




前言:矩陣論是對線性代數的延伸,很有必要深入研究。矩陣與泛函數分析和凸優化存在着密不可分的關係,尤其是內積空間部分。研究矩陣論可以加深對PCA,SVD,矩陣分解的理解,尤其是第一章入門的線性空間的理解,在知識圖譜向量化,self_attention等論文中會涉及大量的矩陣論的知識。本系列博客對此做一個學習心得總結,省略掉矩陣的微分方程等運算部分,重點論述和AI相關尤其是與結構化約束和無向圖推理相關的部分。學習一本書的最好方法是看兩遍以上,第一遍按順序學習,第二遍倒着看一遍。比如《矩陣論》的最後一章節關於特殊矩陣的論述,第二遍可以以這個爲出發點,重新思考前面的論述,相信會提升很多。從特殊到一般的歸納總結是人類研究自然世界規律的基本方法。關於圖模型和深度學習的融合,可以看看DeepMind和谷歌大腦的論文。圖模型推理這篇博客地址:https://blog.csdn.net/randy_01/article/details/81743882 聯結主義和符號主義的融合是個大難題,但是需要對兩個學派有很深入的理解,最起碼數學基礎應該過硬。目前AI研究的熱點大致包括兩部分:①Auto ML,包括遺傳算法優化神經網絡參數等等②邏輯推理,以知識圖譜爲基礎的研究,包括專家規則系統,cvt節點的圖譜,kb_qa,神經規則推理。其中優化損失函數是一個重要的研究方向,比如1996年的lasso論文養活了一大批後來的學者。成爲研究機器學習專家必須精進以下數學:《矩陣論》+《實變函數與泛函數分析》+《凸優化》+《統計學》,泛函數分析在AI中屬於較高級的應用了。建議學習這些學科最好用國外的教材。花費2年左右的時間精研這些數學著作是有必要的,否則會一直停留在應用層面,很被動!有了數學工具,再結合物理學,神經生物學,計算機等學科開展AI研究,將會順利一些。有人可能不太知道物理學和Ai研究有什麼關係,本人認爲AI和物理存在着一定的相關性,都是揭示和發現自然世界的規則。AI的研究一定靠規則,尤其是推理。借鑑物理學AI可以更好地發展。目前國內高校的基礎研究需要下更大的力度,西湖大學邁出了第一步。目前國內衆多高校開設的所謂Ai專業其實是爲國家增加人口紅利而已,都停留在應用層面,尤其是碩士。後續的博客將會增加物理學和神經生物學基礎知識,再後面將介紹AI基礎研究的進展,比如膠囊網絡提出的原因,神經網絡的缺陷,推理的進展,本體論這些。隨着研究的深入,本人相信最後一定會進入知識圖譜的領域,因爲當下只有知識圖譜才能真正解決AI的難題。本着一以貫之的原則,本系列文章分成兩篇博客論述,並且會對原著進行擴展然後探索在AI中的應用。本系列博客按照以下篇幅展開論述,並且會結合《凸優化》,因爲矩陣和《凸優化》緊密相關:
上篇:基礎部分
第一部分:矩陣的線性空間,矩陣的意義;
第二部分:矩陣的特徵值分解,特徵多項式以及矩陣多項式;
第三部分:歐式空間的內積與度量矩陣;
第四部分:矩陣的範數理解與AI應用;
第五部分:矩陣的正交分解理論以及PCA,SVD;
下篇:探索研究與應用,重點在圖模型推理部分(圖模型和神經網絡融合)
第六部分:矩陣的投影理論;
第七部分:矩陣與AI:
1、矩陣的方法論研究(切入點爲特殊矩陣的研究,從特殊到一般的歸納總結是人類研究自然世界的基本規律);
2、①最小二乘法②對稱正定矩陣,矩陣不等式和分類超平面③損失函數的結構化約束④重要的矩陣:拉普拉斯矩陣⑤PageRank⑥無向圖的卷積算子(譜卷積算子,相對於圖卷積算子)⑦圖模型推理.
第5~8部分安排在下篇博客中,這部分既是實際應用又是對第一部分的深化,比如對損失函數結構化約束的深入研究,圖模型與聯結主義融合的研究等:
第二篇博客地址:https://blog.csdn.net/randy_01/article/details/86618044
在進入正題之前,有必要把《線性代數》裏面重要的知識提煉出來:
一、.對稱矩陣:①![]() ②
②![]() 特徵值分解後的特徵向量係爲標準正交特徵向量系
特徵值分解後的特徵向量係爲標準正交特徵向量系
二、可逆矩陣:①![]() ②
②![]() 經過行初等變換後可以化簡爲E。又稱爲滿秩矩陣,非奇異矩陣。
經過行初等變換後可以化簡爲E。又稱爲滿秩矩陣,非奇異矩陣。
三、正交矩陣:


正交矩陣對一個向量變換成爲正交變換,變換後的向量模不變。經典的二次型可以化簡爲標準二次型,就是對原變量進行正交變換。
四、向量的座標表示:

