方法來分析,做法如下:
假設,
,那麼可以建立等式Y=AX如下
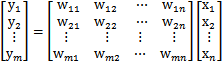
其中,形式和線性迴歸一樣,需要訓練m次得到m個
。
這樣做的一個缺點是,Y中的每個特徵都與X的所有特徵關聯,Y中的特徵之間沒有什麼聯繫。
我們想換一種思路來看這個問題,如果將X和Y都看成整體,考察這兩個整體之間的關係。我們將整體表示成X和Y各自特徵間的線性組合,也就是考察和
之間的關係。
這樣的應用其實很多,舉個簡單的例子。我們想考察一個人解題能力X(解題速度,解題正確率
)與他/她的閱讀能力Y(閱讀速度
,理解程度
)之間的關係,那麼形式化爲:
和
然後使用Pearson相關係數
來度量u和v的關係,我們期望尋求一組最優的解a和b,使得Corr(u, v)最大,這樣得到的a和b就是使得u和v就有最大關聯的權重。
到這裏,基本上介紹了典型相關分析的目的。
給定兩組向量和
(替換之前的x爲
,y爲
),
維度爲
,
維度爲
,默認
。形式化表示如下:
是x的協方差矩陣;左上角是
自己的協方差矩陣;右上角是
;左下角是
,也是
的轉置;右下角是
的協方差矩陣。
與之前一樣,我們從和
的整體入手,定義
我們可以算出u和v的方差和協方差:
上面的結果其實很好算,推導一下第一個吧:
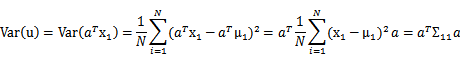
最後,我們需要算Corr(u,v)了

我們期望Corr(u,v)越大越好,關於Pearson相關係數,《數據挖掘導論》給出了一個很好的圖來說明:

橫軸是u,縱軸是v,這裏我們期望通過調整a和b使得u和v的關係越像最後一個圖越好。其實第一個圖和最後一個圖有聯繫的,我們可以調整a和b的符號,使得從第一個圖變爲最後一個。
接下來我們求解a和b。
回想在LDA中,也得到了類似Corr(u,v)的公式,我們在求解時固定了分母,來求分子(避免a和b同時擴大n倍仍然符號解條件的情況出現)。這裏我們同樣這麼做。
這個優化問題的條件是:
|
Maximize Subject to: |
求解方法是構造Lagrangian等式,這裏我簡單推導如下:
求導,得
令導數爲0後,得到方程組:
第一個等式左乘,第二個左乘
,再根據
,得到
也就是說求出的即是Corr(u,v),只需找最大
即可。
讓我們把上面的方程組進一步簡化,並寫成矩陣形式,得到
寫成矩陣形式
令
那麼上式可以寫作:
顯然,又回到了求特徵值的老路上了,只要求得的最大特徵值
,那麼Corr(u,v)和a和b都可以求出。
在上面的推導過程中,我們假設了和
均可逆。一般情況下都是可逆的,只有存在特徵間線性相關時會出現不可逆的情況,在本文最後會提到不可逆的處理辦法。
再次審視一下,如果直接去計算的特徵值,複雜度有點高。我們將第二個式子代入第一個,得
這樣先對求特徵值
和特徵向量
,然後根據第二個式子求得b。
待會舉個例子說明求解過程。
假設按照上述過程,得到了最大時的
和
。那麼
和
稱爲典型變量(canonical variates),
即是u和v的相關係數。
最後,我們得到u和v的等式爲:
我們也可以接着去尋找第二組典型變量對,其最優化條件是
|
Maximize Subject to: |
其實第二組約束條件就是。
計算步驟同第一組計算方法,只不過是取
的第二大特徵值。
得到的和
其實也滿足
即
總結一下,i和j分別表示和
得到結果
我們回到之前的評價一個人解題和其閱讀能力的關係的例子。假設我們通過對樣本計算協方差矩陣得到如下結果:

然後求,得
這裏的A和前面的中的A不是一回事(這裏符號有點亂,不好意思)。
然後對A求特徵值和特徵向量,得到
然後求b,之前我們說的方法是根據求b,這裏,我們也可以採用類似求a的方法來求b。
回想之前的等式
我們將上面的式子代入下面的,得
然後直接對求特徵向量即可,注意
和
的特徵值相同,這個可以自己證明下。
不管使用哪種方法,
這裏我們得到a和b的兩組向量,到這還沒完,我們需要讓它們滿足之前的約束條件
這裏的應該是我們之前得到的VecA中的列向量的m倍,我們只需要求得m,然後將VecA中的列向量乘以m即可。
這裏的是VecA的列向量。
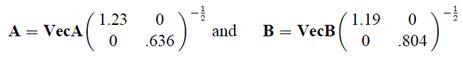
因此最後的a和b爲:

第一組典型變量爲
相關係數
第二組典型變量爲
相關係數
這裏的(解題速度),
(解題正確率),
(閱讀速度),
(閱讀理解程度)。他們前面的係數意思不是特徵對單個u或v的貢獻比重,而是從u和v整體關係看,當兩者關係最密切時,特徵計算時的權重。