這部分和《傅立葉變換》中傅立葉級數的結果一致,只不過一個是向量空間,一個是函數空間。
柯西—施瓦茨不等式的證明:構造函數,常量變化量

有5個不等式很重要,涵蓋了統計學,線性代數以及泛函數分析:①柯西-施瓦茨不等式②Jesen不等式③赫爾德不等式④馬爾可夫不等式⑤切比雪夫不等式。在赫爾德不等式中,p=q=2時它就是柯西-施瓦茨不等式的上界。在證明指數和的對數函數是凸函數時用到了柯西不等式。

五、矩陣相似性:這部分以特徵值分解爲基礎,精華是方陣A(可逆)與它的特徵值對角陣相似的充要條件是A分解後的特徵向量係爲n個線性無關的向量組。
六、矩陣的秩:①經過初等變換後非0行或者列的個數取最小數②線性無關的列(行)向量個數③分解後特徵值非0的個數。
七、方程Ax=b的解x是凸集,證明如下:

這個方程的解有三種情況:

在實際工程中錯在大量的奇異矩陣,這些矩陣的逆矩陣是廣義逆矩陣。僞逆指的是矩陣經過svd後取逆運算。
八、線性無關的幾何解釋:矩陣和《凸優化》緊密相關,學不精《凸優化》,對矩陣的理解相當於停留在初級階段,AI理論研究 也不會深入。線性無關的向量組其實就是這些向量不管如何組合,永遠不共面,各自線性獨立,比如《凸優化》中下面的這個四面體:

v1-v0,v2-v0,v3-v0這三條邊各自線性獨立,是線性無關的。但是再加上v4-v0的話就不是線性無關的向量組了,因爲v4-v0與前三個向量求和後所在的平面共面。
單純形的定義是由仿射集展開的,它是多面體的特殊形式。
上篇:基礎精進
1.線性空間,矩陣的意義
1.1 線性變換
這部分內容是理解矩陣的基礎也是最關鍵的部分。對於線性空間的基本概念不必多解釋,都說矩陣的本質是線性變換,這裏有必要總結一下。一般而言,矩陣乘以向量後結果仍然是向量,相當於對向量進行了變換。這個過程可以用《實變函數與泛函數分析》很好地解釋。矩陣的變換相當於有界線性算子,從函數空間到函數空間的轉換。矩陣是一種映射,輸入即定義域是空間中的點(函數),輸出也是函數空間。那麼矩陣的值域是什麼?
某個空間中所有向量經過變換矩陣後形成的向量的集合,通常用R(A)來表示。設A是m*n的矩陣,稱其列向量構成的子空間爲A的值域空間,R(A),即任意n*1維的向量x,有Ax=b,b是A值域空間中的一個元素,所有的b構成了A的值域空間。A的零空間由所有滿足方程Ax=0的x構成,N(A)。
假設你是一個向量,有一個矩陣要來變換你,這個矩陣的值域表示了你將來所有可能的位置。值域的維度也叫做秩(Rank)。值域所在的空間定義爲W空間。
矩陣的變換包括方向和幅度,方向指的是座標軸,幅度一般值向量的特徵值。舉一個最直觀的例子:
比如說下面的一個矩陣: 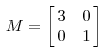
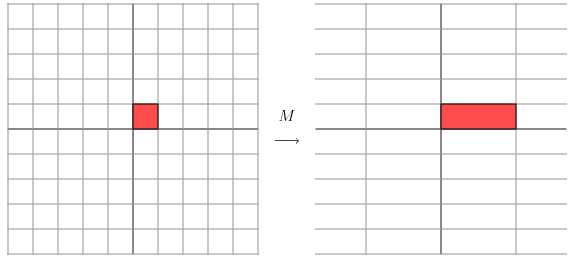
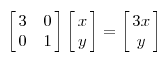


下面從最專業的矩陣論理論,具體解釋矩陣的本質。前面的變換其實是對向量的左邊進行拉伸或者旋轉,所以先介紹一下在矩陣論中座標軸,座標系和座標的概念。
對於線性空間Vn ,空間的基e1,e2,……是一組非線性相關向量,就是這些向量組成的行列式不爲0。空間中的任一向量都可以寫成這些基的線性組合,這些組合係數稱之爲向量的座標。空間的基對應空間的座標系,座標是對應在座標系中的。那麼一個變換矩陣應該如何理解呢?現有空間裏的一個向量x,Tx爲向量的象,也就是經過變換後的向量。現推導如下:

補充:




證畢!
1.2 矩陣的正定性判斷
1.21 定義
首先半正定矩陣定義爲: 其中X 是向量,M 是變換矩陣
我們換一個思路看這個問題,矩陣變換中,MX代表對向量 X進行變換,我們假設變換後的向量爲Y,記做Y = MX。於是半正定矩陣可以寫成:這個是不是很熟悉呢? 他是兩個向量的內積。同時我們也有公式:
||X||,||Y||代表向量 X,Y的長度,是他們之間的夾角。 於是半正定矩陣意味着
, 這下明白了麼?正定、半正定矩陣的直覺代表一個向量經過它的變化後的向量與其本身的夾角小於等於90度。
下面從上面推導的過程來理解,考慮矩陣的特徵值:若所有特徵值均不小於零,則稱爲半正定。若所有特徵值均大於零,則稱爲正定。
矩陣經過特徵值分解後的特徵值是一個對角陣,就是原空間某一個基在變換後的空間的長度變化係數,大於0表示方向一致,小於0表示方向相反,每個向量都會經過變換矩陣A的每列係數組合變換,而A經過分解後分爲特徵值和座標軸兩部分,每個特徵值表明了基的自身變換方向與幅度,>0表明同向變換。如果每個特徵值都>0的話,由於向量是由空間的基線性組合而成最終導致變換後的向量與原向量同向變化。
1.22 半正定矩陣的凸集
1.221 半正定矩陣是凸集,更準確地說是凸椎,請看如下定義:



半正定矩陣的約束條件:①主對角線元素>=0,由矩陣的特徵值分解的行列式可以證明②行列式>=0,因爲特徵值全部>=0,由任意n階矩陣與以特徵值爲主對角線元素的上三角矩陣相似定理可以得出行列式>=0,證畢!
1.222 半正定矩陣應用舉例
最有說服力的例子莫過於凸函數的二階條件判斷。

![]()
二階導數形成如下的半正定矩陣:

大衆所熟悉的最小二乘法損失函數公式的二階導函數就是矩陣P:

這個公式表示的是中心不在原點的橢球。
2.矩陣的特徵值分解以及特徵多項式和矩陣多項式
矩陣的特徵值分解《線性代數》中就有論述,這裏重點論述特徵多項式以及矩陣多項式。
2.1 特徵多項式

上述多項式方程也可以表述爲:![]() ,展開後可以知道,
,展開後可以知道,![]() 和
和![]() 的係數分別爲:
的係數分別爲:
![]() 和
和![]()
![]() 。於是我們可以推導出
。於是我們可以推導出![]() 。引入記號trA =
。引入記號trA = ![]() ,它是矩陣的跡。上面的公式表明:矩陣A的所有特徵值的和等於矩陣的跡,所有特徵值的乘積等於detA。
,它是矩陣的跡。上面的公式表明:矩陣A的所有特徵值的和等於矩陣的跡,所有特徵值的乘積等於detA。
矩陣的特徵值分解在《凸優化》中有很重要的應用:
1.![]()
2.
![]()

![]()


2.2 矩陣的相似性定理

在《線性代數》中關於矩陣的相似性論述主要集中在矩陣和對角矩陣的相似性。根據定義1.15就可以知道,p爲矩陣A的n個線性無關的特徵向量系,B爲由A的特徵值組成的對角陣。再進一步,如果A是n階對稱矩陣,那麼p就是標準正交特徵向量系。在《矩陣論》中論述更一般的情況:p的組成不全是特徵向量系,比如p中可以有一列是特徵向量,其餘的不是,那麼情況是什麼呢?論述這樣的一般性主要是引出《矩陣論》中最重要的定理:哈密特-凱萊定理(Hamilton-Cayley)。爲了證明這個定理,首先引入下面的定理:





爲了更進一步消化這個定理,先舉個例子:


![]()

下面引入哈密特-凱萊定理:





從上面的證明過程可以看出,研究矩陣的相似性有多麼的重要,爲了更進一步研究矩陣的相似性,再來一個例子:設冪級數
![]() 的收斂半徑爲r,如果方陣A滿足
的收斂半徑爲r,如果方陣A滿足![]() ,則矩陣冪級數
,則矩陣冪級數![]() 是絕對收斂的,如果
是絕對收斂的,如果![]() ,則矩陣冪級數是發散的。
,則矩陣冪級數是發散的。
分析:在《傅立葉變換》的博客中已經詳細講解了冪級數分解。由![]() 證明矩陣冪級數絕對收斂 ,只需證明矩陣冪級數的範數收斂即可,即
證明矩陣冪級數絕對收斂 ,只需證明矩陣冪級數的範數收斂即可,即![]() 收斂。 只需證明||A||<r即可,忽略。發散的證明,如果變量的冪級數的每一項都>r,則發散。已知條件譜半徑>r,則可以得到對角陣的特徵值冪級數是發散的。也就是說只要證明A的特徵值冪級數是發散的就可以了。於是我們想到了他的相似三角陣。由於譜半徑>r,所以任一特徵值均>r,所以特徵值冪級數發散,也就是A的相似矩陣冪級數發散,所以A的冪級數發散。證畢!
收斂。 只需證明||A||<r即可,忽略。發散的證明,如果變量的冪級數的每一項都>r,則發散。已知條件譜半徑>r,則可以得到對角陣的特徵值冪級數是發散的。也就是說只要證明A的特徵值冪級數是發散的就可以了。於是我們想到了他的相似三角陣。由於譜半徑>r,所以任一特徵值均>r,所以特徵值冪級數發散,也就是A的相似矩陣冪級數發散,所以A的冪級數發散。證畢!
哈密特-凱萊定理有很多推廣和應用,比如:




下面舉個例子:

![]()


3.歐式空間的內積與度量矩陣
歐式空間屬於特殊的線性空間,在《實變函數與泛函數分析》的第六章裏介紹了Hilbert內積空間。函數可以看作是無限維度的空間向量,比如指數函數的冪級數分解後得到的多項式組合,每個項都可以看作是指數函數的基。所以指數函數(向量)是關於基的線性組合。包括正交三角函數系,也是三角函數的基。重點看一下內積的三個性質:
內積的定義:


內積的性質:

關於性質3,可以進一步展開:有兩個向量X和Y分別關於基x和y線性組合,其中X = ![]() ,Y =
,Y = ![]() ,則按照性質3的展開式進一步得到如下:
,則按照性質3的展開式進一步得到如下:


以上公式表明,只要知道了線性空間中基的矩陣A,就可以得出兩個向量的內積。矩陣A成爲度量矩陣,可以看出,度量矩陣是對稱陣和非奇異矩陣。由於他的對角線上的值全部>0,因此它又是正定矩陣。
度量矩陣的涵義:度量矩陣完全確定了內積,於是可以用任意正定矩陣作爲度量矩陣來規定內積。向量所有可度量的量都可以用內積來刻畫。

初中數學中,向量的夾角規定爲![]() ,是由余弦定理推導出來的。 由於餘弦值<=1,所以我們可以得出:
,是由余弦定理推導出來的。 由於餘弦值<=1,所以我們可以得出:
![]() 或者
或者![]() 。
。
4.矩陣的範數
4.1向量範數
注意:在《矩陣論》中的範數嚴格意義上是《實變函數與泛函數分析》中的"半範數",滿足以下3個性質的範數就是半範數。

在本人的博客《實變函數與泛函數分析學習筆記(二):賦範線性空間》https://blog.csdn.net/randy_01/article/details/82851511
中有詳解介紹。矩陣屬於線性代數範疇,幾何和代數可以是統一的。下面介紹向量的1階,2階和無窮階範數。
無窮階範數:
![]()
它是![]() 上的
上的![]() -範數。證明過程很簡單,省略掉。這個範數可以擴展到函數,函數可以看作是無限維度的向量,作兩個實線性空間的函數,取差值,然後再取差值中的最大值就是無窮階範數了。
-範數。證明過程很簡單,省略掉。這個範數可以擴展到函數,函數可以看作是無限維度的向量,作兩個實線性空間的函數,取差值,然後再取差值中的最大值就是無窮階範數了。
1階範數:
![]()
它是![]() 上的1 -範數,同樣省略掉證明,很簡單。在深度學習的語義相似度中,利用BiLSTM+self_attention獲取到句子對兒語義表示後做差然後取1-範數,用來衡量兩個句子的語義差異,稱爲ma(曼哈頓)距離。最後用exp(-||x1-x2||)作爲最後打分函數的映射。事實上exp函數在Ai發揮了十分重要的作用,關於exp函數性質的深入研究,在《傅立葉變換最詳細的解讀》中有詳細講解。https://blog.csdn.net/randy_01/article/details/83217314
上的1 -範數,同樣省略掉證明,很簡單。在深度學習的語義相似度中,利用BiLSTM+self_attention獲取到句子對兒語義表示後做差然後取1-範數,用來衡量兩個句子的語義差異,稱爲ma(曼哈頓)距離。最後用exp(-||x1-x2||)作爲最後打分函數的映射。事實上exp函數在Ai發揮了十分重要的作用,關於exp函數性質的深入研究,在《傅立葉變換最詳細的解讀》中有詳細講解。https://blog.csdn.net/randy_01/article/details/83217314

更形象地解釋三種範數:![]() -範數是PR和RQ中最長的一邊,1-範數是PR+RQ,2-範數就是PQ。在一般情況下,ma距離衡量兩個句子的語義差異效果更好,可以防止語義丟失問題。
-範數是PR和RQ中最長的一邊,1-範數是PR+RQ,2-範數就是PQ。在一般情況下,ma距離衡量兩個句子的語義差異效果更好,可以防止語義丟失問題。
赫爾德不等式是對範數的擴展,在泛函數分析有詳細論述。
來看一個精彩的橢圓範數:A是任意n階對稱正定矩陣,x爲列向量![]() ,則函數
,則函數
![]()
是x的橢圓範數。


在區間[a,b]上定義的實連續函數的集合,構成R上的一個線性空間,可以驗證:

4.2 矩陣範數
設A![]() ,定義一個實值函數||A||,他滿足以下三個條件:
,定義一個實值函數||A||,他滿足以下三個條件:

由於矩陣有乘法運算,因此再增加一個相容性:
![]()
滿足以上4點,稱||A||爲矩陣A的範數。
下面舉例說明幾個重要的矩陣範數:
1.已知A=![]() ,則存在以下兩個範數:
,則存在以下兩個範數:
![]()
由於矩陣經常作爲向量的空間線性變換(一種映射,規則)出現,因此應該建立矩陣和向量範數的相容性。
定義:對於![]() 上的矩陣範數
上的矩陣範數![]() 和
和![]() 與
與![]() 上的同類向量範數
上的同類向量範數![]() ,如果
,如果![]()
則稱矩陣範數 ![]() 與向量範數
與向量範數 ![]() 相容。
相容。
2.矩陣的Frobenius範數以及AI應用
設A=![]() ,則
,則![]() 是矩陣的Frobenius範數。
是矩陣的Frobenius範數。
證明過程忽略,有一點需要注意:![]() ,則有
,則有![]()
即矩陣範數 ![]() 與向量範數
與向量範數 ![]() 相容。類似於向量的2-範數,把一個mxn的矩陣看成是碾平的向量,取2-範數即可。
相容。類似於向量的2-範數,把一個mxn的矩陣看成是碾平的向量,取2-範數即可。
通常所說的矩陣一階範數指的是列和範數,即取每列絕對值之和最大的數。矩陣的F範數應用是很廣的,比如用BiLSTM捕捉到一個句子的embedding,維度爲[steps,2u],用最後的壓縮向量會丟失很對語義信息,那麼構造如下的矩陣A,捕捉到句子的多個維度,最後與H做乘積得到最終的語義表示AH,維度爲[c,2u],然後碾平。這個過程的核心就是矩陣的F範數結構化約束,把這個約束加載到損失函數中最爲最後的總損失函數。

最後的語義表示爲AH,把上面的F範數作爲損失函數的結構化約束,得到最後的目標函數。在知識圖譜的transD論文裏關於entity和relation的相互投影問題以及h和t不在一個空間的問題,可以很好地用矩陣論來解釋。
3.矩陣的列和範數,譜範數和行和範數
設A=![]()
![]()
![]() ,則從屬於向量x的三種範數||x||1,||x||2,||x||
,則從屬於向量x的三種範數||x||1,||x||2,||x||![]() 的矩陣範數分別爲:
的矩陣範數分別爲:
![]()
![]()
![]()
接下來進一步分析譜範數:


問題轉化爲凸優化,目標函數是minimize s,約束函數是矩陣不等式(廣義不等式)。
5.矩陣的QR分解以及PCA,SVD
矩陣的QR分解理論對PCA和SVD具有非常好的指導意義。矩陣論裏面非常好地闡釋了QR分解和SVD的關係,這裏不做推導了。PCA其實是SVD的外部封裝。特徵值分解和奇異值分解在機器學習領域都是屬於滿地可見的方法。兩者有着很緊密的關係,特徵值分解和奇異值分解的目的都是一樣,就是提取出一個矩陣最重要的特徵。先談談特徵值分解吧:
如果說一個向量v是實對稱方陣A的特徵向量,將一定可以表示成下面的形式: 這時候λ就被稱爲特徵向量v對應的特徵值,一個矩陣的一組特徵向量是一組正交向量。特徵值分解是將一個矩陣分解成下面的形式:
其中Q是這個矩陣A的標準正交特徵向量系組成的矩陣,Σ是一個對角陣,每一個對角線上的元素就是一個特徵值。這個結論其實是QR分解的一個推廣,這個公式更能直觀地解釋第一部分關於半正定矩陣的解釋。我們來看看奇異值分解和PCA的關係吧:
5.1 矩陣的正交對角分解



5.2 矩陣的奇異值分解











上述是《矩陣論》對svd進行的詳細解釋,但是本人認爲還不夠。下面結合本人的理解來進一步闡述:
首先來引入《矩陣論》中的初等旋轉矩陣和初等反射矩陣。
5.3.初等旋轉矩陣






初等旋轉矩陣是正交矩陣,所以對向量變換時模不變,只是旋轉或者是反射。
5.4.初等反射矩陣






5.5 用矩陣的svd實現降維
關於PCA降維這裏不論述了,重點談一下利用svd降維的原理。在論述之前,先看以下svd的分解公式:

這個公式很好地闡釋了矩陣的線性變換,先是旋轉變換,然後中間是拉伸變換,最後再是旋轉變換,其中u 和v都是正交矩陣。那麼我們可以提取出奇異值的主要值,其餘不重要的忽略掉,於是有如下的降維處理:

5.6 PCA
前面提到了,PCA和SVD本質是一致的,PCA其實是SVD的外部封裝。下面直接用最大方差投影理論推導一下PCA。
說明:樣本數據矩陣,列代表特徵維度,每一行代表一個數據。比如具有兩個特徵維度的數據集可以表示爲(x,y),那麼協方差矩陣就是:[cov(x,x) cov(x,y)
cov(y,x) cov(y,y)]
pca降維的一般步驟如下:
①數據預處理,0均值並且歸一化
②構建協方差矩陣
③協方差矩陣特徵值分解
④對特徵值降序排列,找到對應的特徵向量系
⑤預處理後的數據集向④中的特徵向量系投影
下面用最大方差投影理論解釋上述步驟。
構建後的協方差矩陣爲n階Hermite正定矩陣,這意味特徵值分解後的特徵向量係爲標準正交特徵向量系,也就是座標軸。這些座標軸兩輛正交(垂直),數據集向排序後的部分座標軸投影,這些投影后的數據具有最大的方差,其餘的座標軸捨棄之。那麼投影后的方差和前面步驟中的特徵值有何關聯?PCA爲何要先構建Hermite正定的協方差矩陣?我們從幾何角度來看一下:

數據經過預處理後坐標軸是0均值單位向量。現有n個兩兩垂直的座標軸,數據集分別向這些座標軸投影,投影后的數據集仍然爲0均值單位向量,那麼投影后數據集的方差可以比較大小,從中選出top_r個,這top_r個方差值對應的座標軸就是我們想要的。
比較PCA和SVD的具體實現過程確實可以肯定,兩者本質是一致的。
下篇:
總述:上篇主要論述了矩陣理論的一般性,接下來將進一步深入探討特殊矩陣以及應用。國外翻譯版的《矩陣論》主要教會從業人員一種研究矩陣的方法論。縱觀整個篇幅基本可以發現,研究矩陣的方法不外乎以下幾種:①feature value decomposition②矩陣相似性~的研究③矩陣分塊理論。對矩陣的任何研究都離不開這三種方法,比如奇異值分解,矩陣的分解實際上是相似性和分塊理論的融合。矩陣中最重要的元素是feature value,它是矩陣的靈魂。以feature value爲核心的研究,包括線性變換,譜範數,feature value估計,矩陣的擾動問題,穩定性等等。矩陣的範數在AI中往往應用在結構化約束中,矩陣的範數還可以證明矩陣的收斂性,最小二乘法損失函數用矩陣可以解釋爲估計參數滿足向量Y在預測值平面內的投影是預測值向量本身。包括在《實變函數與泛函數分析》和《凸優化》中都可以用矩陣來解釋,比如泛函數分析中著名的乘積空間其實可以看成是矩陣空間,有界線性算子。《矩陣論》+《實變函數與泛函數分析》+《凸優化》+《統計學》是從事研究工作最基本的數學儲備。而普通本科非數學專業的微積分和線代又是前面的基礎。但是理論紮實和創新並不是一回事兒,比如國外的Ai研究員可以從生活常識中得到靈感,比如幼兒的抓鬮,物理學中的彈簧系統的穩定性等等。建立創新意識比知識儲備更重要,也就是增強自身的認知能力,而不只是停留在感知層面。比如有的公司或者研究人員認爲扒論文復現很重要,認爲本科生做不了。事實上如果中國的教育有質量保證的話,本科生完全可以勝任,因爲扒論文復現並不是什麼高深和光彩的事兒。
學習學科的目標並不是單純爲了積累知識,方法論纔是最重要的。比如國內很多研究生很水,據觀察國內很多高校根本不具備開設碩士專業的資格,導師水平不達標,有的甚至不是專業對口的導師,可想而知多麼坑人。方法論在知識圖譜中以及神經規則推理中更爲重要,比如圖模型推理的研究,基本思路是融合統計學派和圖模型,然後用神經網路學習知識表示。再比如CNN的改進總體離不開以下3種方法:①輸入層embedding的擴展,比如融合知識圖譜的embedding表示②卷積算子的改進(數學中的卷積算子的研究和有界線性算子很相似)③最後池化層的改進。去年以色列特拉維夫大學和哈弗大學的一篇改進卷積算子(譜卷積算子的論文很不錯,很前沿,這些都是工業界最具價值的研究)。目前國內的研究最大的問題是"唯論文論"的浮誇,部分博士不務實,以寫論文爲生。工業界的進步靠的是少數有價值的論文,而不是論文漫天紛。國內的研究總體上格局不大,有點兒小家子氣,保守,習慣於在1的基礎上小修小改。從0到1的過程是最具價值的,也是最消耗精力的,需要從基礎抓起。比如有的人研究方向很可能不對思路(純學術派的Ai研究員容易犯這樣的錯誤),從0到1的研究必須必須慢下來。比如很多工業界的碼農學習Ai完全是蜻蜓點水,這是不恰當的,能夠評估一篇論文的商業價值需要很強的學術能力和經驗。再比如去年微軟已經上線的core inferrence chain用cvt節點的圖譜做2-hot以上的推理,metapath衡量語義相似度,論文有些人看了以後認爲這僅僅是一篇paper而已,草率地認爲實際上實現不了。國內確實沒有上線的,這說明國內的Ai基礎研究明顯落後於美國。
1.特殊的矩陣
1.1 正定矩陣與正穩定矩陣
矩陣的研究方法在總述中已經提到了,看下面的圖:

利用以上結論可以得出:對於n階Hermite正定矩陣A有,其中P爲n階非奇異矩陣,證明過程用到了第②條結論。這個結論可以直接證明向量的橢圓範數滿足三角性。n階Hermite正定矩陣毫無疑問是穩定的,他是判斷線性系統穩定性的重要依據(依據特徵值來判斷,前面提到矩陣的特徵值是矩陣的靈魂)。
1.2 投影矩陣
1.21 投影算子、投影矩陣和冪等矩陣的概念


注意:冪等矩陣是A^2=A的矩陣。
![]()

![]()
1.22 判斷投影矩陣的條件

![]()

1.23 投影矩陣的表示

![]()
舉例:


1.3 正交投影矩陣
L子空間的向量與M子空間的向量正交,M是L的正交補。
1.31 正交投影矩陣的表示



x在L上的投影爲:
![]()
1.32 正交投影矩陣在圖模型中的應用
前面的例子不具備很好的說明,現在來論述最速馬爾可夫混合鏈兒問題。在這個例子中,你會很好地看到正交投影矩陣的作用,如何找到矩陣的第二大特徵值。

2. 矩陣的一般相似性定理
在第一篇博客已經提到了哈密特-凱萊定理,依據是任意n階矩陣與三角陣相似。在《線性代數》中論述的是特殊的相似性:n階非奇異矩陣與對角陣(特徵值)相似。更特殊的是n階對稱矩陣的相似性,從特殊到一般的情況是《矩陣論》區別於《線性代數》的地方之一。
二,矩陣與AI
1.最小二乘法的研究
1.1 橢圓方程
1.11 標準橢圓方程
在二維平面內,一個標準的橢圓方程爲x^2/a^2 + y^2/b^2 = 1,用矩陣表示爲
![]()
在《線性代數》的二次型章節中,有標準的二次型矩陣表示,重新回顧一下:





標準的二次型就是這樣的:



其中C是標準正交特徵向量系組成的矩陣。所以以原點爲中心的標準橢圓方程就是X^TAX,A爲Hermite矩陣,X爲橢圓參數。
那麼橢圓中心不在原點的方程呢?比如
![]()
很明顯此時的方程應該爲:(X-X0)^TA(X-X0)
1.12 旋轉後的橢圓方程
比如將原來的橢圓按原點順時針旋轉thelta度,旋轉後的方程是什麼樣的呢?設原橢圓上的一點a(x1,x2),旋轉後爲a`(x1`,x2`)。旋轉矩陣爲![]() ,標記爲C,於是a` = Ca。變換一下,將a`逆時針旋轉thelta度返回原來的a,此時的旋轉矩陣爲
,標記爲C,於是a` = Ca。變換一下,將a`逆時針旋轉thelta度返回原來的a,此時的旋轉矩陣爲![]() ,替換掉原來的C。於是a = Ca`,帶入原來的橢圓方程中得到:
,替換掉原來的C。於是a = Ca`,帶入原來的橢圓方程中得到: ![]() (初等旋轉矩陣和初等反射矩陣在上一篇博客有論述),中心爲X0(x10,x20)的橢圓方程爲(X-X0)^T(C^TAC)(X-X0)。
(初等旋轉矩陣和初等反射矩陣在上一篇博客有論述),中心爲X0(x10,x20)的橢圓方程爲(X-X0)^T(C^TAC)(X-X0)。
1.2 最小二乘法損失函數
1.21 最小二乘法損失函數的由來
最小二乘法對於很多AI從業人員來說很熟悉,感覺沒什麼好說的,但是真要自己獨立深入研究就需要功底了。運用數學知識自行研究AI需要方法論指導,首先寫出最小二乘法的損失函數公式:
![]() ,
,
線性迴歸中的樣本容量爲n,標記Y爲真實值,維度爲n,Y屬於C^n空間,預測值![]() 屬於 L(L爲C^n的子空間)。
屬於 L(L爲C^n的子空間)。
在《統計學》中我們知道,對於迴歸問題,真實值與預測值之間的誤差遵循標準高斯分佈![]() ,他的概率密度函數爲高斯分佈函數,因此利用最大似然函數估計得到:
,他的概率密度函數爲高斯分佈函數,因此利用最大似然函數估計得到:
![]()
讓這個概率密度函數最大化等價於exp()裏面的東東最小,於是就有了最小二乘法的損失函數。當然這個只是經驗風險估計,還沒有加上結構化約束,不能算最後的損失函數,後面將利用《凸優化》論述結構化約束。另外最小二乘法的損失函數屬於凸函數,集合屬於凸集,可以自己驗證一下(兩方面可以驗證,一是變換成橢球公式,橢球屬於典型的凸集,另一種方法求參數的二階導函數>0)。
1.22 損失函數的橢圓範數表示


也就是說X*theltaY沿着M向L的投影,更確切地說是正交投影。我們來驗證一下是否正確。公式Y=X*thelta+Z,按照《矩陣論》中投影的定義,Y分解爲了兩個子空間,這兩個子空間直和是完整的C^n空間,所以X*thelta是Y的投影,符合要求。而且是正交投影,那麼必有正交投影矩陣P滿足以下關係:PY=X*thelta,P爲Hermite冪等矩陣。那麼至此最小二乘損失函數的意義就是:找到最優的參數thelta使損失函數的橢圓範數最小(最優橢圓),根據這樣的參數thelta能夠得到Hermite冪等矩陣P使PY=X*thelta,即X*thelta是Y沿着M(M是L的正交補)的正交投影。X*thelta是對參數thelta的線性變換,把X進行奇異值分解後降維處理或者用PCA降維,X先是對thelta旋轉變換,然後伸縮變換,最後再次旋轉變換,此時的參數變成了L子空間。在實際工程訓練中只能逼近這個理想結論,能否達到主要取決於結構化約束和參數優化方法。於是引出1.23節的論述,請看下文:
1.23 損失函數的結構化約束(lasso研究)
春節後更新……
2.矩陣不等式和分類超平面
2.1 矩陣不等式
從最小二乘法的研究過程中可以看出,判斷是否爲最小二乘的依據就是中間的特徵矩陣,如果是n階Hermite正定矩陣的話,就確定了一個橢球,屬於凸集。參數優化過程是找到凸集中的最優橢球參數使損失達到極小值(不是最小值,沒有最小值,後面論述區別),也就是使橢球範數局部最小化。接下來討論對稱正定矩陣。
上篇中已經提到正定矩陣的定義,正定矩陣的約束包括:①對角線元素>0②矩陣行列式>0。這裏要強調的是,一個對稱正定矩陣總是與橢球唯一對應。那麼,現有兩個點,有多個橢球過這兩個點,這裏面的最優橢球是哪一個?
 -----------------(1)
-----------------(1)
這涉及到了矩陣不等式,先談一下廣義不等式。

廣義不等式闡述了錐集中元素的偏序或者幾何上的空間位置關係,這在矩陣中體現的更明顯。比如上面的y-x指向K的內部,表明用在x的右上方。來看下面的例子:


2.2 最小與極小元
關於最小與極小元的描述不必太複雜,直接看圖:




3. 重要的矩陣:拉普拉斯矩陣,無向圖卷積算子,譜卷積算子,從無向圖到有向圖的推理研究
2.1 拉普拉斯矩陣與PageRank算法
2.2 普通卷積算子,譜卷積算子,無向圖推理
2.21 普通卷積算子
2.22 譜卷積算子
2.23 無向圖推理
2.3 從無向圖到有向圖推理
後續:最近任正非接受採訪時表示,中國的學生基礎數學能力連日韓都不如,日本可以提供8k的視頻了,但是中國不行,因爲數學的問題。認真審視中國的基礎教育我們發現,從小學到高中,中國的數學完全停留在低等的感知層面,即解題和刷題。這是數學中最低級的東西,中國卻把它奉爲圭臬。看看高考的數學考題就可以知道,中國的基礎教育沒有希望。去年孟晚舟事件後,頭條裏頻繁推薦加拿大和美國的高中數學競賽題目,中國的很多初中生都會,很多人感覺很簡單,於是錯誤地認爲加拿大人的智商沒有中國人高。中國人智商確實高,但是很遺憾被基礎教育當作機器來訓練了,人被成功地降級爲了機器。之前總是有人炒作Ai可以取代中國的基礎教育,本人很是不認可,但是結合多年研究AI的經驗又對比中國的基礎教育發現,中國的基礎教育和當今的神經網絡訓練如出一轍:一個數學題經過千百次的練習,相當於深度學習中的歸納偏置,訓練過程堪比SGD或者模擬退火或者遺傳算法優化神經網絡參數,而歸納偏置對應於應試教育的思維定勢。中國的基礎教育搞成這樣,感覺實在是對不起老祖宗,到底是誰的錯?奉勸國內的985學生,不要把學歷當成鍍金的工具,否則實在是對不起985的招牌。中國的基礎教育絕對是反人類的,這一點可以得到證明。基礎教育改革的突破口在於兩點:①高考考題內容②人才評價體系。這兩點是教育改革最關鍵的核心問題,高考考題內容必須改變,嚮應用建模和探索題靠攏,基礎部分要大量減少數學運算和解題,重點考察對數學概念的推導,理解,其他學科也是這個思路。人才評價體系方面,高考考試分數不再是唯一的評價標準,大學是培養人的地方,4年時間應該是節奏很快很累的纔對,大學錄取面試時重點考察人本身,看看這個人能不能適應大學的生活,看看這個人的價值觀,是不是把學歷當成鍍金的工具等等,不合適的就pass,還有大學4年成績不到75分以上的不予畢業,而不是剛過60分。探索職業教育與大學教育發展並重,停止錯誤的擴招,停止教育行政化,推動高校的學術獨立,增加985比例……
中國教育改革的突破口在高考改革,高考改革成功了,中國的總體競爭力以及社會都會有所改善。一個國家的社會好不好是由教育決定的,二者可以相互影響。走在一個縣城的大街上,如果你發現這個縣城的政府大樓和白宮差不多,我們可以斷定這個縣的基礎教育肯定很爛,此處無限循環,break條件目前暫時無解……
馬相伯當年在給蔡元培、于右任、蔣夢麟等學生開示時曾說:“大學之大,非大樓之大,應是大師之大”。蔣夢麟在西南聯大時期擔任北大的校長,力推這個理念。他曾說大學的定位在於搞科研和培養人。如果沒有了這兩個,大學什麼都不是。共產黨建立新中國後,大學逐步退化,現在的大學已經淪落爲職業培訓所,尤其是985高校,實在是恥辱啊,校長下面還有副部級,全球教育界的悲哀和恥辱!目前的教育現狀是以抽概率的方式從14億人中選出"智商高"的人爲國家做貢獻,保證頭部研究,其餘的全部犧牲掉。國際上重大的科研成果中國都有,但是整體水平不行,不重視基礎教育,只關注幾個尖兒, 導致產業整體平均落伍。只有重新迴歸大學的定位,改變基礎教育,均衡發展教育,中國的產業整體才能趕上歐美,光砸錢是沒有用的,只能在少數幾個關鍵領域取得突破。